当数据规模冲破单机极限时,如何设计一个既能平滑扩缩容、又能对业务透明的分布式数据层?从缓存到数据库,虚拟化抽象成为关键架构范式。
一、Tair的启示:虚拟桶如何统一逻辑与物理
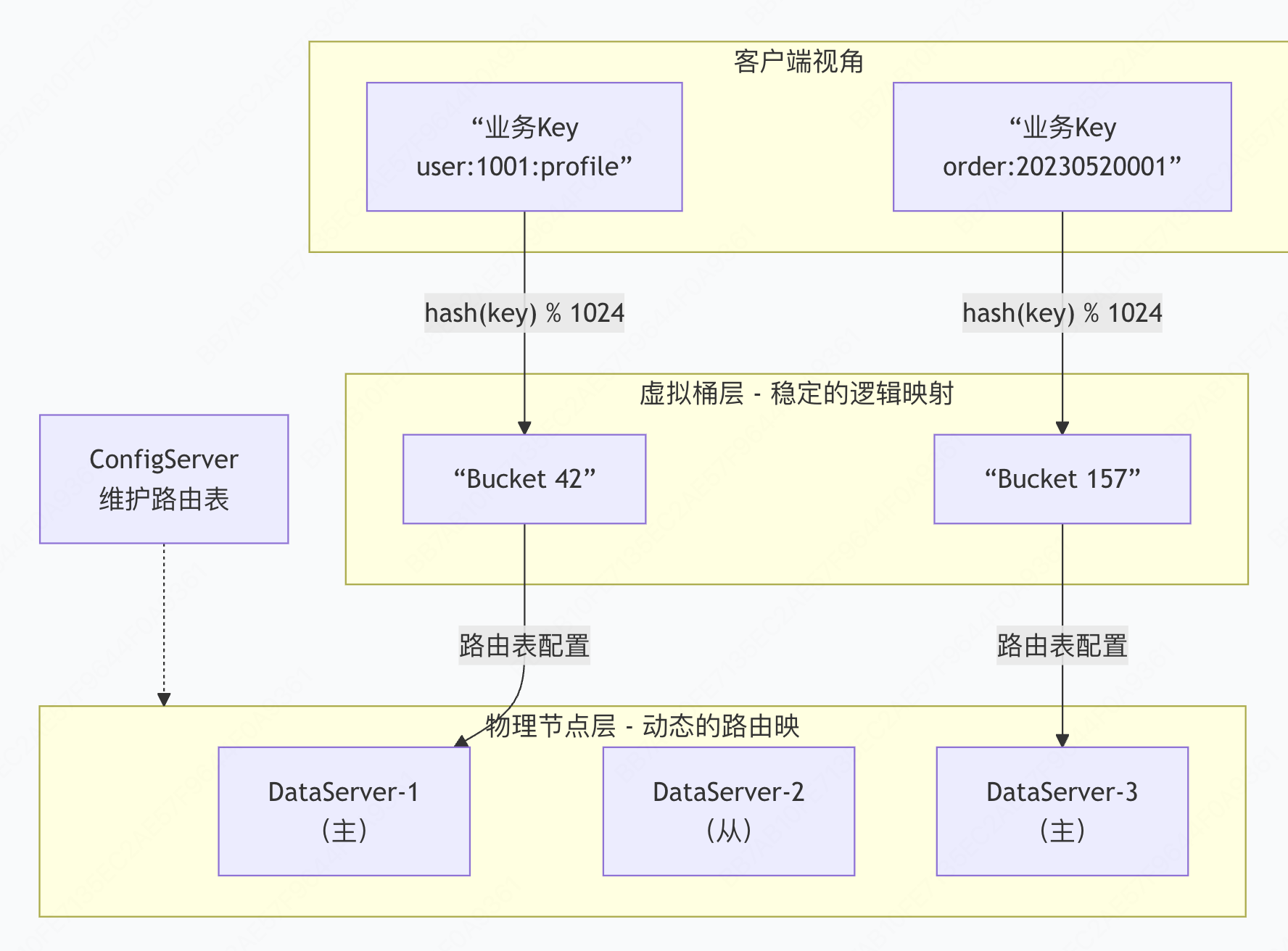
在深入数据库分库分表之前,我们先审视Tair这一分布式缓存系统的经典设计。其核心在于一个巧妙的三层抽象架构,完美解耦了数据逻辑位置与物理存储位置。
1.1 Tair架构核心:数据、桶与节点的三级映射
1. 数据层 (Key-Value Data)
最基础的数据单元,每个键值对承载具体业务信息。如 user:1001:profile -> {"name":"张三", "age":28}。
2. 虚拟桶层 (Virtual Bucket)
Tair设计的精髓所在。整个数据空间被划分为固定数量的逻辑分片(如1024或4096个桶),每个桶是一个逻辑容器 ,通过稳定的哈希函数(如crc32(key) % bucket_count)确定数据与桶的归属关系。这个映射一旦确定永不改变,保证了数据寻址的逻辑稳定性。
3. 物理节点层 (DataServer Nodes)
实际承载数据存储和服务的物理机器。ConfigServer维护着一张动态的路由表 ,记录着每个虚拟桶当前由哪个DataServer主节点负责、哪些从节点备份。
1.2 虚拟桶的核心价值
扩缩容的优雅性:当需要增加节点时,仅需将部分桶从现有节点迁移至新节点。例如从3节点扩至4节点,大约只需迁移1/4的桶,影响面有限且可控。
故障隔离的精细性:单个DataServer故障仅影响其承载的数百个桶,而非半数数据,恢复时可快速将这些桶重新分配到健康节点。
客户端的稳定性:客户端缓存的是"桶→节点"的路由表,而非直接的数据位置。即使底层节点频繁变动,客户端的核心寻址逻辑(Key到桶的映射)也无需改变。
二、数据库分库分表:从原始方案到虚拟化演进
2.1 原始场景:直接分库分表到固定表
在中间件不成熟的早期,业务常采用最直接的方式:应用硬编码分片规则。
sql
-- 根据用户ID直接路由到固定表
String tableName = "user_info_" + (userId % 64);
String sql = "SELECT * FROM " + tableName + " WHERE user_id = ?";
-- 对应物理表
CREATE TABLE user_info_0 (user_id bigint, ...);
CREATE TABLE user_info_1 (user_id bigint, ...);
...
CREATE TABLE user_info_63 (user_id bigint, ...);这种方案的致命问题:
- 业务强耦合:分片逻辑散落在各业务代码中,改动成本高。
- 扩缩容灾难:从64表扩到128表,需要修改所有分片逻辑,并迁移半数数据,几乎等于重做系统。
- 运维黑洞:缺乏统一视角管理分片状态,故障排查困难。
2.2 演进方案:中间件引入逻辑表抽象
现代分布式数据库中间件的核心突破,正是引入了类似Tair"虚拟桶"的逻辑表抽象层。
架构范式转变:
原始模式:应用代码 → 物理表(强绑定)
演进模式:应用代码 → 逻辑表(虚拟) → 物理表(动态绑定)逻辑表的核心特征:
- 对应用透明 :应用操作的是单一逻辑表(如
user_info),无需感知分片。 - 规则可配置:通过配置定义分片键、分片算法(如取模、范围、日期)。
- 动态路由:中间件根据分片键实时计算数据应该路由到哪个物理库表。
java
// 应用视角:操作单一逻辑表
@Mapper
public interface UserMapper {
@Select("SELECT * FROM user_info WHERE user_id = #{userId}")
User selectById(@Param("userId") Long userId);
}
// 中间件内部:自动路由到具体物理表
// 配置规则:user_id % 64 -> ds_${0..15}.user_info_${0..3}
// 当查询user_id=10001时,自动路由到ds_1.user_info_1三、主流中间件实现机制深度解析
3.1 Apache ShardingSphere:嵌入应用层的轻量级方案
设计哲学:将分片能力以SDK形式嵌入应用,追求极致的性能和控制力。
核心组件:
- ShardingSphere-JDBC:在驱动层拦截SQL,重写并路由。
- ShardingSphere-Proxy:独立的代理服务,对应用透明。
实现原理示例:
yaml
# 分片规则配置
rules:
- !SHARDING
tables:
user_info:
actualDataNodes: ds_${0..15}.user_info_${0..3} # 64个物理表
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user_mod_hash
shardingAlgorithms:
user_mod_hash:
type: MOD
props:
sharding-count: 64 # 逻辑分片数 - 相当于Tair的虚拟桶数执行流程:
- SQL解析:解析SQL抽象语法树(AST),提取分片键值。
- 路由计算 :根据分片算法(如
user_id % 64)计算目标分片。 - SQL改写 :将逻辑表名
user_info改写为物理表名user_info_3。 - 执行引擎:通过对应数据源执行改写后的SQL。
- 结果归并:对跨分片查询的结果进行合并、排序、分页等处理。
3.2 Vitess(YouTube/CNCF):代理层的深度方案
设计哲学:在应用与数据库之间构建完整的代理层,提供极致的透明性和功能完整性。
核心概念:VSchema(虚拟Schema)
json
{
"sharded": true,
"vindexes": {
"user_hash": {
"type": "hash" // 哈希分片 - 类似Tair的桶
}
},
"tables": {
"user_info": {
"column_vindexes": [
{"column": "user_id", "name": "user_hash"}
],
"auto_increment": {...}
}
}
}关键技术特性:
- 逻辑分片(Keyspace Shard) :明确引入
-80、80-等分片范围标识,作为可迁移的最小单元。 - 在线重分片(Online Resharding) :
- 基于VReplication在不同分片间同步数据
- 支持双写过渡期,确保数据一致性
- 通过路由规则切换完成流量迁移
- 连接池与查询合并:有效解决MySQL连接数瓶颈,合并相似查询。
3.3 两种路径的对比与选择
| 维度 | ShardingSphere(嵌入式) | Vitess(代理式) | 类比Tair组件 |
|---|---|---|---|
| 架构位置 | 应用进程内(JDBC驱动) | 独立代理进程 | ConfigServer+Client组合 |
| 性能开销 | 极低(无网络跳转) | 有额外网络开销 | 类似直连模式 |
| 语言支持 | Java原生,生态扩展 | 多语言(通过gRPC) | 多语言客户端 |
| 功能完整性 | 分片核心功能强大 | 完整MySQL特性支持 | DataServer功能集 |
| 运维复杂度 | 需各应用单独升级 | 中心化升级,易运维 | ConfigServer集中管理 |
| 典型场景 | Java技术栈,性能敏感 | 多语言混合,需要完整SQL | 缓存与快速访问 |
四、虚拟分片层的通用设计原则
尽管实现各异,但成功的分库分表中间件都遵循着与Tair相似的设计原则:
4.1 稳定逻辑分片空间
java
// 固定逻辑分片数 - 系统设计的基石
public class ShardingConstants {
public static final int LOGICAL_SHARD_COUNT = 1024; // 一旦确定,永不更改
public static int findLogicalShard(long shardKey) {
// 稳定的哈希映射,确保数据永远能找到自己的逻辑分片
return (int) (hash(shardKey) & (LOGICAL_SHARD_COUNT - 1));
}
}4.2 动态物理映射机制
yaml
# 路由配置示例:逻辑分片 -> 物理位置
routing_rules:
logical_shard_0:
datasource: ds_0
physical_table: t_user_00
logical_shard_1:
datasource: ds_0
physical_table: t_user_01
# ... 当需要扩容时,仅修改映射关系
logical_shard_512:
datasource: ds_new # 新数据源
physical_table: t_user_004.3 平滑数据迁移协议
- 增量同步阶段:新老分片同时接收写入,确保数据一致性。
- 路由切换阶段:瞬间切换路由配置,新请求导向新分片。
- 数据清理阶段:异步清理老分片的冗余数据。
五、架构师的选择:何时需要虚拟分片层
5.1 适用场景评估
强烈建议采用:
- 数据量预计超过单机容量70%
- 业务处于快速增长期,需要弹性扩缩能力
- 系统可用性要求高,需避免扩容导致的长时间停机
可暂时规避:
- 数据量小且增长缓慢(< 1TB)
- 业务逻辑极度复杂,强依赖多表JOIN且难以改造
- 团队技术储备不足,无法驾驭分布式系统复杂度
5.2 技术选型建议
初创/中型团队:从ShardingSphere-JDBC开始,技术栈统一,学习成本低,可逐步演进。
大型/多语言团队:考虑Vitess或ShardingSphere-Proxy,中心化管理,对业务侵入小。
云原生环境:优先考虑云厂商托管的分布式数据库服务(如PolarDB分布式版、TiDB),减少自维护成本。
六、总结:虚拟化的力量
Tair的虚拟桶设计揭示了一条分布式数据系统的黄金法则:在易变的物理存储与稳定的业务逻辑之间,必须建立一个持久的虚拟抽象层。
这个抽象层在缓存中叫"虚拟桶",在数据库中叫"逻辑分片"或"逻辑表"。它不仅仅是技术实现细节,更是一种架构哲学:
- 稳定的逻辑视图是系统可维护性的基础
- 动态的物理映射是系统弹性的保障
- 中心化的元数据管理是系统可控的核心
从Tair到分布式数据库中间件,我们看到这一理念在不同数据存储系统中反复验证。作为架构师,理解并应用这一模式,就能在数据规模不断增长的时代,构建出既稳健又灵活的数据架构。
当你的下一个系统面临分库分表的抉择时,不妨先问:我们的"虚拟桶"在哪里? 这个问题的答案,将决定你的系统能否优雅地走向分布式未来。