文章目录
- 第一遍
- 第二遍:了解论文论点
-
- 一、研究背景与目的
- 二、相关工作
- 三、LLMOPT框架
- 四、METHODOLOGY(方法论)
-
- [1. 数据处理](#1. 数据处理)
- [2. 学习过程](#2. 学习过程)
- [3. 自动测试](#3. 自动测试)
- 四、实验评估
- 五、讨论
论文地址:LLMOPT: LEARNING TO DEFINE AND SOLVE GENERAL OPTIMIZATION PROBLEMS FROM SCRATCH
第一遍
一、摘要
优化问题在多场景普遍存在,利用大语言模型(LLMs)实现自然语言描述的优化问题自动化虽有潜力,但存在优化泛化问题,当前LLM相关方法在建模优化问题类型的通用性和准确性上有限。
本文提出LLMOPT统一学习框架,从自然语言描述和预训练LLM出发,构建五元素公式,经多指令微调、模型对齐等,在约20个领域的6个真实数据集上实验,相比最先进方法,平均求解精度提高11.08%。
二、关键词
大语言模型;优化泛化;LLMOPT;五元素公式;模型对齐
提出LLMOPT框架来,统一学习框架来提升优化泛化能力。它从优化问题的自然语言描述和预训练 LLM 出发,构建五元素公式作为学习定义不同优化问题类型的通用模型;
- 采用多指令微调,提高问题形式化和求解器代码生成的准确性与通用性;
- 引入模型对齐和自校正机制,防止 LLMs 出现牺牲求解精度避免执行错误等 "幻觉" 问题。
三、预知识
1. 什么是优化泛化问题
优化泛化问题是指在利用大语言模型(LLMs)处理优化问题时,模型在求解优化问题的准确性以及能够处理的优化问题类型的通用性方面存在限制的情况。具体来说,就是模型可能无法准确地解决各种不同类型的优化问题,或者在面对新的、未曾见过的优化问题场景时,表现出较差的适应性和求解能力。
以下是一些优化泛化问题的简略示例:
- 生产调度:LLM - 基于的系统在常规生产场景表现好,但面对设备故障、紧急订单等特殊情况时,因训练数据覆盖不足,难以准确调整调度方案,导致生产问题。
- 物流配送:基于LLM的规划模型依据常规路况数据训练,遇到交通管制、道路施工等特殊情况,无法合理调整路线,致使配送效率降低。
- 投资组合:LLM - 驱动的模型在平稳市场能提供合理投资建议,但在市场波动、政策调整或有新产品时,难以准确调整策略,影响投资收益。
在nl2sql(自然语言到SQL的转换)中,优化泛化问题也较为突出,以下是一些实际例子:
- 复杂查询场景:当用户输入"找出过去一年中销售额最高的产品类别,且该类别产品在每个季度的销售增长率都超过10%"这样复杂的自然语言查询时,nl2sql系统可能在训练数据中较少遇到这种同时涉及时间范围、聚合计算以及条件筛选的复杂组合情况。因此,可能无法准确生成对应的SQL语句,导致查询结果不准确或无法查询出结果,体现了模型在处理复杂查询场景下的优化泛化能力不足。
- 数据库结构变化:如果数据库中新增了一些表或字段,例如在原有的销售数据库中新增了"产品退货率"字段,而nl2sql模型在训练时并未接触到这些新结构。当用户询问"找出退货率最低的产品及其销售额"时,模型可能无法正确将自然语言转换为包含新字段的SQL语句,因为它难以适应数据库结构的变化,这显示了模型在面对数据库结构动态变化时的泛化能力有限。
- 语义模糊问题:自然语言中存在语义模糊性,如"查找最近畅销的商品","最近"可以有多种理解,可能是近一周、近一个月或其他时间范围。nl2sql模型如果在训练过程中没有充分学习到如何处理这种模糊语义,就可能无法准确确定用户意图,生成的SQL语句可能会按照默认的时间范围进行查询,导致结果与用户期望不符,这反映了模型在处理语义模糊的自然语言查询时优化泛化能力有待提高。
2. 什么是消融研究
Ablation studies即消融研究,是一种在机器学习、深度学习等领域广泛应用的研究方法,用于评估模型中不同组件或操作对模型整体性能的贡献。
具体来说,消融研究通过逐步移除或修改模型的某些部分,然后观察模型性能的变化,以此来确定这些部分对模型性能的影响。例如,在研究一个图像识别模型时,可能会进行以下消融研究:
- 移除某个卷积层:观察模型对图像特征提取能力的变化,以及对最终识别准确率的影响,从而判断该卷积层在模型中的重要性。
- 改变损失函数的某个部分:看模型的收敛速度、稳定性以及最终的性能指标如何变化,以分析该部分损失函数对模型训练的作用。 在上述论文中,通过消融研究来验证问题定义(五元素公式)和模型对齐对提高模型准确性的贡献,即分别去掉这两个部分或改变相关设置,观察模型在解决优化问题时的准确性变化,从而明确它们在LLMOPT框架中的重要性。
3. model alignment(模型对齐)
model alignment(模型对齐)是指为了进一步提升模型的准确性并降低幻觉风险而采取的一系列措施。
模型对齐旨在让模型的输出更符合实际问题的要求,使模型在处理和解决问题时能够遵循特定的规则和目标,减少产生不合理或错误输出的可能性。例如,在处理优化问题时,通过模型对齐可以让模型更好地理解问题的约束条件和目标函数,从而给出更准确、更符合实际情况的解决方案,避免出现与实际问题不相符的"幻觉"结果。
更广泛地说,在人工智能领域,模型对齐通常涉及到使模型的行为、输出或内部表示与某种外部标准或期望的行为保持一致。这可能包括将模型的预测与人类专家的判断对齐,或者使模型在不同的任务或数据集上表现出一致且合理的行为。通过模型对齐,可以提高模型的可靠性、可解释性和实用性,使其更好地适应各种实际应用场景。
第二遍:了解论文论点
一、研究背景与目的
- 优化问题现状与挑战:优化问题广泛存在,如作业调度、路径规划等,但从自然语言描述中定义和解决需专业知识、专家参与和大量时间,阻碍了基于优化的决策广泛应用。利用LLMs实现自动化存在优化泛化问题,即模型在求解准确性和处理问题类型的通用性方面受限。
- 研究目的:提出LLMOPT框架,提升优化泛化能力,解决准确性和通用性问题,使模型更好适用于实际场景。
二、相关工作
- LLMs用于构建和解决优化问题 :
- 背景:NL4Opt竞赛推动相关研究,工作分为基于提示和基于学习的方法。
- 基于提示的方法:如Chain-of-Expert引入基于智能体工作流程,OptiMUS采用定制提示解决线性和混合整数线性规划问题。
- 基于学习的方法:相对研究不足,如LLaMoCo引入指令微调框架,ORLM提出半自动化生成合成训练数据方法,Mamo提供数学建模基准及生成求解器代码的标准化流程。
- LLMs作为优化器组件 :
- 杨等人受贝叶斯优化启发,提出用LLMs作优化器,一个LLM迭代优化提示词,引导另一个LLM执行特定优化任务。
- LLMs可充当优化器组件,如用于遗传算法的交叉和变异算子、生成轨迹优化解决方案、用于多目标优化任务、在贝叶斯优化中模拟采集函数和代理模型等。
三、LLMOPT框架
- 数据 :
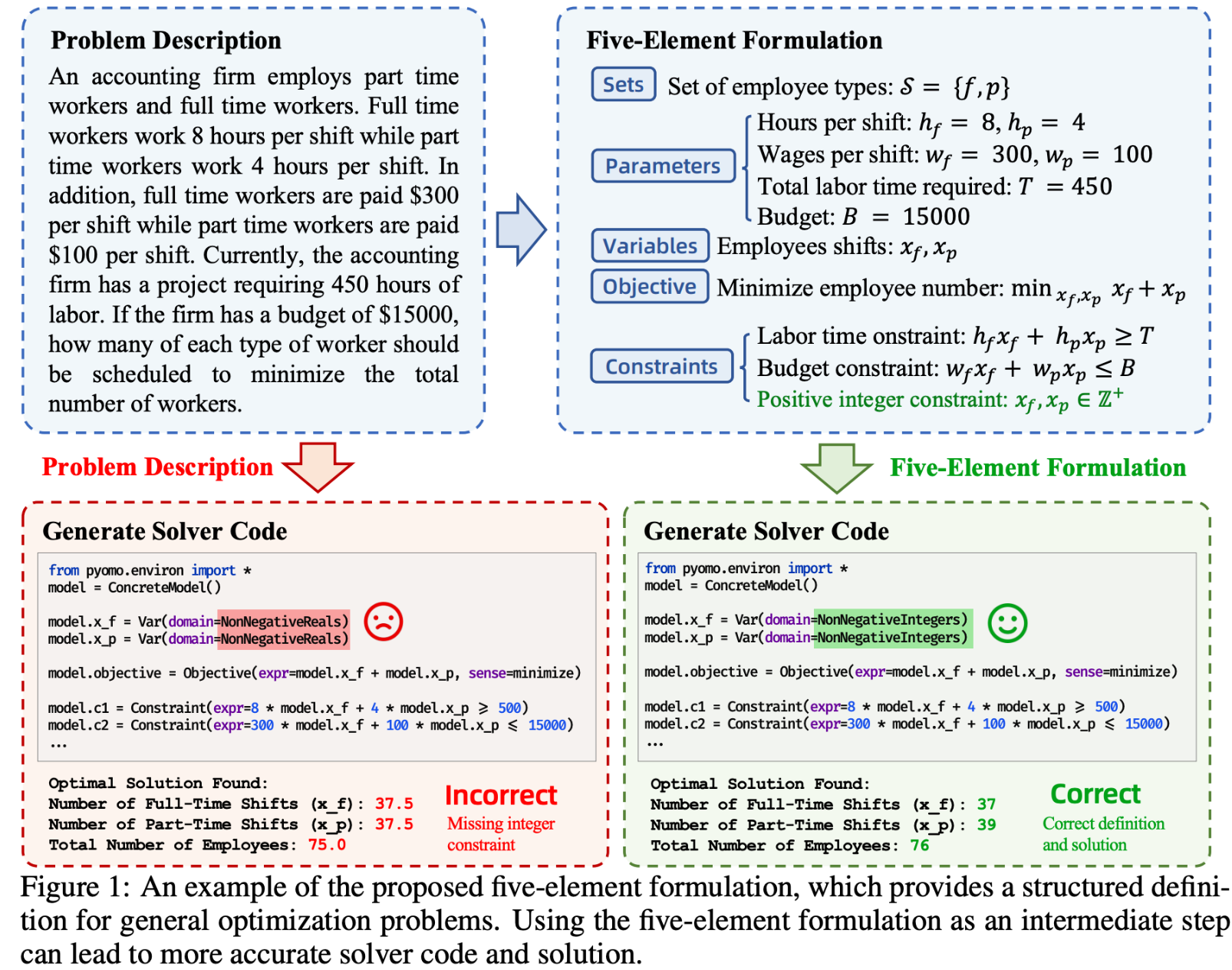
- 五元素公式:提出五元素公式(集合、参数、变量、目标和约束)定义优化问题,能准确表述问题,增强泛化能力,如捕捉隐含的正整数约束,可定义多种类型优化问题。
- 数据收集与划分:收集多个现有优化问题数据集,划分测试集与训练集,确保数据分离。
- 数据增强与标注:利用LLMs通过提示工程扩充数据,专家审查确保质量,进行数据标注,产生适合多指令监督微调(SFT)和模型对齐的数据。
- 学习 :
- 多指令SFT:采用多指令监督微调,通过专家标注的多指令数据集提升LLMs定义和解决问题的准确性,目标是最大化条件概率。
- 模型对齐:引入模型对齐,采用卡尼曼-特沃斯基优化(KTO)算法,依据指令、补全内容和可取性数据对齐模型,减少幻觉,提升性能。
- 自动测试:依据五元素框架构建问题、生成并执行求解器代码、分析运行日志判断是否自校正,自校正机制提升优化泛化能力。
四、METHODOLOGY(方法论)
LLMOPT框架的方法论,旨在通过基于学习的方法实现优化问题定义和求解的更好优化泛化能力。
LLMOPT框架包含数据、学习和自动测试三个关键部分。通过引入五元素公式定义优化问题、进行多指令监督微调(SFT)和模型对齐提高求解准确性,以及带有自校正功能的自动测试过程,实现优化泛化。
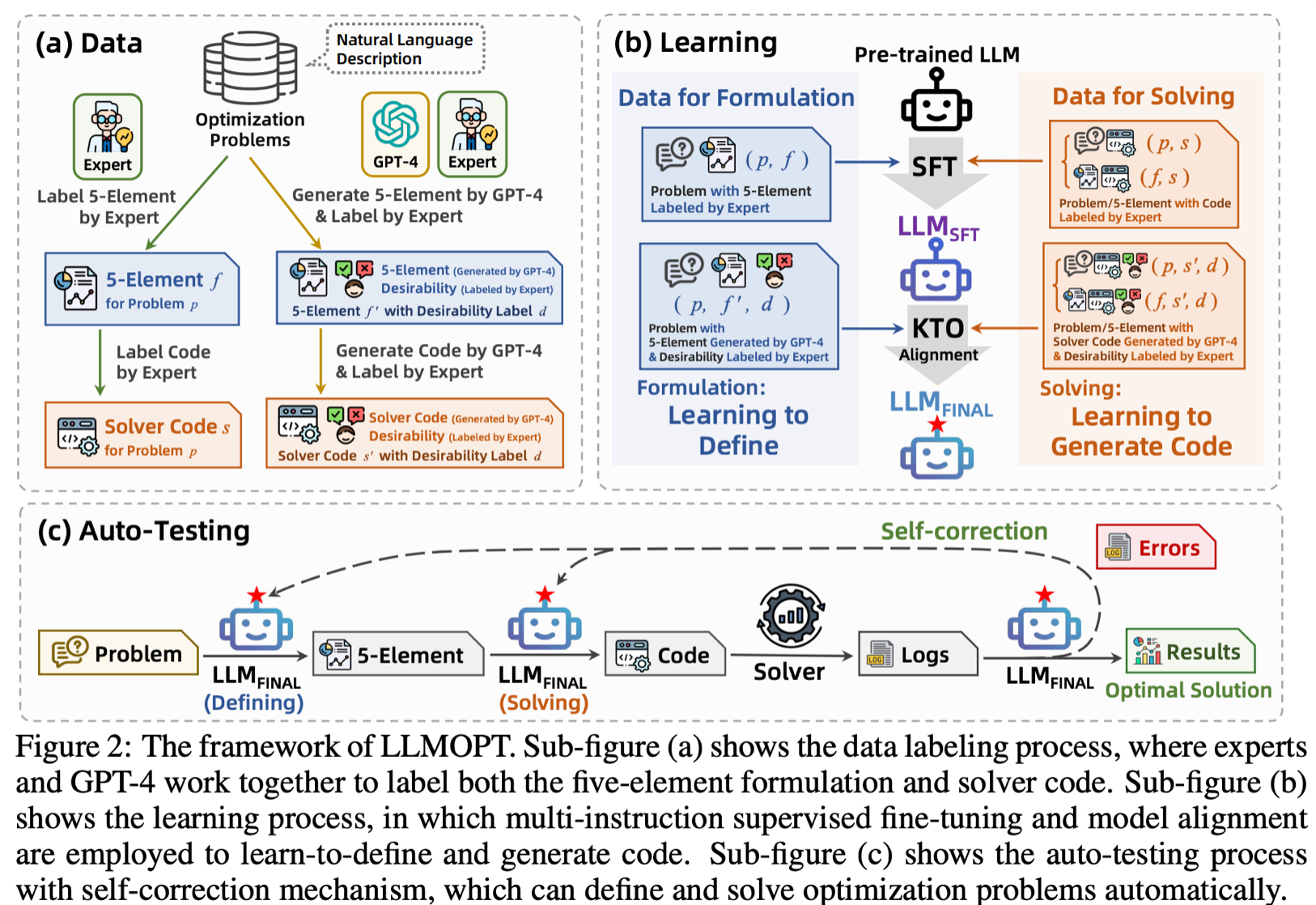
1. 数据处理
- 定义问题:提出五元素公式(集合、参数、变量、目标和约束)定义一般优化问题。它基于优化问题的数学表达式,能保留关键信息,更准确表述问题,且易于大语言模型理解,可定义多种类型优化问题,增强优化泛化能力。
- 数据增强与标注:收集现有优化问题数据集,划分测试集与训练集。利用大语言模型通过提示工程对种子问题应用多种指令进行数据扩充,专家审查确保数据质量和多样性。专家使用五元素公式和求解器代码标注优化问题,GPT-4也生成标注,经专家验证产生完全准确和有潜在错误但经专家验证的两种标注数据,适用于多指令监督微调与模型对齐。
2. 学习过程
- 多指令SFT:采用多指令监督微调,多指令数据集由专家标注,包括问题构建数据集和求解数据集,分别提升大语言模型定义问题和生成求解器代码的能力。微调目标是最大化条件概率,通过最小化负对数似然实现。
- 模型对齐:引入模型对齐减轻大语言模型面对新问题时的幻觉,采用卡尼曼-特沃斯基优化(KTO)算法作为对齐方法,避免奖励模型偏差且减少数据需求。KTO依据(指令、补全内容、可取性)数据对齐模型,其使用的数据集包含GPT-4生成的补全内容及专家赋予的可取性标签,专家通过赋予可取性标签达成模型对齐。通过相关公式推导得出KTO损失函数,促使KTO模型生成与专家标注数据更相符的补全内容,提升优化泛化能力。
3. 自动测试
- 过程步骤:依据自然语言描述,利用五元素框架构建优化问题,针对五元素公式生成并执行求解器代码,分析求解器运行日志判断是否需自校正,实现问题定义和代码生成流程自动化并集成自校正机制。
- 自校正功能:受启发实现自校正,自动分析输出结果、识别代码执行错误。指令按问题、五元素公式、代码及执行结果组织,遵循特定模板。自校正大语言模型判断是否需进一步处理或已得最优解,若需处理则生成带建议分析并决定返回问题构建或代码生成步骤,提升优化泛化能力,特别是问题构建和最终解的准确性。
四、实验评估
- 实验设置:基于Qwen1.5-14B进行SFT和模型对齐,在六个真实数据集上与多种方法比较,用执行率(ER)、求解准确率(SA)和平均求解次数(AST)评估性能。
- 优化泛化分析 :
- 将LLMOPT与基于提示、基于学习的方法以及GPT-4进行比较,展示其优化泛化能力。
- 在Qwen1.5-14B上进行SFT的LLM性能可与GPT-4o相当,完整的LLMOPT在六个数据集上优于GPT-4o和GPT-4-Turbo。
- LLMOPT在六个数据集的求解准确率(SA)达SOTA,相比基于学习的方法,五元素公式定义和自校正使四个数据集准确率平均提升14.83%;相比基于提示的方法,SFT和模型对齐让三个数据集平均提升10.67%,六个数据集上平均提升当前最优性能11.08%。
- 在六个涵盖多种优化类型和20多个领域的数据集上测试,LLMOPT取得SOTA结果,展示了高准确性和通用性。
- 消融研究 :
- 进行全面消融实验,包括无五元素公式、无KTO对齐、无自校正的LLMOPT实验。
- 五元素公式作问题定义提高六个数据集的SA,但有时会降低ER,以略降ER为代价确保正确代码生成,提高SA。
- KTO对齐显著提高六个数据集的SA并减少AST,五元素和KTO对齐结合在复杂数据集上提升SA和AST方面的性能。
五、讨论
- 在更大模型上的尝试:在Qwen2-72B上部署LLMOPT性能提升,但考虑性能与成本权衡,Qwen1.5-14B已达最优性能,未选更大模型。
- 与OpenAI o1模型的比较:OpenAI o1模型推理能力强但有使用限制,LLMOPT微调开源模型在实际工业场景更具成本效益。
- 大语言模型的跷跷板问题:在10个通用任务上比较模型微调前后性能,微调后6个任务性能提升,4个下降,平均提升0.3%,未观察到明显跷跷板效应。
- 高质量数据的重要性:高质量数据对LLMs微调关键,现有优化问题数据稀缺且标注质量低,数据扩充和标注存在挑战。
- 未来研究问题:需高效收集、合成并生成更多样化且标注良好的高质量数据,探索大规模问题数据结构。