MySQL事务机制与日志系统详解
一、MySQL事务机制
1. 事务特性(ACID)
| 特性 | 实现机制 |
|---|---|
| 原子性(Atomicity) | undo log回滚,(事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行)。 |
| 一致性(Consistency) | 约束检查+双写缓冲(事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。) |
| 隔离性(Isolation) | MVCC+锁机制(多个事务并发执行时,一个事务的执行不应影响其他事务的执行。) |
| 持久性(Durability) | redo log持久化(一个事务一旦提交,他对数据库的修改应该永久保存在数据库中) |
2. 事务隔离级别
首先需要了解
脏读:读到了其他事务还没有提交的数据。
不可重复读:对某数据进行读取过程中,有其他事务对数据进行了修改(UPDATE、DELETE),导致第二次读取的结果不同。
幻读:事务在做范围查询过程中,有另外一个事务对范围内新增了记录(INSERT),导致范围查询的结果条数不一致。
| 级别 | 脏读 | 不可重复读 | 幻读 | 实现方式 |
|---|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 | 无锁 |
| 读已提交 | 不可能 | 可能 | 可能 | MVCC快照读 |
| 可重复读 | 不可能 | 不可能 | 可能(InnoDB实际避免) | 一致性视图 |
| 串行化 | 不可能 | 不可能 | 不可能 | 读写锁 |
1.查看当前会话隔离级别
select @@tx_isolation;
在MySQL 8.0中:SELECT @@transaction_isolation;
2.查看系统当前隔离级别
select @@global.tx_isolation;
3.设置当前会话隔离级别
set session transaction isolatin level repeatable read;
4.设置系统当前隔离级别
set global transaction isolation level repeatable read;
5.命令行,开始事务时
set autocommit=off 或者 start transaction
一次InnnoDB的update操作,涉及到BufferPool、BinLog、UndoLog、RedoLog以及物理磁盘,完整的一次操作过程基本如下:
1、在Buffer Pool中读取数据:当InnoDB需要更新一条记录时,首先会在Buffer Pool中查找该记录是否在内存中。如果没有在内存中,则从磁盘读取该页到Buffer Pool中。
2、记录UndoLog:在修改操作前,InnoDB会在Undo Log中记录修改前的数据。Undo Log是用来保证事务原子性和一致性的一种机制,用于在发生事务回滚等情况时,将修改操作回滚到修改前的状态,以达到事务的原子性和一致性。UndoLog的写入最开始写到内存中的,然后由1个后台线程定时刷新到磁盘中的。
3、在Buffer Pool中更新:当执行update语句时,InnoDB会先更新已经读取到Buffer Pool中的数据,而不是直接写入磁盘。同时,InnoDB会将修改后的数据页状态设置为"脏页"(Dirty Page)状态,表示该页已经被修改但尚未写入磁盘。
4、记录RedoLog Buffer:InnoDB在Buffer Pool中记录修改操作的同时,InnoDB 会先将修改操作写入到 redo log buffer 中。
5、提交事务:在执行完所有修改操作后,事务被提交。在提交事务时,InnoDB会将Redo Log写入磁盘,以保证事务持久性。
6、写入磁盘:在提交过程后,InnoDB会将Buffer Pool中的脏页写入磁盘,以保证数据的持久性。但是这个写入过程并不是立即执行的,是有一个后台线程异步执行的,所以可能会延迟写入,总之就是MYSQL会选择合适的时机把数据写入磁盘做持久化。
7、记录Binlog:在提交过程中,InnoDB会将事务提交的信息记录到Binlog中。Binlog是MySQL用来实现主从复制的一种机制,用于将主库上的事务同步到从库上。在Binlog中记录的信息包括:事务开始的时间、数据库名、表名、事务ID、SQL语句等。
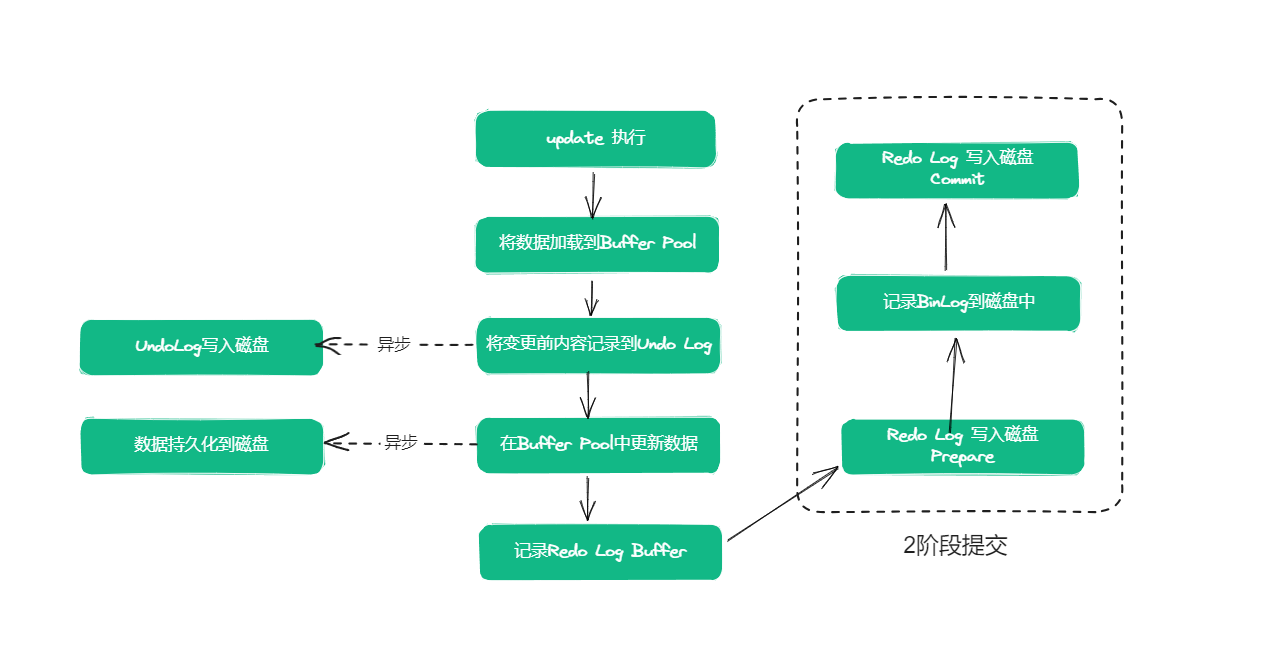
需要注意的是,在binlog和redolog的写入过程中,其实是分成了2阶段的,通过2阶段提交的方式来保证一致性的。
一次insert操作呢:
1、写入undolog,先将事务修改前的数据记录到Undo Log中。
2、写入redolog,处于prepare阶段 (表示事务已修改但未提交)。
3、写入binlog,将binlog 内存日志数据写入文件缓冲区并刷新到磁盘中。
4、写入redolog,处于commit阶段。
二、三大日志系统对比
在MySQL中,redo log和undo log只适用于InnoDB存储引擎,因为要支持事务。而不适用于MyISAM等其他存储引擎。而binlog则适用于所有存储引擎。
1. redo log(重做日志)
Redo Log是MySQL用于实现崩溃恢复和数据持久性的一种机制
作用:
-
确保事务持久性
-
实现WAL(Write-Ahead Logging)机制
-
崩溃恢复时重放已提交事务
特点:
-
物理日志(记录页的修改)
-
循环写入(固定大小文件组)
-
InnoDB引擎特有
配置参数:
innodb_log_file_size = 512M # 单个日志文件大小 innodb_log_files_in_group = 2 # 日志文件数量
2. undo log(回滚日志)
Undo Log则用于在事务回滚或系统崩溃时撤销(回滚)事务所做的修改。Undo Log还支持MVCC(多版本并发控制)机制,用于在并发事务执行时提供一定的隔离性。
作用:
-
事务回滚时恢复数据
-
实现MVCC多版本控制
-
提供一致性读视图
特点:
-
逻辑日志(记录反向SQL)
-
存储在系统表空间或独立undo表空间
-
随事务结束逐渐清理
存储结构:
-- 查看undo表空间 SHOW VARIABLES LIKE 'innodb_undo%';
3. binlog(归档日志)
**用来数据备份、崩溃恢复、主从复制。**主要用来对数据库进行数据备份、崩溃恢复和数据复制等操作
特点:
-
Server层实现(所有引擎通用)
-
逻辑日志(SQL语句或行事件)
-
追加写入(可配置大小)
三种格式:
| 格式 | 写入时机 | 性能 | 安全性 |
|---|---|---|---|
| STATEMENT | 事务提交(SQL 语句的原文) | 高 | 低(导致主从同步的数据不一致) |
| ROW | 事务提交(每个数据更改的具体行的细节) | 低(记录更多的内容) | 高(记录行变化) |
| MIXED | 自动选择 | 中 | 中 |
在RR下,row和statement都可以生效,但是在RC下,只有row格式才能生效。具体见上面我们贴的那个链接的内容。
三、二阶段提交(2PC)
1. 跨日志协调过程
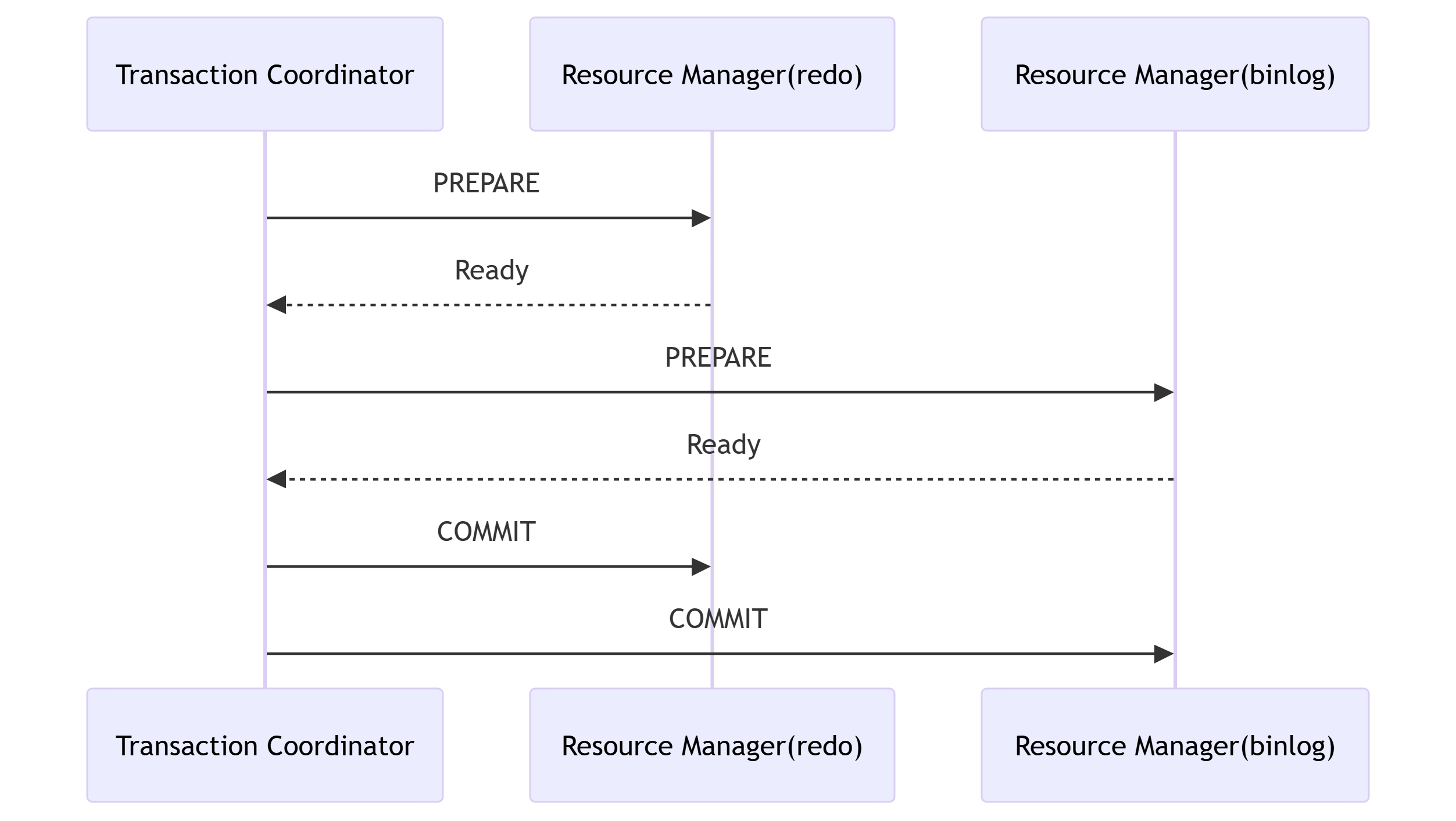
2. MySQL实现流程
-
●Prepare 阶段
○这个阶段 SQL 已经成功执行并生成 redolog,处于prepare阶段
●BinLog持久化
○binlog 提交,通过 write() 将 binlog 内存日志数据写入文件缓冲区;
○通过fsync() 将 binlog 从文件缓冲区永久写入磁盘;
●Commit
○在执行引擎内部执行事务操作,更新redolog,处于Commit阶段write 操作将数据写入文件的缓冲区,这意味着 write 操作完成后,并不一定立即将数据持久化到磁盘上,而是将数据暂时存储在内存中。
fsync 用于强制将文件的修改持久化到磁盘上。它通常与 write 配合使用,以确保文件的修改在 fsync 操作完成后被写入磁盘。
3. 崩溃恢复逻辑
-
binlog无记录:回滚事务(redo prepare但未commit)
-
binlog完整:提交事务(重放redo log)
四、ACID保证机制
1. 原子性实现
// 伪代码:事务执行过程 void execute_transaction() { write_undo_log(); // 记录回滚信息 write_redo_log(PREPARE); execute_sql(); write_binlog(); write_redo_log(COMMIT); // 最终提交 }
2. 隔离性实现
MVCC核心结构:
-
ReadView机制:包含m_ids(活跃事务ID列表),帮我们解决可见性的问题的, 即他会来告诉我们本次事务应该看到哪个快照,不应该看到哪个快照。
-
版本链:通过DB_ROLL_PTR指针串联undo log
可见性判断规则 :基于redaview实现。一个事务,能看到的是在他开始之前就已经提交的事务的结果,而未提交的结果都是不可见的。
●trx_ids,表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
●low_limit_id,应该分配给下一个事务的id 值。
●up_limit_id,未提交的事务中最小的事务 ID。
●creator_trx_id,创建这个 Read View 的事务 ID。
3. 持久性保证
-
redo log刷盘策略:
innodb_flush_log_at_trx_commit = 1 # 每次提交刷盘 -
双写缓冲:防止页断裂
// 写入流程 write_to_doublewrite_buffer(); write_to_data_file();
五、主从复制过程
MySQL 5.6推出基于库级别的并行复制。
可以配置多个库并行进行复制,这意味着每个库都可以有自己的复制线程,可以并行处理来自不同库的写入。这提高了并行复制的性能和效率。
MySQL 5.7推出基于组提交的的并行复制。
它通过将多个事务的提交操作合并成一个批处理操作来减少磁盘IO和锁定开销,从而加速事务的处理,简单来说就是将多个事务的提交操作可以合并成一个批处理操作,以减少磁盘IO次数。
一个组中多个事务,都处于Prepare阶段之后,才会被优化成组提交。那么就意味着如果多个事务他们能在同一个组内提交,这个就说明了这个几个事务在锁上是一定是没有冲突的。换句话说,就是这几个事务修改的一定不是同一行记录,所以他们之间才这样Slave就可以用多个SQL线程来并行的执行一个组提交中的多条SQL,从而提升效率,降低主从延迟。能互不影响,同时进入Prepare阶段,并且进行组提交。
事务的二阶段提交就跟原生的有点区别。因为日志的刷盘过程会因为组提交而需要等待
组提交的二阶段提交
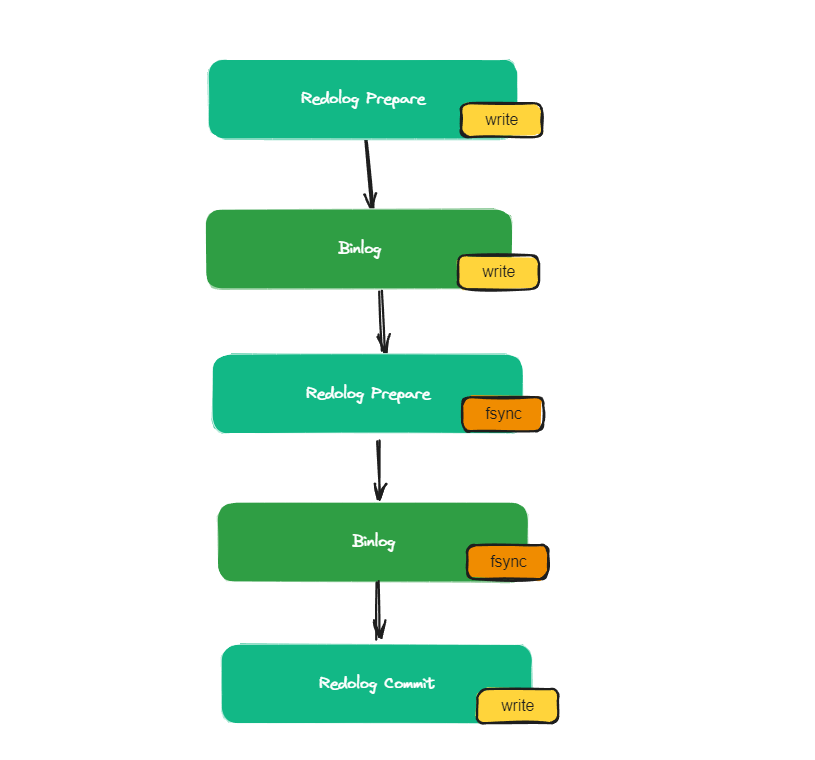
MySQL 8.0 推出基于WRITESET的并行复制。
WriteSet 是通过检测两个事务是否更新了相同的记录来判断事务能否并行回放的,因此需要在运行时保存已经提交的事务信息以记录历史事务更新了哪些行,并且在做更新的时候进行冲突检测,拿新更新的记录计算出来的hash值和WriteSet作比较,如果不存在,那么就认为是不冲突的,这样就可以共用同一个last_committed 、
last_committed 指的是该事务提交时,上一个事务提交的编号。
就这样,就能保证同一个write_set中的变更都是不冲突的,那么同一个write_set就可以并行的通过多个线程进行回放SQL了。
1. 复制原理
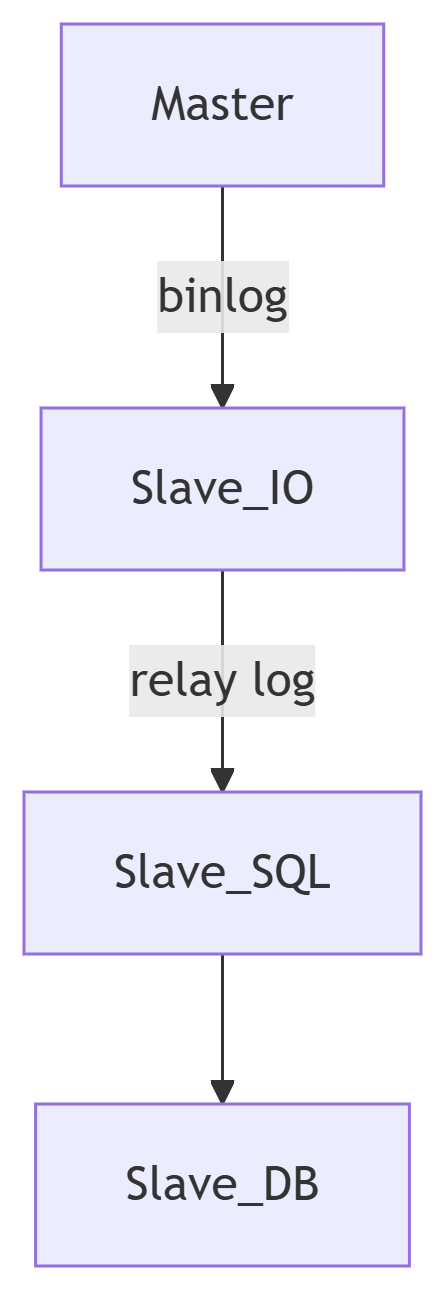
2. 详细步骤
-
主库:
-
事务提交时写入binlog
-
通过dump线程发送事件
-
-
从库:
-
IO线程:拉取binlog到relay log
-
SQL线程:重放relay log中的事件
-
状态报告:
SHOW SLAVE STATUS
-
3. 复制模式
| 模式 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 异步(默认) | 主库不等待从库ACK | 高性能 | 数据可能丢失 |
| 半同步 | 至少一个从库ACK | 平衡性能与安全 | 网络影响性能 |
| 全同步 | 全部从库ACK | 安全性可以保障 | 性能很差 |
4. 配置示例
-- 主库配置 CREATE USER 'repl'@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'; -- 从库配置 CHANGE MASTER TO MASTER_HOST='master_host', MASTER_USER='repl', MASTER_PASSWORD='password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=107; START SLAVE;
5.主从延迟问题
数据库的主从延迟是指在主从数据库复制过程中,从服务器(Slave)上的数据与主服务器(Master)上的数据之间存在的时间差或延迟。
一般来说导致主从延迟可能由多种因素引起,以下是一些常见的原因:
网络延迟:主节点和从节点之间的网络延迟导致复制延迟这是比较常见的一种情况,
从节点性能问题:从服务器的性能不足也可能导致复制延迟。如果从服务器的硬件资源(CPU、内存、磁盘)不足以处理接收到的复制事件,延迟可能会增加。
复制线程不够:当从节点只有一个线程,或者线程数不够的时候,数据回放就会慢,就会导致主从节点的数据延迟。
解决主从延迟主要有几个事情可以做:
优化网络:确保主节点和从节点之间的网络连接稳定,尽量同城或者同单元部署,减小网络延迟。
提高从服务器性能:增加从服务器的硬件资源,如CPU、内存和磁盘,以提高其性能,从而更快地处理复制事件。
并行复制:借助MySQL提供的并行复制的能力,提升复制的效率,降低延迟。
六、关键优化参数
1. 事务相关
transaction-isolation = REPEATABLE-READ innodb_rollback_on_timeout = ON
2. 日志相关
sync_binlog = 1 # binlog刷盘控制 innodb_flush_log_at_trx_commit = 1 # redo刷盘控制 binlog_format = ROW # 推荐使用ROW模式
3. 复制优化
slave_parallel_workers = 4 # 并行复制 slave_preserve_commit_order = ON # 保持事务顺序