目录
[学习使用 strcpy 库函数](#学习使用 strcpy 库函数)
要求使用函数递归实现:接受一个无符号整型值,按照顺序打印他的每一位
函数是什么
在 C 语言里,函数和数学中的函数有相似之处
以数学函数 f(x)=2x+1 为例,当 x 取值不同时,函数会有不同的结果。比如 x=2 时,将 x=2 代入函数可得 f(2)=2×2+1=5;当 x=3 时,代入后得到 f(3)=2×3+1=7
同样,这个数学函数也能用 C 语言中的函数来表示。我们可以定义一个 C 语言函数,让它接收一个参数,在函数内部按照 2x+1 的规则进行计算并返回结果,从而实现与这个数学函数相同的功能
代码演示:
int f(int x)
{
return 2*x + 1;
}
int main()
{
int x = 0;
scanf("%d", &x);
printf("%d\n", f(x));
return 0;
}库函数
在 C 语言里,为了方便使用常用功能,会将这些功能封装成一个个函数,这些函数被称为库函数,像 printf 函数、scanf 函数、strlen 函数等都属于库函数
需要注意的是,C 语言本身并没有直接实现这些库函数,而是制定了 C 语言的标准以及库函数的约定。比如对于 scanf 函数,C 语言标准规定了它的功能、函数名、参数和返回值等
而库函数的具体实现通常由编译器来完成,常见的编译器如 VS2022 编译器、gcc 编译器等,它们会依据 C 语言标准对库函数进行具体的编码实现,这样开发者就能在编程时直接使用这些库函数了
学习使用 strcpy 库函数
C/C++ 中的库函数信息,都可以在 cplusplus.com 网站 上查询到
如果想学习或了解某个库函数的用法、参数含义及功能,直接在这个网站搜索对应的函数名即可,它是编程中查阅库函数的实用资源
strcpy 库函数 
"destination" 代表目的地字符串,"source" 代表源头字符串。当一个函数的返回值类型为 char* 时,意味着该函数返回的是目的地字符串的首地址
strcpy 是一个库函数,从其文档可知,它的功能是进行字符串拷贝。具体来说,就是把源头字符串的数据复制到目的地字符串,并且会覆盖目的地字符串原有的内容,同时还会将源头字符串末尾的结束符 '\0' 也一同复制过去
若要在代码中使用 strcpy 函数,需要包含相应的头文件,头文件代码如下:
#include<string.h>代码演示:
char source[] = "hello world";
char destination[] = "xxxxxxxxxxxxxxxx";
strcpy(destination, source);
printf("%s\n", destination);代码验证:

自定义函数
在编程中,自定义函数 指的是开发者根据实际需求自己编写的函数。它和 C 语言中的库函数(如printf、strlen)一样,都遵循相同的基本结构,包括:
- 返回类型 :函数执行完毕后输出的数据类型(如
int、char*); - 参数:函数执行时需要的输入信息(可以没有参数,也可以有多个);
- 返回值 :通过
return语句返回的结果(若无需返回结果,返回类型为void)
写一个函数能找出两个整数中的最大值
代码演示:
int get_max(int a, int b)
{
return a > b ? a : b;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
int max = get_max(a, b);
printf("%d\n", max);
return 0;
}写一个函数交换两个整型变量的内容
代码演示:
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
printf("交换前:a = %d;b = %d\n", a, b);
Swap(&a, &b);
printf("交换后:a = %d;b = %d\n", a, b);
return 0;
}在编写函数交换两个整型变量的值时,不能直接传递实参。这是因为在函数调用时,实参的值会被复制给形参,实参和形参分别占用不同的内存空间,也就是各自独立的空间。在函数内部对形参进行操作,只会改变形参的值,而不会影响到实参原本的值
为了真正实现交换两个实参的值,我们需要传递实参的地址。由于实参是 int 类型,所以函数的形参要使用 int* 类型来接收这些地址。int* 类型的变量可以存储整型变量的地址。在函数内部,通过 * 这个解引用关键字,我们可以根据存储的地址找到对应的实参,进而对实参的值进行修改,这样就能实现两个实参值的交换
牛刀小试
写一个函数判断一个整数是否是素数
代码演示:
int is_prime(int tmp)
{
if (tmp <= 1)
return 0;
for (int i = 2; i <= sqrt(tmp); i++)
{
if (tmp % i == 0)
return 0;
}
return 1;
}
int main()
{
int input = 0;
scanf("%d", &input);
if (is_prime(input))
printf("is prime\n");
else
printf("not is prime\n");
return 0;
}代码解析:
我们要编写一个函数来判断一个整数是否为素数。素数是指大于 1 且只能被 1 和自身整除的正整数。所以在判断之前,首先要排除小于等于 0 的整数,因为它们显然不符合素数的定义
该函数的返回规则是:返回 0 表示这个数不是素数,返回 1 表示这个数是素数
对于输入的变量 input,我们需要判断它是否为素数。判断的方法是,用 input 对 2 到 input - 1 之间的数进行取模运算。可以使用 for 循环来遍历这个区间内的所有数。如果在遍历过程中,input 对某个数取模的结果为 0,那就说明 input 除了 1 和它本身之外,还能被其他数整除,那么它就不是素数,此时函数直接返回 0
不过,其实并不需要从 2 遍历到 input - 1,只需要遍历 2 到 sqrt(input)(sqrt 是开平方函数)之间的数即可。这是因为如果一个数 input 不是素数,那么它一定可以分解为两个因数 m 和 n,即 input = m * n,其中 m 和 n 中至少有一个小于等于 sqrt(input)。所以,只要检查到 sqrt(input) 就可以判断 input 是否为素数了
如果 for 循环执行完毕都没有找到能整除 input 的数,那就说明 input 只能被 1 和它本身整除,即 input 是素数,此时函数返回 1
写一个函数判断某一年是否是闰年
代码演示:
int is_leap_year(int year)
{
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0))
return 1;
else
return 0;
}
int main()
{
int year = 0;
scanf("%d", &year);
is_leap_year(year);
if (is_leap_year(year))
printf("is leap year\n");
else
printf("not is leap year\n");
return 0;
}代码解析:
闰年的判断规则是能被 4 整除但不能被 100 整除,或能被 400 整除的年份
根据以上的规则编写出对应的逻辑代码,就能判断某一年是否是润年
写一个函数,实现一个整型有序数组的二分查找
代码演示:
int binary_search(int* parr, int size, int number)
{
int left = 0;
int right = size - 1;
while (left <= right)
{
int mid = (left + right) / 2;
if (parr[mid] < number)
{
left = mid + 1;
}
else if(parr[mid] > number)
{
right = mid - 1;
}
else
{
return mid;
}
}
return -1;
}
int main()
{
int arr[] = { 1,2,4,6,7,9,12,32,45,77,90 };
int size = sizeof(arr) / sizeof(arr[0]);
int input = 0;
scanf("%d", &input);
int ret = binary_search(arr, size, input);
if (ret == -1)
printf("number not found\n");
else
printf("number index is: %d\n", ret);
return 0;
}代码解析:
我们要实现一个二分查找函数,二分查找是一种高效的查找算法,它的前提是数组必须是有序的。在函数调用时,需要传递三个参数:数组的指针 arr,用于访问数组元素;数组的元素个数 size,这样能确定查找范围;要查找的整数 input,即我们要在数组中找到的目标值
函数的返回值规则是:如果在数组中找到了目标值 input,就返回该值在数组中的下标;如果没有找到,就返回 -1,因为数组的下标最小是从 0 开始的, -1 可以作为一个明确的未找到的标识
- 初始化查找范围 :定义两个变量,
left作为左下标,初始值设为 0,它指向数组的起始位置;right作为右下标,初始值设为size - 1,它指向数组的末尾位置 - 开始循环查找 :使用
while循环来进行查找,循环的条件是left <= right。只要满足这个条件,就说明还有元素没有被检查过,查找过程可以继续 - 计算中间下标 :在每次循环内部,计算中间元素的下标
mid,计算公式为mid = (left + right) / 2。通过这个中间下标,我们可以将数组分成两部分 - 比较中间元素与目标值 :
- 如果
input大于中间元素arr[mid],说明目标值在数组的右半部分,此时更新left为mid + 1,缩小查找范围到右半部分 - 如果
input小于中间元素arr[mid],说明目标值在数组的左半部分,此时更新right为mid - 1,缩小查找范围到左半部分 - 如果
input等于中间元素arr[mid],说明已经找到了目标值,直接返回mid,也就是目标值在数组中的下标
- 如果
- 未找到目标值 :如果
while循环结束后还没有找到目标值,说明目标值不在数组中,此时返回 -1 即可
函数的嵌套调用
在编程中,当我们定义了多个函数后,有时会需要在一个函数的执行过程中,调用另一个函数来完成特定任务。这种 在一个函数内部调用另一个函数的方式,就是函数的嵌套调用
代码演示:
void print()
{
printf("hello world\n");
}
void three_print()
{
for (int i = 0; i < 3; i++)
{
print();
}
}
int main()
{
three_print();
return 0;
}在 three_print 函数中调用了 print 函数,这就是函数的嵌套调用
函数的链式访问
函数的链式访问是一种编程技巧,它指的是将一个函数的返回值直接作为另一个函数的参数来使用
代码演示:
printf("%d\n", strlen("abcdef"));把 strlen 函数的返回值作为 printf 函数的参数,这就是函数的链式访问
函数的链式访问可以让代码更加简洁和紧凑,避免创建中间变量。不过,在使用链式访问时也要注意代码的可读性,如果链式访问的函数过多,可能会让代码变得难以理解和调试。所以,在实际编程中要根据具体情况合理使用函数的链式访问
一段有趣的代码
代码演示:
printf("%d", printf("%d", printf("%d", 43)));问:最后在控制台上输出的结果是多少?
需明确 printf 函数的返回值为其输出的字符个数:
如:printf("%d", 1); 的返回值就是 1,printf("%d", 123); 的返回值就是 3
具体执行过程如下:
- 执行最内层
printf("%d", 43),会先在控制台输出43(共 2 个字符),返回值为2 - 中间层
printf("%d", 2)接收内层返回值,输出2(1 个字符),返回值为1 - 最外层
printf("%d", 1)接收中间层返回值,输出1(1 个字符)
综上,控制台输出结果为 4321
代码验证: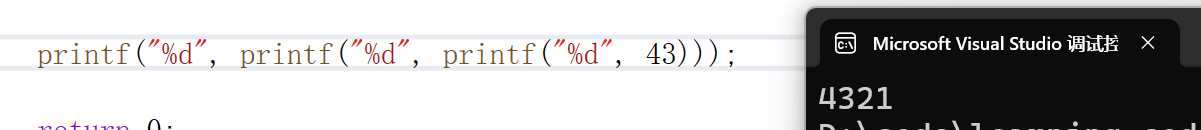
函数的声明、调用和定义
函数的定义
int Add(int a, int b)
{
return a + b;
}函数 Add 的功能为计算两个整数的和,其定义是实现该功能的具体代码逻辑,即通过设定参数接收两个整数输入,在函数体内执行加法运算,并将运算结果作为返回值输出,从而完成两个整数相加功能的程序实现
函数调用
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
int sum = Add(a, b);
printf("%d\n", sum);
return 0;
}在 main 函数里使用 Add 函数的操作,在编程中被称作函数调用,此操作可触发 Add 函数执行其预设功能
函数声明
// 函数声明
int Add(int a, int b);
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
// 函数调用
int sum = Add(a, b);
printf("%d\n", sum);
return 0;
}
// 函数定义
int Add(int a, int b)
{
return a + b;
}在 C 程序设计中,若自定义函数的定义位于 main 函数之后,则需在 main 函数执行前进行函数声明
这是由于程序遵循从上至下的执行逻辑,编译器在处理 main 函数时若未预先知晓自定义函数的存在,会因无法识别函数名称而报错
按照模块化编程规范,函数声明通常被放置在头文件(.h)中,用于告知编译器函数的参数类型和返回值类型;而函数的具体实现(定义)则集中存储在对应的源文件(.c)中,这种分离式设计有助于代码的组织、维护及复用,确保程序在编译阶段能够正确解析函数调用关系
函数递归
什么是递归
递归是函数直接或间接调用自身的编程方式。需定义基线条件(终止递归的条件)和递归条件(逐步逼近基线的逻辑),通过重复调用解决可分解为相似子问题的任务
递归的核心思维在于:把大事化小
递归的两个必要条件
- 基线条件(终止条件):必须存在至少一个无需递归调用的终止条件,用于退出递归过程,避免无限循环;
- 递归条件:函数需通过自身调用逐步分解问题,且每次递归调用必须更接近基线条件,确保问题规模递减直至满足终止条件
一个简单的递归
int main()
{
printf("hello\n");
main();
return 0;
}若 main 函数直接调用自身,构成直接递归。由于该递归未设置基线条件(终止条件),程序会无限次递归调用自身,导致调用栈不断增长
当栈空间被耗尽时,将引发栈溢出错误,造成程序异常终止。这一现象体现了递归中终止条件的必要性 ------ 缺少该条件会破坏递归的收敛性,最终导致内存资源耗尽
牛刀小试
要求使用函数递归实现:接受一个无符号整型值,按照顺序打印他的每一位
例如:
输入:1234 ;输入:1 2 3 4
代码演示:
void print_every_one(int n)
{
if (n > 9)
{
print_every_one(n / 10);
}
printf("%d ", n % 10);
}代码解析:
该函数实现按顺序打印无符号整数每一位的功能,核心通过数学运算 %10(取个位)和 /10(去除个位)分解数字,并结合递归逐层处理
算法思路:
数字分解原理:
- 对于任意整数
n,n % 10可获取其个位数字(如123 % 10 = 3) n / 10可去除个位,得到高位数字(如123 / 10 = 12)
通过重复这两步,可逐位拆解整数的每一位
递归过程分析(以 n = 123 为例):
首次调用与递归展开
- 初始调用
print_every_one(123),因123 > 9,触发递归调用print_every_one(123 / 10 = 12) - 第二次调用
print_every_one(12),因12 > 9,继续递归调用print_every_one(12 / 10 = 1)
基线条件触发(递归终止)
- 第三次调用
print_every_one(1),此时1 <= 9,不满足递归条件,跳过if语句,直接执行printf("%d ", 1 % 10),输出 1
逐层返回与后续打印
- 返回上一层(第二次调用,
n = 12),执行printf("%d ", 12 % 10),输出 2 - 再返回初始层(首次调用,
n = 123),执行printf("%d ", 123 % 10),输出 3
最终输出结果
控制台按递归返回顺序打印 1 2 3,实现从高位到低位的顺序输出
核心逻辑总结:
- 递归特性 :通过不断将问题规模缩小(
n / 10),直至满足基线条件(n <= 9)时终止递归,再逐层返回处理当前层的打印逻辑 - 执行顺序:递归调用时先处理高位(通过不断剥离个位),返回时再依次打印低位,利用调用栈的后进先出特性,自然实现从高位到低位的顺序输出
要求写一个函数:能实现求字符串的长度
代码演示:
int my_strlen(const char* s)
{
int count = 0;
while (*s != '\0')
{
count++;
s++;
}
return count;
}代码解析:
此函数 my_strlen 用于计算字符串的长度。参数 s 是一个指向字符串首字符的指针
在 C 语言里,字符串以 '\0' 作为结束标志。函数利用 while 循环来遍历字符串,只要当前指针 s 所指向的字符不是 '\0',就表明还有字符需要统计
在循环内部,count 变量用于统计字符串中字符的数量,每统计一个字符,count 的值就加 1。同时,指针 s 通过 s++ 操作指向下一个字符,从而实现对字符串的逐字符遍历
当 s 指向 '\0' 时,意味着已经遍历完整个字符串,此时循环结束,count 变量中存储的数值就是字符串中字符的总个数,也就是该字符串的长度,最后将其作为函数的返回值返回
编写函数,不允许创建临时变量,求字符串的长度
代码演示:
int my_strlen(const char* s)
{
if (*s == '\0')
return 0;
return 1 + my_strlen(s+1);
}代码解析:
函数参数与返回值
该函数接受一个指向 const char 类型的指针 s 作为参数,const 表明此指针指向的字符串内容不能被修改。函数返回一个 int 类型的值,即字符串的长度
递归终止条件
在函数内部,首先会检查指针 s 所指向的字符是否为 '\0'。在 C 语言中,字符串以 '\0' 作为结束标志。如果当前字符是 '\0',则意味着已经到达字符串的末尾,此时函数将返回 0。这是递归的终止条件,它确保了递归调用不会无限进行下去,避免出现栈溢出的错误
递归调用逻辑
若当前字符不是 '\0',说明还未遍历完整个字符串。函数会将指针 s 向后移动一位(s + 1),使其指向下一个字符,然后再次调用 my_strlen 函数,以计算从下一个字符开始的子字符串的长度。由于当前字符也是字符串的一部分,所以在递归调用返回的结果上加 1,表示当前字符的长度。最终将这个累加后的结果作为当前字符串的长度返回
递归调用示例
假设传入的字符串为 "abc",递归调用过程如下:
- 第一次调用
my_strlen("abc"),当前字符为'a',不是'\0',则进行递归调用1 + my_strlen("bc") - 第二次调用
my_strlen("bc"),当前字符为'b',不是'\0',继续递归调用1 + my_strlen("c") - 第三次调用
my_strlen("c"),当前字符为'c',不是'\0',再次递归调用1 + my_strlen("") - 第四次调用
my_strlen(""),此时当前字符为'\0',满足终止条件,返回 0 - 返回到第三次调用,
my_strlen("c")返回1 + 0 = 1 - 返回到第二次调用,
my_strlen("bc")返回1 + 1 = 2 - 返回到第一次调用,
my_strlen("abc")返回1 + 2 = 3
通过这种递归的方式,函数逐步缩小问题规模,直到满足终止条件,最终计算出整个字符串的长度