在RabbitMQ中,Exchange(交换器)是消息路由的核心组件,它接收生产者发送的消息,并根据不同的规则将消息转发到一个或多个队列。
RabbitMQ主要支持以下几种类型的交换器:
1. Direct Exchange(直连交换器)
- 路由规则 :Direct Exchange根据消息的路由键(routing key)来路由消息。当消息发送到Direct Exchange时,Exchange会将消息发送到与该路由键完全匹配的队列。如果没有匹配的队列,消息将被丢弃(取决于具体配置)。
- 适用场景:适用于需要**精确匹配**的场景。比如在一个订单处理系统中,根据订单的类型(如普通订单、其他订单)作为路由键,将不同类型的订单消息发送到对应的处理队列。
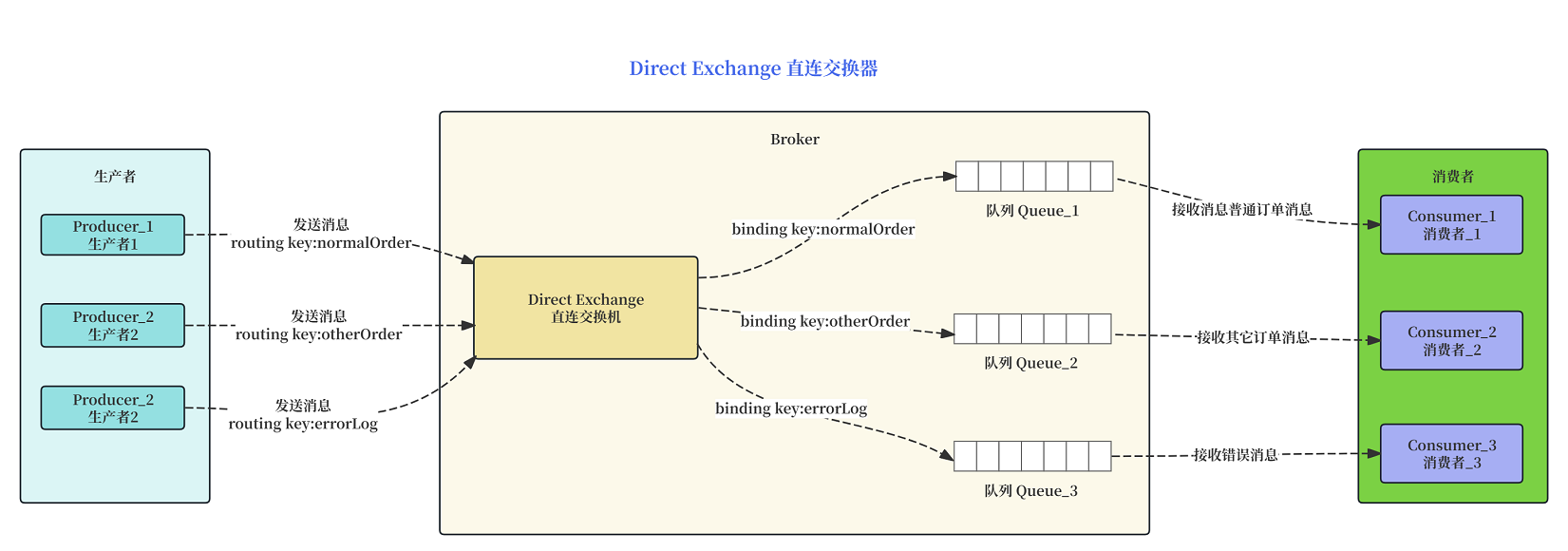
说明:
- 生产者发送消息时,会指定一个 routing key(如 normalOrder 或 otherOrder)。
- 队列通过 Binding Key 绑定,每个队列通过一个 binding key 绑定到 Direct Exchange。
- 精确匹配路由,Direct Exchange 会将消息的 routing key 与队列的 binding key 进行精确匹配。只有完全匹配的队列才会收到消息。
- normalOrder 的消息精确匹配了 binding key: normalOrder,因此被路由到Q1队列,由 Consumer_1 消费。
- otherOrder 的消息精确匹配了 binding key: otherOrder,因此被路由到Q2队列,由 Consumer_2 消费。
- errorLog 的消息精确匹配了 binding key: errorLog,因此被路由到Q3队列,由 Consumer_3 消费。
2. Topic Exchange(主题交换器)
- 路由规则 :Topic Exchange支持更灵活的路由匹配 ,它使用通配符来匹配路由键。具体来说,使用
*匹配一个单词,#匹配零个或多个单词。路由键是由点(.)分隔的单词序列。比如server.cpu.use是一个有效的路由键。 - 适用场景:适用于需要根据消息的主题进行分类路由的场景。比如在一个监控系统中,不同的监控指标(如服务器的CPU使用率、内存使用率,磁盘空间等)可以通过不同的路由键模式进行匹配,将相关消息发送到对应的处理队列。
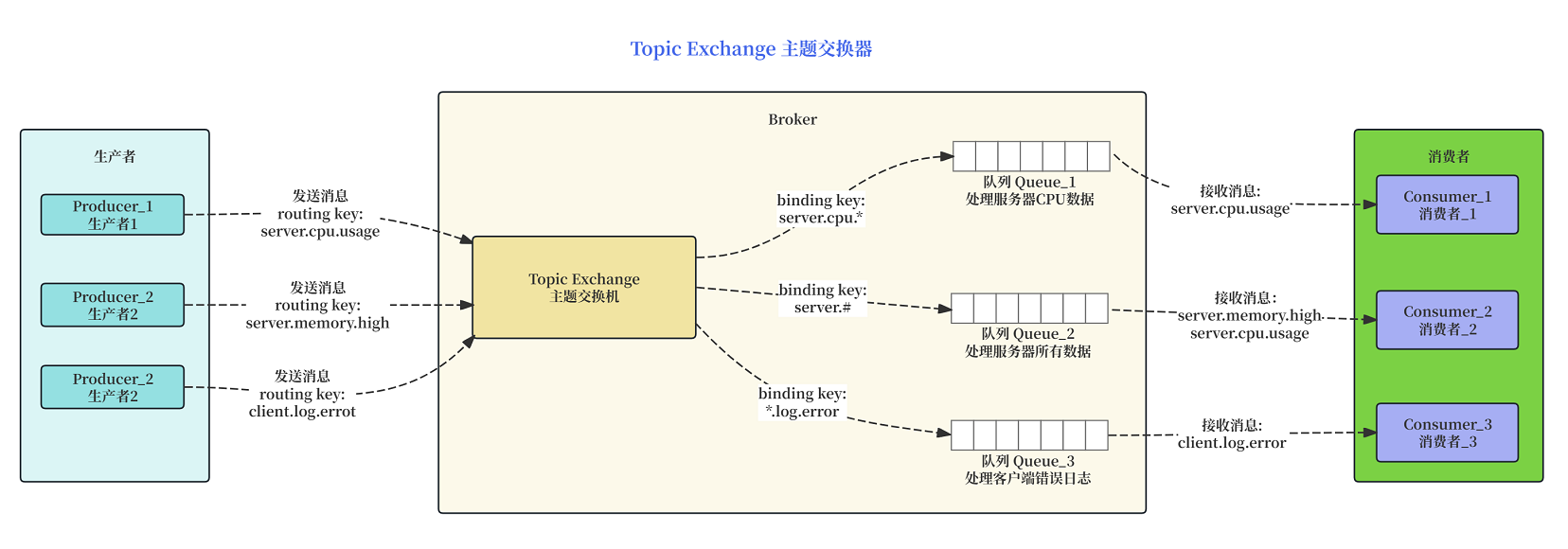
说明:
- 所有生产者都向同一个 Topic Exchange 发送消息
- 队列通过包含通配符(* 匹配一个单词,# 匹配零个或多个单词)的 binding key 绑定到 Topic Exchange。
- Exchange 将消息的 routing key 与队列的 binding key 进行模式匹配。
- 消息分发:
- server.cpu.usage 消息被路由到 Q1 (server.cpu.* 匹配) 和 Q2 (server.# 匹配)。
- server.memory.high 消息被路由到 Q2 (server.# 匹配)。
- client.log.error 消息被路由到 Q3 (*.log.error 匹配)。
3. Fanout Exchange(扇形交换器)
- 路由规则 :Fanout Exchange会将接收到的消息广播到所有与它绑定的队列,而不考虑消息的路由键。无论路由键是什么,所有绑定到该交换器的队列都会收到消息副本。
- 适用场景:适用于广播消息的场景,例如系统通知。当有新的系统公告时,需要通知所有相关的模块,这些模块对应的队列都绑定到Fanout Exchange,从而都能收到公告消息。
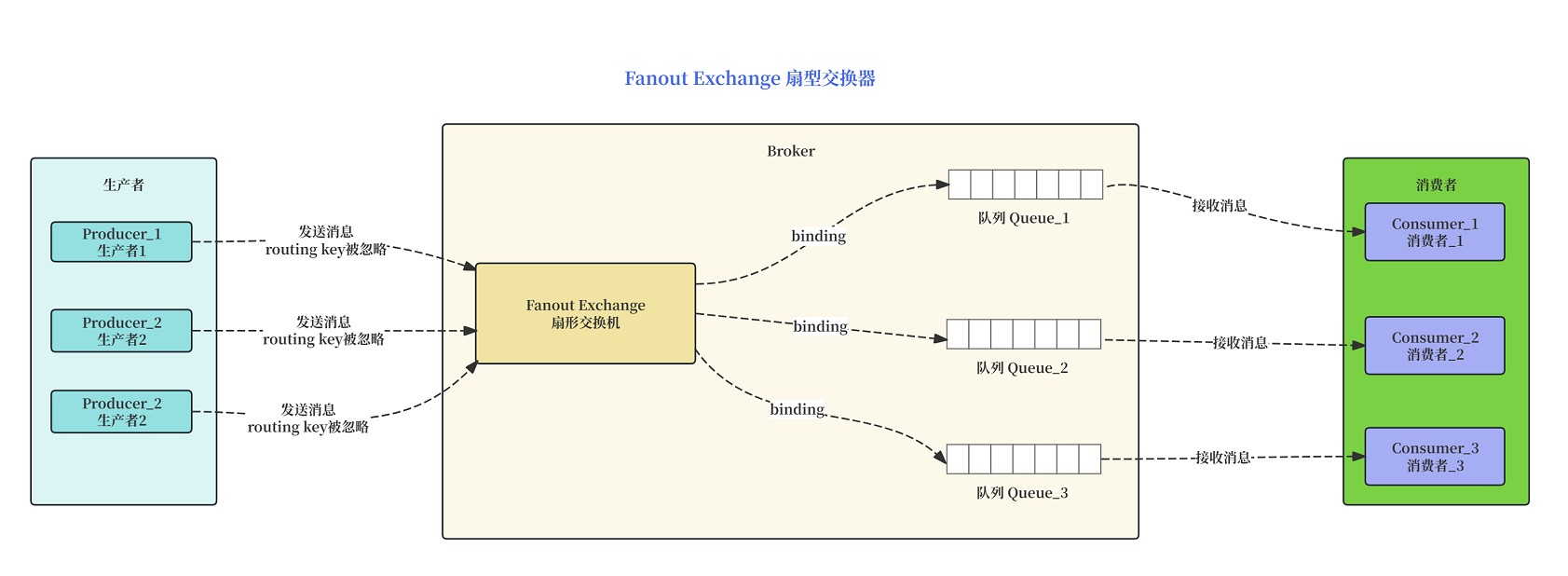
说明:
- Fanout Exchange 会将接收到的所有消息广播给所有绑定到它的队列。
- 生产者发送消息时指定的 routing key 会被 Fanout Exchange 完全忽略。
- 队列绑定到 Fanout Exchange 时,不需要指定 binding key(或者说,指定了也会被忽略)。
- 同一条消息会被复制并发送到所有绑定的队列中,因此所有连接到这些队列的消费者都会收到相同的消息。
4. Headers Exchange(头部交换器)
- 路由规则 :Headers Exchange根据消息的headers属性 来路由消息,而不是路由键。当消息发送到Headers Exchange时,Exchange会检查消息的headers属性,并与绑定队列时指定的headers属性进行匹配。如果匹配成功,消息将被发送到该队列。匹配规则有两种:
x-match = all表示所有指定的headers属性都必须匹配;x-match = any表示只要有一个指定的headers属性匹配即可。 - 适用场景:Headers Exchange相对较少使用,适用于需要根据消息的headers信息进行复杂路由的场景,比如根据消息的来源、优先级等headers属性进行路由。
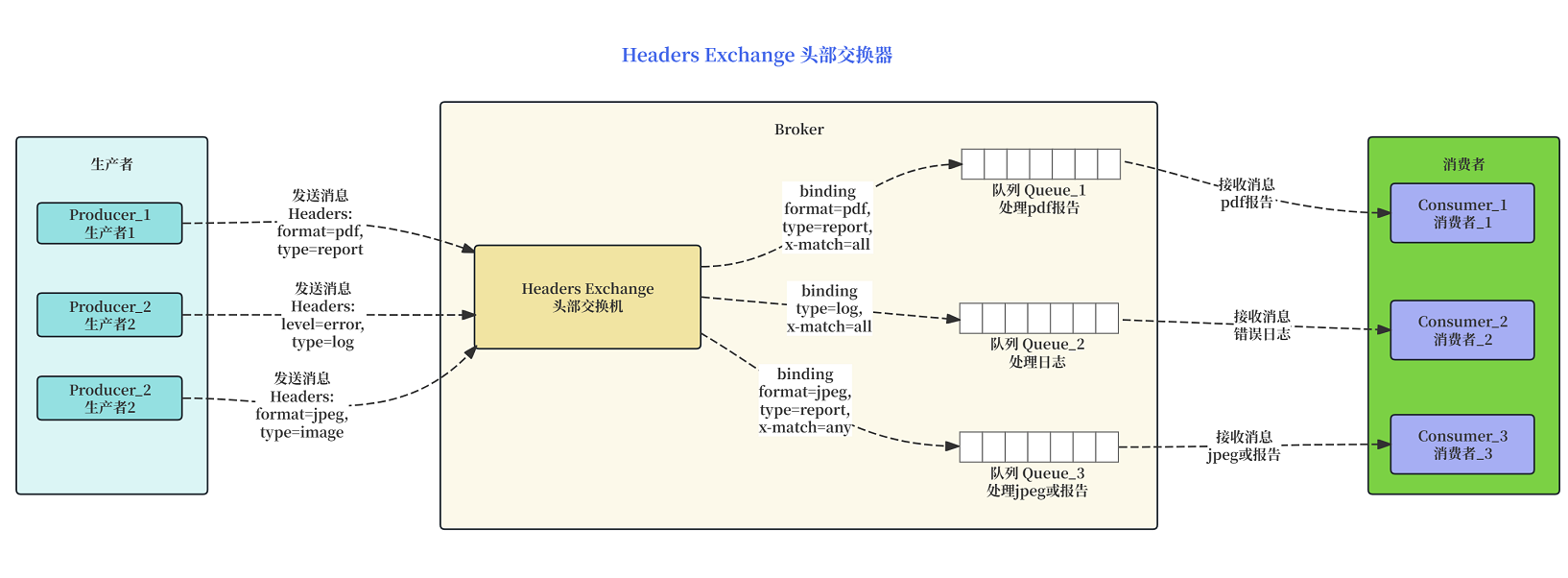
说明:
在基于 Headers 路由中,消息的路由不再依赖 routing key,而是依赖消息头(Headers)中的键值对。
绑定参数 (Binding Arguments): 队列绑定到 Exchange 时,需要指定一组键值对作为匹配条件,并且必须包含一个特殊的 x-match 参数。
匹配策略 (x-match):
- x-match=all: 消息头必须包含所有在绑定参数中指定的键,并且对应的值也要匹配。(AND 逻辑)
- x-match=any: 消息头至少包含一个在绑定参数中指定的键,并且对应的值也要匹配。(OR 逻辑)
消息分发:
- P1 的消息 (format=pdf, type=report) 匹配了 Q1 (需要 all) 和 Q3 (需要 any report)。
- P2 的消息 (type=log, level=error) 仅匹配了 Q2 (需要 all log)。
- P3 的消息 (format=jpeg, type=image) 仅匹配了 Q3 (需要 any jpeg)。