祝大家五一假期快乐!
最近推特加了逆向,频繁出现404,无法正常抓取数据,这里给出推特逆向的思路及代码,供大家参考学习!
本文将介绍如何使用 Python 模拟请求 Twitter 的 GraphQL 接口,结合 requests、BeautifulSoup 和自定义的 x-client-transaction-id 参数,成功获取搜索结果中的 timeline 数据。适合具备一定 Python 基础的开发者或对 Web 爬虫感兴趣的同学。
一、背景介绍
众所周知,Twitter(现 X)并没有开放完整的搜索接口给普通用户使用。如果你不是开发者账号,或者没有获得 Twitter API v2 的高级权限,就很难通过官方 API 获取搜索结果。
但实际上,Twitter 的 Web 前端使用的是 GraphQL 接口进行数据交互。我们可以通过分析请求,手动构造这些请求并获取数据。
二、核心技术栈
-
requests:用于发起 HTTP 请求 -
bs4(BeautifulSoup):用于解析 Twitter 首页 HTML,辅助构造 client_transaction_id -
json:构造 GraphQL 请求参数 -
loguru:用于日志记录 -
自定义模块
ClientTransaction:用于生成 Twitter 的x-client-transaction-id
三、关键参数获取
为了成功模拟 Twitter 请求,我们需要准备以下关键参数:
-
authorizationToken:用于通过认证。 -
Cookie:用于维持会话,尤其是ct0和auth_token是必要的。 -
x-client-transaction-id:是防爬关键参数,通过访问首页解析获得。
四、代码
python
import bs4
import requests
import time
from decryption.transaction import ClientTransaction
from loguru import logger
import json
# 设置 cookie 和 authorization(需自己抓包获取)
twitter_cookie = '...你的cookie...'
authorization = "Bearer ...你的token..."
# 提取 ct0
xCsrfToken = ""
for part in twitter_cookie.split(";"):
if part.strip().startswith("ct0="):
xCsrfToken = part.strip().split("=", 1)[1]
break
def get_cursor(dataJson):
instructions = dataJson.get('data', {}).get('search_by_raw_query', {}).get('search_timeline', {}).get('timeline', {}).get('instructions', [])
entries = []
cursor = None
for ins in instructions:
if ins.get('type') == "TimelineAddEntries":
entries = ins.get('entries', [])
for ent in entries:
content = ent.get('content', {})
if content.get('cursorType') == 'Bottom':
cursor = content.get('value')
break
return cursor, entries
cursor = ''
page = 1
while True:
url = "https://twitter.com"
resp = requests.get(url, headers={"User-Agent": "..."})
response = bs4.BeautifulSoup(resp.content, "lxml")
ctreq = ClientTransaction(home_page_response=response)
xClientTransactionId = ctreq.generate_transaction_id(
method="GET",
path="/i/api/graphql/AIdc203rPpK_k_2KWSdm7g/SearchTimeline"
)
url = "https://x.com/i/api/graphql/AIdc203rPpK_k_2KWSdm7g/SearchTimeline"
headers = {
"authorization": authorization,
"x-client-transaction-id": xClientTransactionId,
"x-csrf-token": xCsrfToken,
"x-twitter-auth-type": "OAuth2Session",
"x-twitter-active-user": "yes",
"x-twitter-client-language": "zh-cn",
"Cookie": twitter_cookie,
"content-type": "application/json"
}
variables = {
"rawQuery": "feed",
"count": 20,
"querySource": "typed_query",
"product": "Top",
}
if cursor:
variables["cursor"] = cursor
params = {
"variables": json.dumps(variables, separators=(",", ":")),
"features": json.dumps({
"rweb_video_screen_enabled": False,
"profile_label_improvements_pcf_label_in_post_enabled": True,
# ...省略部分参数
})
}
response = requests.get(url, headers=headers, params=params)
logger.info(f"页数:{page},状态码:{response.status_code}")
if response.status_code == 404:
logger.warning("页面未找到,重试...")
continue
req_data = response.json()
cursor, entries = get_cursor(req_data)
for entry in entries:
logger.info(entry)
time.sleep(3)
page += 1五、运行效果展示
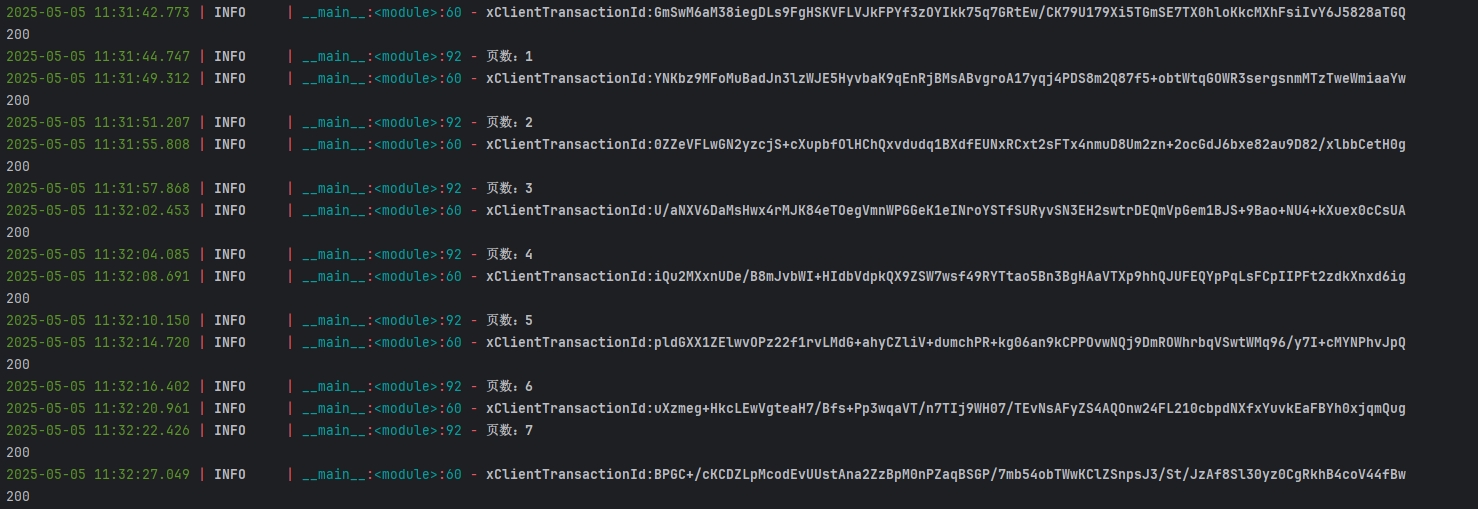
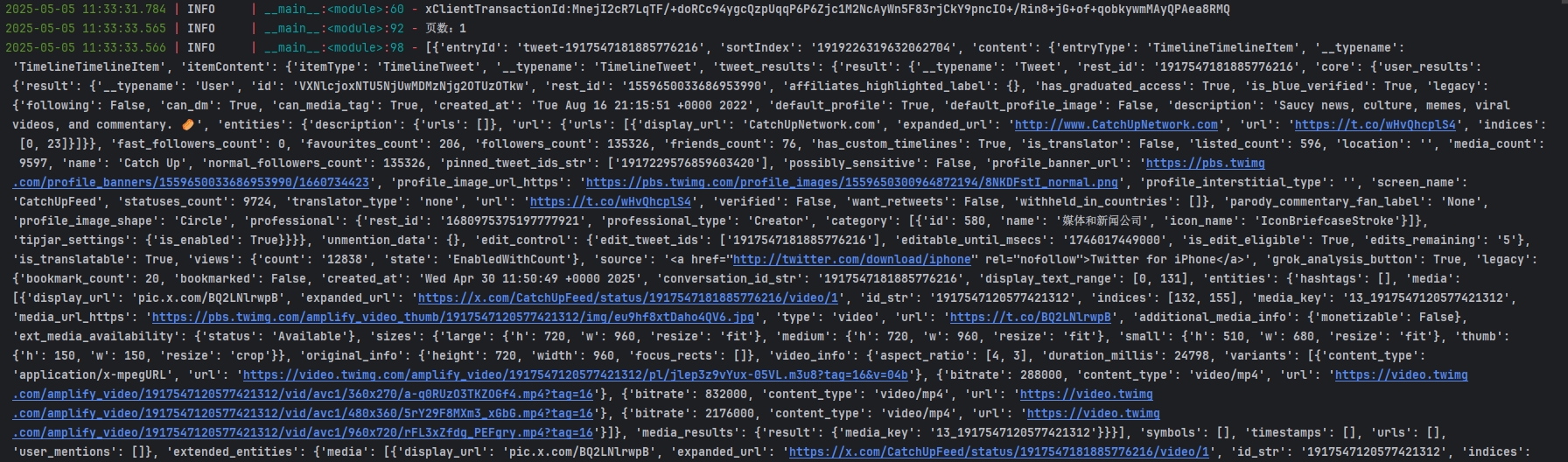
六、注意事项
-
防止封号 :建议不要频繁请求,设置合理的
sleep(如 3~5 秒)。 -
cookie 有效期 :
auth_token和ct0是有时效性的,需要定期更新。
七、总结
通过对 Twitter Web 接口的逆向分析,我们可以在不依赖官方 API 的情况下实现搜索结果的抓取。当然,这种方式存在一定的稳定性和合规风险,建议仅用于学习研究。如需帮助可以联系:zx_luckfe