文章目录
- [1、 消息队列的作用什么?](#1、 消息队列的作用什么?)
- [2、Kafka 集群的架构是什么样子的?](#2、Kafka 集群的架构是什么样子的?)
- [3、Kafka 消费者组和生产者组是什么?](#3、Kafka 消费者组和生产者组是什么?)
- [4、 Kafka 如何保证消息的的不丢失?](#4、 Kafka 如何保证消息的的不丢失?)
- [5、Kafka 为什么性能高?比 RocketMQ 吞吐率高的根本原因是什么?](#5、Kafka 为什么性能高?比 RocketMQ 吞吐率高的根本原因是什么?)
-
- [1、顺序磁盘 I/O 的极致利用](#1、顺序磁盘 I/O 的极致利用)
- 2、零拷贝(Zero-Copy)技术`(核心、根本)`
- [3、页缓存(Page Cache)优先策略](#3、页缓存(Page Cache)优先策略)
- 4、批量处理与高效压缩
- [6、 Kafka 如何保证消息的顺序消费?](#6、 Kafka 如何保证消息的顺序消费?)
1、 消息队列的作用什么?
1. 解耦
定义:解耦是指将系统中的各个组件或模块之间的直接依赖关系降低,使它们之间的交互更加灵活和独立。
实现原理:生产者将消息发送到消息队列中,消费者从队列中获取消息进行处理。生产者和消费者之间不再直接通信,而是通过消息队列这个中间件进行交互。
应用场景:在电商系统中,订单系统和库存系统可以通过消息队列进行通信。订单系统生成订单后,将订单信息发送到消息队列,库存系统从队列中获取订单信息并处理库存更新。即使库存系统暂时不可用,订单系统也可以正常运行,不会受到影响。
2. 异步通信
定义:异步通信是指生产者发送消息后,不需要等待消费者立即处理消息,而是可以继续执行其他任务。
实现原理:消息队列允许生产者将消息发送到队列后立即返回,消费者则根据自己的处理能力从队列中拉取消息进行处理。
应用场景:在用户注册场景中,主流程(如数据库写入)完成后,非关键操作(如发送邮件、短信通知)可以通过消息队列异步处理。这样可以快速响应用户请求,提高用户体验。
3. 削峰填谷
定义:削峰填谷是指通过消息队列缓冲瞬时高流量,将其平滑为持续的低流量,避免系统因瞬时高并发而崩溃。
实现原理:当生产者生成消息的速度超过消费者处理的速度时,消息会被存储在队列中,消费者按固定速率消费消息。这样可以减少对消费者的压力,防止系统因突发高负载而崩溃。
应用场景:在秒杀活动或双十一等高流量场景中,用户下单请求量激增。通过将请求写入消息队列,后台服务按能力处理,避免瞬时压力导致系统崩溃。
思:消息队列是什么?
消息队列的定义
消息队列(Message Queue,简称MQ)是一种中间件,用于在应用程序之间传递消息。它允许一个或多个生产者(消息的发送者)将消息发送到队列中,同时允许一个或多个消费者(消息的接收者)从队列中读取消息。消息队列的主要功能是存储和转发消息,从而实现应用程序之间的通信。
消息队列的工作原理
生产者(Producer):生产者是消息的发送方,它将消息发送到消息队列中。
消息队列(Message Queue):消息队列是一个中间存储,用于暂存消息。它是一个先进先出(FIFO)的队列。
消费者(Consumer):消费者是消息的接收方,它从消息队列中读取消息并进行处理。
消息队列的作用
解耦:生产者和消费者之间不需要直接通信,通过消息队列间接交互。
异步通信:生产者发送消息后可以继续执行其他任务,不需要等待消费者处理。
削峰填谷:缓冲瞬时高流量,平滑负载。
消息队列的常见类型
点对点(Point-to-Point):一个消息只能被一个消费者消费。
发布-订阅(Publish-Subscribe):一个消息可以被多个消费者消费。
消息队列的常见实现
Apache Kafka:高性能、分布式的消息队列,适合高吞吐量场景。
RabbitMQ:支持多种协议,功能丰富,适合多种应用场景。
ActiveMQ:功能强大的消息中间件,支持多种消息协议。
RocketMQ:高性能、高吞吐量的消息队列,适合大规模分布式系统。
消息队列的简单例子
假设你有一个电商系统,用户下单后需要发送邮件通知用户。如果没有消息队列,下单模块需要直接调用邮件发送模块,这会导致以下问题:
如果邮件发送模块不可用,下单模块也会失败。
下单模块需要等待邮件发送完成才能返回,用户体验差。
使用消息队列后:
下单模块将订单信息发送到消息队列。
邮件发送模块从消息队列中读取订单信息并发送邮件。
下单模块不需要等待邮件发送完成,用户体验更好。
2、Kafka 集群的架构是什么样子的?
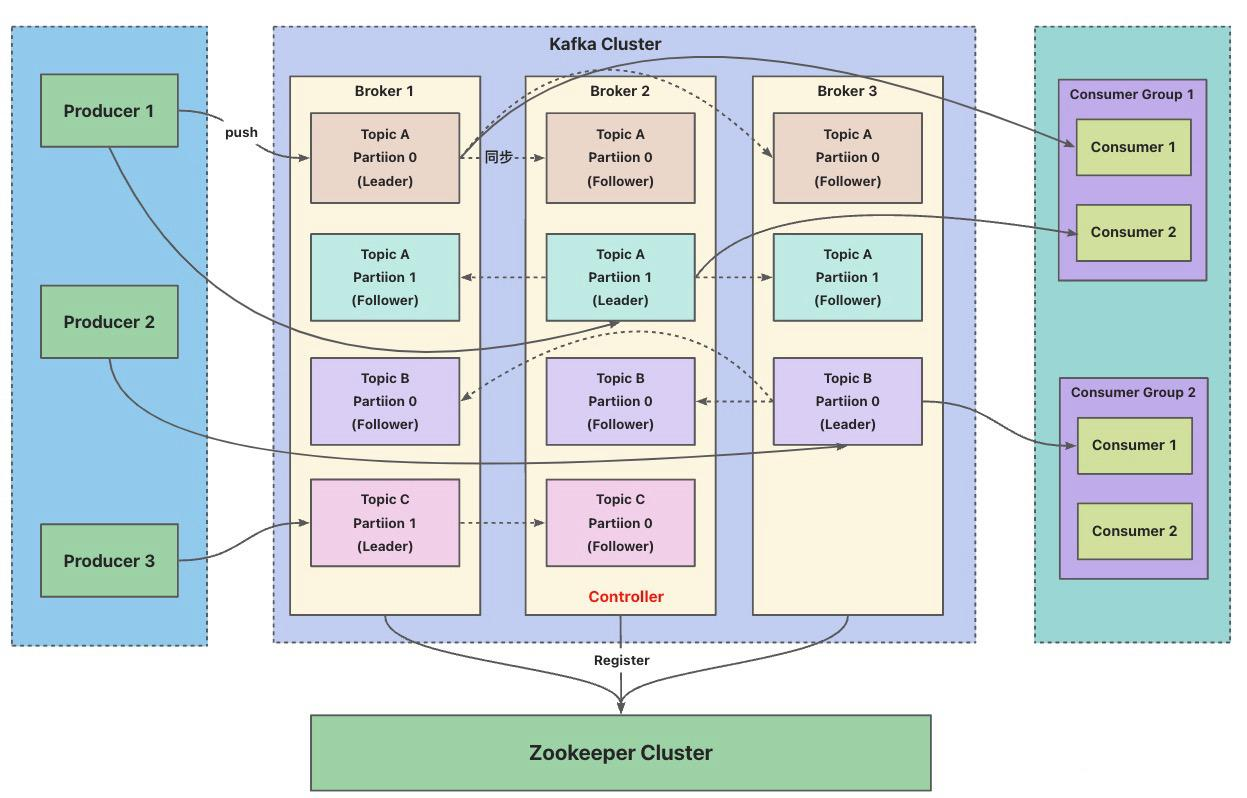
3、Kafka 消费者组和生产者组是什么?
定义与核心作用
- 定义:消费者组(Consumer Group)是由多个消费者实例组成,共同订阅并消费一个或多个主题(Topic)的消息。
- 核心作用 :实现消息的并行消费 和负载均衡,确保高吞吐量和容错性。消费者组下可以有一个或多个消费者实例,它们共享一个公共的 ID,这个 ID 被称为 Group ID。
关键机制
-
分区分配:
- 每个分区(Partition)只能被同一消费者组内的一个消费者消费。
- 若消费者数量 > 分区数,多余的消费者处于闲置状态。
- 示例:主题有3个分区,消费者组有3个消费者 → 每个消费者负责1个分区。
-
重平衡(Rebalance):
- 触发条件:消费者加入/离开、分区数量变化。
- 过程:重新分配分区所有权,确保负载均衡。
- 缺点:重平衡期间消费者暂停消费,可能影响实时性。
-
偏移量(Offset)管理:
- 消费者组通过提交偏移量记录消费进度(存储于
__consumer_offsets主题)。 - 支持自动提交(默认)或手动提交(精确控制)。
- 消费者组通过提交偏移量记录消费进度(存储于
典型场景
- 横向扩展:增加消费者实例提升消费速度。
- 容灾恢复:消费者故障后,其他消费者接管其分区。
- 多租户隔离:不同消费者组独立消费同一主题(如日志分发)。
切记
一个主题中的一个 Partition 只能被同一个消费者组中的一个消费者消费!!!如果一个消费者组中的消费者数量大于 Partition 数量,则会导致多出来的消费者无法消费到消息。
常见问题解答
Q1:消费者组内多个消费者如何避免重复消费?
- 答案:每个分区仅由一个消费者消费,偏移量由组统一管理,天然避免重复。
Q2:生产者如何实现消息的顺序性?
- 答案:对同一分区(如相同Key的消息),Kafka保证顺序写入;跨分区无法保证。
Q3:消费者组能否消费多个主题?
- 答案:可以,消费者组可订阅多个主题,按分区分配策略统一管理。
4、 Kafka 如何保证消息的的不丢失?
从以下三个方面进行保证:
- 生产者Producer,使用带回调通知的send(msg,callback)方法,并且设置acks = all 。它的消息投递要采用同步的方式。Producer要保证消息到达服务器,就需要使用到消息确认机制,也就是说,必须要确保消息投递到服务端,并且得到投递成功的响应,确认服务器已接收,才会继续往下执行。
- 设置broker中的配置项unclean.leader.election.enable = false,保证所有副本同步。同时,Producer将消息投递到服务器的时候,我们需要将消息持久化,也就是说会同步到磁盘。注意,同步到硬盘的过程中,会有同步刷盘和异步刷盘。如果选择的是同步刷盘,那是一定会保证消息不丢失的。就算刷盘失败,也可以即时补偿。但如果选择的是异步刷盘的话,这个时候,消息有一定概率会丢失。
- 就是消费者Consume。设置enable.auto.commit为false。在Kafka中,消息消费完成之后,它不会立即删除,而是使用定时清除策略,也就是说,我们消费者要确保消费成功之后,手动ACK提交。如果消费失败的情况下,我们要不断地进行重试。所以,消费端不要设置自动提交,一定设置为手动提交才能保证消息不丢失。
5、Kafka 为什么性能高?比 RocketMQ 吞吐率高的根本原因是什么?
1、顺序磁盘 I/O 的极致利用
- 日志追加写入(Append-Only Log) :
Kafka 将消息按顺序追加到磁盘文件,完全避免随机写 。
优势:顺序 I/O 性能远超随机 I/O(机械硬盘顺序写速度可达 100MB/s,随机写仅 1MB/s)。 - RocketMQ 的妥协 :
虽然 RocketMQ 也采用顺序写入(CommitLog),但需维护 索引文件(ConsumeQueue) 支持消息查询,引入轻微随机读,降低 I/O 效率。
2、零拷贝(Zero-Copy)技术(核心、根本)
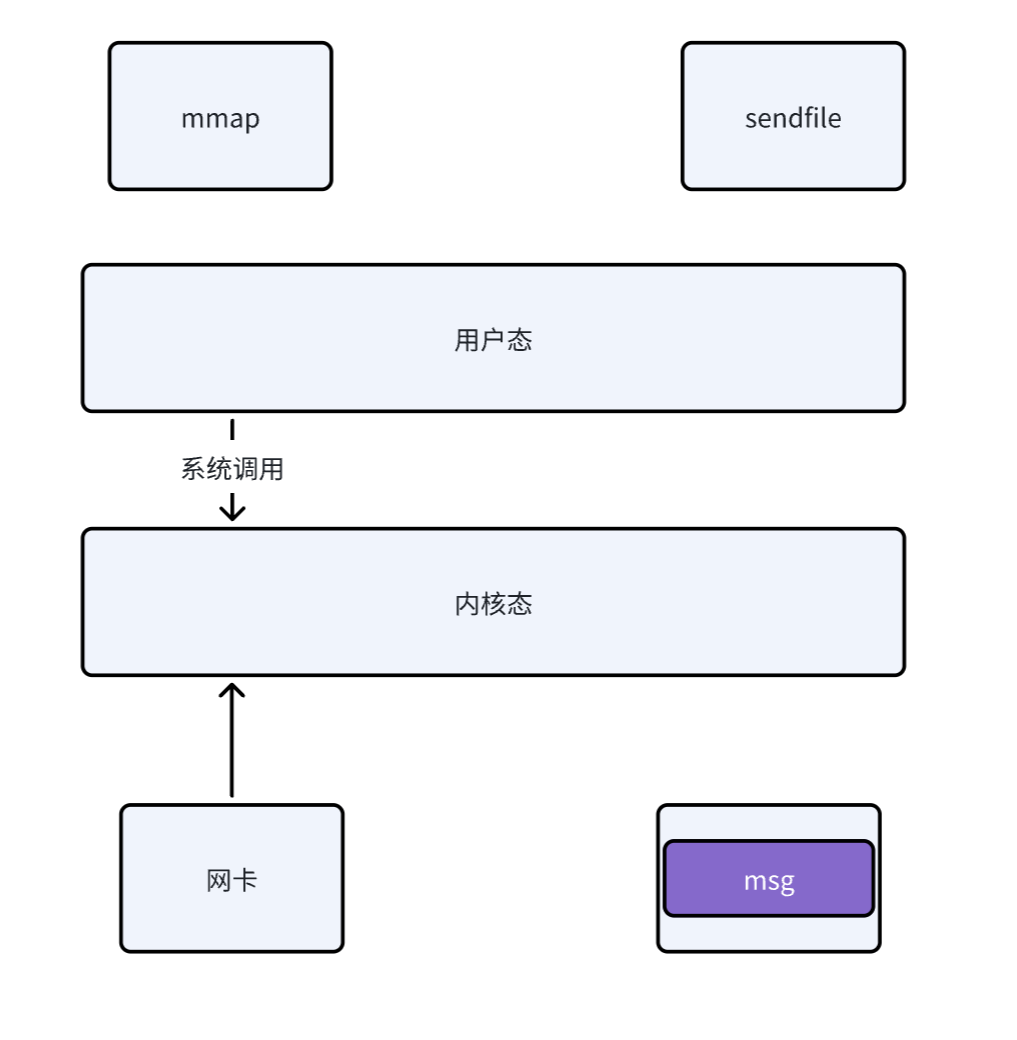
由于 Kafka 仅提供基础功能,并不提供死信队列、延迟队列等功能
- Kafka 的实现 :
使用sendfile(函数返回字节数)系统调用,数据直接从 页缓存(Page Cache) 传输到网卡,跳过用户态与内核态的数据拷贝。
效果:减少 2 次内存拷贝(传统流程需 4 次),降低 CPU 和内存占用。 - RocketMQ 的局限 :
虽然 RocketMQ 也采用了零拷贝技术,但是需要由于 RocketMQ 实现了信队列、延迟队列等高级功能,所以必然需要从内核态将数据拷贝到用户态,因此其系统调用使用的是mmap(函数返回了消息的具体内容),得到的具体消息内容,因此其零拷贝实际进行了三次数据的拷贝,而 kafka 仅进行了两次。
3、页缓存(Page Cache)优先策略
- Kafka 的设计哲学 :
- 数据读写直接依赖操作系统的页缓存,避免 JVM 堆内存管理开销(如 GC 停顿)。
- 消息写入时仅追加到页缓存,由操作系统异步刷盘,最大化 I/O 吞吐。
- RocketMQ 的取舍 :
默认使用 堆外内存(DirectBuffer) 存储消息,减少 GC 影响,但需手动管理内存,复杂度高。
4、批量处理与高效压缩
- 批量写入与拉取 :
- 生产者积累一批消息后批量发送,减少网络请求次数。
- 消费者批量拉取消息,提升单次请求效率。
- 压缩算法(如 LZ4、ZStandard)显著降低网络传输量。
- RocketMQ 的平衡点 :
默认配置更偏向低延迟(如批量阈值较小),牺牲部分吞吐量。
- 分区(Partition)并行模型
- 无锁化设计 :
每个 Partition 独立处理读写,天然支持水平扩展。
生产者、消费者在 Partition 级别无竞争,避免锁开销。 - RocketMQ 的队列(Queue)模型 :
类似 Kafka 的 Partition,但事务消息、顺序消息需额外协调,可能引入锁竞争。
- 异步副本与一致性权衡
- Kafka 的 ISR 机制:
异步复制数据到 Follower,只需 Leader 确认写入即可响应生产者,高吞吐优先 。
允许副本短暂不一致(通过 min.insync.replicas 控制可靠性)。 - RocketMQ 的同步双写:
主从副本同步写入后才返回确认(SYNC_MASTER 模式),强一致性优先,吞吐量降低。
6、 Kafka 如何保证消息的顺序消费?
**Kafka只能保证单个分区内的消息顺序,而无法保证跨分区的顺序。**这一点很重要,因为很多用户可能会误以为只要在一个主题下就能保证全局顺序,但实际上需要依赖分区的设计。
接下来需要详细解释如何利用分区来保证顺序。比如生产者通过指定消息键(Key)将相关消息发送到同一分区,消费者则按分区顺序消费。这时候可能会提到生产者发送消息时使用相同的Key,确保进入同一分区,消费者单线程处理每个分区的消息,或者使用多线程但确保同一分区的消息由同一线程处理。
同时,用户可能想知道如何应对消费者组内的多个消费者实例,这时候需要解释分区的分配机制,每个分区只能被一个消费者实例消费,从而保证顺序。如果有多个消费者实例,每个实例处理不同的分区,而每个分区内的消息是顺序的。