Mysql基础语法(一)
在这个基础语法(一)中,仅讲解简单的DDL、DML和DQL语句使用。
一、基本概念
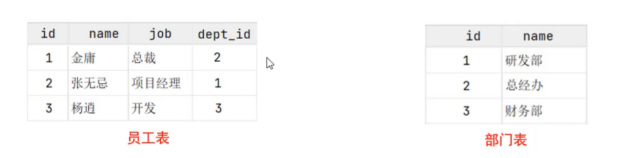
Mysql是一种关系型数据库,即由多张相互连接的二维表组成。参考下面这幅图,员工表的dept_id字段关系到部门表的id字段,也就是两张二维表具有关系。
- **二维表:**Mysql中的表都是二维的,也就是行与列,除此之外,没有第三维度。
二、数据类型
Mysql数据库中的数据类型一般分为三大类,数值类型、字符串类型和时间类型。
2.1 数值类型
Mysql中的数值类型一共有8个(主要掌握INT和FLOAT),其中包括整型和浮点数类型,如下:
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 描述 |
|---|---|---|---|---|
| TINYINT | 1 btye | -2^8 ~ 2^7-1 | 0 ~ 2^8-1 | 小整数 |
| SMALLINT | 2 btye | -2^15 ~ 2^15-1 | 0 ~ 2^16-1 | 大整数 |
| MEDIUMINT | 3 btye | -2^23 ~ 2^23-1 | 0 ~ 2^24-1 | 大整数 |
| INT / INTEGER | 4 btye | -2^31 ~ 2^31-1 | 0 ~ 2^32-1 | 大整数 |
| BIGINT | 8 btye | -2^63 ~ 2^63-1 | 0 ~ 2^64-1 | 极大整数 |
| FLOAT | 4 btye | 单精度浮点数 | ||
| DOUBLE | 8 btye | 双精度浮点数 | ||
| DECIMAL | 小数值 |
- 1 byte指的是占一个比特,一个比特占8个二进制位(每个二进制位都是0或者1),在无符号中,一个比特能最大表达2的八次方减一(即2^8 - 1),这是由于即使你8个二进制位都是1,即11111111。那也就是(2的8次方-1),由于其无法占用到第九位,因为28的二进制是100000000,所以1个比特最大能表达(2的8次方-1)。
- 在有符号 中,一个比特(8位),需要用一位来记录正负符号(符号位一般是最高位,0表示正数,1表示负数),所以只有七位用于记录数的大小,那么在正数部分,最大能表达(2的7次方-1),那为何负数能表达到(2的7次方)呢,这是由于符号位的存在,0表示为00000000,那么当符号位为负数时,100000000表示-0,虽然看着是0,但是这个数被二进制使用,表示负数的最大数,即2^7。
- 以上说的这些二进制计算,和计算机组成原理有关系,这里稍微拓展了一下。
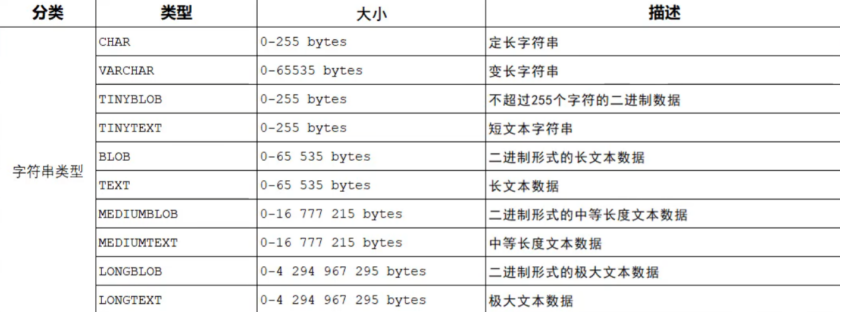
2.2 字符串类型
字符串类型一共有10种,其中主要是CHAR和VARCHAR类型。
- VARCHAR是一种不定长字符串,也就是说他会根据实际内容来占用空间;而CHAR是一种定值占用空间的类型。
sql
-- 下面同样定义30比特空间大小的两个字符串类型,例如插入abcd,四个英文字符,理论占用4的字节的空间
-- VARCHAR的占用的空间,会根据实际插入字符的大小来决定,abcd占4个字节
VARCHAR(30);
-- CHAR则是定值空间占用,即使abcd占不到30比特,但是他会在空间中占用30个比特的大小
CHAR(30);- 所以VARCHAR的优势很明显,对于不定长的字段(例如游戏名称,有长有短),可以根据这个来定义,能节省空间。
- 对于定长,例如电话号码,身份证号,使用CHAR,因为CHAR插入效率高,VARCHAR需要计算字符串大小,效率低。
2.3 时间类型
Mysql的时间类型主要有五个,主要掌握DATE、DATETIME和TIME。
- DATE是日期,TIME是具体时间、DATETIME是具体日期的具体时间

三、通用语法
3.1 语法规则
在数据库中,有一种通用的SQL语法,该SQL语法在Mysql之外的其他数据库也适用,例如Oracle。SQL语法用着下面三个规则:
- SQL默认都是;(英文分号)结尾,在识别到结尾符号之前,SQL可以写多行,也可以写一行,直到;符号结束
sql
-- 可以写成一行
select * from tb_user;
-- 也可以写成多行,一般复杂的SQL就会写成多行
select *
from
tb_user;- SQL中每个关键字或者表面之间可以隔离多个空格
sql
-- 下面两句SQL是等价的,两个单词或者关键字之间可以有多个空格
select * from tb_user;
select * from tb_user;- SQL中关键字(例如select、update等等)不区分大小写
sql
-- 等效
select * from tb_user;
SELECT * from tb_user;3.2 SQL语法
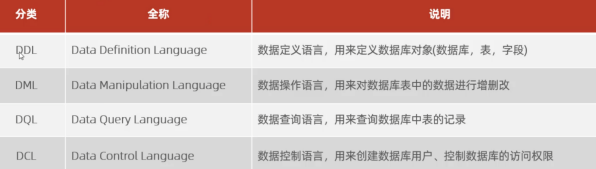
SQL的主要语法分为四大类,DDL(定于数据库和表)、DML(增删改)、DQL(查询)和DCL(系统控制)。
(注:个人觉得使用层面上,最重要的就是DQL,其次是DDL和DML,DCL的话一般运维人员用得多,我们一般很少用)
3.2.1 DDL语句(于数据库和表)
- 查看数据库
sql
show databases;- 切换数据库(注意,一定要切换数据库,才能使用数据库下面的表,不然调用数据表会报错,这里用database_name表示要创建的数据库名字)
sql
use database_name;- 创建数据库(if not exists 可以不写,但是规范建议写)
sql
create database database_name if not exists;- 删除数据库(if exists 可以不写,但是规范建议写)
sql
drop database if exists database_name;- 查看表(目前所处于什么数据库,就会查看什么数据库下面的表)
sql
show tables;- 创建表(column_name是字段名,column_type字符的数据类型,comment是备注信息,if not exists可省略)
sql
create table if not exists table_name(
column_name column_type comment '',
column_name column_type comment '',
....
column_name column_type comment ''
)comment '';- 查看表的结构(查看建表语句)
sql
DESC table_name;- 删除表(删除表和表中的数据,和下面的truncate有点区别)
sql
drop table if exists table_name;- 删除表(但是会同时创建一个结构一样,但是没有数据的新表)
SQL
truncate table table_name;- 除此之外还有一些增加表字段,修改表字段的alter语句,这里就不作展示了。
3.2.2 DML语句(增删改)
- 添加数据
sql
-- 插入完整的数据,第一个是插入一行完整数据,第二个是插入多行完整数据
insert into table_name values (xxx,xxx,xxx);
insert into table_name values (xxx,xxx,xxx),(xxx,xxx,xxx),(xxx,xxx,xxx);
-- 插入表中指定字段的数据,可以插入个别字段的数据,也可以把表的所有字段都列出来,相当于上面的插入完整数据
insert into table_name(column_1,column_2....) values (xxx,xxx....);
insert into table_name(column_1,column_2....) values (xxx,xxx....),(xxx,xxx....),(xxx,xxx....);- 修改数据
sql
-- 修改制定字段的值,如果后面不加where条件的话,会修改所有该字段的值,也可以修改多个值
update table_name set column_name = xxxx where 条件
update table_name set column_1 = xxxx , column_2 = xxx where 条件- 删除数据
sql
-- 删除数据,不加where条件就会删除整个表的数据
delete from table_name where 条件3.2.3 DQL语句(查询)
- 简单查询
sql
-- *代表所有数据,这个就是查询全部数据
select * from table_name;
-- 这个是插叙制定字段的数据,如果把全部字段都列出来的话,相当于select *,但是虽然都是查询全部数据,但是有区别
select column_1,column_2 from table_name;
-- 给查询结果起别名
select column_1 as other_name , column_2 as other_name from table_name;
-- as 可以省略,效果一样
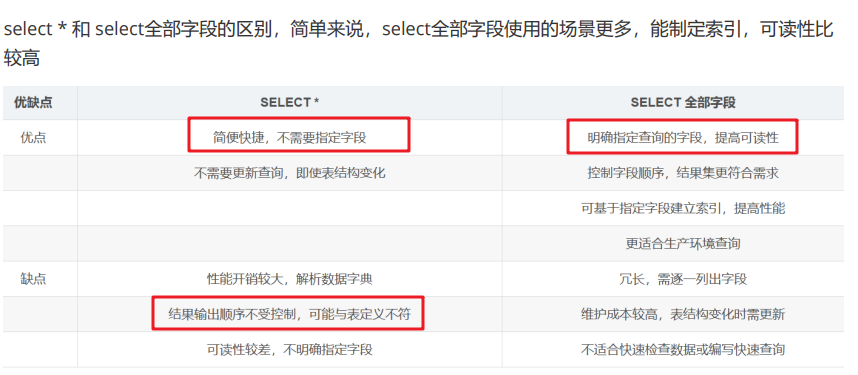
select column_1 other_name , column_2 other_name from table_name; - 简单来说,select * 的话简单便捷,但是可读性较差,他的输出字段顺序取决于定义表时的顺序,较为固定,而且不能起别名。
- select全部字段的话,可以增强可读性,但是不好维护,万一表结构更新,需要改动较大。
- where条件过滤
sql
-- where 条件过滤有多个过滤方式
-- 这里举个例,可以进行大小等值比较
where id > 10;
where id == 10;
where id >=10;
-- 范围查询
where id between 1 and 10;
where id in (1,10);
-- 模糊查询,一般使用字符串字段匹配,例如电话,名字,用法有百分号%和下划线_两种
where name like '张%' -- 匹配张开头的字段,张xx,张x,张xxx,只要是张开头,后面不管是什么就会被匹配上
where name like '%杰' -- 匹配杰结尾的,xx杰,x杰,xxx杰,只要是杰结尾,前面不管是什么就会被匹配上
where name like '%杰%' -- 匹配杰字在中间的,x杰x,只要是杰在中间出现过,前面和后面不管是什么就会被匹配上
where name like '张_' -- 下划线代表占位符,例如这里是查询张x,只能是两个字
where name like '___' -- 下划线代表占位符,例如这里是三个下划线,只能是三个任意的字- 去重distinct
sql
-- distinct关键字能去掉该字段重复的数据,如果是多个字段返回的话,会全部字段都相同才会被当作重复数据
select distinct column_name from table_name; - 聚合函数
sql
-- 聚合函数是Mysql中提供的方便用户调用的函数,其中null值不参加聚合函数的运算
-- 统计这张表的数据行数
select count(*) from table_name;
-- 统计某一字段的和,sum函数的参数只能是一个字段列或者表达式
select sum(column_name) from table_name;
-- AVG()平均数
select AVG(column_name) from table_name;
-- MIN()最小值
select MIN(column_name) from table_name;
-- MAX()最大值
select MAX(column_name) from table_name;- 分组查询
sql
-- 关键字 group by 字段,根据该字段分组,后面可以接having关键字,表示分组后的结果进行条件过滤,有点像where,不过where是针对分组之前,having是针对分组之后
select * from table_name where xxx group by column_name having xxx;- 排序
sql
-- 默认ASC升序(即使不写ASC,也是默认升序),DESC降序
-- 根据某个字段(column_name)升降序展示
select * from table_name order by column_name ASC / DESC;- 分页查询
sql
-- 使用limit关键字,用法为limit(起始行,展示多少行),起始行从0开始计算,例如数组。
select * from table_name limit (0,10); -- 从第1行数据开始,展示10条数据
select * from table_name limit (11,10); -- 从第12行数据开始,展示10条数据-
SQL执行顺序 (如上面所示,介绍的这么多关键字用法,排序、分组、分页等等,全都可以放在一起使用,不过有先后顺序)
- 先是 FROM 关键字,从哪张表中查询数据,
- 然后是 where 过滤
- 然后是 group by 分组和having过滤
- 然后才是 select 挑选返回结果字段
- 然后到 order by 排序
- 最后到 limit 分页

-
也许大家很好奇,执行顺序在这里有什么用吗,其实主要关系到一个别名问题,我们在写SQL时避免不了要给表或者字段起别名,而Mysql有一个规则,当你给表起了别名之后,那么你后续调用这个表就需要使用别名,如下:
sql
-- 例如我有一张表叫做sys_test表
select * from sys_test as s where s.id = 1; -- 正确
select * from sys_test as s where sys_test.id = 1; -- 错误,会报错- 从上面的例子,大家应该能比较直观感受到这个规则,后续的问题引入,执行顺序关系到你能不能调用这个表的别名。大家从上面能知道 from 是先执行的,如果在 from 的时候,我已经给表起了别名,那么后续的where、select使用这个表的时候都要使用表的别名;相反,如果在执行你这个关键字之前,没有人给表起别名,你只能使用表的原名。大家再结合下面的例子好好理解一下:
sql
-- 正常执行顺序,没问题
select age,name from emp where age > 20 order by age ASC limit 5;
-- 由于先执行from 再到where,from时已经为表emp起了别名e,故后续where 使用e.age没问题
select age,name from emp e where e.age > 20 order by age ASC limit 5;
-- 由于先执行where,再到select,所以select时起的别名e_age在where之前没生效,故where处无法生效吗,故错误
select age as e_age , name as e_name from emp where e_age> 20 order by age ASC limit 5;