今天有同学反馈一个问题,比较有代表性。说下
问题描述 在 root 用户下 无法执行如下代码
1.linux执行计划 :crontab 加入
c
42 17 7 5 * /root/hadoop_op.sh2.hadoop_op.sh内语句:
c
#!/bin/bash
su - hadoop
cd /opt/module/hadoop-3.3.0/sbin
./start-all.sh
jpscrontab 代码 问题解析
42 17 7 5 * /root/hadoop_op.sh 这行代码是一个 cron job(定时任务)表达式,它会在特定的时间执行指定的命令或脚本。具体解析如下:
- 42 17 7 5 *:
这部分是 cron 定时任务的时间和日期设置,表示任务在何时执行。这个时间格式包含 5 个字段,依次是:
分钟 (Minute):42
表示任务将在每小时的第 42 分钟执行。
小时 (Hour):17
表示任务将在下午 5 点(17:00)执行。
日期 (Day of Month):7
表示任务将在每月的 7 号执行。
月份 (Month):5
表示任务将在每年的 5 月执行。
星期几 (Day of Week):*
星号 (*) 表示任务将在任何星期几执行,也就是说不限制具体的星期几。
- /root/hadoop_op.sh:
这是要执行的脚本文件路径,表示在指定的时间点,系统会运行这个脚本。具体来说,它会运行 /root/hadoop_op.sh 这个文件。
从上文看此代码没有问题
也可以改为每天 17点 42分
要设置 cron job 每天的 17:42 执行,你可以使用以下表达式:
c
42 17 * * * /root/hadoop_op.sh解释:
42:表示在每小时的第 42 分钟。
17:表示在 17:00,也就是下午 5 点。
*:表示每天都会执行(没有指定具体的日期或月份)。
*:表示每个月都会执行(没有指定具体的月份)。
*:表示每周的任何一天都会执行(没有指定具体的星期几)。
.hadoop_op.sh 代码 问题解析
在Linux中,su - hadoop命令用于切换到hadoop用户,但在sh脚本中直接使用su可能会遇到问题。具体原因如下:
1. 切换用户:
在脚本中使用su命令时,它通常不会像在终端中直接输入一样生效,因为su是一个交互式命令,需要一个终端来启动一个新的用户会话。如果你在脚本中直接调用su - hadoop,它不会成功切换用户并继续执行后续命令。
su会要求输入hadoop用户的密码,如果没有密码交互,su可能会失败。
2. 解决方法
如果你希望以hadoop用户身份执行脚本中的命令,最好的方式是使用sudo。你可以在脚本中加入sudo来提升权限,或者在脚本外部确保该命令有权限执行。
你可以修改脚本如下:
c
#!/bin/bash
sudo su - hadoop -c "cd /opt/module/hadoop-3.3.0/sbin && ./start-all.sh && jps"这样可以确保切换到hadoop用户并执行指定的命令。
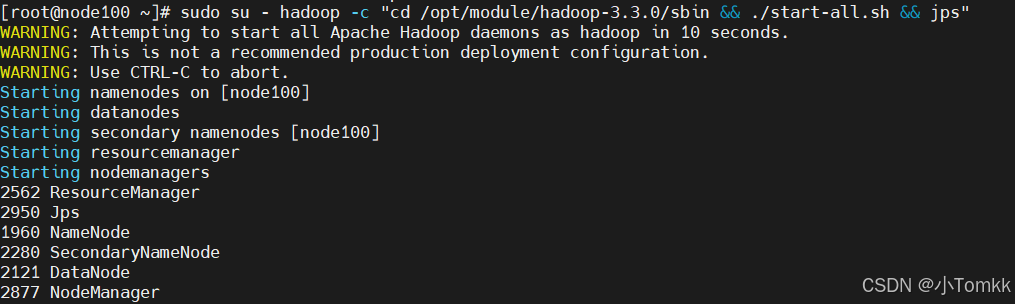
可以看到 切换用户 后 已经启动了,
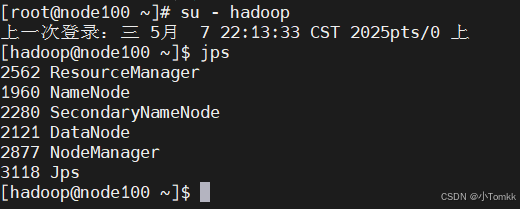
3. 确保sudo配置:
为了让sudo su - hadoop -c工作,你需要确保hadoop用户具有足够的权限,且能够在不输入密码的情况下执行sudo命令。你可以在sudoers文件中配置hadoop用户,允许其无需密码使用sudo命令。
在/etc/sudoers文件中添加如下行:
建议在root 目录下执行 如下 命令
c
chmod 755 /etc/sudoers
vi /etc/sudoers
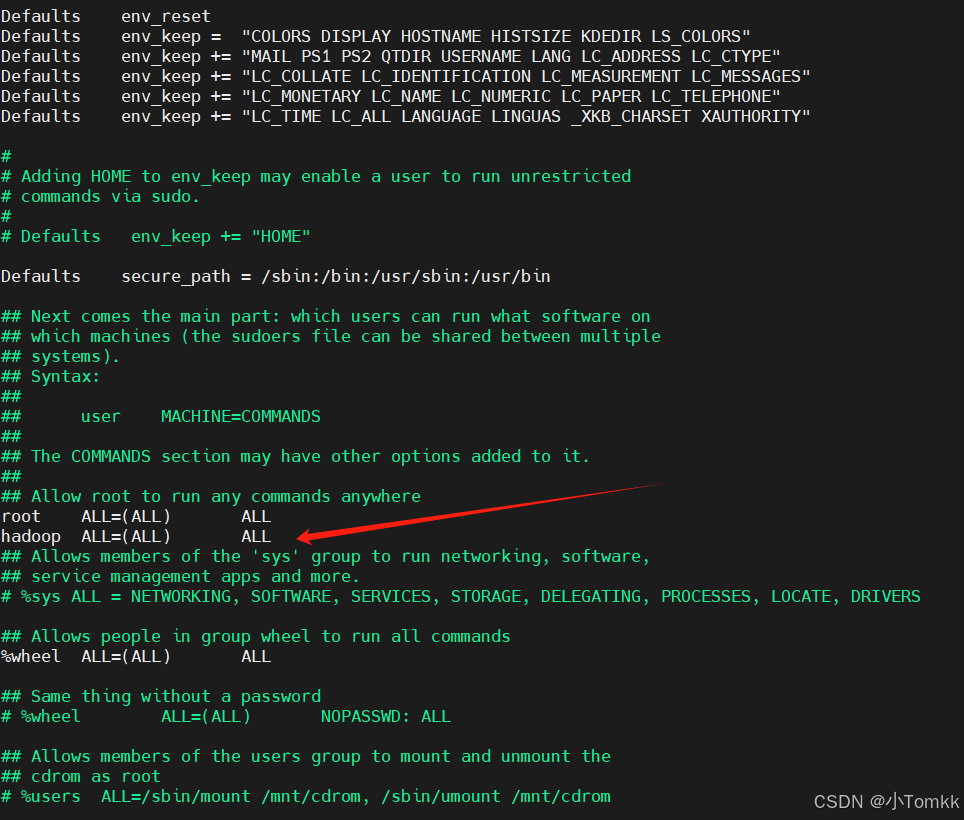
改为如下
c
hadoop ALL=(ALL) NOPASSWD: ALL4. 注意事项:
由于你的命令中包括了jps,它会显示正在运行的Java进程。如果start-all.sh成功启动了Hadoop集群,jps应该能够列出Hadoop相关进程。
结论:
直接在sh脚本中切换用户并执行其他命令是不可行的。你需要使用sudo来解决权限问题,并通过适当的方式切换用户。