ICLR 2025 spotlight
paper
构建能够在少量样本下学习出优良策略的深度强化学习(RL)智能体一直是一个极具挑战性的任务。为了提高样本效率,近期的研究尝试在每获取一个新样本后执行大量的梯度更新。尽管这种高更新-数据比(UTD)策略在实证中表现良好,但它也会导致训练过程中的不稳定性。以往方法常常依赖周期性地重置神经网络参数以应对这种不稳定性,但在许多实际应用中,重启训练流程是不可行的,并且需要对重置的时间间隔进行调参。在本文中,我们关注于在有限样本条件下实现稳定训练所面临的一个核心难点:学习得到的价值函数无法泛化到未观察到的在策略动作上。我们通过引入由学习到的世界模型生成的少量数据,直接缓解了这一问题。我们提出的方法------用于时序差分学习的模型增强数据(Model-Augmented Data for Temporal Difference learning,简称 MAD-TD)------利用少量生成数据来稳定高 UTD 的训练过程,并在 DeepMind 控制套件中最具挑战性的任务上取得了有竞争力的性能。我们的实验进一步强调了使用优质模型生成数据的重要性,MAD-TD 抗击价值函数高估的能力,以及其在持续学习中带来的实际稳定性提升。
MAD-TD基于TD3算法,并对参数采用UTD=8的默认更新。对critic的采用DYNA架构下的real-data以及simulate-data以5%混合比例采样。
其中模型采用类似TD-MPC2,需要训练encoder对状态进行表征;对critic采用HL-Gauss (上一篇《Stop regressing: Training value functions via classification for scalable deep RL》);世界模型根据给定的encoder后的状态和动作 a 预测下一状态的潜在表示和观察到的奖励。模型训练损失有三个项:编码下一状态的 SimNorm 表征的交叉熵损失、奖励预测的 MSE 以及下一状态critic估计与预测状态的critic估计之间的交叉熵。
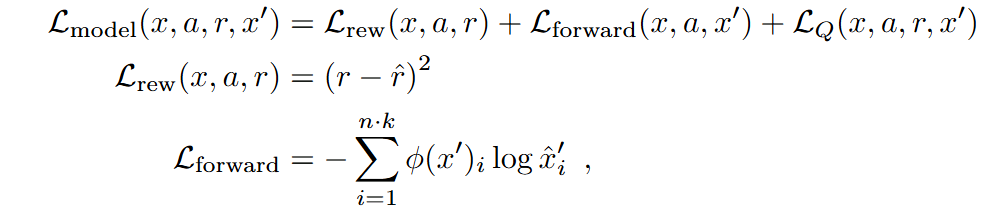
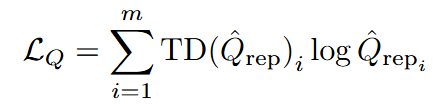
算法核心在基于模型的数据的合成,后面也对比了基于Diffusion-model的方法:
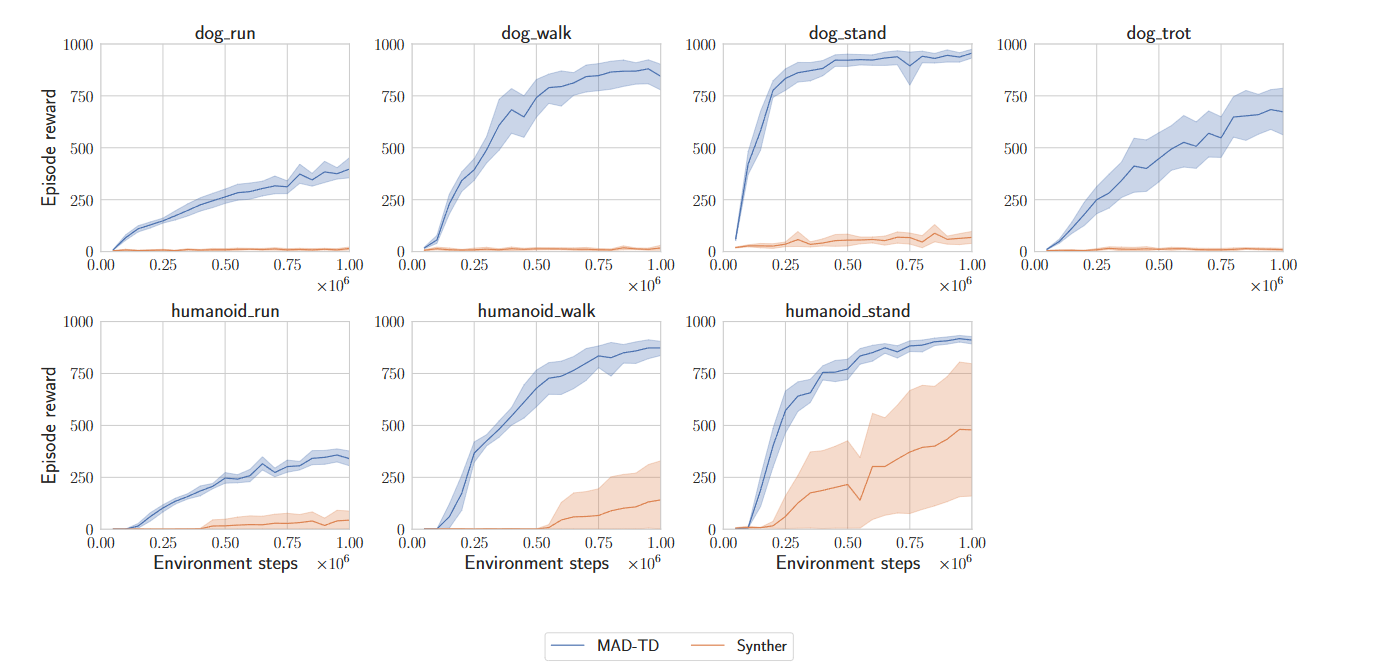
文章分析Synther失败是由于Q值发散,学习的价值函数无法实现有效泛化。总结就是合成数据的同时能学习到有效的价值函数尤其重要。