论文链接: GPT1: Improving Language Understanding by Generative Pre-Training
点评:
首次将Transformer的decoder部分引入无监督训练且引入了辅助训练目标。文章证明无监督预训练显著提升判别任务性能,其中Transformer架构和长依赖文本数据是关键成功因素。这项工作为无监督学习在自然语言理解及其他领域的研究提供了新方向,进一步揭示了无监督学习的作用机制与适用场景。
自然语言理解涵盖了一系列广泛且多样化的任务,包括文本蕴含推理、问答系统、语义相似度评估以及文档分类等。尽管大规模未标注文本语料库资源丰富,但针对这些特定任务进行学习所需的标注数据却相对稀缺,这使得基于判别式训练的模型难以取得理想性能。我们证明,通过在多样化的未标注文本语料库上对语言模型进行生成式预训练,再针对每个具体任务进行判别式微调,可以在这些任务上实现显著提升。与以往方法不同,我们在微调过程中采用任务感知的输入转换策略,在确保模型架构改动最小的前提下实现了高效的知识迁移。文章在自然语言理解领域的多个基准测试中验证了该方法的有效性。文章提出的通用任务无关模型,在研究的12项任务中有9项超越了专门为各任务定制架构的判别式训练模型,显著刷新了当前最优水平。例如,我们在常识推理任务(Stories Cloze Test)上实现了8.9%的绝对提升,在问答任务(RACE)上提升5.7%,在文本蕴含任务(MultiNLI)上提升1.5%。
详细文章训练分为无监督训练、和有监督微调两阶段:
3 Framework
一、无监督训练
给定一个无监督的序列,我们使用一个标准的语言模型来最大化如下概率:
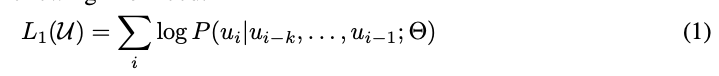
其中k是窗口大小,P是使用网络得到的条件概率。网络结构使用多层Transformer 解码器。这个模型将一个多头自注意力操作应用到输入的文本上,接着是位置相关前向网络层来构建在目标文本的输出分布
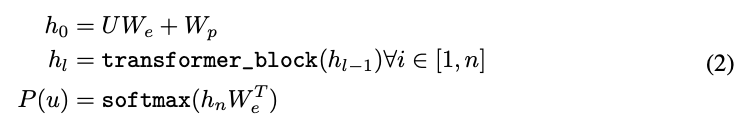
二、有监督微调
在前面的无监督微调训练完毕后,我们使用有监督训练来调整参数。在有监督任务里引入了参数Wy来学习新的有监督目标:
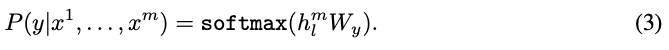
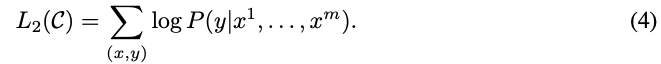
同时也添加了语言模型作为辅助任务,来提升模型的泛化能力 和 加速收敛。

对于文本分类,可以直接按照前面的描述微调。而其他的任务,例如问答和文本蕴含任务,却需要对输入进行格式化,例如句子排序或 文本、问题和答案三对。下文简要描述这些输入转换方式(图1提供了直观示意图),所有转换均包含添加随机初始化的开始标记 和结束标记。
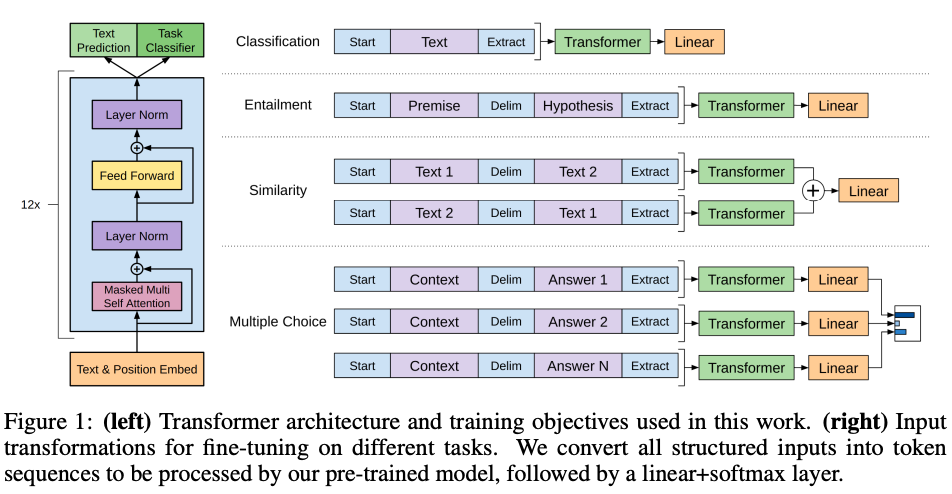
文本蕴含(Textual Entailment)
对于蕴含任务,我们将前提(premise)p 和假设(hypothesis)h 的 token 序列拼接,并在中间插入一个分隔符标记 ($)。
相似度(Similarity)
对于相似度任务,被比较的两个句子本身没有顺序关系。为了适应这一点,我们将输入序列修改为包含两种可能的句子顺序(中间用分隔符隔开),并分别独立处理这两个顺序,生成两个序列表示 hₘₗ,最后对它们进行按元素相加,再将结果输入线性输出层。
问答与常识推理(Question Answering & Commonsense Reasoning)
对于这类任务,给定上下文文档 z、问题 q 和一组候选答案 {aₖ}。我们会将文档上下文、问题与每个候选答案拼接(中间添加分隔符标记),得到 [z; q; $; aₖ]。每个拼接后的序列由模型独立处理,最终通过 softmax 层 归一化,生成候选答案的概率分布。
4 实验
我们进行了三项消融实验(见表5):
- 移除辅助语言模型(LM)目标 :在微调阶段剔除辅助LM目标后,发现其对自然语言推理(NLI)任务和QQP数据集性能有明显提升。整体趋势表明,大规模数据集受益于辅助目标,而小规模数据集则无显著增益。
- Transformer vs. LSTM:将Transformer替换为单层2048单元的LSTM后,模型平均得分下降5.6分。仅在小数据集MRPC上,LSTM表现优于Transformer。
- 预训练的重要性:直接使用未经预训练的Transformer架构进行监督学习时,所有任务性能均显著下降,与完整模型相比平均下降14.8%。
5 结论
我们提出了一个通过生成式预训练与判别式微调相结合的通用框架,实现了单一模型在多任务自然语言理解中的优异表现。通过在长文本语料库上的预训练,模型习得了丰富的世界知识和对长距离依赖关系的处理能力,并成功迁移至问答、语义相似度评估、文本蕴含判断和分类等判别任务中。在研究的12个数据集中,我们的模型在9个任务上刷新了最佳性能。
实验表明,无监督预训练显著提升判别任务性能,其中Transformer架构和长依赖文本数据是关键成功因素。这项工作为无监督学习在自然语言理解及其他领域的研究提供了新方向,进一步揭示了无监督学习的作用机制与适用场景。