k8s监控方案实践(二): 集成Alertmanager告警与钉钉Webhook通知
文章目录
- [k8s监控方案实践(二): 集成Alertmanager告警与钉钉Webhook通知](#k8s监控方案实践(二): 集成Alertmanager告警与钉钉Webhook通知)
- 一、Alertmanager简介
-
- [1. 什么是Alertmanager?](#1. 什么是Alertmanager?)
- [2. Prometheus与Alertmanager的工作流程](#2. Prometheus与Alertmanager的工作流程)
- 二、Alertmanager实战部署
-
- [1. 创建Namespace(prometheus-namespace.yaml)](#1. 创建Namespace(prometheus-namespace.yaml))
- [2. 创建ConfigMap(alertmanager-config.yaml)](#2. 创建ConfigMap(alertmanager-config.yaml))
- [3. 创建Service(alertmanager-svc.yaml)](#3. 创建Service(alertmanager-svc.yaml))
- [4. 创建Deployment(alertmanager-deploy.yaml)](#4. 创建Deployment(alertmanager-deploy.yaml))
- [5. 部署所有资源](#5. 部署所有资源)
- 三、Prometheus告警规则配置
-
- [1. 配置Pormetheus告警规则](#1. 配置Pormetheus告警规则)
- [2. 配置Prometheus与Alertmanager通信](#2. 配置Prometheus与Alertmanager通信)
- 四、集成钉钉Webhook
-
- [1. 创建ConfigMap(webhook-dingtalk-config.yaml)](#1. 创建ConfigMap(webhook-dingtalk-config.yaml))
- [2. 创建Service(webhook-dingtalk-svc.yaml)](#2. 创建Service(webhook-dingtalk-svc.yaml))
- [3. 创建Deployment(webhook-dingtalk-deploy.yaml)](#3. 创建Deployment(webhook-dingtalk-deploy.yaml))
- [4. 创建模板文件(webhook-dingtalk-templates.yaml )](#4. 创建模板文件(webhook-dingtalk-templates.yaml ))
- [5. 部署所有资源](#5. 部署所有资源)
- 总结
随着容器化和微服务架构的不断发展,系统的复杂性与日俱增,构建一套完善的监控与告警体系已成为保障系统稳定运行的关键。在上一篇文章中,我们介绍了如何在 Kubernetes 中部署 Prometheus,并集成 Node Exporter 实现对节点资源的基础监控,为整体可观测性打下了坚实基础。
在本篇中,我们将继续完善监控体系,重点介绍如何部署 Alertmanager 并配置 Prometheus 告警规则,帮助我们及时感知系统异常,并通过钉钉、飞书等方式实现告警通知,进一步提升运维响应能力与系统可靠性。
一、Alertmanager简介
1. 什么是Alertmanager?
Alertmanager 是 Prometheus 生态中的核心组件之一,主要用于接收 Prometheus 发送的告警(Alerts),并按照用户定义的规则对这些告警进行:
- 去重(Deduplication):避免重复告警干扰
- 分组(Grouping):相似告警聚合成一条,提升可读性
- 抑制(Silencing):在特定情况下抑制某些告警,如在维护窗口中
- 路由(Routing):按标签或规则将不同告警分发到不同的接收人或平台
- 通知(Notification):最终将告警通过 Email、Slack、Webhook、飞书、钉钉等方式发送出去
2. Prometheus与Alertmanager的工作流程
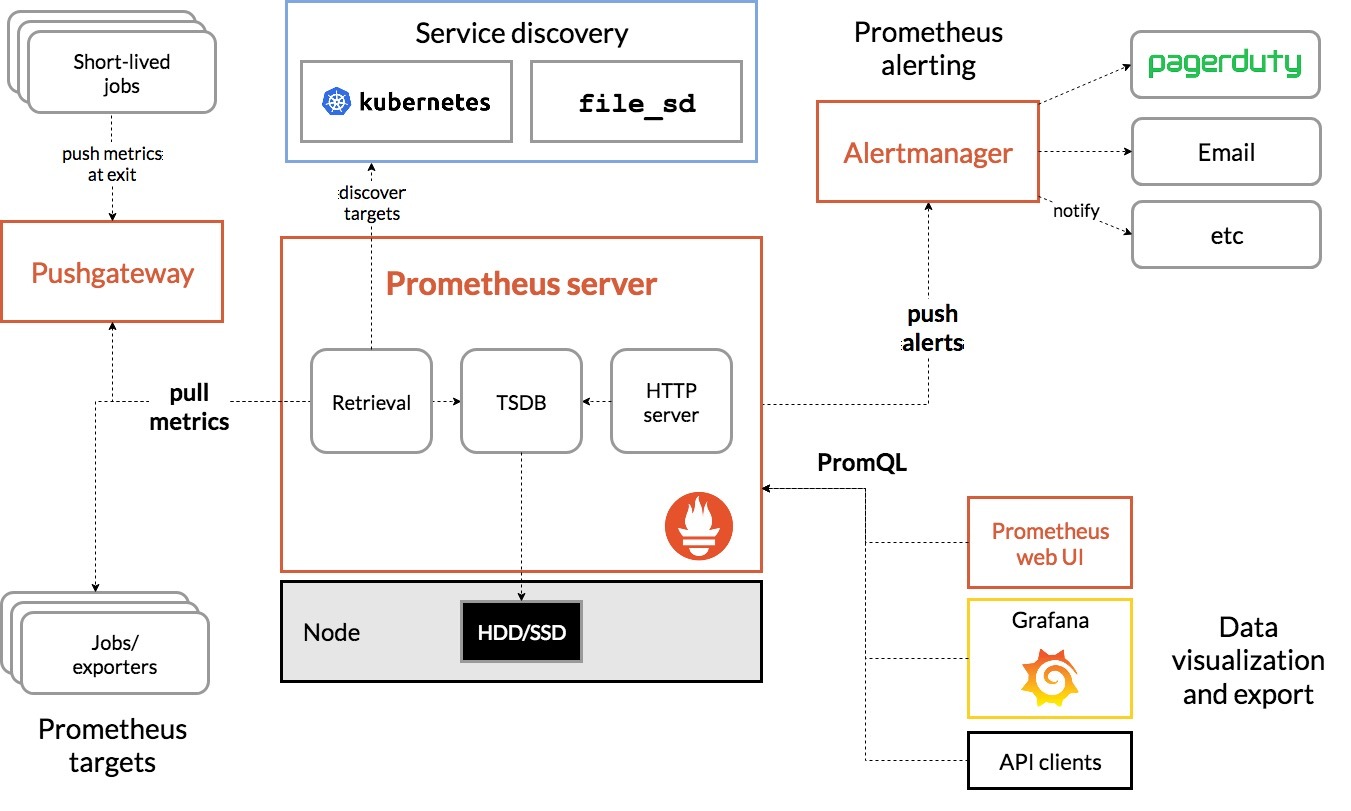
Alertmanager 并不主动采集数据,它只处理告警。以下是 Prometheus 与 Alertmanager 的协作流程:
- Prometheus 定期根据配置文件中定义的告警规则(alerting rules)对收集到的时间序列数据进行评估
- 当满足某条规则的触发条件时,Prometheus 会将该规则对应的 Alert(告警)发送给 Alertmanager
- Alertmanager 收到告警后,进行上述的去重、分组、路由和通知
- 用户通过接收端(如钉钉群、邮箱等)接收到告警信息
✅ 提示:Prometheus 与 Alertmanager 之间通过 HTTP 协议通信,默认使用端口 9093 接收告警。
二、Alertmanager实战部署
1. 创建Namespace(prometheus-namespace.yaml)
创建名为prometheus的命名空间,用于隔离部署监控相关资源
yaml
apiVersion: v1
kind: Namespace
metadata:
name: prometheus2. 创建ConfigMap(alertmanager-config.yaml)
配置 Alertmanager 的基本设置,包括告警的路由、分组规则、抑制规则以及通知方式等。下面配置了钉钉 webhook 作为告警接收渠道
yaml
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: aalertmanager
name: alertmanager-config
namespace: prometheus
data:
config.yml: |
global:
#旧的告警3分钟没有更新,则认为告警解决
resolve_timeout: 3m
route:
group_by: ['alertname'] #根据告警规则组名进行分组
group_wait: 0s #在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现
group_interval: 10s #控制告警组的发送频率,一条告警消息发送后,等待10秒,发送第二组告警
repeat_interval: 1h #发送报警间隔,如果指定时间内没有修复,则重新发送报警
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs: #钉钉 webhook 地址
- url: 'http://dingtalk.prometheus.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true #表示服务恢复后会收到恢复告警
inhibit_rules: #配置抑制告警规则
- source_match:
severity: 'error' #如果源告警为 error,目标告警为 warn,则抑制该目标告警
target_match:
severity: 'warn'
equal: ['alertname', 'target', 'job', 'instance'] #相同标签的告警才会抑制
- source_match:
severity: 'warn'
target_match:
severity: 'info'
equal: ['alertname', 'target', 'job', 'instance']3. 创建Service(alertmanager-svc.yaml)
为 Alertmanager 创建一个专用的 Service,使其可以暴露给 Prometheus 使用
yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: prometheus
labels:
app: alertmanager
spec:
ports:
- port: 9093
targetPort: 9093
protocol: TCP
selector:
app: alertmanager4. 创建Deployment(alertmanager-deploy.yaml)
部署 Alertmanager 到 Kubernetes 集群,挂载配置文件并设置必要的启动参数
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.local/k8s/alertmanager:0.25.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9093
protocol: TCP
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
volumeMounts:
- mountPath: /etc/alertmanager/
name: alertmanager-config
volumes:
- name: alertmanager-config
configMap:
name: alertmanager-config5. 部署所有资源
bash
kubectl apply -f prometheus-namespace.yaml
kubectl apply -f alertmanager-config.yaml
kubectl apply -f alertmanager-svc.yaml
kubectl apply -f alertmanager-deploy.yaml三、Prometheus告警规则配置
1. 配置Pormetheus告警规则
/kubernetes/prometheus/rules 目录下创建 k8s-node_exporter.yml,用于定义监控条件,例如内存、CPU使用率等告警条件(这里不清楚为什么是这个目录的看上一篇文章)
yaml
groups:
- name: K8S服务器告警
rules:
- alert: "K8S服务器内存告警"
expr: 100 - ((node_memory_MemAvailable_bytes{job=~"k8s.*"} * 100) / node_memory_MemTotal_bytes{job=~"k8s.*"}) > 90
for: 5m
labels:
severity: warn
annotations:
summary: "{{ $labels.instance }} 内存使用率过高,请尽快处理!"
description: '{{ $labels.instance }}内存使用率90%,当前使用率{{ printf "%.2f" .Value }}%.'
- alert: "K8S服务器磁盘空间告警"
expr: (1 - node_filesystem_avail_bytes{job=~"k8s.*", fstype=~"ext4|xfs"} / node_filesystem_size_bytes{job=~"k8s.*",fstype=~"ext4|xfs"}) * 100 > 90
for: 60s
labels:
severity: warn
annotations:
summary: "{{ $labels.instance }}磁盘空间使用超过90%了"
description: '{{ $labels.instance }}磁盘使用率超过90%,当前使用率{{ printf "%.2f" .Value }}%.'
- alert: "K8S服务器CPU告警"
expr: 100-(avg(irate(node_cpu_seconds_total{job=~"k8s.*",mode="idle"}[5m])) by(instance)* 100) > 90
for: 5m
labels:
severity: warn
instance: "{{ $labels.instance }}"
annotations:
summary: "{{$labels.instance}}CPU使用率超过90%了"
description: '{{ $labels.instance }}CPU使用率超过90%,当前使用率{{ printf "%.2f" .Value }}%.'
- alert: "K8S服务器负载告警"
expr: (node_load15{job=~"k8s.*"}) > 50
for: 5m
labels:
severity: warn
instance: "{{ $labels.instance }}"
annotations:
summary: "{{$labels.instance}}服务器负载异常"
description: '{{ $labels.instance }}服务器负载异常,当前负载{{ printf "%.2f" .Value }}%.'
- alert: "K8S服务器IO性能告警"
expr: ((irate(node_disk_io_time_seconds_total{job=~"k8s.*"}[30m]))* 100) > 95
for: 5m
labels:
severity: warn
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
description: '{{$labels.instance}} 流入磁盘IO大于95%,当前使用率{{ printf "%.2f" .Value }}%.'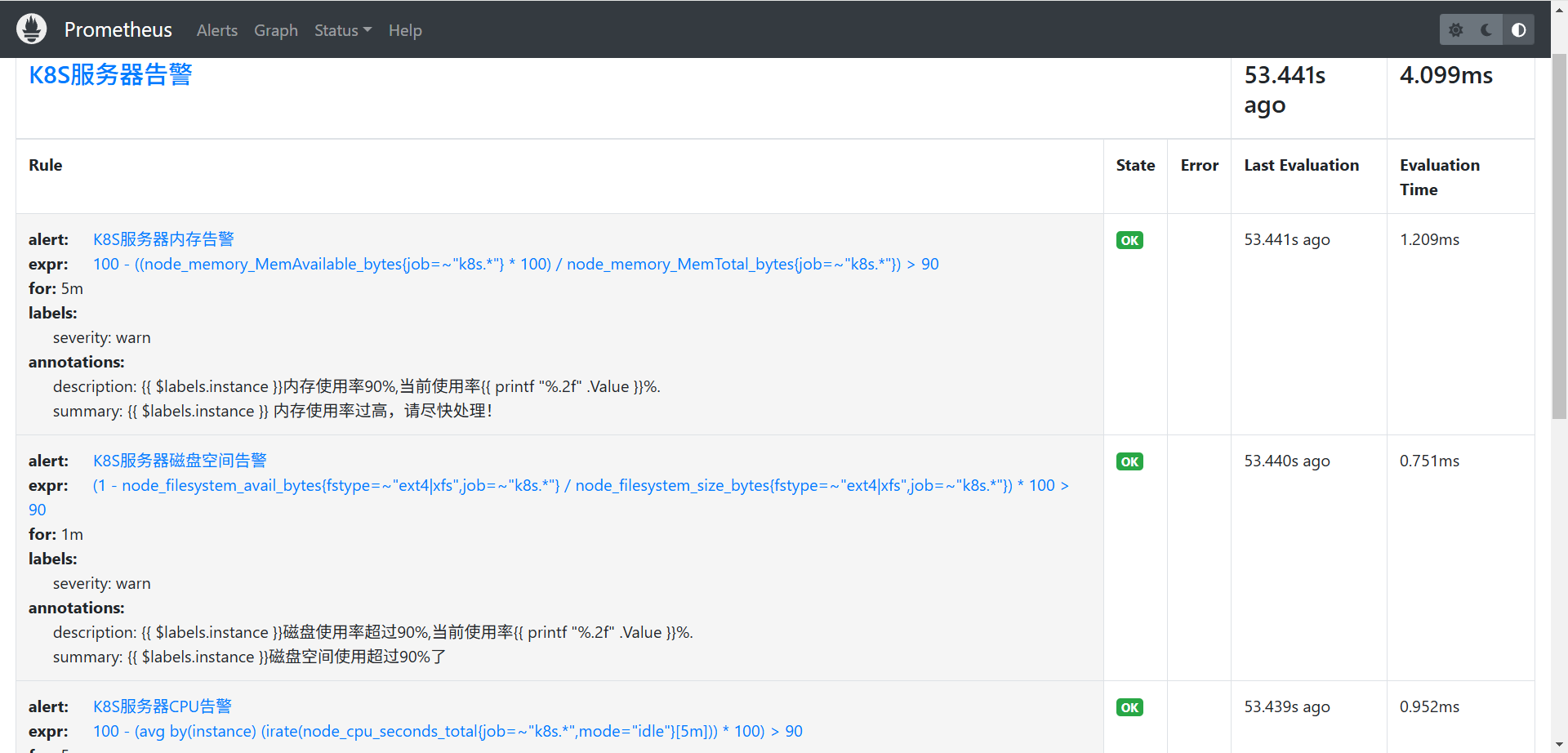
2. 配置Prometheus与Alertmanager通信
确保 Prometheus 的配置文件已正确配置以与 Alertmanager 通信
yaml
data:
prometheus.yml: |
global:
scrape_interval: 15s #抓取数据的间隔时间
scrape_timeout: 10s #超时时间
evaluation_interval: 1m #评估时间
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager.prometheus.svc.cluster.local:9093']
四、集成钉钉Webhook
由于 Alertmanager 本身不直接支持钉钉告警推送,我们通过部署一个中间转发服务来处理 Prometheus 的告警并发送到钉钉。这里使用 prometheus-webhook-dingtalk 服务来实现这一功能
1. 创建ConfigMap(webhook-dingtalk-config.yaml)
创建 webhook-dingtalk-config.yaml,配置钉钉机器人的地址、密钥和告警模板
yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: dingtalk
name: dingtalk-config
namespace: prometheus
data:
config.yml: |
templates:
- /etc/prometheus-webhook-dingtalk/templates/template.tmpl
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxx #替换成实际的钉钉机器人token
secret: xxx #加签配置
message:
text: '{{ template "email.to.message" . }}' #使用模板格式化消息2. 创建Service(webhook-dingtalk-svc.yaml)
yaml
apiVersion: v1
kind: Service
metadata:
name: dingtalk
namespace: prometheus
labels:
app: dingtalk
spec:
ports:
- port: 8060
targetPort: 8060
protocol: TCP
selector:
app: dingtalk3. 创建Deployment(webhook-dingtalk-deploy.yaml)
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-webhook-dingtalk
namespace: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: dingtalk
template:
metadata:
labels:
app: dingtalk
spec:
containers:
- name: webhook-dingtalk
image: harbor.local/k8s/prometheus-webhook-dingtalk:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8060
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus-webhook-dingtalk/
name: dingtalk-config
- mountPath: /etc/prometheus-webhook-dingtalk/templates/
name: dingtalk-templates
volumes:
- name: dingtalk-config
configMap:
name: dingtalk-config
- name: dingtalk-templates
configMap:
name: dingtalk-templates4. 创建模板文件(webhook-dingtalk-templates.yaml )
该模板将告警格式化为钉钉支持的 Markdown 格式
yaml
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: dingtalk
name: dingtalk-templates
namespace: prometheus
data:
template.tmpl: |
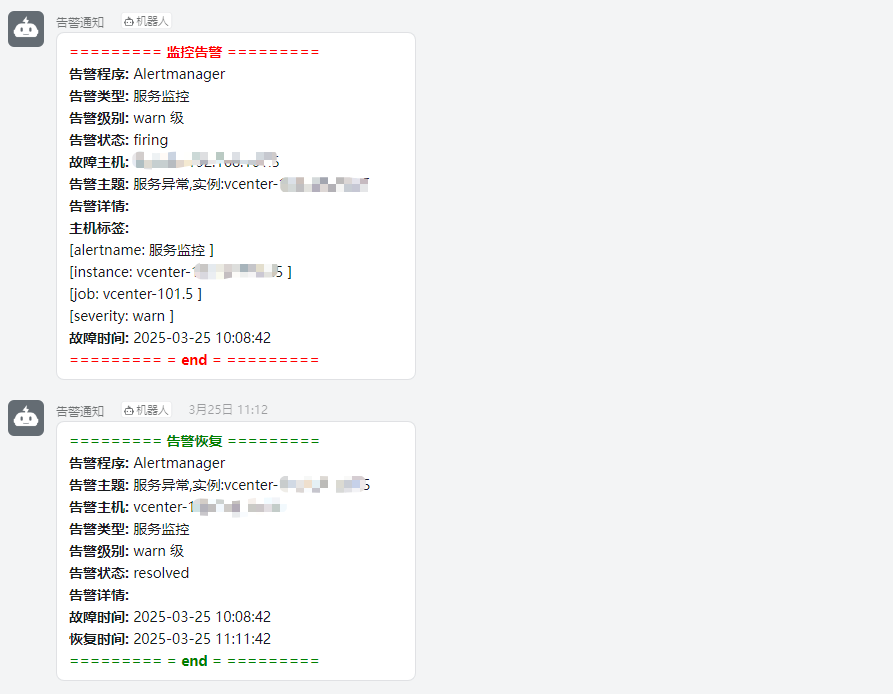
{{ define "email.to.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
<font color=#FF0000>========= **监控告警** ========= </font>
**告警程序:** Alertmanager
**告警类型:** {{ $alert.Labels.alertname }}
**告警级别:** {{ $alert.Labels.severity }} 级
**告警状态:** {{ .Status }}
**故障主机:** {{ $alert.Labels.instance }} {{ $alert.Labels.device }}
**告警主题:** {{ .Annotations.summary }}
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
**主机标签:** {{ range .Labels.SortedPairs }} </br> [{{ .Name }}: {{ .Value | markdown | html }} ]
{{- end }} </br>
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
<font color=#FF0000>========= = **end** = ========= </font>
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
<font color=#00800>========= **告警恢复** ========= </font>
**告警程序:** Alertmanager
**告警主题:** {{ $alert.Annotations.summary }}
**告警主机:** {{ .Labels.instance }}
**告警类型:** {{ .Labels.alertname }}
**告警级别:** {{ $alert.Labels.severity }} 级
**告警状态:** {{ .Status }}
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间:** {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
<font color=#00800>========= = **end** = ========= </font>
{{- end }}
{{- end }}
{{- end }}5. 部署所有资源
bash
kubectl apply -f webhook-dingtalk-config.yaml
kubectl apply -f webhook-dingtalk-svc.yaml
kubectl apply -f webhook-dingtalk-deploy.yaml
kubectl apply -f webhook-dingtalk-templates.yaml至此,Alertmanager 配置完毕,Prometheus 告警可以通过钉钉 Webhook 发送通知
总结
🚀 本篇详细介绍了在 Kubernetes 环境中部署 Prometheus 与 Alertmanager,并结合钉钉 Webhook 实现监控告警通知的完整流程。通过配置告警规则和通知渠道,可以及时掌握集群关键指标变化,提高系统稳定性和运维响应效率。
✅下一篇将介绍如何在 Kubernetes 中部署并配置 Grafana,实现监控数据的可视化展示,打造高效直观的监控面板。