感兴趣的可以先收藏起来,还有在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,我会一一回复,希望可以帮到大家。
一、程序背景
野生蘑菇种类繁多(已知超 10 万种),但毒蘑菇与可食用蘑菇外观相似,肉眼难区分,误食事件频发(如 2024 年某乡村 10 余人误食剧毒鹅膏菌中毒,3 人死亡),严重威胁生命健康。传统识别方法依赖专业人员形态学判断或民间经验,存在门槛高、准确性差的弊端,无法满足大众准确识别需求。在此背景下,开发基于深度学习的蘑菇种类识别系统,以解决蘑菇识别难题、保障食品安全、助力相关科研与产业发展成为迫切需求。
二、程序功能需求
1. 用户功能
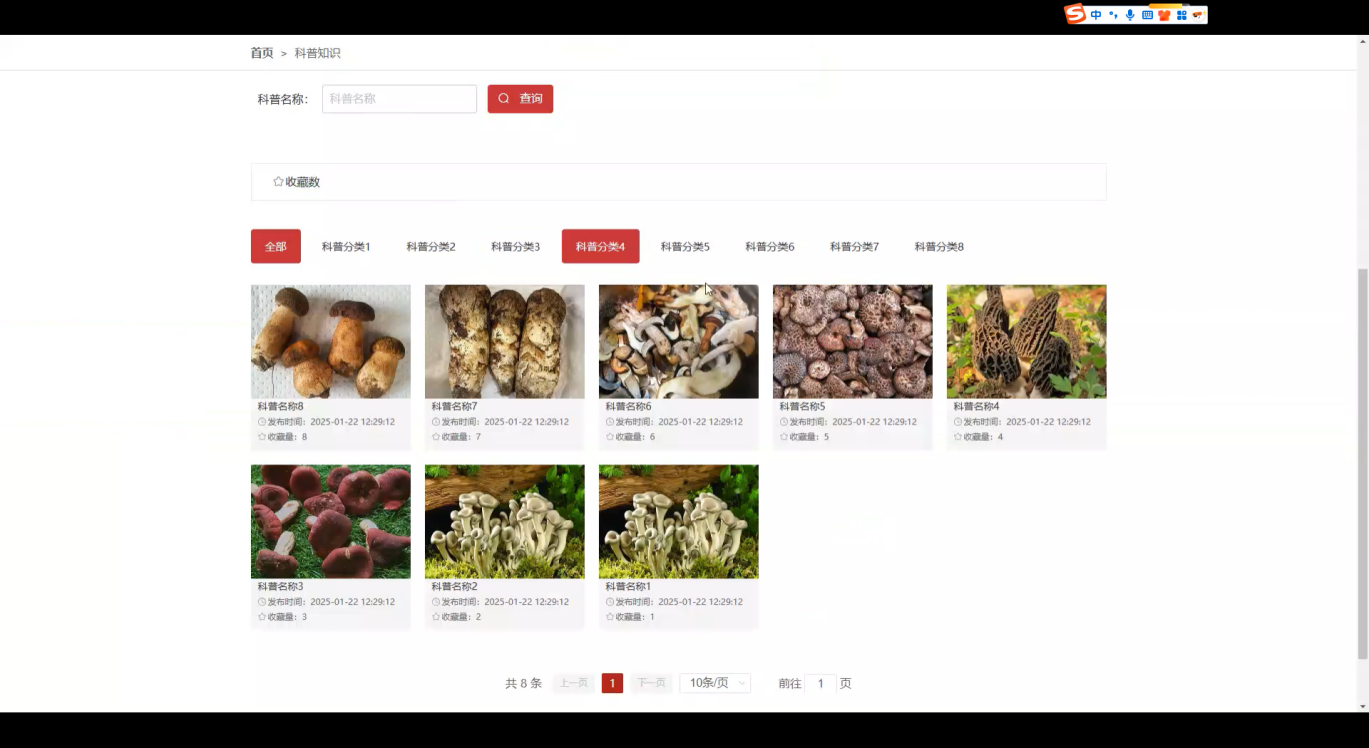
- 科普知识展示:图文并茂呈现蘑菇生长环境、营养价值、毒性特征等;
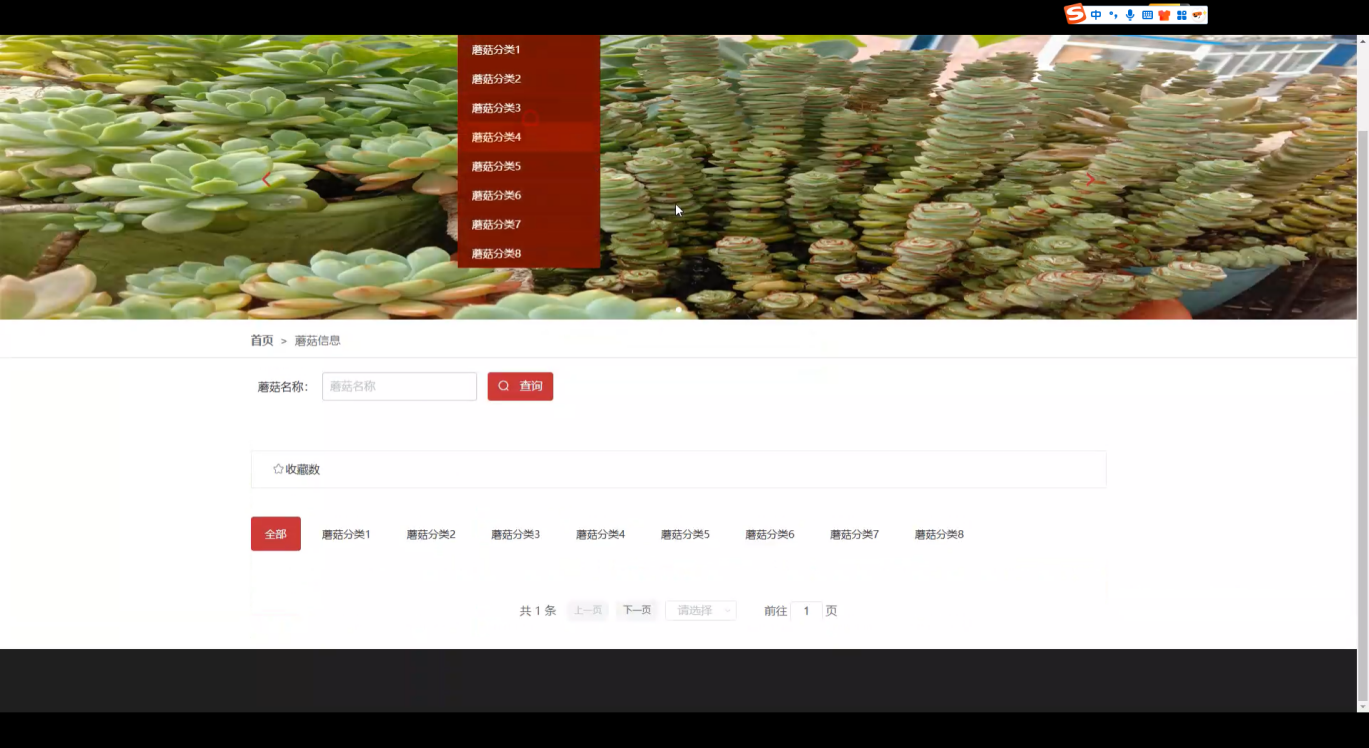
- 蘑菇信息查询:支持按名称、特征等搜索蘑菇详细介绍;
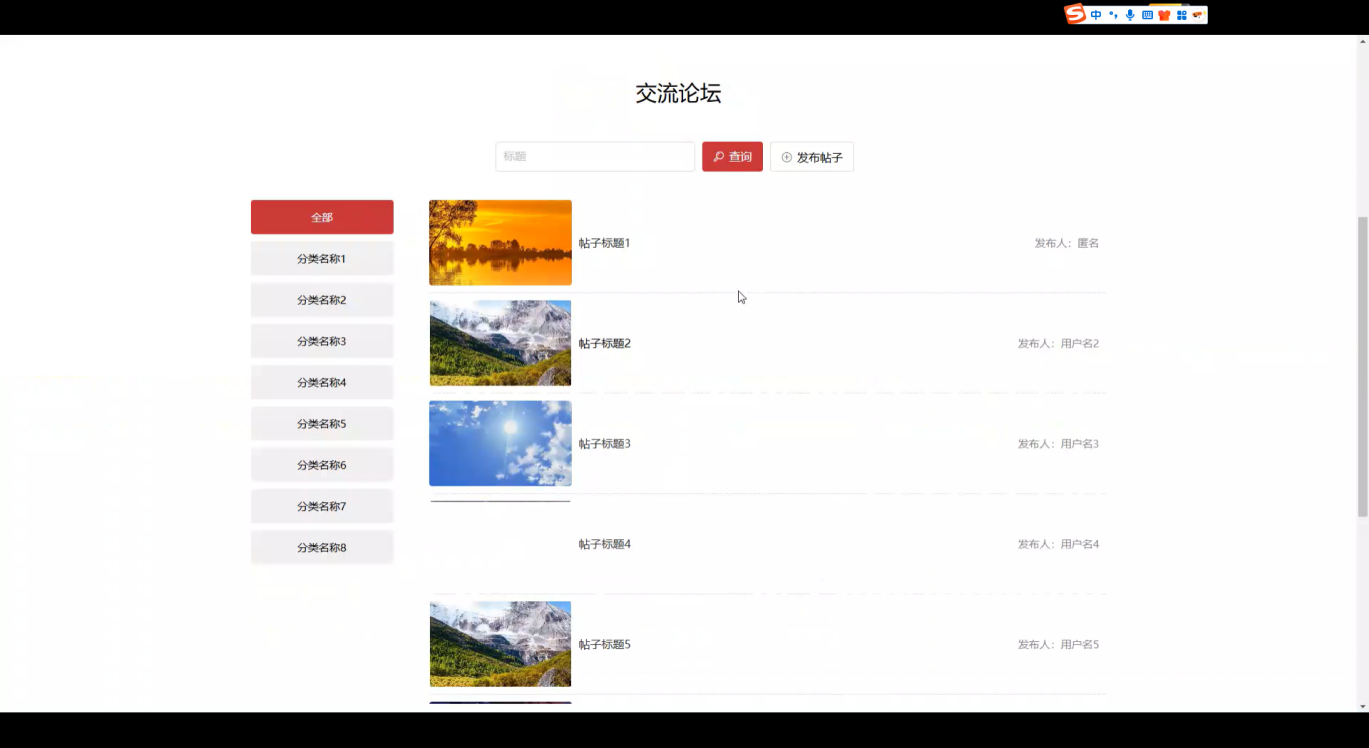
- 交流论坛:用户交流识别经验、分享蘑菇相关趣事,可发帖、评论、点赞;
- 通知公告:接收系统更新、重要提示等实时推送;
- 注册登录:保障账号安全,个性化记录操作;
- 留言反馈:提出意见与问题;
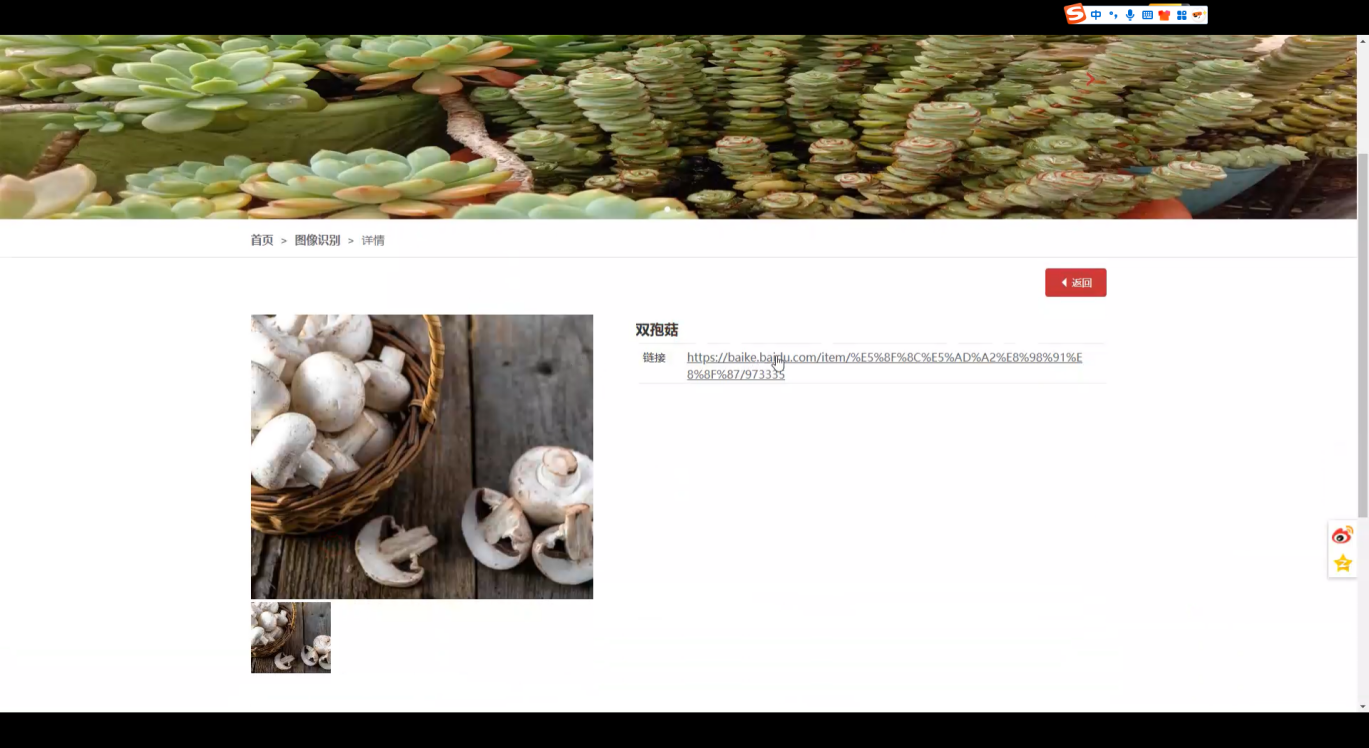
- 核心功能 - 图像识别:上传蘑菇图片,快速获取识别结果及匹配的蘑菇信息。
2. 管理员功能
- 图像识别管理:审核用户上传的识别内容;
- 科普知识管理:更新、编辑、删除科普资料;
- 蘑菇信息管理:完善、校正、增删蘑菇数据;
- 交流论坛管理:处理违规帖子、维护秩序,可删除帖子、禁言违规用户;
- 通知公告管理:发布、修改、删除通知;
- 留言反馈管理:查看并回复用户问题;
- 用户管理:审核用户注册、处理异常账号。
三、功能创新点
- 融合深度学习核心技术:基于卷积神经网络(CNN)实现高精度蘑菇图像识别,突破传统经验识别的局限性,降低用户使用门槛;
- 功能多元化集成:并非单一识别工具,整合科普教育、信息查询、社交分享等功能,形成 "识别 + 科普 + 互动" 的综合服务模式;
- 应用场景适配性优化:采用 B/S 架构,支持多终端(电脑、手机、平板)主流浏览器访问,实现随时随地便捷识别;
- 本土化与实用性结合:针对国内不同地区(如云南)特色蘑菇资源优化模型,提升地域针对性识别准确率,同时通过管理员审核机制保障识别内容可靠性。
四、系统架构
采用分层架构设计,自下而上分为三层,各层协同工作:
- 数据层:以 MySQL 数据库为核心,存储蘑菇科普知识(文本 + 图片)、用户信息、论坛帖子、识别记录、训练数据等各类数据,通过索引优化和 InnoDB 引擎保障数据存储安全与查询效率;
- 业务逻辑层:基于 Java 技术开发,运用 SpringBoot 等框架搭建后端服务,实现用户认证、图像识别处理、数据增删改查、业务逻辑协调(如关联识别结果与蘑菇信息)等核心功能,衔接数据层与表现层;
- 表现层:基于 B/S 架构,通过 HTML、CSS、JavaScript、Vue.js 等技术构建前端界面,为用户和管理员提供直观操作入口,接收输入并展示系统处理结果。
五、写论文的重点
- 问题导向的背景与意义阐述:突出误食毒蘑菇的现实危害和传统识别方法的弊端,强调深度学习技术应用于蘑菇识别的必要性与价值(保障安全、助力科研、规范产业);
- 技术路线的清晰性:详细说明 CNN 算法原理、模型训练过程,以及 B/S 架构、Java、MySQL 等技术在系统中的具体应用,体现技术可行性;
- 系统设计的完整性:重点呈现整体架构、功能模块划分、数据库逻辑(E-R 图)与物理设计(表结构),确保设计方案可落地;
- 核心功能的实现细节:聚焦图像识别功能的前后端交互流程、模型调用方式、预处理与预测过程,以及用户 / 管理员核心功能的技术实现手段;
- 测试与验证的严谨性:明确测试目的、方法,详细列出功能测试(尤其是识别准确率)、性能测试(响应时间、稳定性)结果,客观分析系统优势与不足;
- 总结与展望的针对性:凝练系统核心成果,精准指出当前不足(如相似蘑菇模糊图片误判、高并发加载慢),并提出可行的优化方向(升级模型、增加训练数据、负载均衡)。
六、功能截图