
传输层TCP协议的确认应答,超时重传机制
TCP报文格式
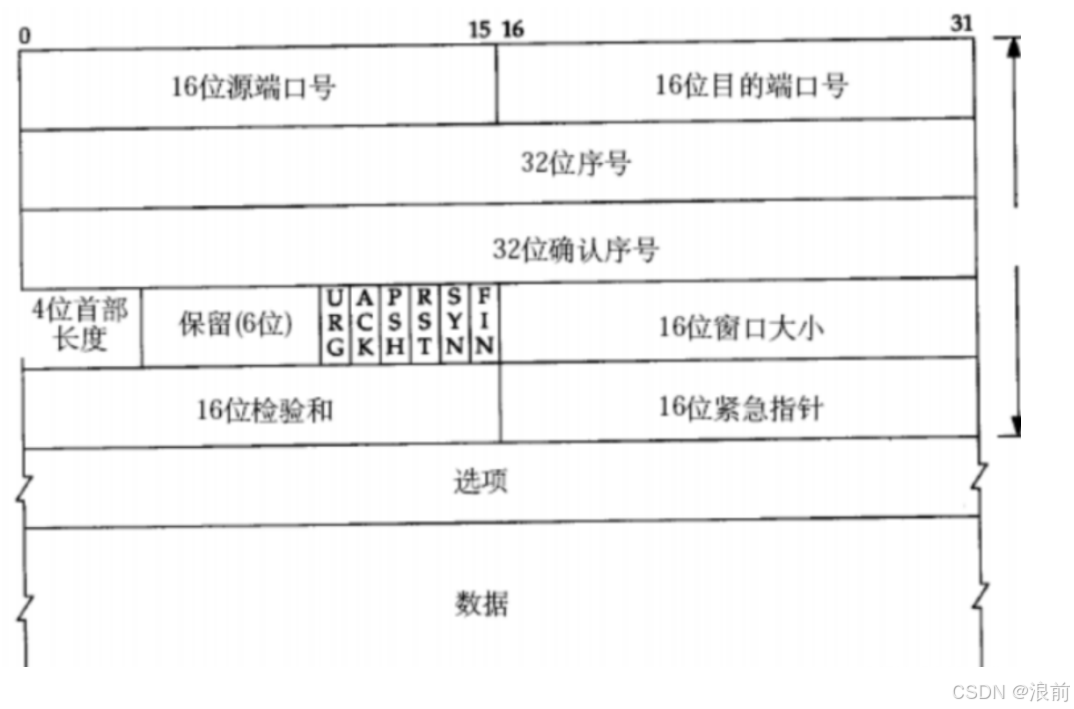
4位首部长度(报头长度)
这个报头长度一共是4个比特位 ,虽然UDP的报头长度是固定的
但是TCP的报头长度是不固定的,长度是可变的
为什么TCP的报头长度是可变的?
因为在TCP的报头中的前20个是固定的长度,但是20个之后的就是属于选项部分
这个选项就是opitional:选项表示可有可无的,所以选项这一部分是可变化的,可以有多个,可以有一个,可以没有
TCP的报头长度是不固定的,报头最短是20字节(没有选项),报头最长是60字节(选项最多是40字节)
同时TCP的报头是4个比特位的,相当于是0~15这16个数字,那么如何表示60呢?
其实TCP在这里有一个很巧妙的设定:
在TCP报头中的单位是4个字节,不是一个字节/字节,选项都是4字节一个单位的,出现的只能是4的倍数:比如4字节,8字节,12字节,16字节等等,不可能出现1字节,2字节...
TCP报头长度一共是4个比特位,那么就相当于是4 乘以4个字节才是TCP的真实比特位
即如果表示出的数字是15 ,那么就应该乘以4,那么TCP数据报头的真实长度就是60
保留位(reserved)
TCP中一共有6个保留位。
TCP中保留位的作用:
在UDP中的报头的大小是已经固定死的,只能是2个比特位
不能改变和扩展
这样UDP协议这样的特性会有一个不好的缺点:
如果UDP一旦发生了扩展的操作,改变了报头的长度,那么就会导致机器在发送UDP数据的时候,在接收UDP数据接收端机器不兼容这个数据,会导致通信失败。
所以TCP就吸取了UDP的教训:
TCP的保留位就是提前准备好的位置,现在TCP不使用这个保留位
让这个保留位先在报头中占据好位置,但是现在先不用
等到后面当TCP 需要进行报头的扩展操作的时候才去使用这个保留位,这样就可以避免出现扩充了TCP的报头之后出现数据不兼容的问题,防止出现通信中断的问题
6个标志位
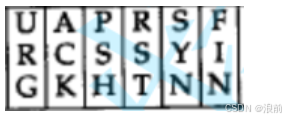
上图就是TCP报头中的六个标志位,后续会慢慢展开,这里先暂时不讲解。
16位检验和
16位检验和相当于UDP中的校验和
这个16位检验和是如何计算的?
把TCP中的报头和载荷加在一起,计算出一个校验值,根据这个校验值去判断传输过来的数据是否发生了比特翻转,是不是错误的数据
TCP协议一共是有如下特性:
- TCP是有连接的
- TCP是可靠传输的
- TCP是全双工的
- TCP是面向字节流的
可靠传输
可靠传输的定义:
发送方发出去数据之后,能够知道接收方是否收到数据,
一旦发现接收方没有收到,可以立马采取一系列的手段来补救
注意,这里的可靠传输不是保证一定可以传输成功
如何实现可靠传输
确认应答
发送方,把数据发送给接收方之后,接收方收到数据就会给发送方返回一个 应答报文(acknowledge),简称ack
发送方如果收到了这个应答报文ack,就知道自己的数据发送成功了
序号与确认序号

序号和确认序号存在的意义:
在网络中有着后发先至的问题出现,所以就引入了序号和确认序号来解决这个后发先至的问题
我们针对数据进行编号后,当应答报文接收到数据之后,就会对发送端说明清楚接收/应答的是哪一个数据
然而在实际的网络传输过程中会是比较复杂的
我们的TCP 是面向字节流进行传输的,以字节流为单位进行传输的
数据不是一条一条的数据进行传输的
所以TCP将每个字节的数据都进行了编号:
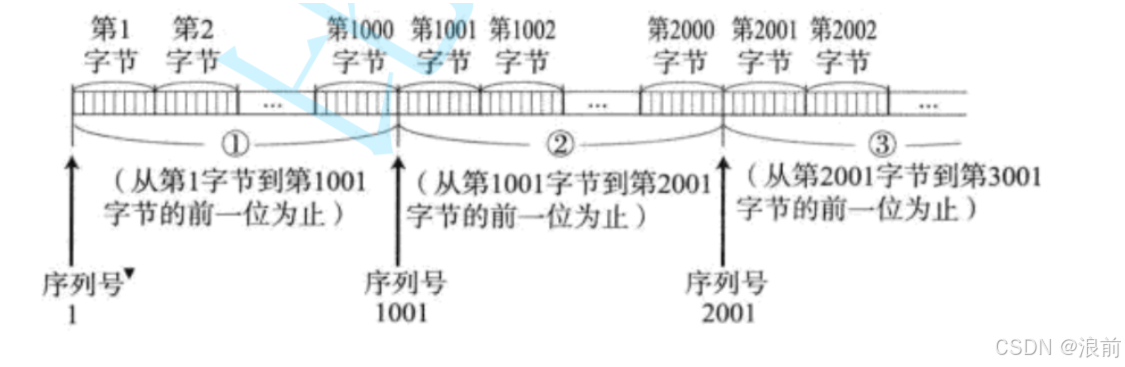
序号的编号方式
在实际的TCP中是按照字节为单位进行编号的
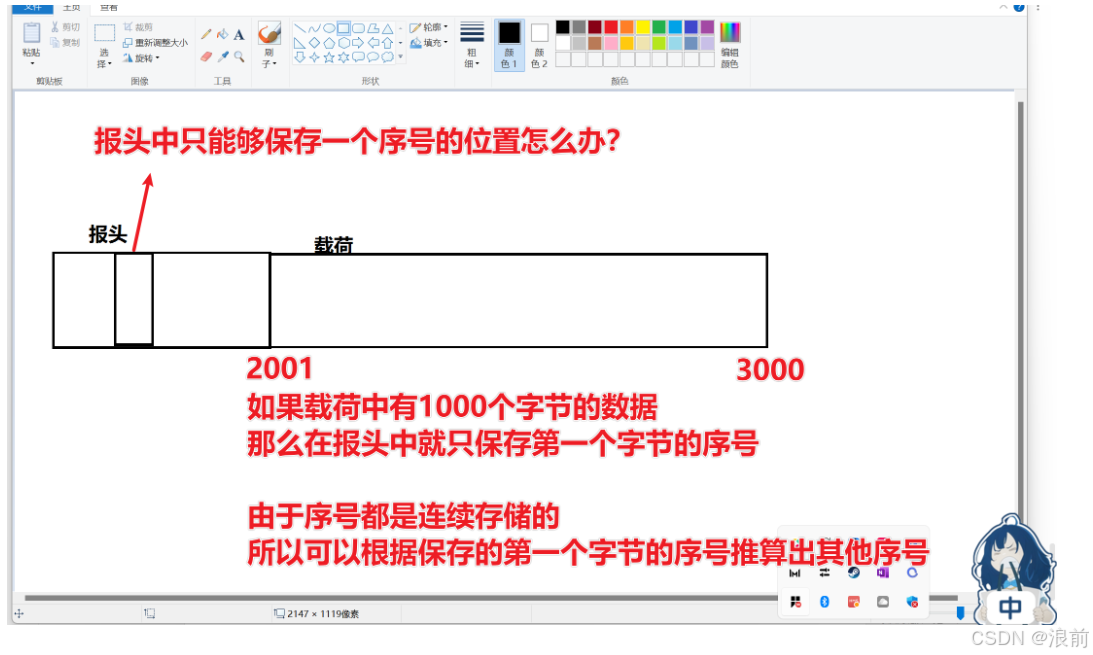
确认序号的编写方式
确认序号的位置是在应答报文中
确认序号的编写方式按照发送端的最后一个字节数据的序号 加一来进行确认序号的编写
下图所示:
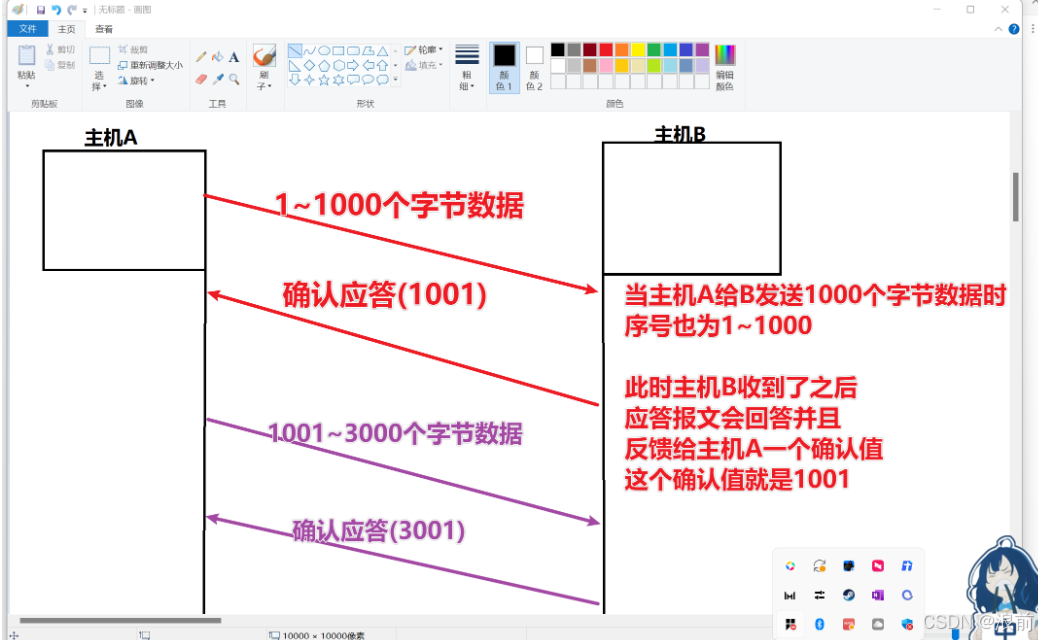
应答报文(ACK)
ACK的定义:
应答报文也叫做ACK报文,Acknowledge(应答)
在上图中的应答报文ACK的确认值有两层含义:
- 主机B已经收到了小于确认值的所有字节数据
- 下一次发送的字节数据从序号1001之后的数据开始发送
ACK的目的
通过特殊的ACK数据包,里面携带的确认序号来告诉发送方,哪些数据已经确认收到了,此时发送方就知道数据是否发送成功了(可靠传输)
注意:
TCP的确认应答机制是TCP可靠传输的最核心机制
TCP的三次握手不是TCP可靠传输的最核心机制
确认应答机制依靠一个应答报文ACK
应答报文发送反馈给发送端一个确认值:来表示接受方正确接收到了数据
如何区分ACK
由于接收端和发送端会进行网络数据传输
既然接收端会返回一个ACK的应答报文
那么如何区分一个数据包是一个普通的数据,还是一个应答报文?
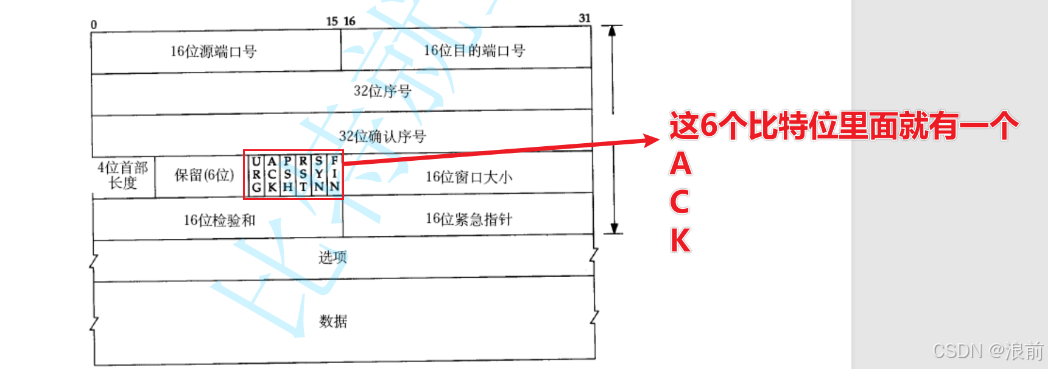
通过标志位来区分
通过TCP报头中的六个标志位,其中有一个标志位就是ACK:
当这个ACK为1的时候,说明这个数据包就是一个应答报文
当这个ACK为0 的时候,说明这个数据包就是一个普通报文
如下所示:
超时重传
TCP的超时重传机制是确认应答的补充机制
如果在网络传输过程中一切顺利
那么应答报文会返回给发送方一个ACK来表示数据已经成功收到
但是如果在网络传输过程中发生了丢包,那么就不会有应答报文了,此时就使用超时重传来对确认应答进行补充。
什么是丢包
我们的网络传输结构如下所示:
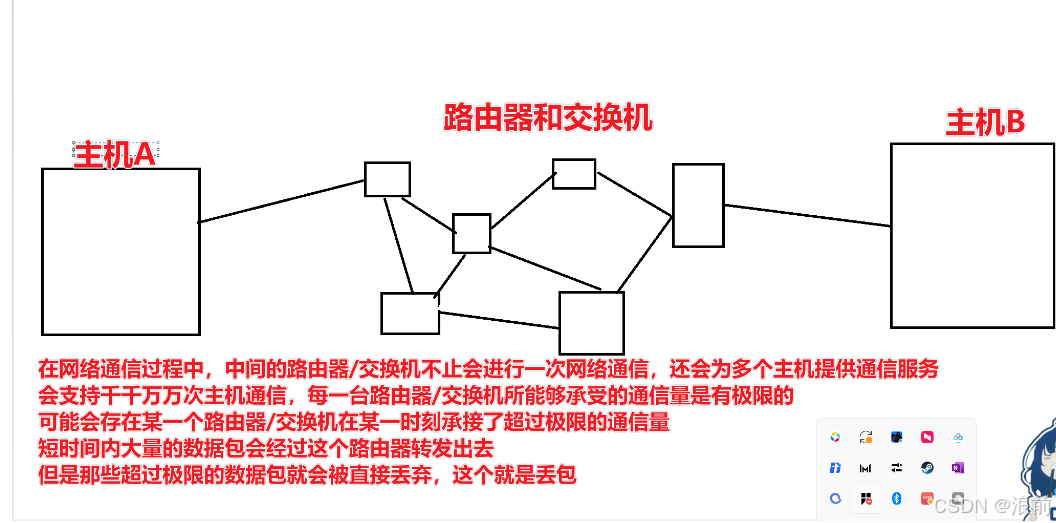
丢包的定义
丢包是因为在网络通信过程中,网络传输的数据会经过很多的路由器和交换机进行转发
此时如果在短时间内一个路由器接收到超过自身极限的数据包
那么路由器就会把多余的,超过自身极限的数据包丢弃掉,这个过程就是丢包。
而且丢包的情况是客观存在而且无法避免,难以预测的,所以丢包的情况无法彻底解决
但是我们可以使用TCP的可靠性来对抗丢包的情况,尽可能的把数据包给传输过去
如果真的出现了丢包的情况,就可以使用TCP协议的超时重传的机制来对抗丢包
超时重传
超时重传的定义:
当主机A给主机B发送数据之后,会等待一段时间,而且这个等待时间是有上限的
在等待的这一段时间里面,如果主机A接收到了主机B回馈的应答报文(ACK),那么就说明没有发生丢包
但是如果超过了等待时间的上限,主机A还没收到ACK,那么判断发生了丢包,此时主机A就会重新再发一次数据包给主机B
这个就是超时重传机制
但是在这其中有一个问题:
只要主机A没有接收到应答报文,那么就直接判断主机B没有接收到数据,此时主机A就直接又发了一遍数据包。
这个逻辑是有问题的,因为丢包是有两种情况的:
丢包的两种情况
丢包的发生情况是分为两种的:
第一种丢包的情况:数据包在传输的过程中丢失了
第二种丢包的情况: 是主机B成功地接收了数据包,但是主机B在返回ACK的时候,ACK丢失了,主机A没有收到ACK
而且如果真的发生了丢包,发送方是无法区分出是哪一种丢包情况的,所以只要出现了丢包,就会进行重传。
如下图所示:
这是第一种情况,数据包在传输的过程中丢失了:
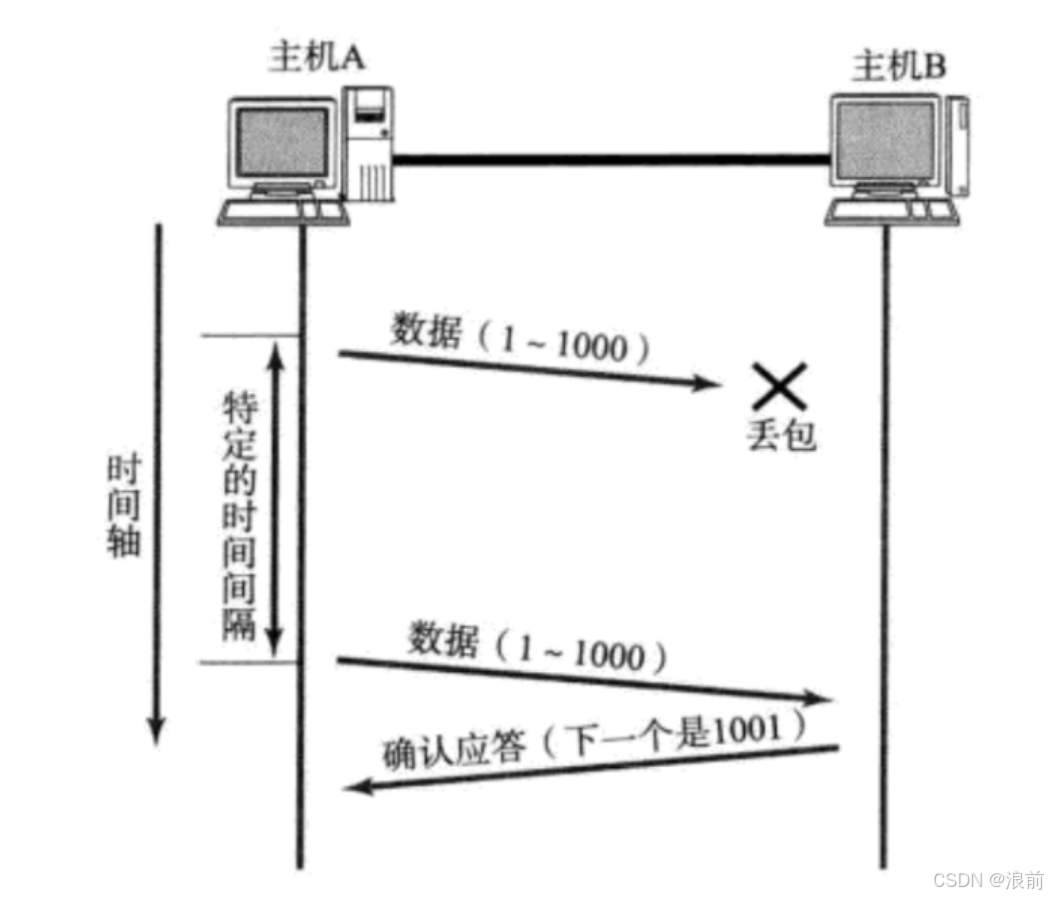
这是第二种情况:
主机B成功地接收了数据包,但是主机B在返回应答报文的时候,应答报文丢失了
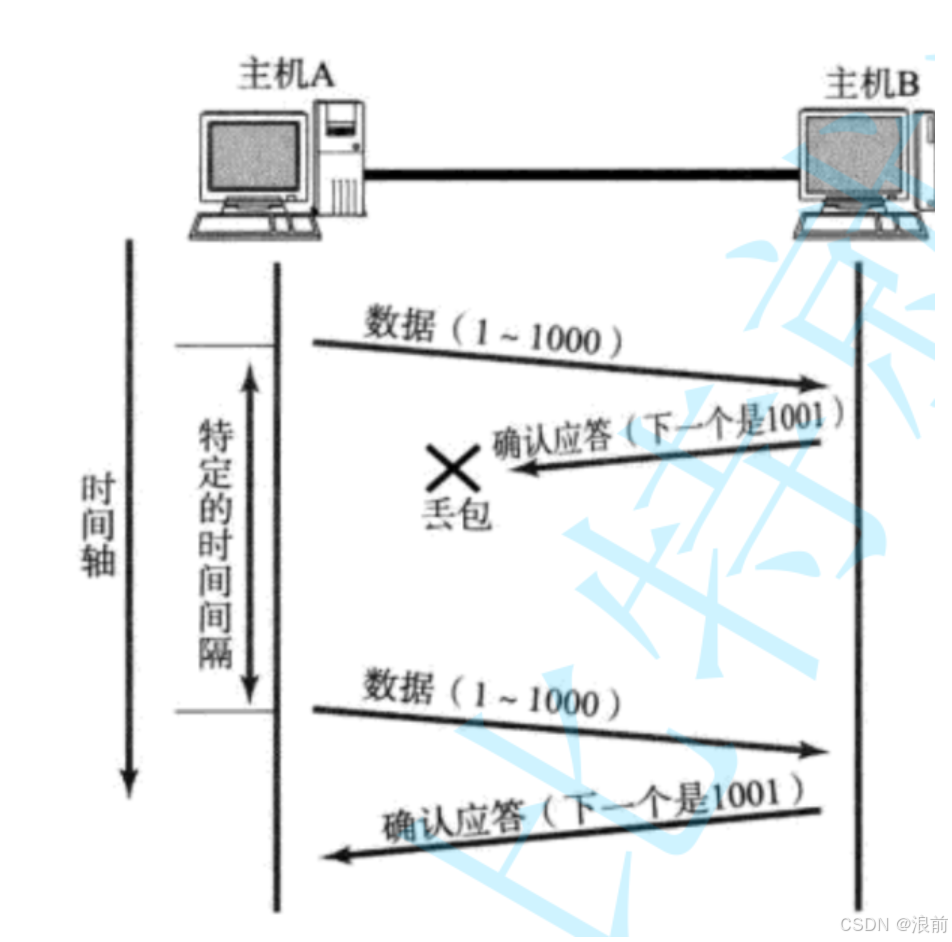
如果是第二种情况的丢包,那么主机A又会给主机B发送一遍数据包
此时主机B会接收到两个重复的数据包,万一这个数据报的请求是扣款请求呢,那岂不是要被连续扣款两次?
那么TCP是如何解决上述问题的呢?
此时就引入了内存缓冲区的概念了。
内存缓冲区(接收缓冲区)
位置
针对上述的丢包问题,其实在TCP Socket的内核中有一个内存缓冲区(一块内存空间),也就是在TCP中有一个"接收缓冲区"
作用
当主机A发送数据到达主机B的时候,是先到达主机B内核中的一个名叫内存缓冲区的空间当中
只有当应用程序调用read/Scanner.next的时候,才可以从内存缓冲区中读取出数据
所谓的读操作本质就是读取内存缓冲区
当数据到达主机B的内存缓冲区的时候,会先对数据进行一个判断
判断传过来的这个数据是否已经在内存缓冲区中已经有了
或者曾经在内存缓冲区中存在过。
如果数据已经在缓冲区中有了,或者曾经存在过,那就直接将这个数据丢弃掉
此时这个内存缓冲区就可以保证应用程序在调用read/Scanner.next读操作的时候
不会读取到重复的数据,也就解决了刚才丢包的问题,避免了应用程序会出现二次扣款的操作
如何判断数据重复
在内存缓冲区里面是如何判断数据是否重复?
根据传输过来的数据的序号
因为每一个传输过来的数据是字节,每一个字节数据都有序号,而且序号是连续的。
所以判断刚刚传输过来的新数据是不是重复数据
依据就是判断新数据的序号是否与缓冲区里面的旧数据的序号重复了
此时一共有两种情况出现:
- 旧的数据已经在缓冲区,旧数据还没有被应用程序给读取走,此时根据新数据的序号来判断是否重复即可
- 旧的数据不在缓冲区,旧的数据已经被应用程序读取走了,此时在缓冲区里已经无法查到这个数据了
面对面对第二种情况的出现,其实我们的TCP API已经解决好了这个问题:
接收方的缓冲区其实可以看成一个以序号为优先级的阻塞队列
这个优先级队列的运行逻辑如下:
当所有的数据都到达缓冲区之后,会在这个缓冲区里面按照序号,从小到大进行排列,这样也解决了后发先至的问题
当应用程序在缓冲区里面进行读取数据的时候,此时读取的都是已经按照序号从小到大排列好的连续数据
而且应用程序在读取完数据之后,TCP的API会记录好应用程序读取的最后一个数据的序号,此时这个TCP API记录的最后一个序号就可以作为刚刚问题的解决方案
比如:此时缓冲区里面有从1~2000序号开始的数据,此时应用程序读取了前2000个数据
TCP 的API就会记录这个序号2000,说明序号1~2000的数据已经被读取完毕,
当缓冲区被传入新的数据的时候,就可以根据这个序号2000来判断是否有重复数据了
如果新数据的序号当中有小于2000的数据,因为数据的序号是连续的
说明这个数据是一个重复数据,如果新数据的序号全部都是大于2000的,那么就说明这个数据不是重复数据。
接收缓冲区的功能
有了以上的基础学习之后,证明了接收缓冲区可以实现两个功能:
- 去重:可以根据序号来判断是否是重复数据
- 排序:在缓冲区的数据会按照序号从小到大排序,保证了应用程序在读取数据的时候是有序正确的,因为如果程序读取到的顺序错误的数据会对应用程序对应的逻辑关系产生不好的影响
注意:在超时重传机制中,即使接收方缓冲区发现传输过来的数据是一个重复的数据,进行了丢弃之后,也还是要对发送方返回一个应答报文(ACK)的,如果不返回ACK,发送方还会再一次继续发送数据。
但是这个超时重传机制也不是无限一直重传
重传的次数是有一个上限的,重传到一定程度,发送方还没有接收到ACK,就会尝试重置连接,如果重置失败,就会放弃连接
而且这个超时的时间阈值不是固定不变的,是动态变化的,重传的次数越多,这个超时的时间阈值就越高,重传的频率就越低
