关于Streamlit的介绍,可参考《玩转Streamlit》系列
在当今数据驱动的时代,快速构建交互式工具并直观地将数据分析结果交付给用户,已成为数据应用开发的核心需求。
无论是企业内部的决策支持系统,还是面向公众的数据可视化平台,都需要一种高效且灵活的开发方式。
Plotly和Streamlit的结合,正是满足这一需求的完美解决方案。
Plotly作为一个强大的交互式图表库,支持多种图表类型,能够轻松创建动态且美观的可视化效果。
而 Streamlit 是一个轻量级、低代码的 Web 应用框架,专注于简化数据应用的开发流程,让开发者能够快速构建并部署交互式应用。
二者的互补性显而易见:
Plotly:支持40+交互式图表类型,从基础折线图到 3D 曲面图应有尽有Streamlit:用纯Python脚本即可创建Web应用,部署时间从数周缩短到数小时
本文主要介绍如何结合Plotly和Streamlit开发动态数据应用,并优化其性能。
1. Streamlit应用中嵌入Plotly图表
1.1. 静态图表嵌入
将Plotly图表嵌入Streamlit应用的基础方法是通过st.plotly_chart()函数直接渲染Plotly图表。
这种方式简单直接,能够快速将图表展示在页面上。
以下是一个将折线图 和热力图 嵌入 Streamlit 页面的示例代码:
python
import streamlit as st
import plotly.express as px
import pandas as pd
# 创建一个简单的折线图
df = pd.DataFrame({"x": [1, 2, 3, 4, 5], "y": [10, 11, 12, 13, 14]})
line_fig = px.line(df, x="x", y="y", title="折线图示例")
# 创建一个热力图
heatmap_data = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6], "C": [7, 8, 9]})
heatmap_fig = px.imshow(heatmap_data, title="热力图示例")
# 在 Streamlit 中展示图表
st.plotly_chart(line_fig)
st.plotly_chart(heatmap_fig)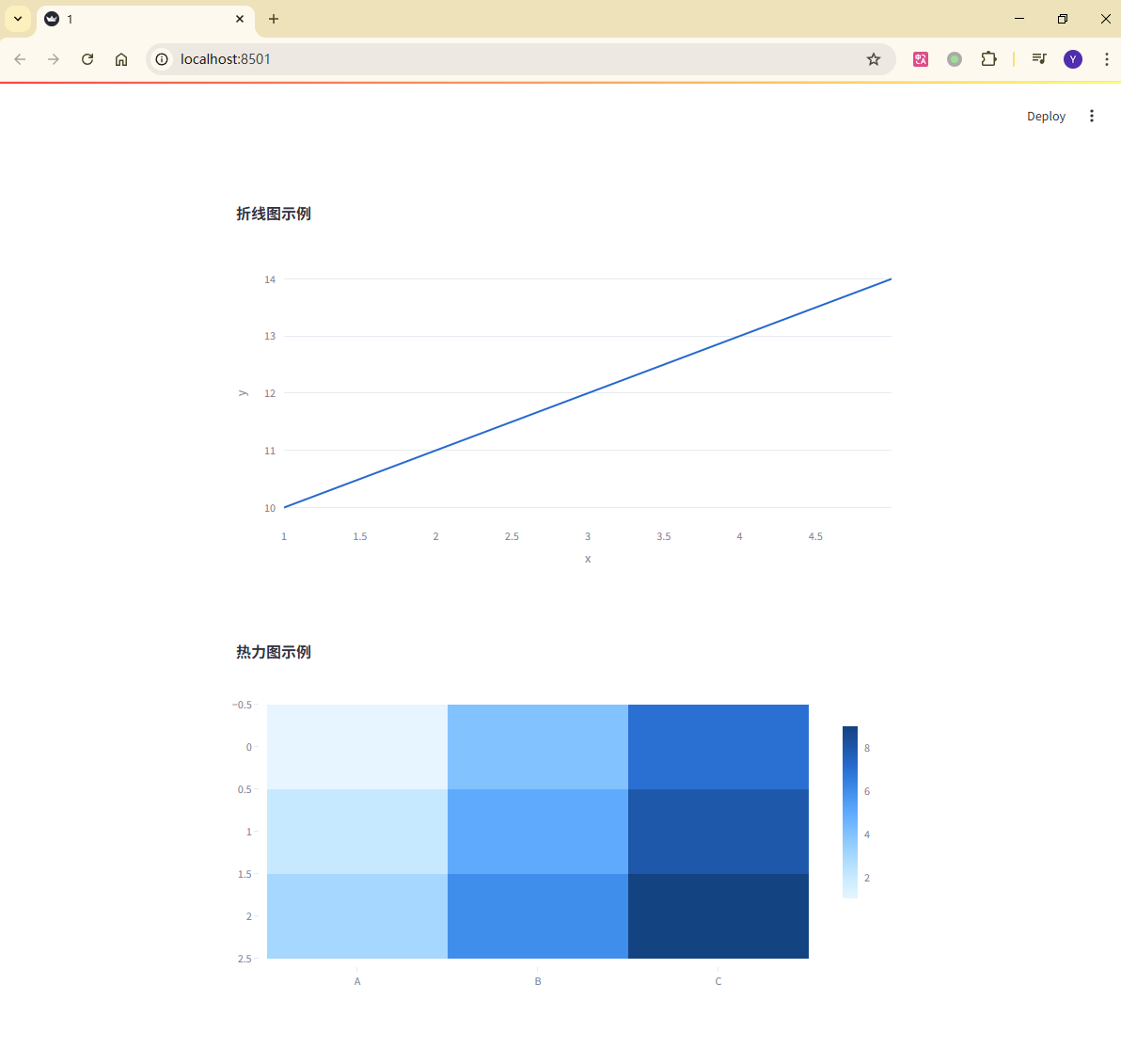
1.2. 图表与组件交互
Plotly图表的强大之处不仅在于其静态展示 能力,更在于其动态交互性。
通过结合Streamlit的交互组件(如st.slider和st.selectbox),可以实现图表参数的动态控制,从而为用户提供更加灵活的可视化体验。
以下是一个案例,展示如何通过用户选择的日期范围 实时更新K 线图:
python
import streamlit as st
import plotly.graph_objects as go
import pandas as pd
# 获取K线数据
data = pd.read_parquet(
r"/path/to/BTC-USDT_1h.parquet"
)
# 创建日期范围选择器
start_date = st.date_input("开始日期", value=data["candle_begin_time"].min())
end_date = st.date_input("结束日期", value=data["candle_begin_time"].max())
# 根据选择的日期范围筛选数据
filtered_data = data.query(
"candle_begin_time >= @start_date & candle_begin_time <= @end_date"
)
# 创建 K 线图
fig = go.Figure(
data=[
go.Candlestick(
x=filtered_data.index,
open=filtered_data["open"],
high=filtered_data["high"],
low=filtered_data["low"],
close=filtered_data["close"],
)
]
)
fig.update_layout(title="K 线图", xaxis_title="日期", yaxis_title="价格")
# 在 Streamlit 中展示图表
st.plotly_chart(fig)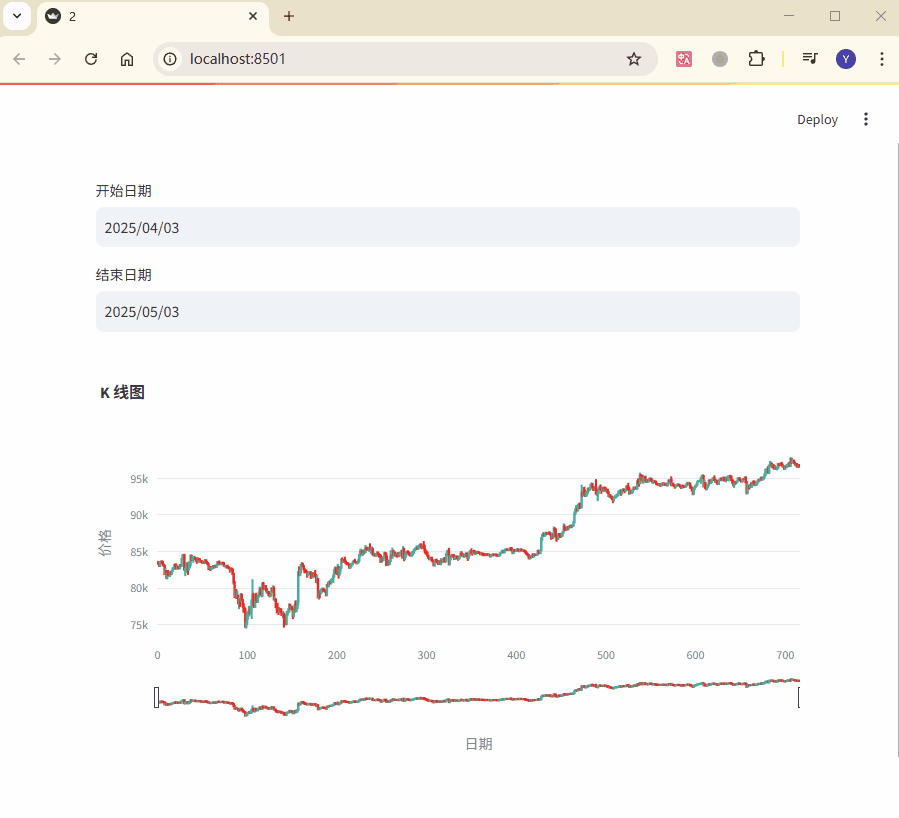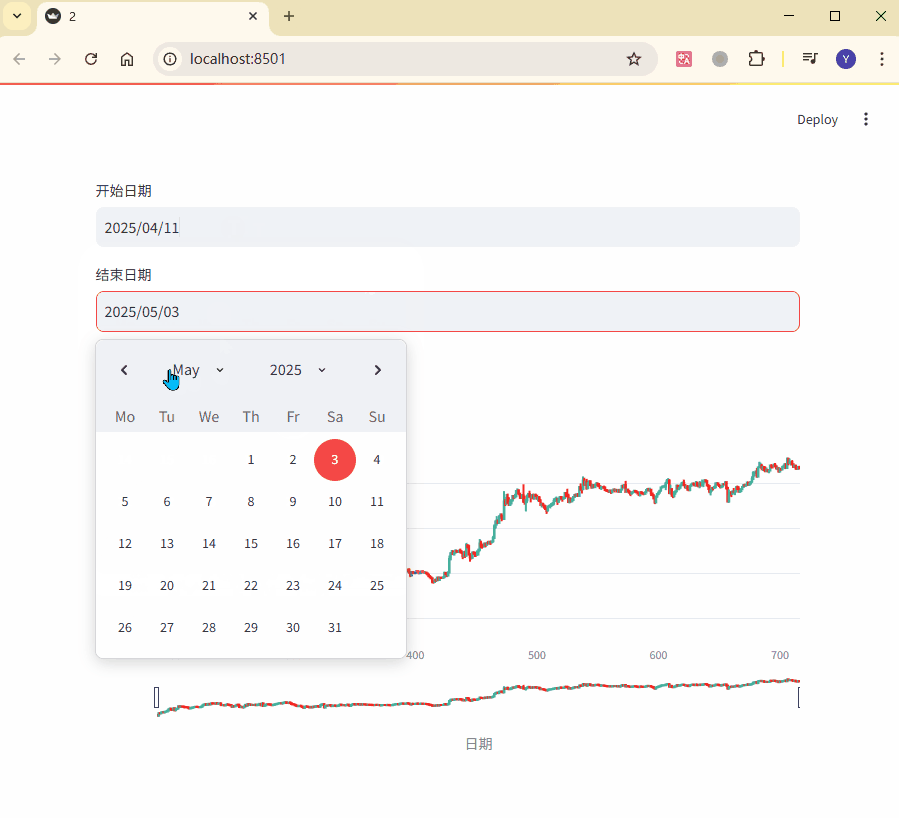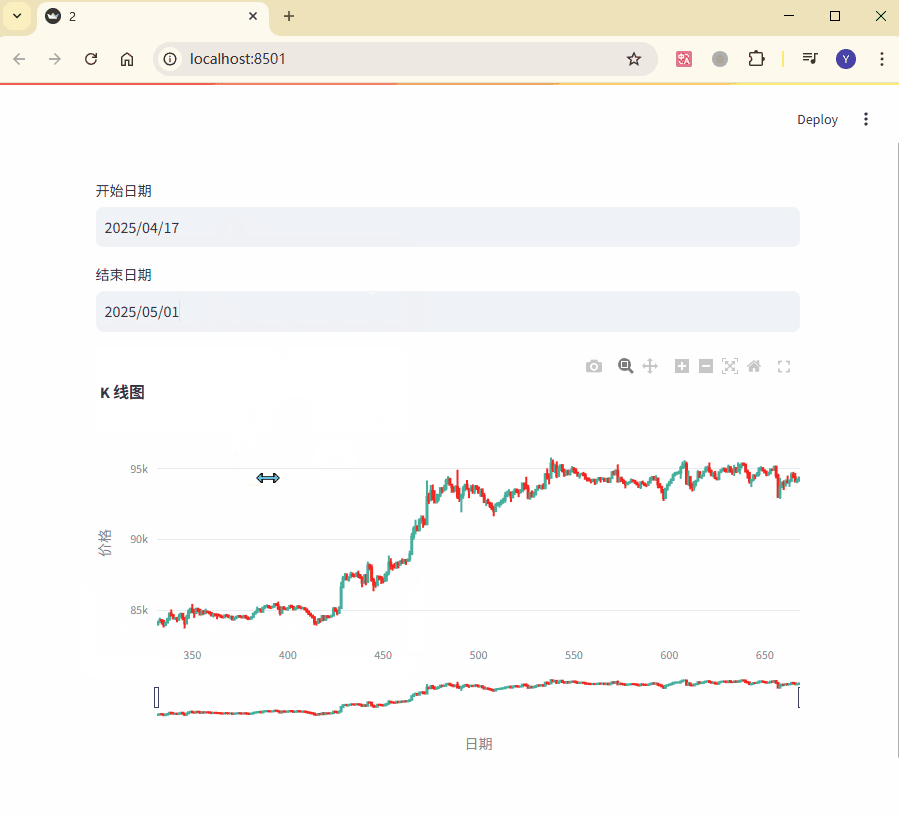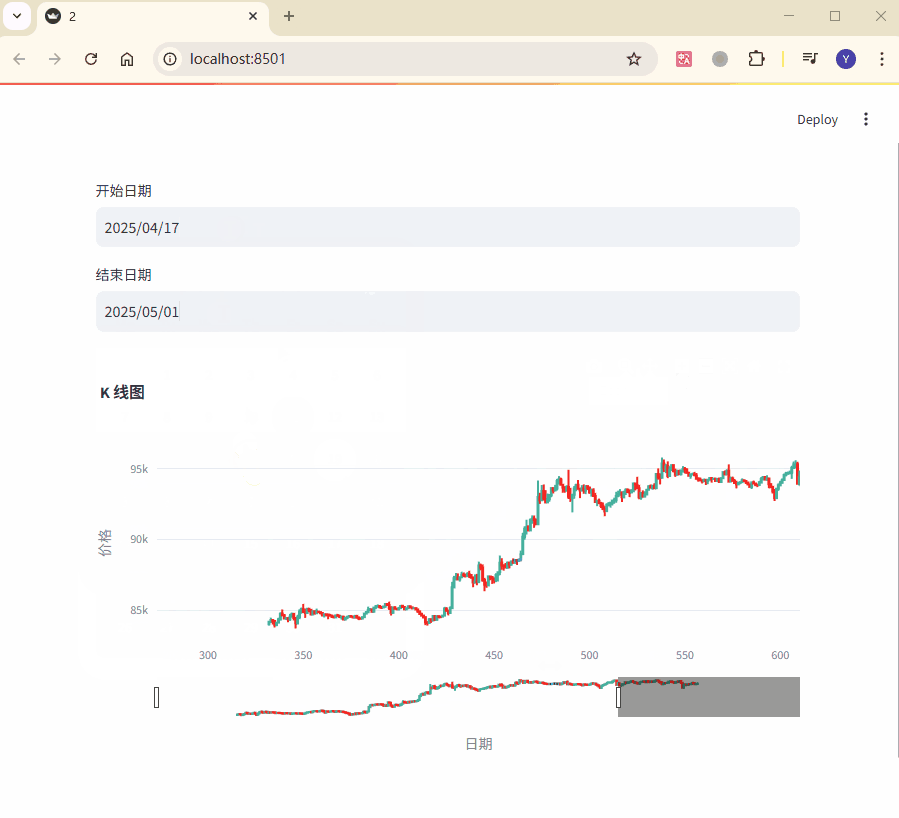
在这个示例中,用户可以通过日期选择器动态调整 K 线图的显示范围,
而Plotly图表会根据筛选后的数据实时更新,从而实现交互效果。
2. 数据驱动的交互式应用
2.1. 上传文件更新图表
在实际应用中,数据往往是动态的,用户可能需要根据不同的条件来查看不同的数据视图。
通过结合Streamlit的输入组件(如st.file_uploader、st.selectbox和st.slider),可以实现数据的动态加载和图表的动态更新。
以下是一个实战案例,展示如何构建一个动态销售分析看板,支持按地区和产品类别筛选:
python
import streamlit as st
import plotly.express as px
import pandas as pd
# 上传数据
uploaded_file = st.file_uploader("上传销售数据", type=["csv"])
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
# 提取地区和产品类别的列表
regions = data["地区"].unique()
products = data["产品类别"].unique()
# 创建筛选组件
selected_region = st.selectbox("选择地区", regions)
selected_product = st.selectbox("选择产品类别", products)
# 根据筛选条件过滤数据
filtered_data = data[(data["地区"] == selected_region) & (data["产品类别"] == selected_product)]
# 创建动态图表
fig = px.bar(filtered_data, x="日期", y="销售额", title="销售分析")
st.plotly_chart(fig)在这个示例中,用户可以通过上传数据文件,并选择地区和产品类别,动态生成销售分析图表。
这种设计模式不仅提高了应用的灵活性,还增强了用户体验。
2.2. 使用缓存优化性能
在处理大量数据时,性能优化是一个不可忽视的问题。
Streamlit提供了缓存机制,通过@st.cache_data装饰器,可以避免重复加载和计算数据,从而显著提高应用的性能。
以下是一个示例,展示如何通过缓存优化数据处理和绘图性能:
python
import streamlit as st
import plotly.express as px
import pandas as pd
# 缓存数据加载函数
@st.cache_data
def load_data(file):
return pd.read_csv(file)
# 缓存图表生成函数
@st.cache_data
def create_chart(data):
return px.bar(data, x="日期", y="销售额", title="销售分析")
# 上传数据
uploaded_file = st.file_uploader("上传销售数据", type=["csv"])
if uploaded_file is not None:
# 加载数据并缓存
data = load_data(uploaded_file)
# 创建筛选组件
selected_region = st.selectbox("选择地区", data["地区"].unique())
selected_product = st.selectbox("选择产品类别", data["产品类别"].unique())
# 根据筛选条件过滤数据
filtered_data = data[(data["地区"] == selected_region) & (data["产品类别"] == selected_product)]
# 生成图表并缓存
fig = create_chart(filtered_data)
st.plotly_chart(fig)在这个示例中,通过缓存数据加载和图表生成的过程,可以避免重复计算,从而提高应用的加载速度。
启用缓存后,用户在切换筛选条件时,图表的更新速度会明显加快。
缓存策略对比效果:
| 场景 | 未启用缓存 | 启用缓存 |
|---|---|---|
| 10MB CSV加载 | 1.2s | 0.05s |
| 复杂图表生成 | 0.8s | 0.01s |
3. 总结
Plotly和Streamlit的结合为快速构建兼具交互性与美观的数据应用提供了强大的支持。
通过组件联动设计,可以实现灵活的用户交互;
通过缓存优化,可以显著提高应用的性能;
通过用户友好的界面布局,可以提升用户体验。
这种组合不仅适用于数据分析和可视化,还可以扩展到实时数据监控、机器学习模型结果可视化等更多场景。