目录
[1 Hive数据导入概述](#1 Hive数据导入概述)
[1.1 Hive数据导入方式分类](#1.1 Hive数据导入方式分类)
[1.2 Hive数据模型与存储结构](#1.2 Hive数据模型与存储结构)
[2 LOAD DATA命令详解](#2 LOAD DATA命令详解)
[2.1 基本语法与参数](#2.1 基本语法与参数)
[2.2 LOAD DATA执行流程](#2.2 LOAD DATA执行流程)
[2.3 案例分析](#2.3 案例分析)
[3 HDFS数据迁移技术](#3 HDFS数据迁移技术)
[3.1 HDFS文件操作与Hive集成](#3.1 HDFS文件操作与Hive集成)
[3.2 外部表技术应用](#3.2 外部表技术应用)
[3.3 分区表动态加载](#3.3 分区表动态加载)
[4 性能优化策略](#4 性能优化策略)
[4.1 文件格式选择对比](#4.1 文件格式选择对比)
[4.2 并行加载技术](#4.2 并行加载技术)
[4.3 资源调优参数](#4.3 资源调优参数)
[5 高级应用场景](#5 高级应用场景)
[5.1 动态分区加载](#5.1 动态分区加载)
[5.2 数据转换加载](#5.2 数据转换加载)
[5.3 事务表加载](#5.3 事务表加载)
[6 常见问题排查](#6 常见问题排查)
[6.1 加载失败常见原因](#6.1 加载失败常见原因)
[6.2 性能瓶颈分析](#6.2 性能瓶颈分析)
[6.3 小文件问题](#6.3 小文件问题)
[6.4 字符编码问题](#6.4 字符编码问题)
[7 结论](#7 结论)
引言
在大数据生态系统中,Hive作为基于Hadoop的数据仓库工具,其数据导入导出功能是ETL流程中的关键环节。
1 Hive数据导入概述
1.1 Hive数据导入方式分类
- Hive支持多种数据导入方式,主要分为以下几类:
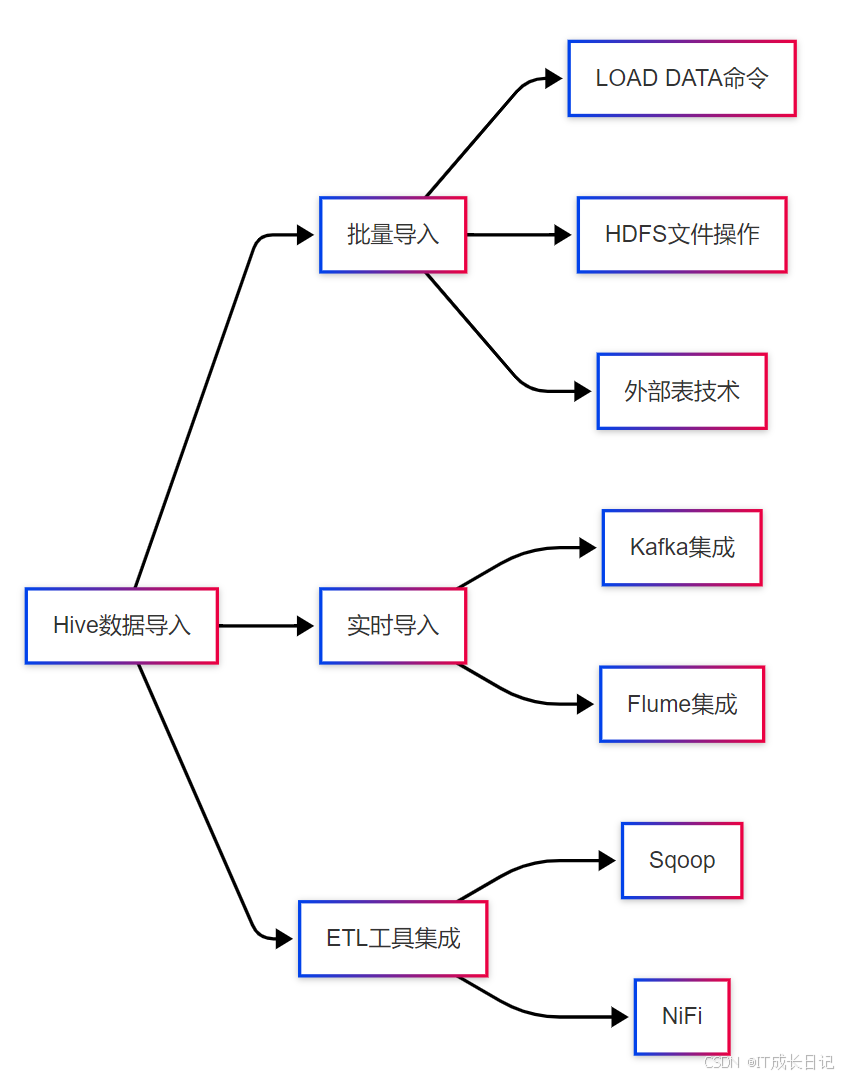
批量导入是Hive最常用的数据加载方式,具有以下特点:
- 适合大规模数据迁移
- 对系统资源要求集中
- 通常用于离线分析场景
- 支持多种文件格式(Text, ORC, Parquet等)
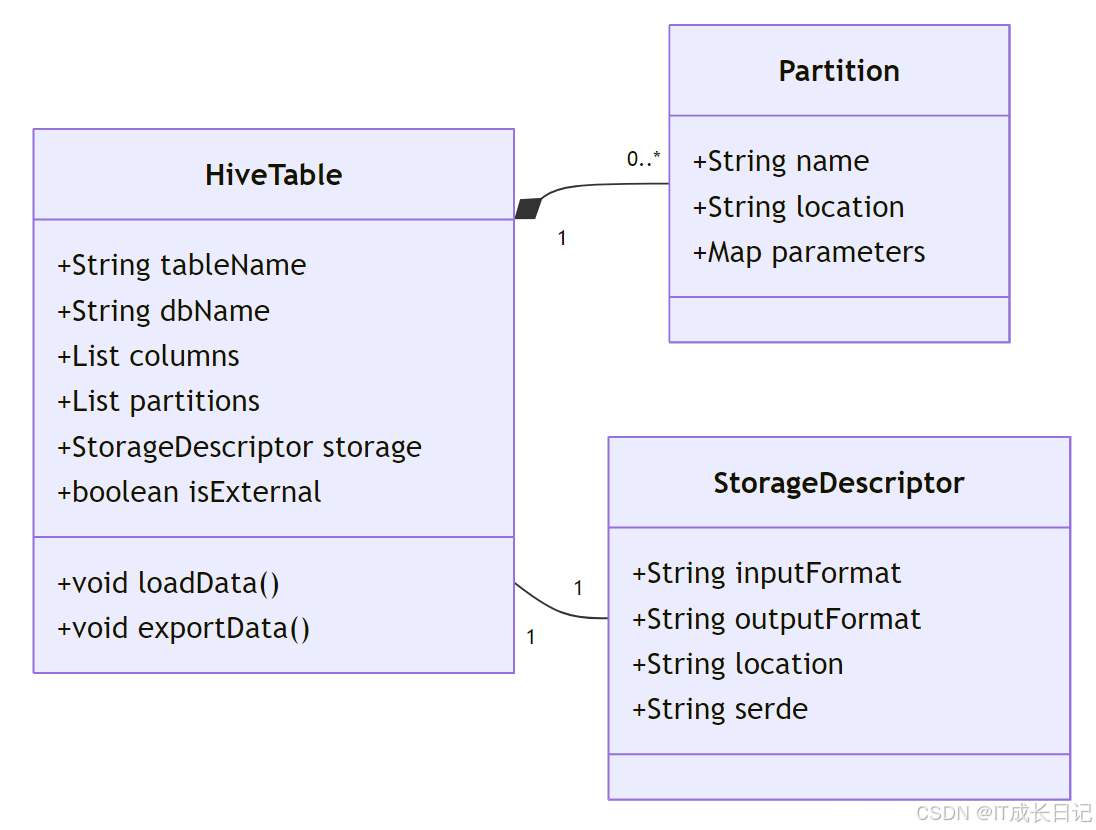
1.2 Hive数据模型与存储结构
理解Hive数据导入前,需要明确几个核心概念:
- 内部表(Managed Table):Hive完全管理的表,删除表时数据也会被删除
- 外部表(External Table):仅管理元数据,数据存储在外部位置
- 分区(Partition):按照指定列的值对表进行物理划分
- 分桶(Bucket):对数据进行哈希分区,提高查询效率
2 LOAD DATA命令详解
2.1 基本语法与参数
-
LOAD DATA命令是Hive内置的批量导入工具,其完整语法如下:
LOAD DATA [LOCAL] INPATH 'filepath'
[OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]
关键参数说明:
- LOCAL:指定源文件位于本地文件系统(而非HDFS)
- INPATH:数据文件路径,可以是文件或目录
- OVERWRITE:是否覆盖目标表中的现有数据
- PARTITION:指定目标分区(仅对分区表有效)
2.2 LOAD DATA执行流程
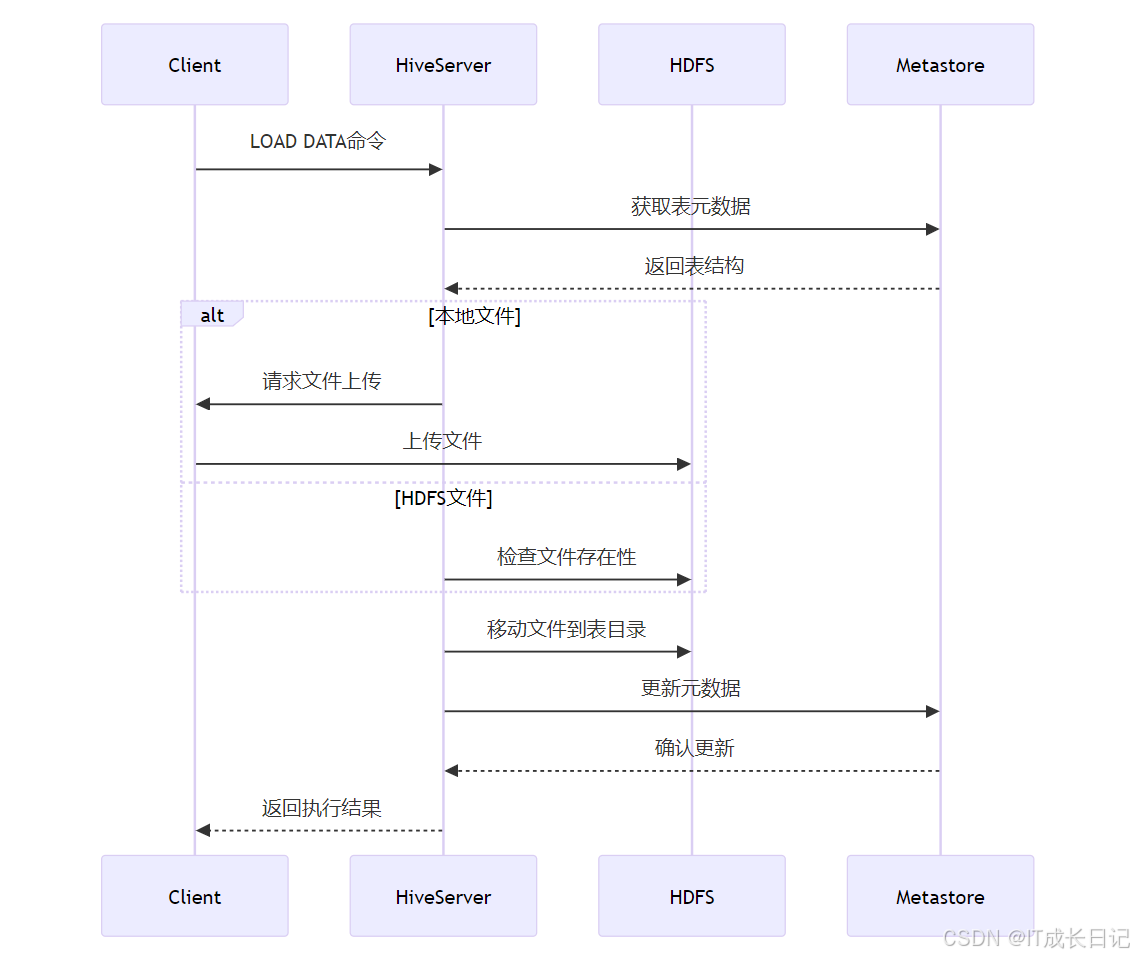
流程说明:
- 客户端提交LOAD DATA命令到HiveServer
- HiveServer从Metastore获取表元数据
- 对于本地文件,先上传到HDFS临时位置
- 将文件移动到目标表目录(HDFS操作)
- 更新Metastore中的元数据信息
- 返回操作结果给客户端
2.3 案例分析
-
案例1:从HDFS导入数据到非分区表
-- 创建目标表
CREATE TABLE user_info (
id INT,
name STRING,
age INT
) STORED AS TEXTFILE;-- 从HDFS导入数据(文件需预先上传到HDFS)
LOAD DATA INPATH '/tmp/user_data.txt' INTO TABLE user_info; -
案例2:从本地导入数据到分区表
-- 创建分区表
CREATE TABLE logs (
ip STRING,
request STRING,
time STRING
) PARTITIONED BY (dt STRING)
STORED AS ORC;
-- 从本地导入数据到特定分区
LOAD DATA LOCAL INPATH '/home/user/logs_20230101.csv'
OVERWRITE INTO TABLE logs
PARTITION (dt='2023-01-01');
3 HDFS数据迁移技术
3.1 HDFS文件操作与Hive集成
-
HDFS作为Hive的底层存储,直接操作HDFS文件可以实现更灵活的数据迁移:
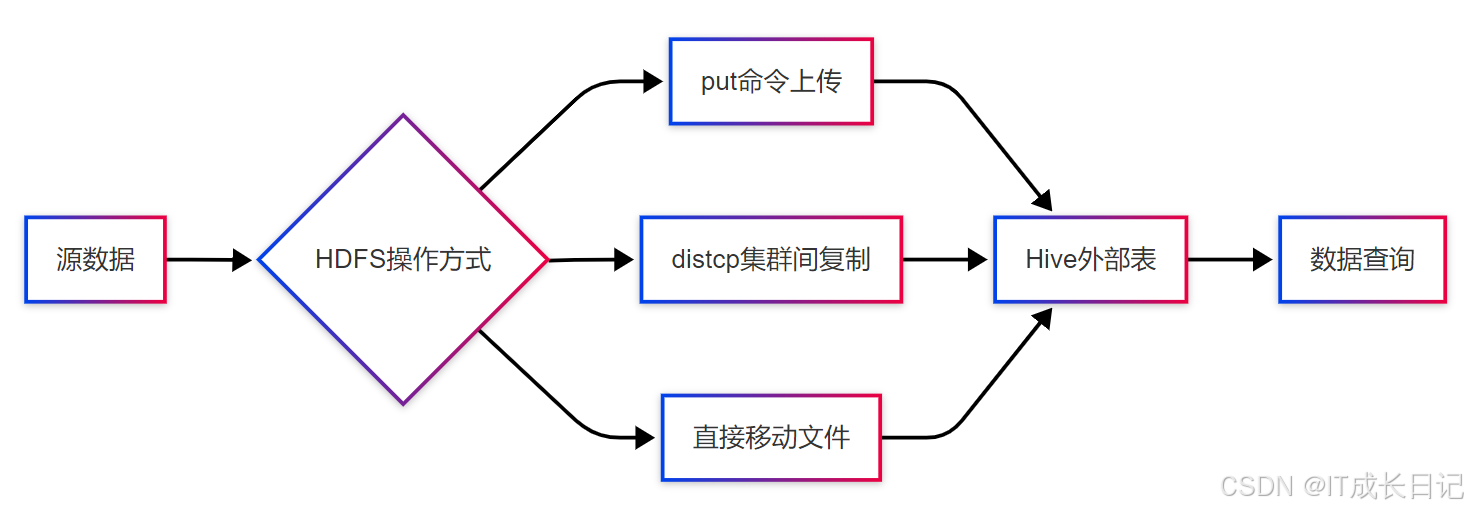
-
常用HDFS命令:
上传本地文件到HDFS
hadoop fs -put local_file /hdfs/path
在HDFS中移动文件
hadoop fs -mv /old/path /new/path
跨集群复制
hadoop distcp hdfs://cluster1/path hdfs://cluster2/path
3.2 外部表技术应用
外部表是HDFS数据迁移的强大工具,其特点包括:
- 数据位置灵活可控
- 删除表不会影响数据文件
- 支持多种文件格式
-
可与其他工具无缝集成
-
创建外部表示例:
CREATE EXTERNAL TABLE ext_sales (
order_id BIGINT,
product_id INT,
amount DOUBLE
) STORED AS PARQUET
LOCATION '/data/sales/2025';
3.3 分区表动态加载
-
结合HDFS目录结构与Hive分区表特性,可以实现高效的数据加载:
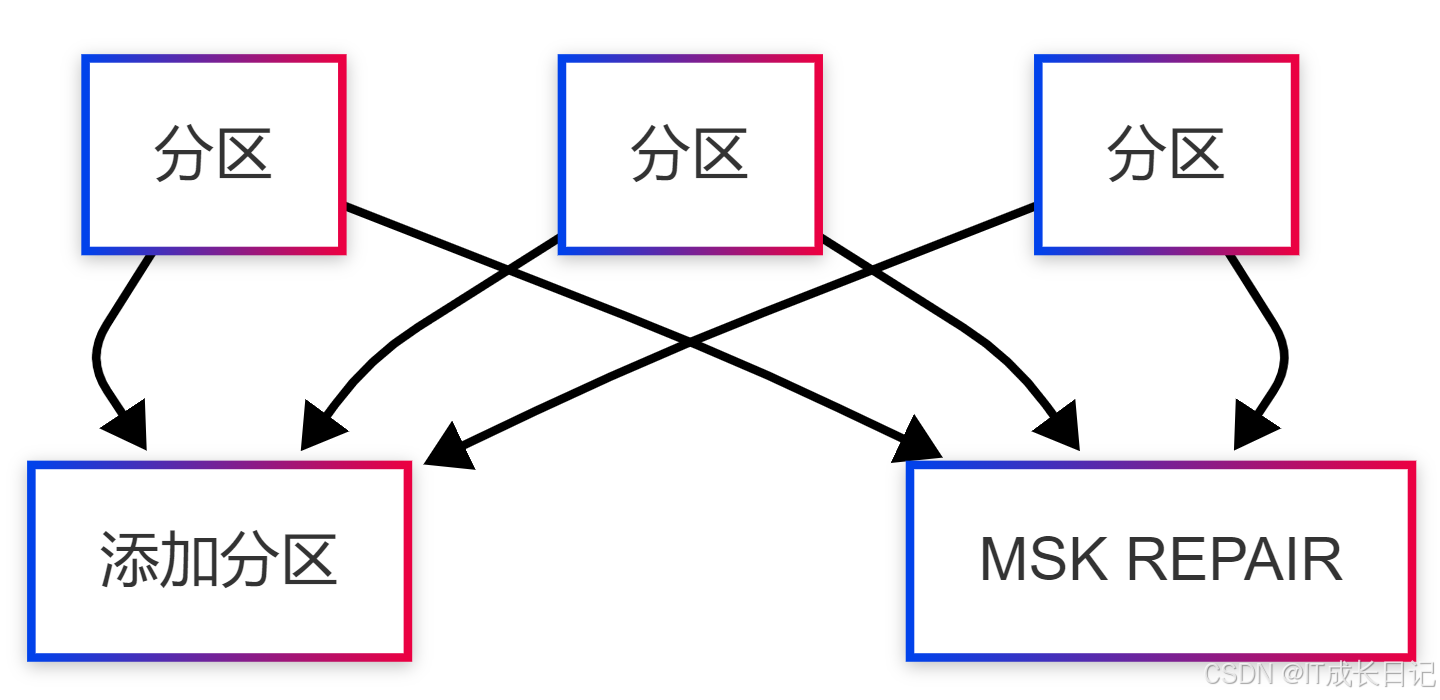
-
实现方法:
-- 方法1:手动添加分区
ALTER TABLE logs ADD PARTITION (dt='2025-05-01')
LOCATION '/data/logs/dt=20250501';
-- 方法2:自动修复分区
MSCK REPAIR TABLE logs;
4 性能优化策略
4.1 文件格式选择对比
|----------|------|------|-----|--------|
| 格式 | 加载速度 | 查询速度 | 压缩比 | 适用场景 |
| TEXT | 快 | 慢 | 低 | 临时数据交换 |
| SEQUENCE | 中 | 中 | 中 | 中间结果存储 |
| ORC | 慢 | 快 | 高 | 分析型查询 |
| PARQUET | 慢 | 快 | 高 | 跨平台分析 |
4.2 并行加载技术
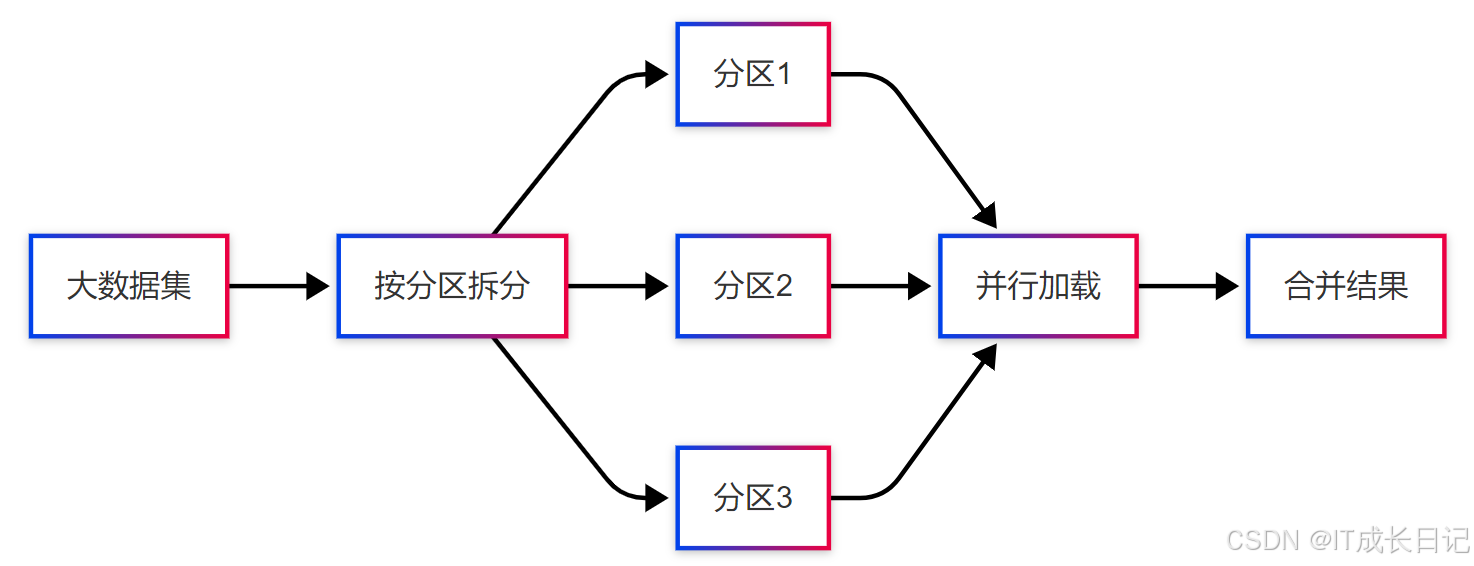
4.3 资源调优参数
-- 设置Mapper数量
SET mapred.map.tasks=100;
-- 启用并行执行
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=16;
-- 优化小文件合并
SET hive.merge.mapfiles=true;
SET hive.merge.size.per.task=256000000;
SET hive.merge.smallfiles.avgsize=16000000;5 高级应用场景
5.1 动态分区加载
-- 启用动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
-- 根据数据自动创建分区
LOAD DATA INPATH '/data/events'
INTO TABLE events_part
PARTITION (year, month);5.2 数据转换加载
-- 创建临时外部表指向原始数据
CREATE EXTERNAL TABLE temp_events (
raw string
) LOCATION '/data/raw/events';
-- 使用ETL处理并加载
INSERT INTO TABLE final_events
SELECT
get_json_object(raw, '$.id') as id,
from_unixtime(get_json_object(raw, '$.time')) as event_time
FROM temp_events;5.3 事务表加载
-- 创建ACID表
CREATE TABLE transactional_emp (
id int,
name string
) STORED AS ORC TBLPROPERTIES ('transactional'='true');
-- 批量插入
LOAD DATA INPATH '/data/emp' INTO TABLE transactional_emp;6 常见问题排查
6.1 加载失败常见原因
-
权限问题:
解决方案:设置正确的HDFS权限
hadoop fs -chmod -R 777 /user/hive/warehouse
-
文件格式不匹配:
-- 确保表定义与文件格式一致
CREATE TABLE ... STORED AS [TEXTFILE|ORC|PARQUET] -
元数据不同步:
-- 刷新元数据缓存
REFRESH TABLE tablename;
6.2 性能瓶颈分析
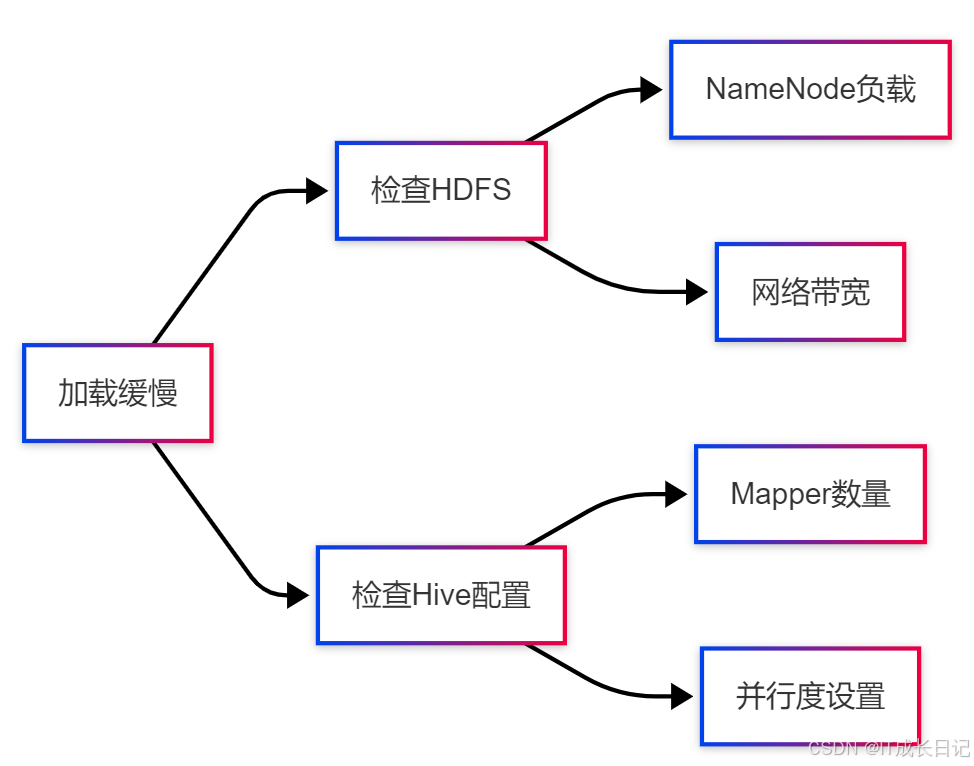
优化建议:
- 监控NameNode资源使用
- 增加集群带宽
- 调整mapreduce任务参数
- 优化文件大小(128MB-256MB最佳)
6.3 小文件问题
-- 合并已有小文件
ALTER TABLE sales CONCATENATE;
-- 设置合并参数
SET hive.merge.smallfiles.avgsize=16000000;
SET hive.merge.size.per.task=256000000;6.4 字符编码问题
-- 指定编码格式
CREATE TABLE encoded_data (
content string
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '/data/encoded'
TBLPROPERTIES ('serialization.encoding'='GBK');7 结论
Hive数据批量导入与HDFS数据迁移是大数据平台的基础能力,掌握这些技术对于构建高效的数据管道至关重要。
在实际项目中,建议根据数据规模、时效性要求和系统资源等因素,选择最适合的数据加载策略。随着技术的发展,Hive数据导入导出功能将持续演进,为大数据处理提供更强大的支持。