文章目录
进程间通信(IPC)
进程间通信的目的
进程间通信的目的是让运行在操作系统中的多个进程能够交换数据、协调行为、共享资源,从而实现复杂的系统功能。
1. 数据交换
- 目的:不同进程之间传递结构化或非结构化数据
- 场景 :
- 管道:父进程将数据通过管道传递给子进程
- 消息队列:异步发送日志信息或任务指令(如分布式系统中的任务调度)
- 套接字:跨网络传输数据(如客户端与服务器通信)
2. 资源共享
- 目的:多个进程共同访问同一资源,避免重复分配或冲突
- 场景 :
- 共享内存:高速读写同一块内存(如数据库缓存、实时图像处理)
- 内存映射文件:多个进程加载同一文件到内存(如日志分析工具并行处理日志)
3. 进程协同
- 目的:协调多个进程的执行顺序或互斥访问资源
- 场景 :
- 信号量:控制对共享资源的访问(如多进程写入同一文件时的互斥锁)
4. 系统解耦
- 目的:分离不同功能模块,提升系统可维护性和扩展性
- 场景 :
- 微服务架构:通过消息队列(如 RabbitMQ)解耦服务间的调用
- 插件化设计:主进程通过 IPC 与插件进程通信
5. 分布式计算
- 目的:跨物理机器或虚拟节点协作完成任务
- 场景 :
- MPI(Message Passing Interface):高性能计算集群中进程间通信
- RPC(Remote Procedure Call):远程调用其他机器的服务(如分布式数据库查询)
IPC 的典型方式对比
| 机制 | 用途 | 特点 | 示例场景 |
|---|---|---|---|
| 管道 | 单向数据流 | 简单、父子进程专用 | Shell 命令组合 (`cmd1 |
| 共享内存 | 高速数据共享 | 零拷贝、需同步机制 | 实时音视频处理 |
| 消息队列 | 异步通信 | 结构化消息、内核持久化 | 任务调度系统 |
| 信号量 | 同步与互斥 | 原子操作、控制资源访问 | 多进程写入同一文件 |
| 套接字 | 跨网络通信 | 灵活、支持复杂协议 | Web 服务器与客户端通信 |
| 信号 | 简单事件通知 | 异步、无数据负载 | 强制终止进程 (kill -9) |
总结
进程间通信的本质是打破进程隔离性,实现:
- 数据流动:传递信息,支持协作
- 资源共享:避免冗余,提升效率
- 行为协调:同步操作,防止竞态条件
选择合适的 IPC 机制需权衡 性能需求、开发复杂度、系统架构,例如:
- 本地高性能:优先共享内存 + 信号量
- 跨网络扩展:选择套接字或 RPC
- 简单通知:使用信号或管道
进程间通信的前提
因为进程具有独立性,所以进程的信息具有独立性
所以进程之间想直接通信是不可能的
进程之间通信的前提是有不同的进程能看到同一份资源的平台
这份资源肯定不能由进程提供,因为进程具有独立性,所以进程提供的一切信息都是独立的
所以进程间通信的核心思想就是:
由操作系统提供一个公共平台,不同进程向这个平台写入/读取信息
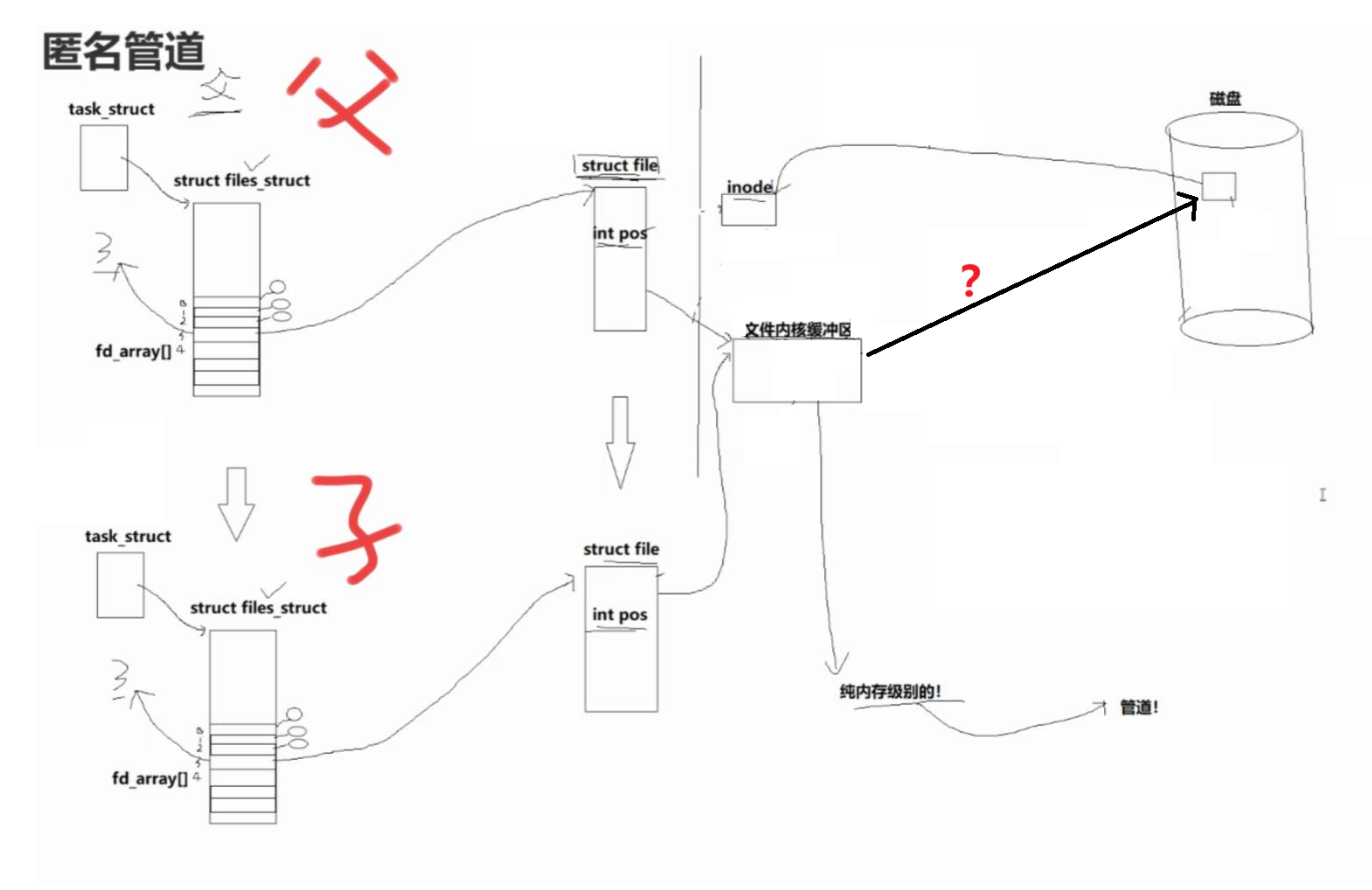
匿名管道
匿名管道的原理
struct files_struct子进程自己也要拥有独立的一份
为什么?
-
因为struct files_struct的作用是,管理进程打开的文件,
属于进程的范畴,子进程是一个独立的进程,所以它应该有 -
进程具有独立性,子进程如果再打开/关闭了文件,肯定不能影响父进程,所以子进程自己得有一份
在内存中,一个文件的内容和属性不会被重复加载
即一个被打开的文件只会出现一份inode,一份内核级缓冲区
所有打开这个文件的进程,共用一个inode和文件内核级缓冲区
所以子进程和父进程共用同一个inode和文件内核级缓冲区
两个进程打开同一个文件时,文件的struct flie不是共享的
为什么?
-
不同进程虽然打开了同一个文件,但是打开方式可能不同
struct file中有一个标志位,表示打开的方式
-
读写位置不同
进程虽然打开的是同一个文件,但大部分情况下对它的读写位置是不同的
struct file中有一个记录文件读写指针位置
所以子进程自己拥有独立的struct file
为什么同一个文件的struct file不是共享的,而inode是共享的?
因为inode记录的是文件要存储在磁盘中的属性(文件的权限,大小等),是静态的,共享的
而struct file记录的是文件打开后,进程动态操作文件时,文件的动态地属性信息(文件读写指针的位置等属性信息)
所以
此时子进程和父进程就可以通过各自的struct file对同一个文件内核级缓冲区进行读写了,并且还可以使用文件读写指针进行精确的读写
这也就达成了进程间通信的前提,不同的进程看到同一份资源
此时父子进程不就可以借助文件内核级缓冲区进行通新了吗?
我们如果想把文件级内核缓冲区作为进程间通信的平台,那它里面的数据肯定不能再刷新到磁盘了
所以Linux设计了一种纯内存级的文件,并设置了对应的系统调用
也就是它里面的数据只保存的内存中,不会保存到磁盘中
这个纯内存级别的文件,就叫管道
创建匿名管道的过程
-
父进程以
只读方式和只写方式,使用特殊系统调用打开同一个纯内存级别的文件 但是操作系统会创建两个struct file指向一个文件的内核级缓冲区 -
父进程创建子进程,
子进程继承父进程的文件描述符表,也就让子进程也以只读方式和只写方式打开了那个内存级文件 -
父子进程分别关闭一个不需要的读(写)端,做出一个"单向的管道"
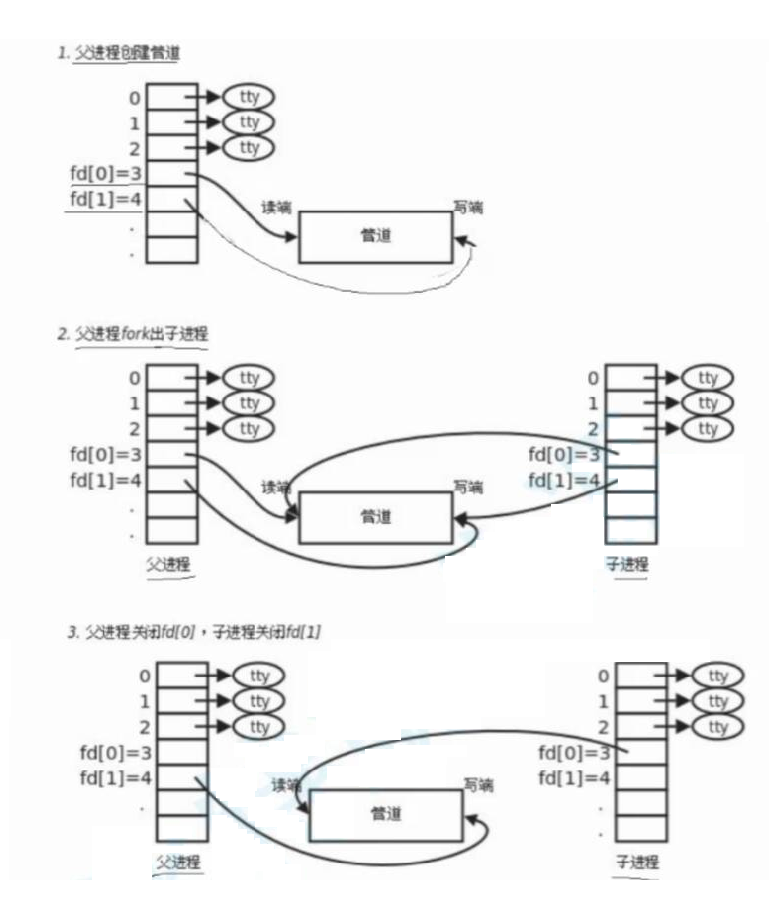
因为
规定管道只能单向通信
(只能从a进程向b进程传输数据,不能反过来,除非再创建一个从b到a的管道)
然后父(子)进程就可以使用系统调用write(read)加文件描述符,把数据写入到文件内核级缓冲区,进行通信了
如果不关闭不需要的读写端会怎样?
①虽然依旧可以通信,但是会有风险,可能会误操作(把读操作搞成写操作等),破坏管道结构
②不关闭不需要的读写端,会占用文件描述符,是一种资源浪费
也就是文件描述符泄露
为什么父进程要同时以只读方式和只写方式同时打开内存文件呢?
①如果只是以r方式打开内存文件,那么子进程继承到的struct file里面的flag就也只能是r,就没人能写了
只以w的方式打开同理
②如果父进程以rw的方式打开一个struct file,父子就都能读写了,会权限放大,违反管道的通信规则(只能单向通信)
匿名管道相关系统调用
pipe
头文件:unistd.h
返回值:int类型
①成功返回0
②失败返回-1
参数表:int pipefd[2]
输出型参数,会把以读写方式打开内存文件的文件描述符带出来
pipefd0:读端的文件描述符
pipefd1:写端的文件描述符
(记巧:可以把1看作笔,笔是用来写[w]的)
作用:打开(创建)一个匿名管道(内存文件)
命名管道
例
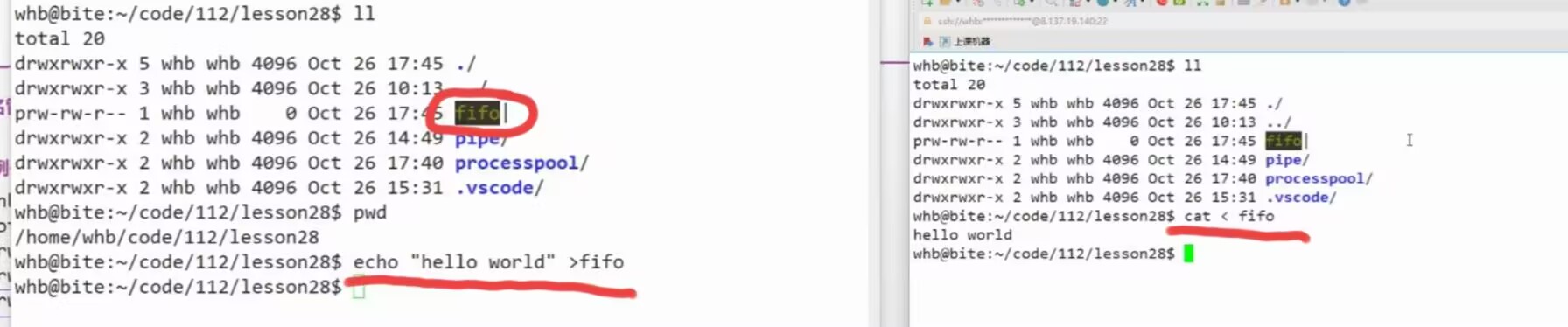
命名管道的文件类型是p
(类似目录的文件类型是d)
命名管道的文件本质就是一个标识符
是让多个进程可以通过命名管道文件找到同一个内核级文件缓冲区
命名管道的原理
为什么叫命名管道?
因为命名管道对应的文件虽然是存储在内存中的一个文件,它有自己的路径,文件名和inode
所以任何一个命名管道在内存中都具有唯一性
所以可以让不同进程,通过同一条路径找到同一个命名管道,借此进行通信
命名管道虽然有文件名和inode
但是磁盘中只有它的属性(其实就是inode)没有内容
因为
①命名管道也和匿名管道一样,内核级文件缓冲区中的内容不会刷新到磁盘
②要使用命名管道的文件名,inode,路径才能让进程找到命名管道

所以命名管道的原理很简单:
不同进程通过同一路径找到命名管道,然后一个以读方式打开,一个以写方式打开,然后看到同一个内核文件缓冲区了,就可以使用read和write通过文件内核级缓冲区进行通信
两个进程如何知道命名管道的路径呢?
创建一个共享的头文件,在里面定义全局变量,表示命名管道的路径,命名管道的起始权限等等共享信息
并让两个进程都包含这个头文件
命名管道搭建过程
两个进程如何知道命名管道的路径呢?
创建一个共享的头文件,在里面定义全局变量,表示命名管道的路径,命名管道的起始权限等等共享信息
并让两个进程都包含这个头文件
那么两个进程通信要通信时,命名管道由谁创建呢?
其实都可以
像命名管道这样的公共资源,一般是让一个指定的进程使用系统调用先行创建
怎么先行创建?
可以封装一个类,在这个类的构造里面使用mkfifo创建命名管道
如果需要还可以在它的析构里面使用unlink把命名管道删除
然后在那个指定进程的全局定义一个这个类的对象,这样进程启动之后,就会第一时间创建对象,就会调用它的构造
然后先启动这个进程创建命名管道,再启动其他进程
命名管道相关系统调用
函数:mkfifo
头文件:sys/types.h和sys/stat.h
返回值:int类型
①成功返回0
②失败返回-1
参数表:
①path:带路径的文件名
②mode:命名管道的最初默认权限所以还会受umask影响(用4个8进制位表示权限)
作用:在指定目录下创建一个命名管道
系统调用:unlink
头文件:unistd.h
返回值:int类型
①成功返回0
②失败返回-1
参数表:
path:带路径的文件名
作用:删除一个指定路径的文件(包括命名管道)
所以命名管道搭建过程如下
- 创建一个共享的头文件,在里面定义全局变量,表示命名管道的路径,命名管道的起始权限等等共享信息 并让两个进程都包含这个头文件
- 指定一个进程使用通过路径+mkfifo创建命名管道,并且先让这个进程运行
- 两个进程都通过路径找到命名管道,再使用open分别以读方式和写方式打开命名管道
- 两个进程通过系统调用read和write进行通信
管道的现象和特性(匿名和命名管道都有)
进程间通信的前提是:
让不同的进程看到同一份资源
所以这一份资源是多个进程共享的
是共享的而且还是资源,那不加以管控的话,肯定的会出问题
比如
①进程a要写给进程b的资源,进程c看见了就直接拿走了
②进程a写了一半,进程b就等不及地把数据读走了
等等数据不一致问题
所以要正确使用共享资源的话,就必须对共享资源进行保护被保护的共享资源,称为临界资源
管道自己就会把共享资源保护起来,保障进程通信的安全
管道的现象
当管道为空并且管道正常时,read(读端)会阻塞- 为什么?
因为管道本质是一块物理内存,管道为空还去读,读到的要吗是乱码(还没初始化)要吗就是已经被读取过但还没被覆盖掉的过期信息 - 如何做到?
因为管道是操作系统创建的,并且read也是系统调用,所以操作系统管理着它们两个的信息
操作系统当然也就可以知道管道是否为空,是否正常
为空的时候,就把要read的进程链接到管道的struct file中的等待队列中,就阻塞住了
等到管道有数据,再把进程放回运行队列,读取数据
- 为什么?
当管道写满了并且管道正常时,write(写端)会阻塞
管道中的数据是有最大上限的,不同平台上限可能不同,但是都有上限
所以管道写满了的话,就不能再写了,不然要吗越界访问,要吗覆盖原来的数据,都是不行的
当管道写端关闭并且管道读端正常时,如果此时管道为空的话,读端再读也只会读取到文件结束标志表示管道断开,并且会直接返回,不会阻塞
如果发生这种情况,因为管道中可能还有数据没读完,所以暂时还可以read读取它
但是read系统调用的返回值为0时,数据就一定读取完了
而此时
写端关闭了,管道中不可能再有数据了
使用if判断,当read返回值为0时就表示管道断开了,手动关闭读端,结束通信
当管道读端关闭并且管道写端正常时,操作系统会自动杀掉向管道write的进程
因为读端关闭之后,没有人能再从管道读,所以再向管道写就一定是白忙活,浪费时间
操作系统不会做任何浪费时间/空间的工作
所以操作系统一旦检查到这个情况,就直接使用kill的13号信号SIGPIPE,把进程杀掉了
管道的特性
面向字节流
即
从管道读数据的进程,只关心自己要读多少字节,不关心写端写了多少次
向管道写数据的进程,只关心自己要写多少字节,不关心读端要读多少次
这样的好处是:解藕
写端只管自己写,读端只管从管道读
不是写端一次写多少,读端就得一次读多少
用于拥有血缘关系的进程之间的通信(匿名管道的特性)
因为匿名管道的原理就是,通过子进程会继承父进程资源的特性实现的
所以有血缘关系的进程(父子进程,兄弟进程,爷孙进程等)理论上都能通过匿名管道通信
只要利用继承特性,让它们看到同一个内核文件缓冲区就行
管道的生命周期随进程
因为打开的文件的生命周期随进程,而管道本质是内存文件
所以当所有打开管道的进程都没了或者管道的所有读写端都关闭了管道就会被释放
一个管道只能单向通信,这是规定
所以要双向通信,就可以在两个进程之间接两个管道
管道自带同步互斥等保护共享资源的机制
单次写入/读取的数据的字节,小于PIPE_BUF(宏),那么这个写入操作就具有不可被拆分的原子性
PIPE_BUF是一个宏变量,一般是4096
也就是如果单次write写入到字节数小于PIPE_BUF,那么它就是安全的
不可能出现write写到一半,就被其他进程读走了