本章介绍为单个运行进程 提供的新抽象:线程(thread) 。经典观点是一个程序只有一个执行点 (一个程序计数器,用来存放要执行的指令),但多线程(multi-threaded)程序会有多个执行点 (多个程序计数器,每个都用于取指令和执行)。换一个角度来看,每个线程类似于独立的进程 ,只有一点区别:它们共享地址空间 ,从而能够访问相同的数据。
因此,单个线程的状态与进程状态非常类似。线程有一个程序计数器(PC) ,记录程序从哪里获取指令。每个线程有自己的一组用于计算的寄存器 。所以,如果有两个线程运行在一个处理器上,从运行一个线程(T1)切换到另一个线程(T2) 时,必定发生上下文切换 (context switch)。线程之间的上下文切换类似于进程间的上下文切换 。对于进程 ,我们将状态保存到进程控制块 (Process Control Block,PCB )。现在,我们需要一个或多个线程控制块 (Thread Control Block,TCB ),保存每个线程的状态 。但是,与进程相比,线程之间的上下文切换有一点主要区别:地址空间保持不变(即不需要切换当前使用的页表)。
线程和进程 之间的另一个主要区别 在于栈 。在简单的传统进程地址空间模型 可以称之为**单线程(single-threaded)进程** 中,只有一个栈 ,通常位于地址空间的底部(见 图26.1 左图)。
然而,在多线程的进程 中,每个线程独立运行,可以调用各种例程来完成正在执行的任何工作。不是地址空间中只有一个栈,而是每个线程都有一个栈。 假设有一个多线程的进程,它有两个线程,结果地址空间看起来不同。(图26.1 右图)
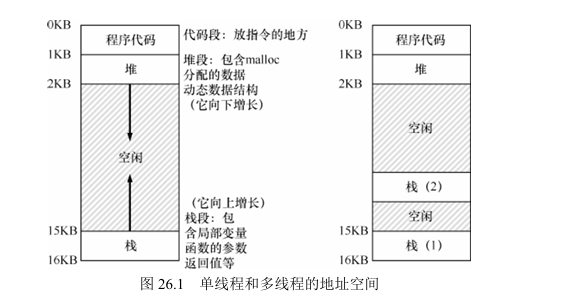
在 图26.1 中,可以看到两个栈跨越了进程的地址空间。因此,所有位于栈上的变量、参数 、返回值和其他放在栈上的东西 ,将被放置在有时称为线程本地(thread-local)存储的地方,即相关线程的栈。
一、实例:线程创建
假设想运行一个程序,它创建两个线程,每个线程都做了一些独立的工作,在这例子中,打印"A"或"B"。代码如图26.2所示。
主程序创建了两个线程 ,分别执行函数 mythread() ,但是传入不同的参数(字符串类型的 A或者 B)。一旦线程创建,可能会立即运行(取决于调度程序的兴致),或者处于就绪状态,等待执行。创建了两个线程(T1和T2)后,主程序调用pthread_join(),等待特定线程完成。

小程序可能执行顺序,在表 26.1 中,向下方向表示时间增加,每个列显式不同的线程(主线程、线程1 或 线程2)何时运行。

但请注意,这种排序不是唯一可能的顺序。实际上,给定一系列指令,有很多可能的顺序,这取决于调度程序决定在给定时刻运行哪个线程 。例如,创建一个线程后,它可能会立即运行,这将导致表26.2中的执行顺序。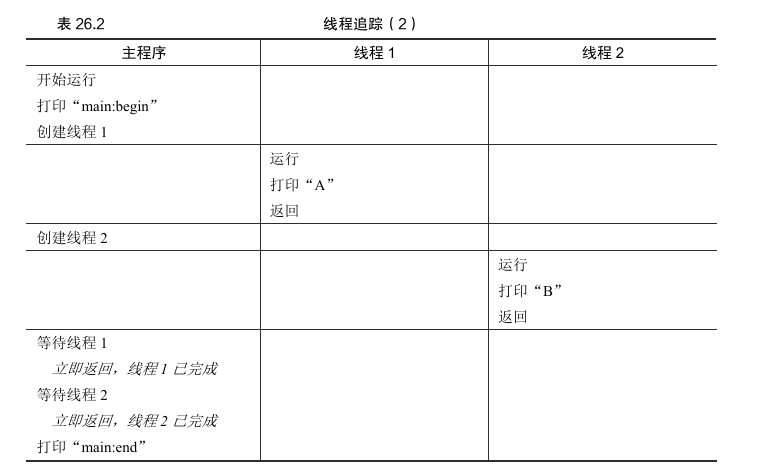
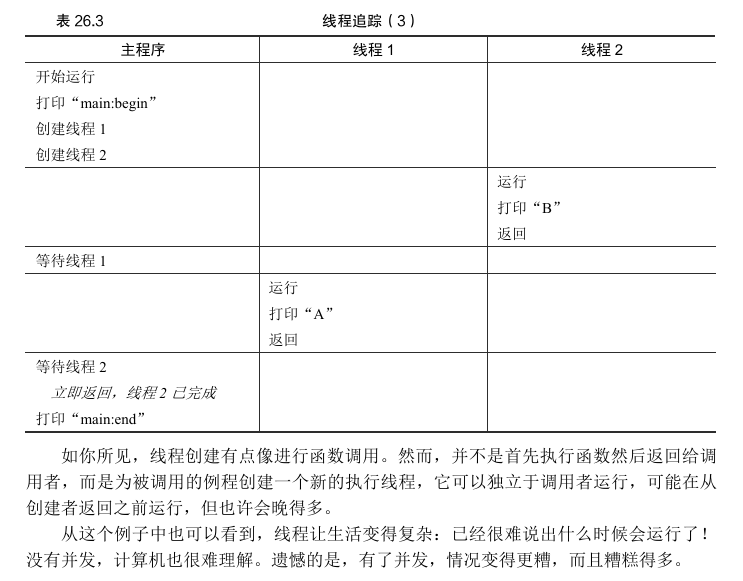
我们甚至可以在 "A" 之前看到 "B",即使先前创建了线程1,如果调度程序决定先运行线程2,没有理由认为先创建的线程先运行。表26.3展示了最终的执行顺序,线程2在线程1之前先展示结果
二、为什么更糟糕:共享数据
上面演示的简单线程示例非常有用,它展示了线程如何创建,根据调度程序的决定,它们如何以不同顺序运行。但是,它没有展示线程在访问共享数据时如何相互作用。
设想一个简单的例子,其中两个线程希望更新全局共享变量。我们要研究的代码如图26.3 所示
#include <stdio.h>
#include <pthread.h>
#include "mythreads.h"
static volatile int counter = 0;
//
// mythread()
//
// Simply adds 1 to counter repeatedly, in a loop
// No, this is not how you would add 10,000,000 to
// a counter, but it shows the problem nicely.
//
void *
mythread(void *arg)
{
printf("%s: begin\n", (char *) arg);
int i;
for (i = 0; i < 1e7; i++) {
counter = counter + 1;
}
printf("%s: done\n", (char *) arg);
return NULL;
}
//
// main()
//
// Just launches two threads (pthread_create)
// and then waits for them (pthread_join)
int
main(int argc, char *argv[])
{
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: done with both (counter = %d)\n", counter);
return 0;
} 以下是代码的一些说明:封装了线程创建和合并例程 ,以便在失败时退出 。对于这样简单的程序,我们希望至少注意到发生了错误(如果发生了错误),但不做任何非常聪明的处理(只是退出)。因此,Pthread_create()只需调用 pthread_create(),并确保返回码为 0。如果不是,Pthread_create()就打印一条消息并退出。
其次,没有用两个独立的函数作为工作线程,只使用了一段代码,并向线程传入一个参数(本例中是一个字符串),这样就可以让每个线程在打印其消息前,打印不同的字母。
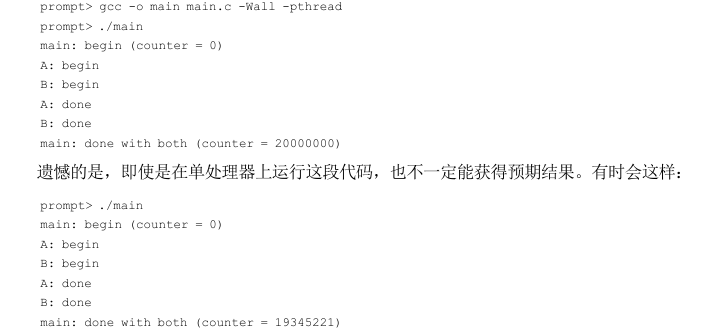
最后,可以看每个工作线程正在尝试做什么:向共享变量计数器添加一个数字,并在循环中执行 1000万次。因此,预期结果是:20000000。
现在编译并运行该程序,观察它的行为。有时候,一切如我们预期的那样:
三、核心问题:不可控的调度
为了理解为什么会发生这种情况,我们必须了解编译器为更新计数器生成的代码序列。 在这个例子中,只是给 counter 加上一个数字(1)。因此,做这件事的代码序列可能看起来像这样(在x86中):
mov 0x8049a1c,%eax
add $0x1,%eax
mov %eax,0x8049a1c
这个例子假定,变量 counter 位于地址 0x8049a1c。在这3条指令中,先用x86的 mov 指令,从内存地址处取出值,放入 eax 。然后,给 eax 寄存器的值加 1(0x1)。最后,eax 的值被存回内存中相同的地址。
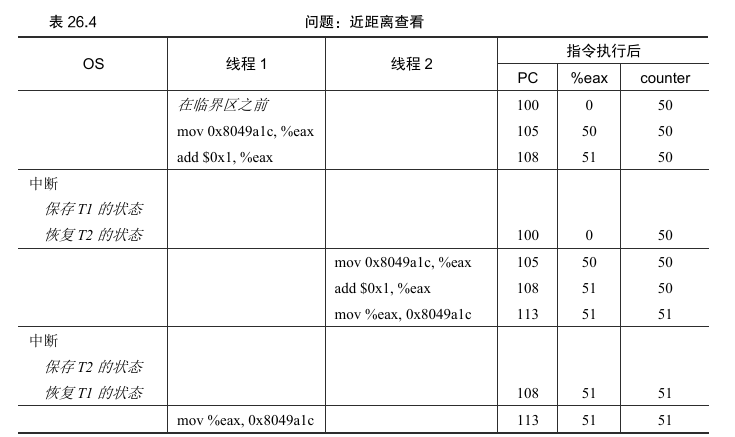
设想两个线程之一(线程1)进入这个代码区域,并且因此将要增加一个计数器。它将counter 的值(假设它这时是50)加载到它的寄存器 eax 中。因此,线程1 的 eax = 50。然后它向寄存器加 1,因此 eax = 51。现在,①一件不幸的事情发生了:时钟中断发生 。因此,操作系统将当前正在运行的线程 (它的程序计数器、寄存器,包括eax等)的状态 保存到线程的TCB。
② 现在更糟的事发生了:线程 2 被选中运行,并进入同一段代码。它也执行了第一条指令 ,获取计数器的值并将其放入其 eax 中 请记住:运行时**每个线程都有自己的专用寄存器** 。上下文切换代码将寄存器虚拟化(virtualized),**保存并恢复它们的值** 。此时counter的值仍为 50,因此线程2的eax = 50。假设线程2执行接下来的两条指令,将eax递增1(因此eax = 51),然后将 eax 的内容保存到counter(地址0x8049a1c)中 。因此,全局变量 counter现在的值是51。
③ 最后,又发生一次上下文切换 ,线程 1 恢复运行。还记得它已经执行过 mov 和 add 指令,现在准备执行最后一条 mov 指令。回忆一下,eax=51。因此,最后的 mov 指令执行, 将值保存到内存,counter 再次被设置为51。
简单来说,发生的情况是:增加 counter 的代码被执行两次,初始值为 50,但是结果为 51。这个程序的" 正确 "版本应该导致变量 counter 等于52。
为了更好地理解问题,追踪详细的执行。假设在这个例子中,上面的代码被加载到内存中的地址 100 上,就像下面的序列一样(熟悉类似 RISC 指令集的人请注意:x86 具有可变长度指令。这个 mov 指令占用 5 个字节的内存,add只占用3个字节):
100 mov 0x8049a1c, %eax
105 add $0x1, %eax
108 mov %eax, 0x8049a1c
发生的情况如表 26.4 所示。假设 counter 从 50 开始,并追踪这个例子,确保明白发生什么
展示的情况称为竞态条件 (race condition):结果取决于代码的时间执行 。由于运气不好(即在执行过程中发生的上下文切换),得到了错误的结果。事实上,可能每次都会得到不同的结果。因此,我们称这个结果是不确定的(indeterminate),而不是确定的 (deterministic)计算(我们习惯于从计算机中得到)。不确定的计算不知道输出是什么,它在不同运行中确实可能是不同的。
由于执行这段代码的多个线程可能导致竞争状态 ,因此我们将此段代码 称为临界区 (critical section)。临界区是访问共享变量(或更一般地说,共享资源)的代码片段 ,一定不能由多个线程同时执行。
真正想要的代码就是所谓的互斥 (mutual exclusion)。这个属性保证了如果一个线程在临界区内执行,其他线程将被阻止进入临界区。
四、原子性愿望
解决这个问题的一种途径是拥有更强大的指令,单步就能完成要做的事,从而消除不合时宜的中断的可能性。比如,如果有这样一条超级指令怎么样?
memory-add 0x8049a1c , $0x1
假设这条指令将一个值添加到内存位置 ,并且硬件保证它以原子方式(atomically)执行 。当指令执行时,它会像期望那样执行更新。它不能在指令中间中断 ,因为这正是我们从硬件获得的保证:发生中断时,指令根本没有运行,或者运行完成,没有中间状态。
在这里,原子方式 的意思是**"作为一个单元"**,有时我们说"全部或没有"。希望以原子方式执行3个指令的序列:
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c
如果有一条指令来做到这一点,我们可以发出这条指令然后完事。但在一般情况下,不会有这样的指令 。设想我们要构建一个并发的 B 树,并希望更新它。我们真的希望硬件支持 " B树的原子性更新 " 指令吗?可能不会,至少理智的指令集不会。
因此,要做的是要求硬件提供一些有用的指令 ,可以在这些指令上构建一个通用的集合,即所谓的同步原语 (synchronization primitive)。通过使用这些硬件同步原语,加上操作系统的一些帮助,我们将能够构建多线程代码,以同步和受控的方式访问临界区,从而可靠地产生正确的结果------ 尽管有并发执行的挑战。

五、等待另一个线程
本章提出了并发问题,就好像线程之间只有一种交互,即访问共享变量 ,因此需要为临界区支持原子性 。事实证明,还有另一种常见的交互,即一个线程在继续之前必须等待另一个线程完成某些操作。例如,当进程执行磁盘 I/O 并进入睡眠状态时,会产生这种交互。 当 I/O 完成时,该进程需要从睡眠中唤醒,以便继续进行。
在接下来的章节中,我们不仅要研究如何构建对同步原语的支持来支持原子性 , 还要研究支持在多线程程序中常见的睡眠/唤醒交互的机制。
