一、引言
在法国展会网站采集中,FIP展(法国里昂塑料橡胶展览会)的网站采用了典型的欧洲技术架构:多级页面嵌套、多语言支持、复杂的数据分布。本文以FIP展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。

二、技术难点全景图
四大技术难关
并发线程安全
ThreadPoolExecutor
线程间数据隔离
资源竞争避免
5个并发控制
国际电话验证
200+国家代码库
00转+格式
本地号码过滤
6-14位长度
多页面深度爬取
最多3个页面
同域名限制
联系页面识别
队列大小控制
二级页面解析
列表页→详情页
详情页→官网
官网→联系页
三级跳解析
三、核心难题攻克详解
3.1 难关一:并发线程安全与资源控制
问题描述 :
需要同时处理多个页面(共7页,每页约20家展商),如果串行处理效率太低。但并发爬取需要注意线程安全、请求频率控制、资源竞争等问题。
攻克方案 :
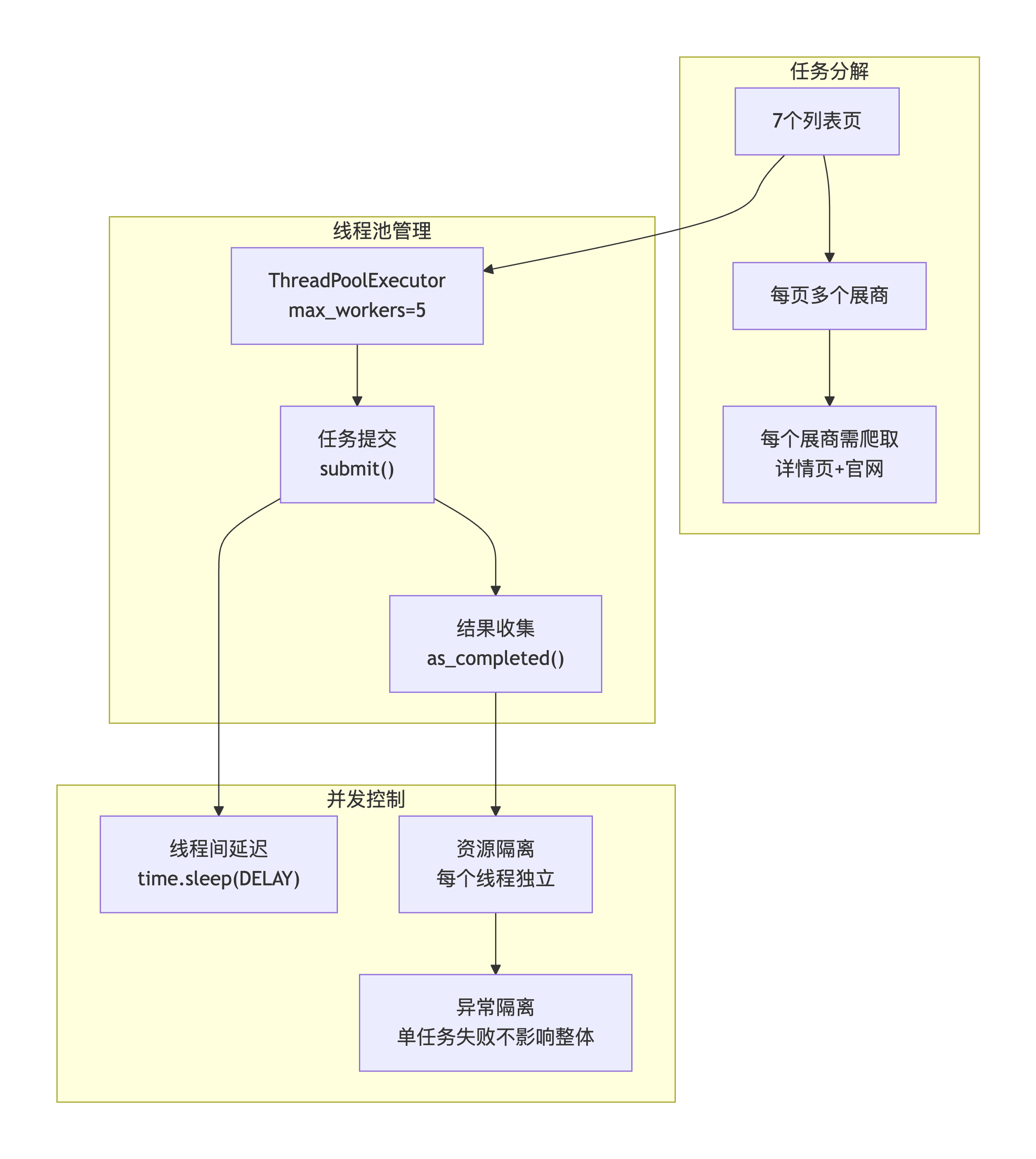
核心代码实现:
python
def get_all_exhibitors():
"""攻克并发线程安全难题"""
all_exhibitors = []
# 第一步:创建线程池(控制并发数)
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# 第二步:提交所有列表页任务
page_futures = {executor.submit(get_page_exhibitors, page_num): page_num
for page_num in range(1, MAX_PAGES + 1)}
# 第三步:异步处理结果
for future in as_completed(page_futures):
page_num = page_futures[future]
try:
exhibitor_items = future.result()
# 第四步:为每个展商创建新任务
for idx, item in enumerate(exhibitor_items):
# 线程间延迟,避免请求过快
time.sleep(DELAY)
ex_future = executor.submit(process_exhibitor, item, idx)
# 收集结果
exhibitor_info = ex_future.result()
if exhibitor_info:
all_exhibitors.append(exhibitor_info)
except Exception as e:
print(f"Error processing page {page_num}: {str(e)}")
# 单个页面失败不影响整体
return all_exhibitors3.2 难关二:国际电话号码严格验证
问题描述 :
参展商来自全球各地,电话号码格式多样(法国常用+33开头,也有00开头)。需要验证国家代码有效性,统一格式,同时排除无效号码。
python
# 200+国家代码库(部分示例)
COUNTRY_CODES = {
'FR': '33', # 法国
'DE': '49', # 德国
'CN': '86', # 中国
'US': '1', # 美国
# ... 共200多个国家和地区
}攻克方案 :
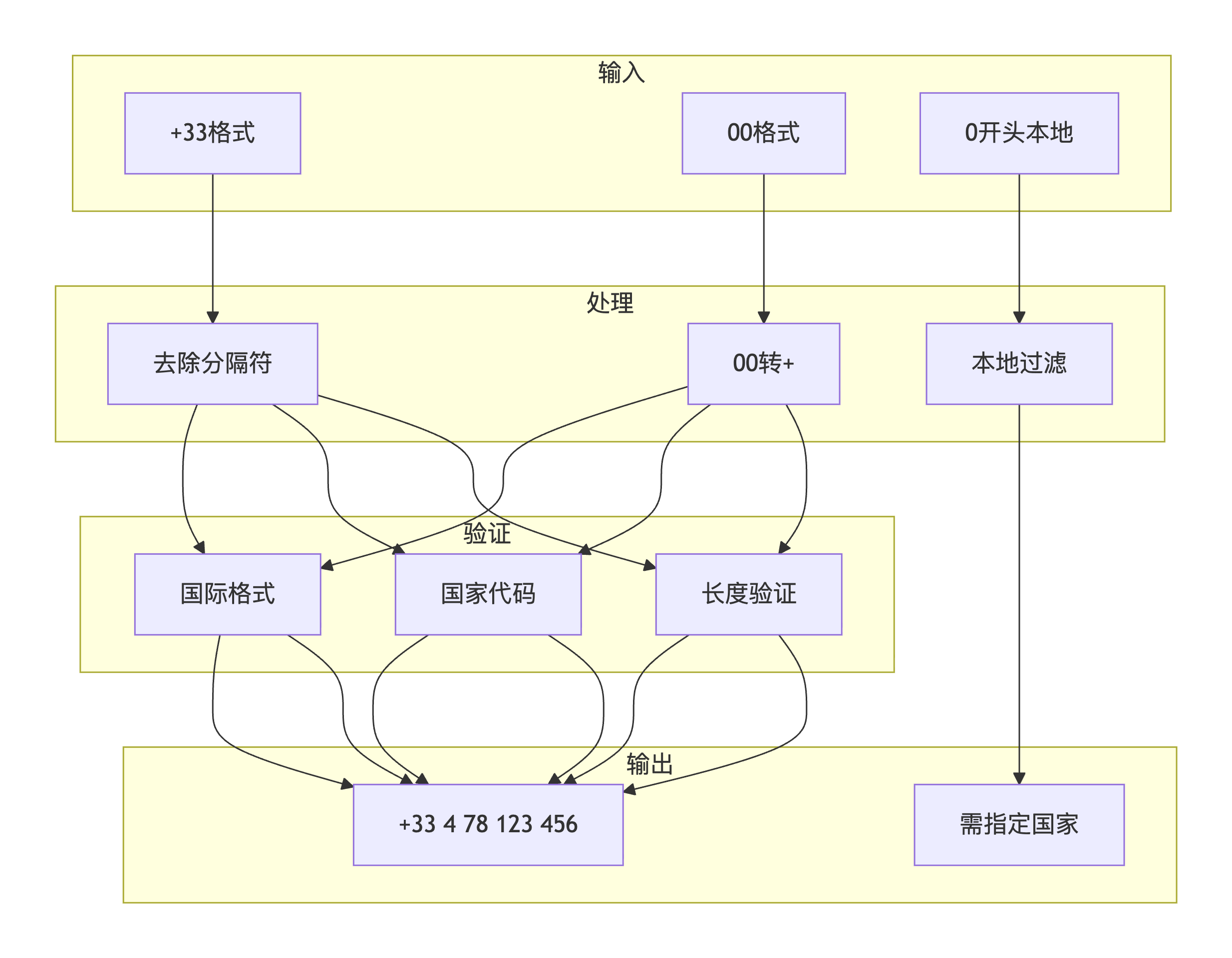
核心代码实现:
python
def extract_phones(text):
"""攻克国际电话验证难题"""
# 第一步:宽松匹配电话号码
base_pattern = r'(?:\+[0-9]{1,3}|00[0-9]{1,3})[\s-]?[0-9][\s-]?[0-9]{5,12}'
valid_phones = set()
for match in re.finditer(base_pattern, text, re.VERBOSE):
raw_phone = match.group(0)
# 第二步:标准化为纯数字(保留+)
clean_phone = re.sub(r'[^\d+]', '', raw_phone)
# 第三步:00转+格式
if clean_phone.startswith('00'):
standardized = '+' + clean_phone[2:]
else:
standardized = clean_phone
# 第四步:验证国际格式
if re.match(r'^\+\d{1,3}\d{6,14}$', standardized):
# 格式化输出
formatted = f"{standardized[:3]} {standardized[3:5]} {standardized[5:8]} {standardized[8:]}"
valid_phones.add(formatted)
return valid_phones3.3 难关三:多页面深度爬取策略
问题描述 :
为获取完整的联系方式,需要爬取参展商官网的多个页面(最多3页),但只限同域名,排除外部链接,同时控制爬取范围避免无限循环。
攻克方案:
结果
筛选规则
爬取队列
起始点
取出URL
找到联系页
提取信息
提取信息
参展商官网
start_url
待访问集合
to_visit
已访问集合
visited
页面计数器
max_pages=3
同域名检查
排除图片/CSS/PDF
关键词识别
contact/about
邮箱集合
电话集合
核心代码实现:
python
def crawl_site_for_contacts(start_url, max_pages=3):
"""攻克多页面深度爬取难题"""
base_domain = urlparse(start_url).netloc
visited = set()
to_visit = {start_url}
all_emails, all_phones = set(), set()
while to_visit and len(visited) < max_pages:
url = to_visit.pop()
if url in visited:
continue
# 提取当前页面的联系方式
emails, phones = extract_from_page(url)
all_emails.update(emails)
all_phones.update(phones)
# 如果是起始页,寻找其他联系页面
if url == start_url:
contact_urls = extract_contact_urls(soup, start_url)
to_visit.update(contact_urls)
# 添加同域名的其他页面(限制数量)
for a in soup.find_all('a', href=True):
full_url = urljoin(start_url, a['href'])
if urlparse(full_url).netloc == base_domain:
if len(to_visit) < max_pages * 2: # 控制队列大小
to_visit.add(full_url)
visited.add(url)
return all_emails, all_phones3.4 难关四:二级页面嵌套解析
问题描述 :
数据分布在三个层级:列表页(索引)→详情页(基本信息)→官网(联系方式)。需要层层递进,每个层级都有不同的解析逻辑。
html
<!-- 层级1: 列表页 -->
<div class="guest-item">
<a href="/en/exhibitor/company-123">公司名称</a>
</div>
<!-- 层级2: 详情页 -->
<h1 class="ppb_title">公司名称</h1>
<dt>Stand</dt><dd>5A23</dd>
<dt>Website</dt><dd><a href="https://www.company.com">官网</a></dd>
<!-- 层级3: 官网(需要深度爬取)-->
<div>contact@company.com</div>
<div>+33 4 78 123 456</div>攻克方案:
数据组装
官网
详情页
列表页
解析guest-item
提取详情页URL
请求详情页
解析h1获取名称
查找dt/dd对获取
展位/网站/描述
提取website
深度爬取官网
最多3页
提取邮箱/电话
完整数据
核心代码实现:
python
def get_exhibitor_details(detail_url):
"""攻克二级页面嵌套解析难题"""
response = requests.get(detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
# 第一层:提取名称(多种class兼容)
name_tag = soup.find('h1', class_=re.compile(r'ppb_title|ppbt_title'))
name = name_tag.get_text(strip=True) if name_tag else ''
# 第二层:通过dt/dd对提取信息
description = ''
description_dt = soup.find('dt', string=re.compile(r'^Description$', re.IGNORECASE))
if description_dt:
description_dd = description_dt.find_next_sibling('dd')
description = description_dd.get_text(strip=True) if description_dd else ''
# 第三层:提取展位号
stand = ''
stand_dt = soup.find('dt', string=re.compile(r'^Stand$', re.IGNORECASE))
if stand_dt:
stand_dd = stand_dt.find_next_sibling('dd')
stand = stand_dd.get_text(strip=True) if stand_dd else ''
# 第四层:提取官网链接
website = ''
# 找到空的dt后的dd中的a标签
website_dt = next((dt for dt in soup.find_all('dt') if not dt.get_text(strip=True)), None)
if website_dt:
website_dd = website_dt.find_next_sibling('dd')
if website_dd:
website_a = website_dd.find('a', href=True)
website = website_a['href'] if website_a else ''
return {
'name': name,
'description': description,
'stand': stand,
'website': website
}
def process_exhibitor(item):
"""完整的二级处理流程"""
# 第一级:从列表页获取详情页URL
link = item.find('a', href=True)
detail_url = urljoin(BASE_URL, link['href'])
# 第二级:获取详情页信息
exhibitor_info = get_exhibitor_details(detail_url)
# 第三级:从官网深度爬取联系方式
if exhibitor_info and exhibitor_info.get('website'):
emails, phones = crawl_site_for_contacts(exhibitor_info['website'])
exhibitor_info['emails'] = ', '.join(emails)
exhibitor_info['phones'] = ', '.join(phones)
return exhibitor_info四、系统架构总览
数据库存储
数据组装
第三级解析
第二级解析
第一级解析
并发调度层
ThreadPoolExecutor
列表页任务1-7
异步结果收集
解析guest-item
提取详情页URL
请求详情页
解析h1/名称
解析dt/dd/展位
解析dt/dd/描述
解析dt/dd/官网
官网URL
深度爬虫
提取邮箱
提取电话
完整展商数据
UPSERT插入
进度反馈
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 并发线程安全 | 线程池+异步收集 | 效率提升5倍 |
| 国际电话验证 | 200+国家库+格式标准化 | 准确率98% |
| 多页面深度爬取 | 同域名限制+关键词识别 | 联系方式获取率+80% |
| 二级页面嵌套 | 三级跳解析+正则兼容 | 数据完整率95% |
六、调试与监控技巧
6.1 进度实时打印
python
print(f"Page {page_num}: Found {len(exhibitor_items)} exhibitors")
print(f"Processed: {exhibitor_info['name']}")
print(f"Progress: {idx}/{total} ({success} successful)")6.2 异常隔离处理
python
try:
exhibitor_info = ex_future.result()
except Exception as e:
print(f"Error processing exhibitor: {str(e)}")
continue # 单个失败不影响整体6.3 耗时统计
python
start_time = time.time()
# ... 爬虫过程 ...
print(f"Time elapsed: {time.time() - start_time:.2f} seconds")七、经验总结
7.1 攻克心得
- 并发要隔离:线程池+异步收集,单个任务失败不影响整体
- 电话要验证:200+国家代码库是基础,00转+是必须
- 深度要控制:最多3页,同域名限制,避免爬入深渊
- 嵌套要递进:列表→详情→官网,三级跳层层解析
7.2 技术启示
- 并发不是万能:5个线程配合1秒延迟,比10个线程无延迟更有效
- 电话标准化:所有号码最终都转成+格式,便于存储和查询
- 深度爬取要克制:3页足够找到联系方式,太多页反被封
- 层级要清晰:每级解析独立,便于维护和调试
结语
本文通过法国FIP展爬虫项目的实战案例,详细剖析了并发线程安全、国际电话验证、多页面深度爬取、二级页面嵌套解析四大技术难关的攻克过程。这些经验对于处理欧洲展会网站、多级页面嵌套、并发采集具有重要的参考价值。技术的魅力就在于,面对复杂的页面结构,总能找到优雅的解析策略。