stack和queue的使用及其模拟实现
- 一、stack和queue的使用
- 二、stack和queue的模拟实现
- 三、deque------了解即可,不需要模拟实现
- 四、优先级队列priority_queue的使用及其模拟实现
-
- 1、priority_queue的使用
- 2、priority_queue的模拟实现
-
- 命名空间的展开与自己写的头文件在.cpp文件中的顺序
- push
- pop
- top
- size、empty
- 测试当前priority_queue的结构
- 仿函数/函数对象:模仿函数调用的类/类对象
-
- [- 利用仿函数控制比较逻辑](#- 利用仿函数控制比较逻辑)
- [- 将上述仿函数的逻辑代码套用在priority_queue中](#- 将上述仿函数的逻辑代码套用在priority_queue中)
- [- 利用仿函数自行调整比较逻辑](#- 利用仿函数自行调整比较逻辑)
- priority_queue的模拟实现代码
栈和队列和前面学习过的容器有点不一样,因为它们是用全新的模式来实现。string、vector、list是一种经典的代表,而本讲的stack和queue又是另一种经典的代表。
stack和queue的使用非常简单,我们重点看底层实现。
一、stack和queue的使用
stack只在栈顶push、pop;queue在队尾push,在队头pop。

像list、vector、string都是容器container,它们的第一个模板参数是数据类型,第二个模板参数是个内存池。而stack不是容器,是容器适配器,是STL六大组件之一。
容器与容器适配器的区别:list、vector、string等容器的增删查改都是自己实现,自己管理底层的结构和数据;stack、queue等容器适配器,例如stack不是自己实现栈去管理数据,而是用其他的容器去适配出stack,所以容器适配器的第二个模板参数传递的不是空间配置器(内存池),而是容器。
1、stack的使用
容器适配器stack关联的是stack的底层。若不关注它的底层,只关注它的使用方式的话,那就只关注 " LIFO(last-in first-out)"即可。
cpp
#include <iostream>
#include <stack>
using namespace std;
int main()
{
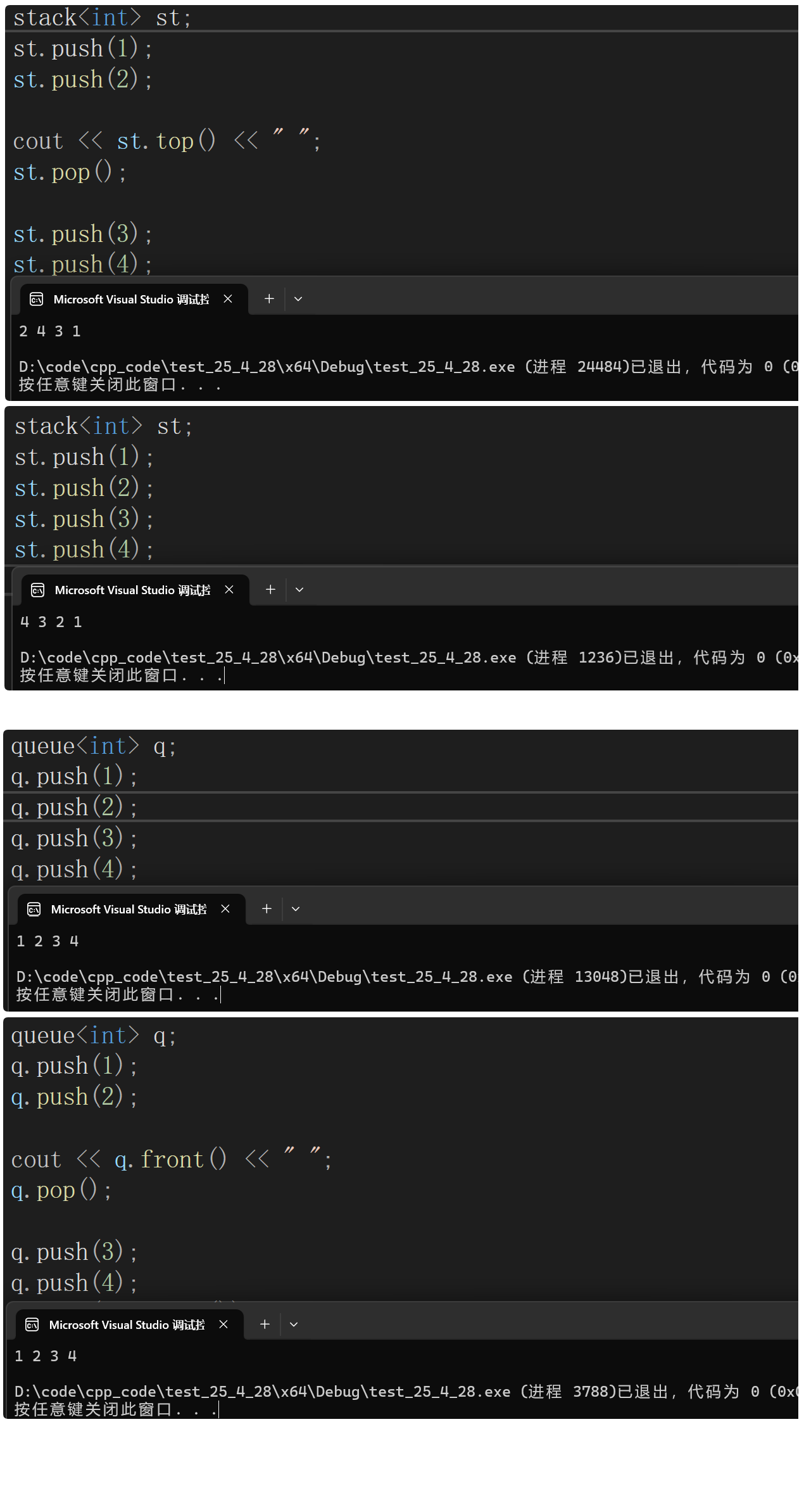
stack<int> st;
st.push(1);
st.push(2);
cout << st.top() << " ";
st.pop();
st.push(3);
st.push(4);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
cout << endl;
return 0;
}
stack算法题
题目1:最小栈
最小栈解析:LeetCode 155题解 | 最小栈
题目2:栈的压入、弹出序列
栈的压入、弹出序列解析:牛客网题解 | 栈的压入、弹出序列
题目3:逆波兰表达式求值
逆波兰表达式求值解析:LeetCode 150题解 | 逆波兰表达式求值
2、queue的使用
同理,只关注FIFO即可:

cpp
#include <iostream>
#include <queue>
using namespace std;
int main()
{
queue<int> q;
q.push(1);
q.push(2);
cout << q.front() << " ";
q.pop();
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
cout << endl;
return 0;
}向栈中入数据、出数据的方式有很多种,因为对于栈来说,后进先出是相对的;而队列入数据,不管怎么样都是先进先出:
queue算法题
题目:二叉树的层序遍历
二叉树的层序遍历解析:LeetCode 102题解 | 二叉树的层序遍历
二、stack和queue的模拟实现
封装
STL的六大组件,我们现在所认识到的组件有算法、容器、迭代器。STL是数据结构与算法的库,但是它从逻辑上划分成六个部分。容器:在内存中管理数据;算法:对数据进行各种处理。容器与算法都借助迭代器去控制。迭代器可以在不破坏底层结构的情况下(不需要了解底层结构的情况下,本质是对底层结构的封装)去访问容器。算法、容器、迭代器的设计体现了更高层次的封装。
那么封装是什么呢?封装的下一层是容器,容器可能是各种各样的结构:数组结构、链式结构、树形结构...,因为底层结构的不同,访问容器按理来说有各种各样的方式,但是迭代器在这里的设计特点就是提供了统一的访问容器的方式,为了实现这种统一而对各种各样的结构进行了封装,封装屏蔽了底层差异(容器各种各样的结构)和实现细节。例如,顺序表和链表的迭代器的实现方式的差异都是很大的,因为数组和链表的底层结构差异就很大,那么要访问它们的差异也很大。但是它们使用迭代器的方式是高度类似的,只需要关注用这种方式去访问和修改,不用去关心细节。同理,算法也可以借助迭代器访问和修改容器,只需关心传递过来的迭代器类型(单向、双向、随机),而不用去关心传递过来的是哪个容器的迭代器。所以封装不仅仅是把数据和方法放在一个类里。支付宝和微信的支付体现的就是一种封装,各个银行的支付方式都各有不同。支付宝和微信屏蔽了各个银行底层的实现细节,绑卡后支付方式都统一了,实际上支付出去的钱还是来自银行卡。
适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
平时我们接触最多的适配器就是电源适配器,电源适配器会进行转换,把家里的220V电压/功率转换成手机需要的电压/功率。适配的本质是一种转换。
我们之前用C语言写的栈,要么是数组栈,要么是链式栈。可以用数组结构写一个栈,也可以用链式结构写一个栈,那么C++可不可以继续用这种方式写呢?答案是可以的,但是C++考虑到了栈是只在一端出入数据,只要控制在一端(这一端是栈顶,另一端是栈底)出入数据,那么无论是数组结构还是链式结构都能实现栈,而vector(顺序表)和list(带头双向循环链表)都能控制只在一端出入数据,所以可以封装vector/list来实现栈。
容器适配器:是适配器的一种。刚刚之所以用封装的知识点来过渡,是因为容器适配器也是一种封装的体现,不用去关心底层栈/队列到底是什么结构,我们只知道栈/队列是后进先出/先进先出的。容器适配器本质就是封装现有的容器转换实现出我们想要的东西。
1、stack的模拟实现
vector支持尾插尾删,vector底层就是数组,那么就可以把数组的尾部当成栈顶,在尾部出入数据,同理,list也是一样的。基于此,不用把代码写死,那么就可以再加个模板参数Container,封装Container 。当然不是说Container是什么容器都可以,栈的要求是只在一端,把这一端定义成尾部,尾部就是栈顶,那么栈的push/pop接口就在容器的尾部push/pop,要求容器有push_back、pop_back接口。
top
能用下标 + []的方式吗?------ 不能。

因为Container可能支持尾插尾删,但是可能不支持operator[],例如list。因此访问尾部数据的统一接口是back ,或者没有back接口用迭代器end()--也是可以的。
实现两个版本,与库里的保持一致:


cpp
// stack.h
#include <iostream>
#include <deque>
#include <vector>
#include <list>
using namespace std;
namespace zsy
{
template<class T, class Container = deque<T>>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
T& top()
{
return _con.back();
}
const T& top() const
{
return _con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}
cpp
// Test.cpp
#include "stack.h"
int main()
{
// 若不想使用缺省值,也可以自己指定参数
//zsy::stack<int, vector<int>> st;
//zsy::stack<int, list<int>> st;
zsy::stack<int> st;
st.push(1);
st.push(2);
cout << st.top() << " ";
st.pop();
st.push(3);
st.push(4);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
cout << endl;
return 0;
}
这些栈、队列等容器适配器都没有提供迭代器,因为只有容器才提供迭代器。为什么不提供呢?容器确实是需要提供迭代器去访问的,但若真的给栈、队列提供迭代器了,那就不能保证"后进先出"、"先进先出"的特性了。
库里没有要求一定要对第二个模板参数传参,可以用缺省值,即用deque实例化出的类型适配。若不想用deque适配,那么就可以自己传递例如vector、list容器实例化出的类型进行适配。deque稍后讲解。
2、queue的模拟实现
与栈不同,队列是在队尾入数据,队头出数据。对应容器要有push_back、pop_front接口。
cpp
// queue.h
#include <deque>
namespace zsy
{
template<class T, class Container = deque<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
T& front()
{
return _con.front();
}
const T& front() const
{
return _con.front();
}
T& back()
{
return _con.back();
}
const T& back() const
{
return _con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}
cpp
// Test.cpp
#include "stack.h"
#include "queue.h"
int main()
{
zsy::queue<int> q;
q.push(1);
q.push(2);
cout << q.front() << " ";
q.pop();
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
cout << endl;
return 0;
}
发现传递参数vector<T>会报错,因为vector不支持头删:
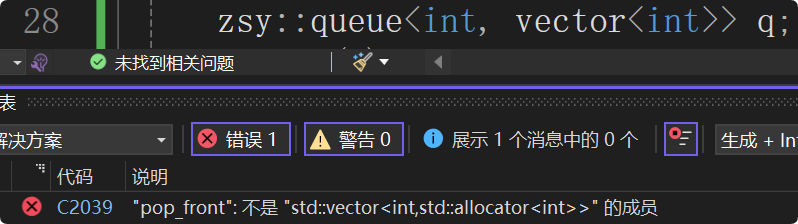
若这里就是想让vector强行适配出queue,有没有办法?有,vector不支持头删,但是可以间接利用erase支持头删。这样vector、list都可以适配出queue。

我们看看库里的支不支持用vector、list适配出queue?
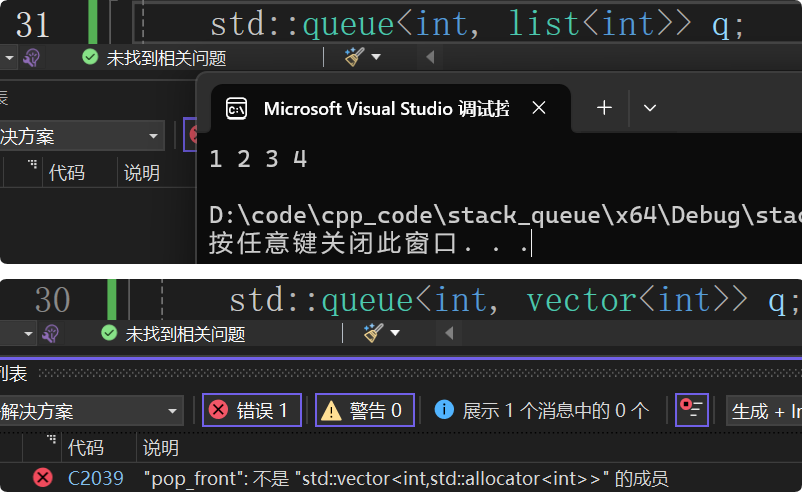
我们发现库里的list可以适配queue,但是vector不能适配queue。我们发现库里的queue的pop接口调用的是容器的头删接口,而不是erase接口,并且vector不支持头删接口,所以报错:

虽然可以强行支持vector头删,但是这种支持牺牲太大了,因为每一次头删都需要挪动数据,若是持续地头删,效率会太低了。
在C++中实现栈和队列是不复杂,本质体现的是一种封装,封装现有的容器去进行适配,适配出容器适配器栈和队列。还有跟复杂的适配------优先级队列。
三、deque------了解即可,不需要模拟实现

栈和队列在进行适配时,没有选择vector、list作为默认容器适配,(当然对于队列选择vector是不行的,也就是它们没有统一选择list作为默认容器)它们统一选择deque作为默认容器适配。
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
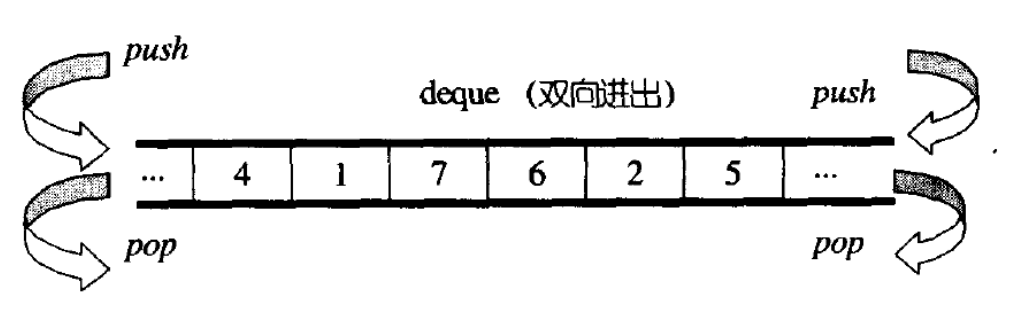
双端队列虽然叫队列,但是与队列没有任何关系。它是个"全能型选手",可以理解为是一个聚合了vector和list功能的容器,既有vector的特点,也有list的特点,而且deque的迭代器是随机访问迭代器。
为什么用deque作为stack和queue的默认适配容器? 仅仅是因为deque有尾插尾删接口可以适配stack、有尾插头删接口可以适配queue来作为默认适配容器吗?------ 不完全是,那么就要了解deque的底层及其deque容器产生的原理是什么?某种程度上deque容器的诞生是可以替代容器vector和容器list,当前看起来是这样的。接下来分析vector和list的优缺点(面试题)。

1、vector和list的优缺点(面试题)
-
vector
-
- 优点:
1、支持下标随机访问。
2、CPU高速缓存命中率高。
- 优点:
-
- 缺点:
1、头部或中部插入删除效率低下,因为要挪动数据。
2、扩容有一定成本,存在空间浪费。例如:现在容量是100,满了,扩容到200,插入120个数据,后面80个空间浪费;vector"删除"也存在一定的空间浪费,因为数组不支持部分空间释放。例如,100个空间,满了,删除20个数据,只删除20个数据,但是空间还是100个不变的,若后面不用这20个空间,也是会造成空间浪费的。
- 缺点:
-
list
-
- 缺点:
1、不支持下标随机访问。
2、CPU高速缓存命中率低。
- 缺点:
-
- 优点:
1、任意位置可以O(1)插入删除,不需要挪动数据。
2、不存在扩容,按需申请释放,不浪费空间。
- 优点:
通过对比发现,vector和list是两个互补的结构,二者相辅相成又有各自的特点。vector的优点是list的缺点,vector的缺点反而是list的优点。
CPU高速缓存命中率
CPU速度很快,内存速度也很快,但是相对于CPU没有那么快。数据结构存储在内存里,在内存上开空间存储数据。写了个程序用迭代器/范围for...等方式访问/修改数组或者链表。
例如用范围for对容器里的数据进行访问修改:
cpp
for (auto& e : container)
{
e++;
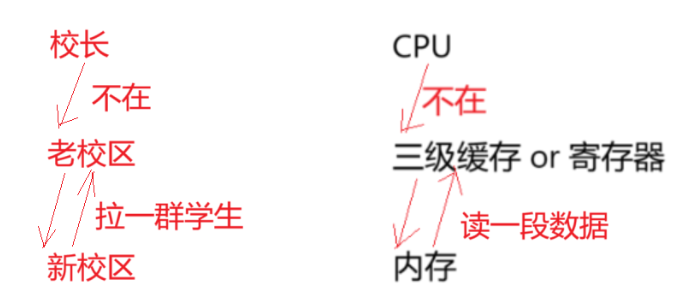
}范围for会转换成迭代器访问修改内存里的数据,会对数据进行++处理,这个过程就是让CPU去访问存储空间中的数据,然后进行修改,最后在写回内存。不过这里的CPU的速度太快了,内存会跟不上。所以CPU对内存里的数据进行访问时,会先把内存里的数据加载到速度相对快一点的"缓存"里,现在严格说是"三级缓存"(老一点的设备可能是两级缓存。一级比一级小,一级比一级快),或者加载到"寄存器"里。
寄存器 和三级缓存的效率都很高,寄存器的效率最高,但是寄存器通常都很小,一个CPU周围通常都有几十个寄存器,一般需要高频快速访问的都放在寄存器里,稍微大一点的就不能放在寄存器里,就需要加载到缓存里。
大概机制:CPU访问一个数据,先看这个数据是否在缓存里。在就叫缓存命中,不在就是不命中。不命中,就要将数据先加载到缓存里,然后再访问缓存。CPU在这里就是通过缓存去访问:
-
情况一:数据在缓存里。那么CPU就直接访问,对数据直接处理,读操作直接读,写操作还要回写到内存里。
-
情况二:数据不在缓存里。在内存中找到数据加载到缓存,再对缓存发起访问,这时就会缓存命中。

- 为什么访问vector里的数据CPU高速缓存命中率高呢?而list的CPU高速缓存命中率低呢?
CPU一次性去"缓存"里读数据时 ,不是一次读4/8个字节的读法,而是一次要读一段数据 ,这一段有多长是要看CPU的字长,一般读一次是几百上千个字节。(这就好比一个学校有新老校区,校长公务繁忙常年在老校区,老校长想叫一部分同学问问学校食住等情况,而大部分同学又都在新校区。当校长想访问的学生们正好在老校区,那么就直接访问即可;当想访问的学生们在新校区,学校提供专门的大巴车负责接送学生,每次接送不是一个一个接送,而是接送一车学生到老校区。)在计算机中有个局部性原理的概念:日常的程序在访问内存中的数据时,通常访问一个位置的同时就会很大概率访问它相邻的位置。所以CPU访问一个数据,若这个数据是第一个数据且不在"缓存",那么就要将这个数据加载到缓存(即读这一个数据到缓存),是一次读一个数据吗?不是的,而是一次读一段数据,类比一次接送一群学生。为什么要读一段数据?两个原因:原因一是局部性原理。原因二是读一个字节也是读,读一堆字节也是读,成本是一样的。
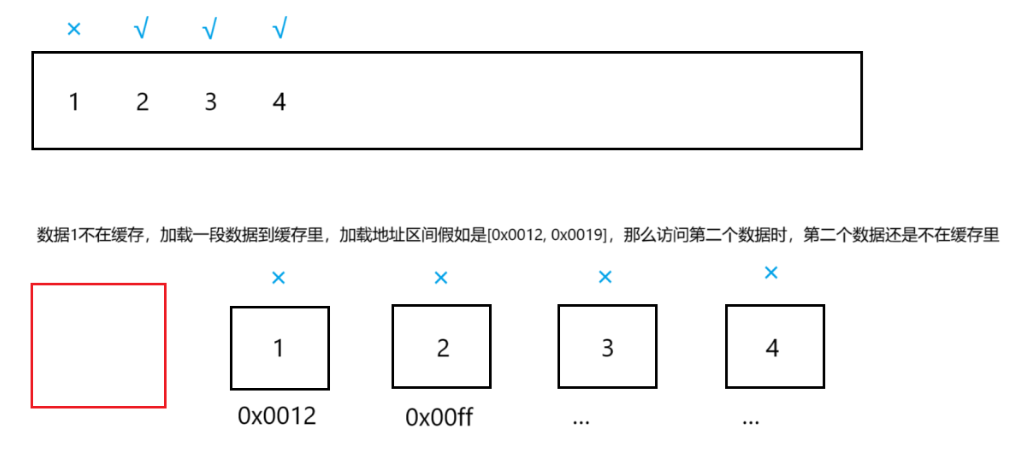
- 那么刚刚一段范围for的程序访问vector/list的差别就体现出来了。若访问它们的第一个数据且这个数据不在缓存里,读一段数据加载到缓存里:
-
vector:CPU访问第二个数据时,第二个数据就在缓存里,同理访问第三、四...个数据时,这些数据也在缓存里。因为加载了一长段字节到缓存里。这是由物理结构决定的,vector的物理地址连续。
-
list:由于结点与结点之间的地址没有直接的关联,所以加载一长段不一定会把第一个数据后面的结点加载进缓存中。我们按最坏的情况分析,当CPU访问后面的数据时,这些数据都不在缓存中。
若第一个数据不在缓存,假设加载一次读4个数据,同样的加载一次,vector不命中一个数据,三个数据命中;按最坏情况分析,list四个数据都不命中,并且还有缓存污染的问题:由于结点之间地址不连续,每次不是加载一个数据,所以会大概率加载一段与后面要访问的结点不相关的连续地址数据,这些数据不是我们需要的并且还加载到缓存里,但是缓存空间是一定的并且远远比内存小,内存是以GB为单位,则缓存是以MB/KB为单位,缓存满了之后会把其他数据挤出去。
更多缓存知识:与程序员相关的CPU缓存知识
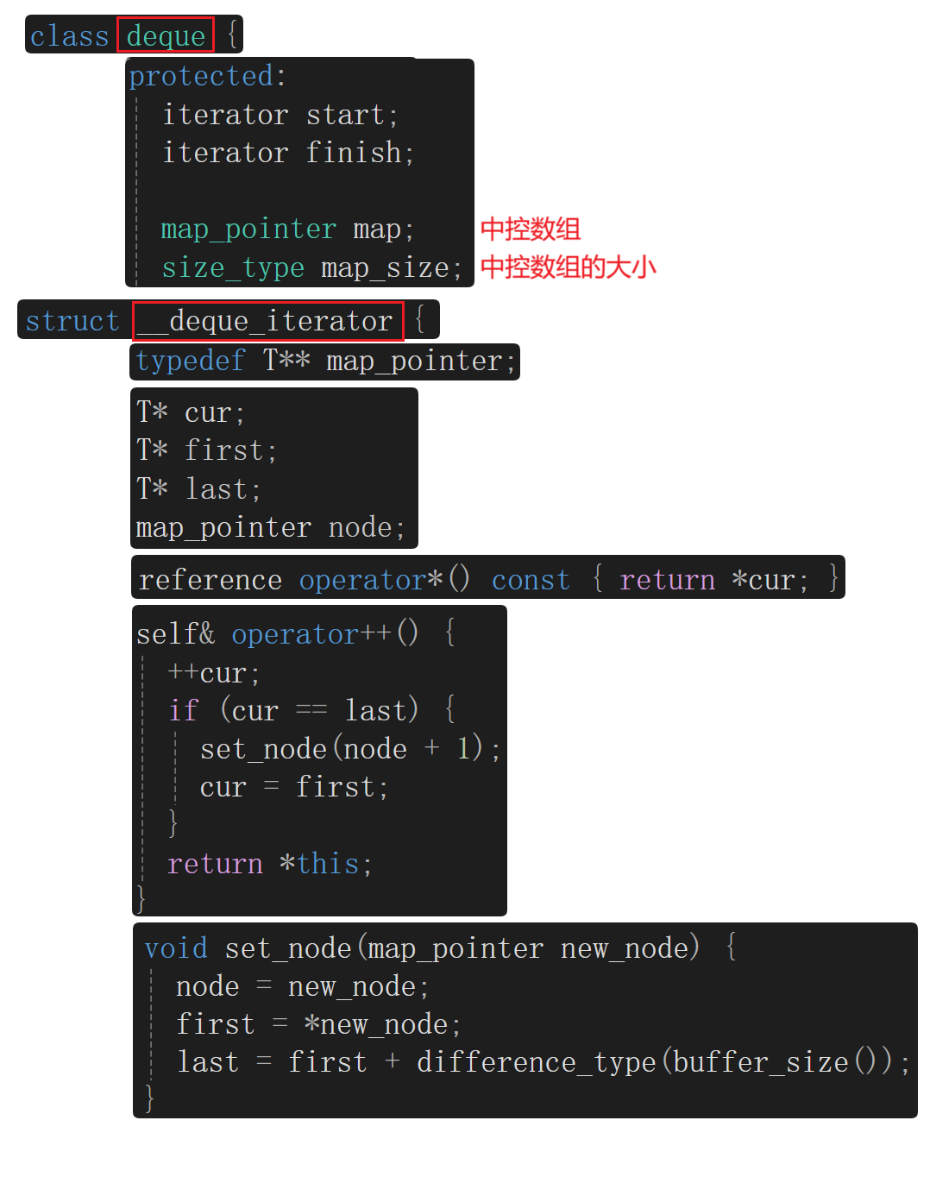
2、deque的底层结构
deque正是依据vector和list的优缺点来设计的。单纯从设计的角度看,deque既有vector的优点也有list的优点,deque也包含了二者的接口设计。
那么deque能不能代替vector和list呢?------ 不能。那么就要分析deque的底层结构,底层既不是数组结构,也不是链表结构。deque是个折中的设计,用一个一个小数组(buffer) 存储数据,假设一个buffer大小是10,满了以后,再开一个10个大小的buffer数组空间,再满了,再开一个buffer...以此类推。那么这时就没有扩容的概念了。deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个
动态的二维数组,其底层结构如下图所示:
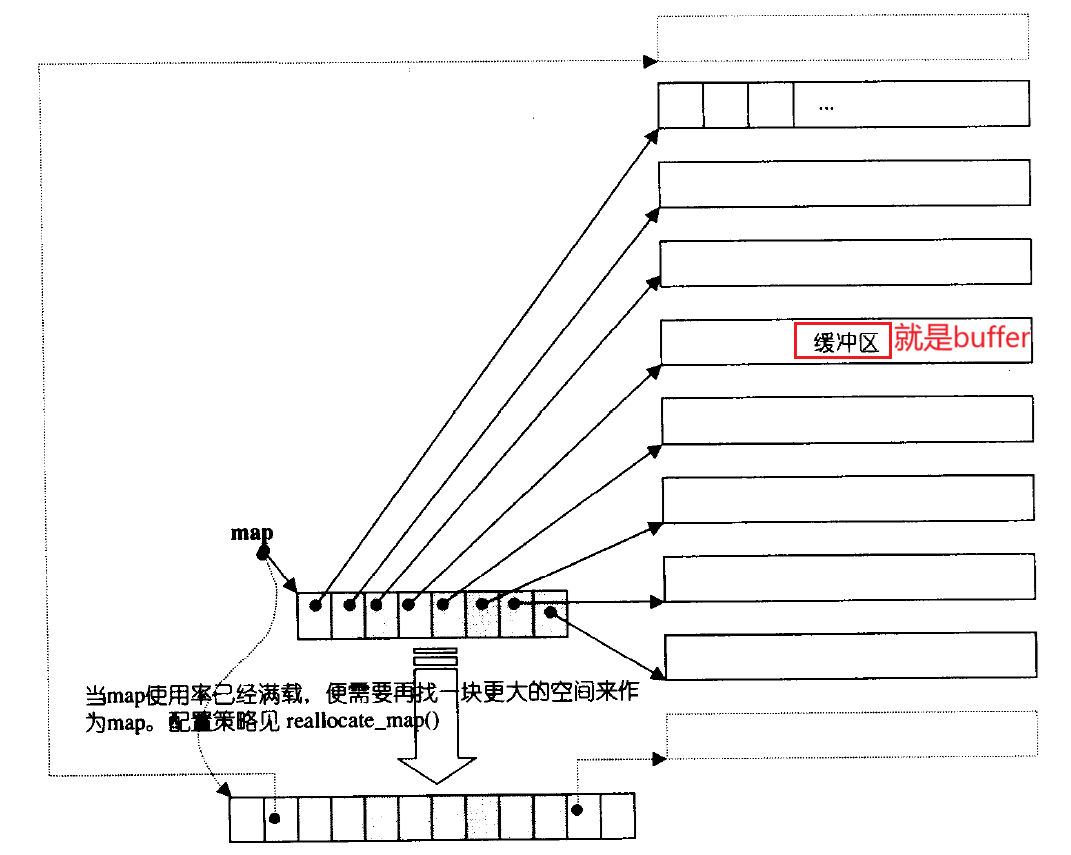
链表中的结点之间相互连接,知道了头结点的指针就知道了整个链表,那么这些buffer怎么连接起来呢?------ 中控数组,是个指针数组,依次存储buffer的地址,buffer与buffer之间不连续,但是buffer的地址存储在连续的数组中,中控数组满了会扩容,即便会扩容但是相比vector扩容代价低了很多,扩容拷贝原有数据时只需要拷贝buffer数组指针即可。
如何实现头插头删、尾插尾删、operator\[\]呢?------ deque的迭代器设计。只有理解deuqe的迭代器的意义,才能了解deuqe的结构是如何设计的。双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其"整体连续"以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
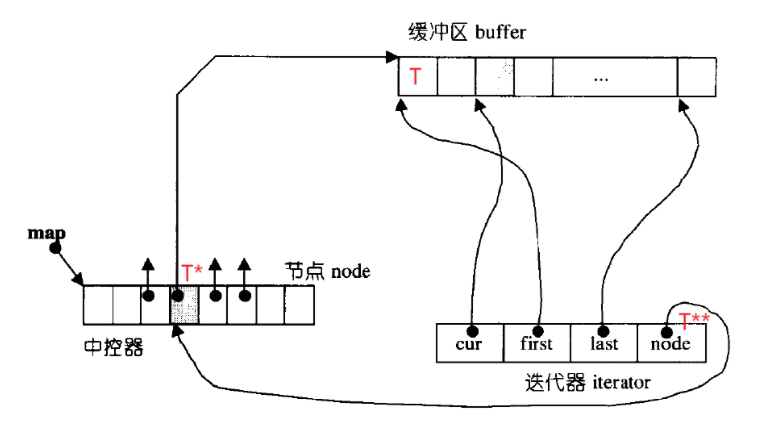
我们之前的迭代器有的是封装了一个结点指针,而这里的每个deque的迭代器是封装了四个指针,这四个指针分别指向:first和last分别指向当前要访问的buffer(要访问的数据在一个buffer里)的空间开始的位置和最后一个空间的下一个位置、cur指向buffer里的当前访问的数据、node是个二级指针,指向中控数组里对应的buffer的位置。
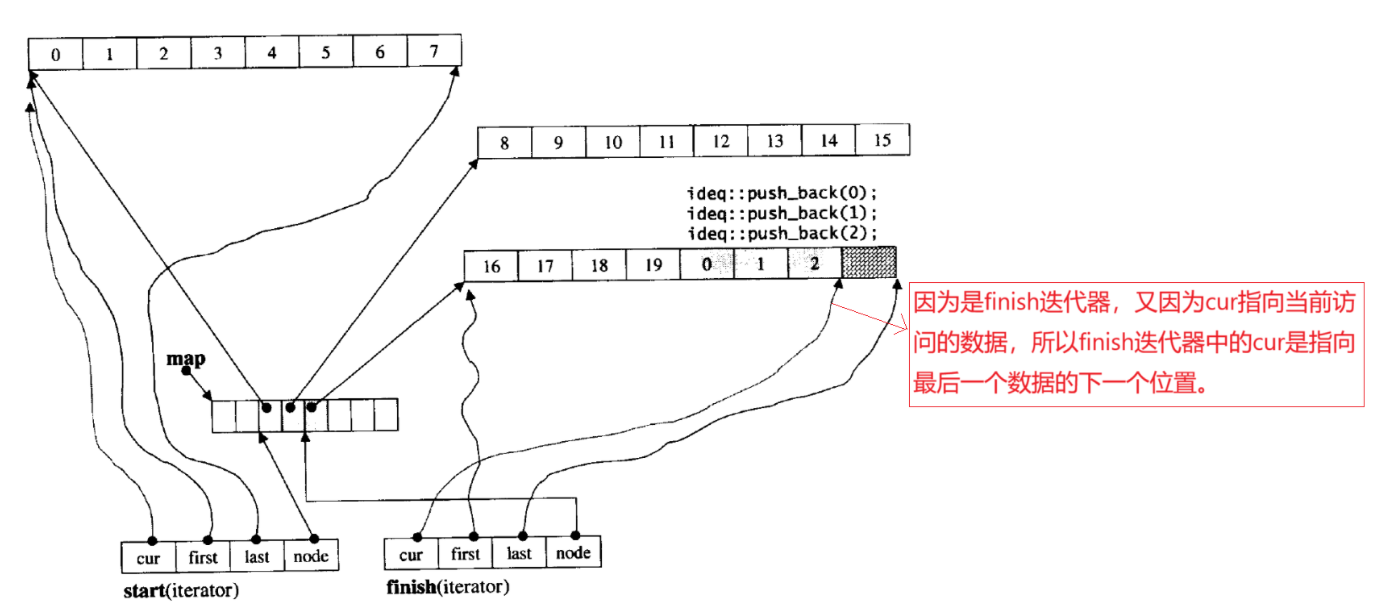
那deque是如何借助其迭代器维护其假想连续的结构呢?------ deque的迭代器结构及其遍历。
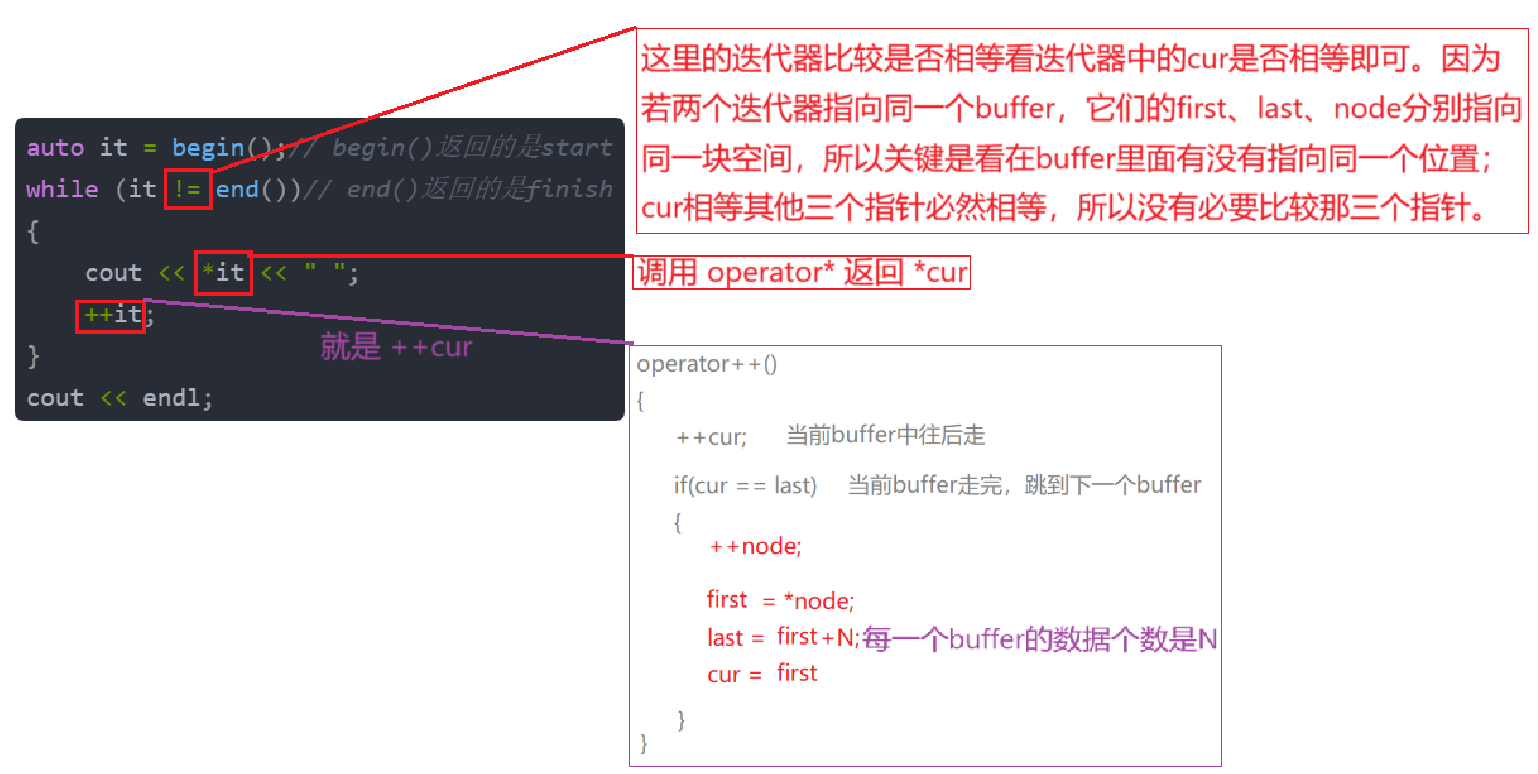
deque里包含两个迭代器:start和finish,begin()返回的是start,end()返回的是finish。
迭代器遍历代码:
上述所讲述的内容,可以大致看一下源码:

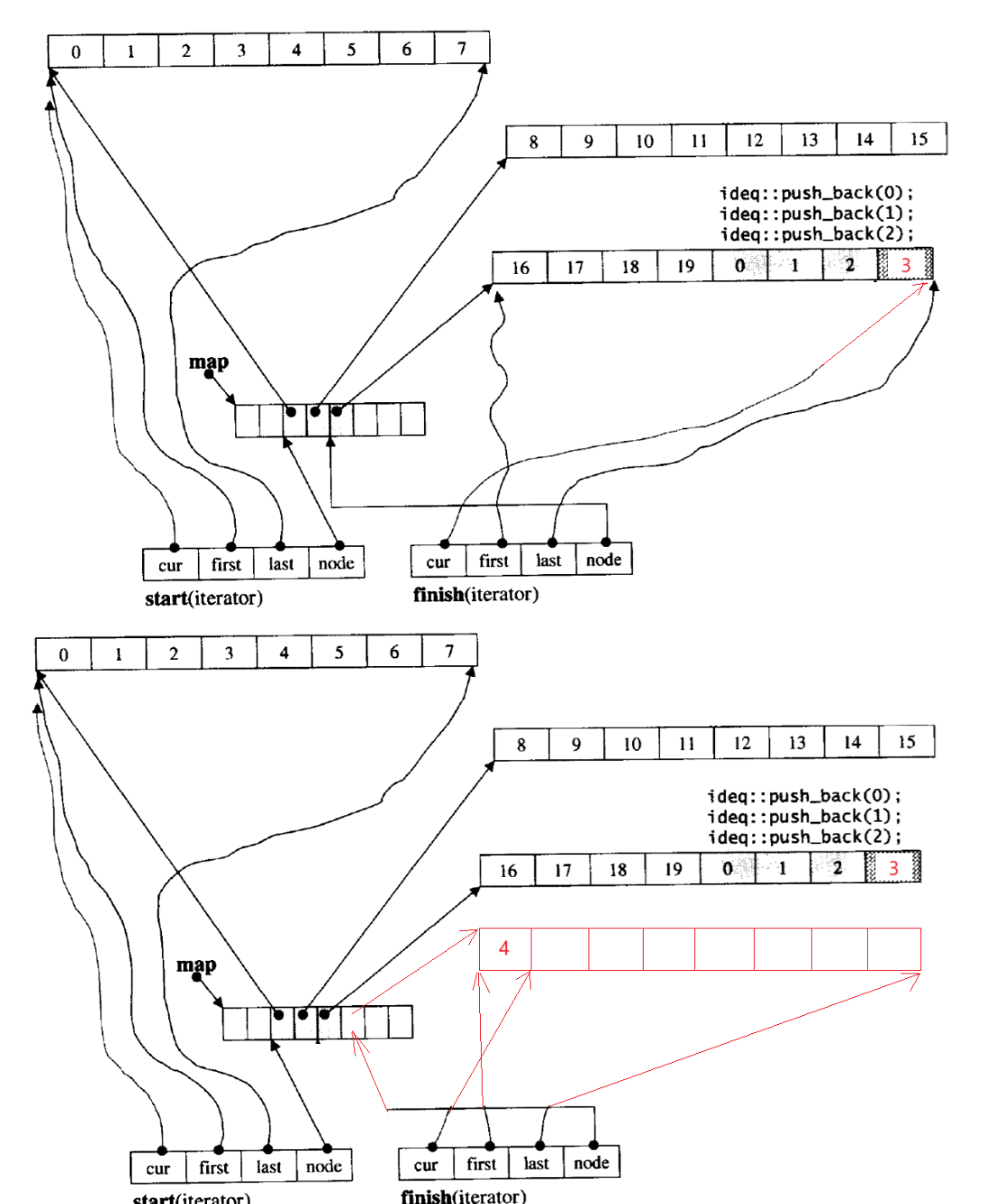
deque的插入删除与deque迭代器的关联:
- 假设连续
push_back数据3、4:
push_back本质就是更新finish。当前图中 cur != last 表示当前 buffer 还有空间,在 finish 的 cur 位置插入3,再 cur++ 。再尾插数据4,发现 cur == last ,表示当前 buffer 空间满了,则新增 buffer 。若中控数组后面有空间,就正常新增 buffer ;若没有空间,则中控数组还要扩容再新增 buffer 。我们就分析简单情况下,若中控数组后面有空间,新开一个 buffer ,其指针存在中控数组里,插入数据4,finish 的 cur 指向最后一个 buffer 的最后一个数据4的下一个位置。
pop_back:--cur,若走完一个 buffer 就要把当前 buffer 删掉,重置 finish 到上一个 buffer ,前一个 buffer 是 finish 的--node找到的。
- 假设连续
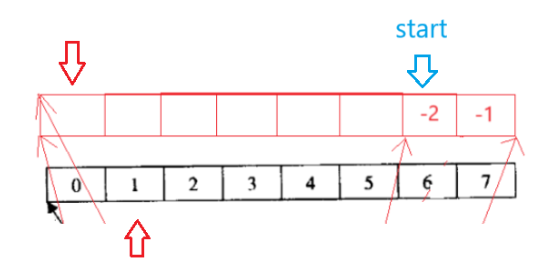
push_front数据-1、-2:
头插数据-1。push_front本质就是更新start ,若第一个buffer满了(cur == first),(若中控数组满了,则扩容)开一个新buffer空间,注意头插在新空间中的最后一个位置,因为依据迭代器的遍历逻辑这样才是连续的。start 的 cur 指向新头插进来的数据。插入数据-2时,cur != first,没满,cur--,再插入数据。
pop_front:++cur。同理,走完一个buffer就要把当前buffer删掉,重置start到下一个buffer,下一个buffer是start的++node找到的。
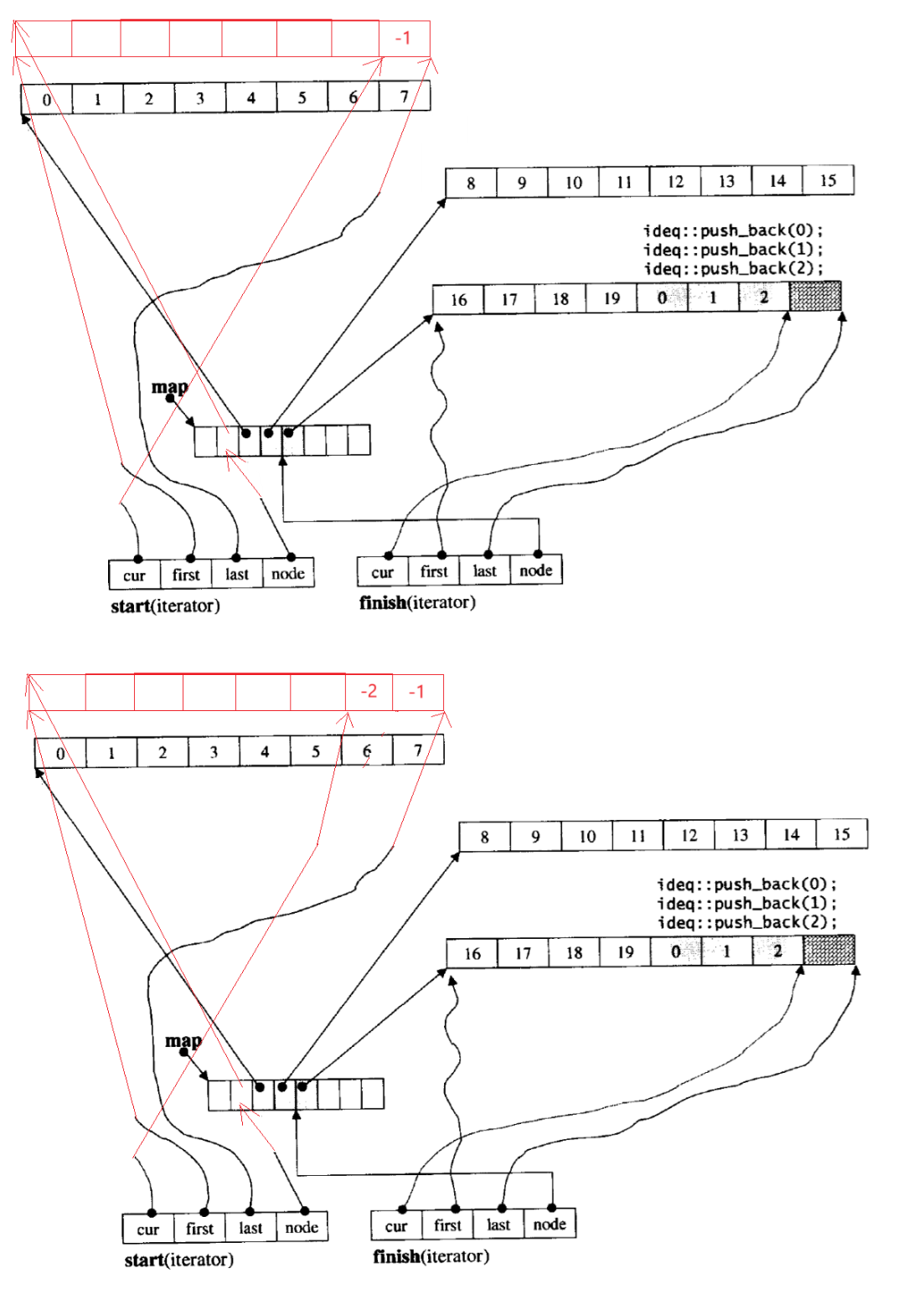
双端队列的设计:双端队列,双端就是头和尾,意味着头和尾都很方便插入和删除,参考刚刚讲过的push_back、push_front。第一个buffer的地址不是放在中控数组的第一个位置,而是放在中控数组偏中间的位置。意味着向前向后新增buffer都很方便,不需要挪动数组里的指针来给新增的buffer腾出空间存储其地址,若挪动则连带着迭代器里的node指针也挪动了效率很低。
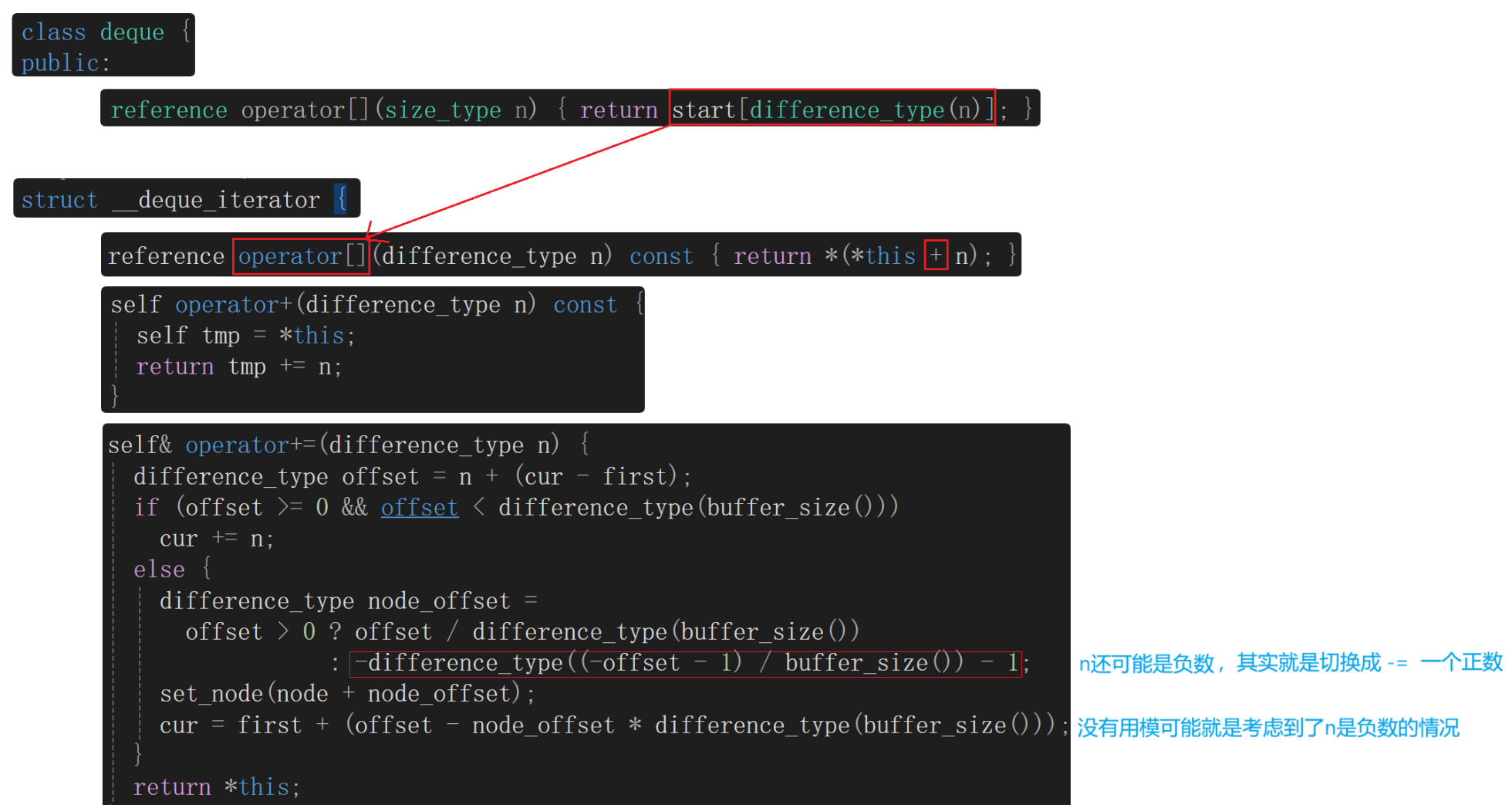
deque的随机访问如何实现?------ 借助deque的迭代器。deque的迭代器是随机迭代器,支持++、--、+、-。库里的下标随机访问是调用start,再调用 operator+ 复用 operator+=,所以我们可以看看迭代器里是如何实现 += 的,我们先尝试自己分析:
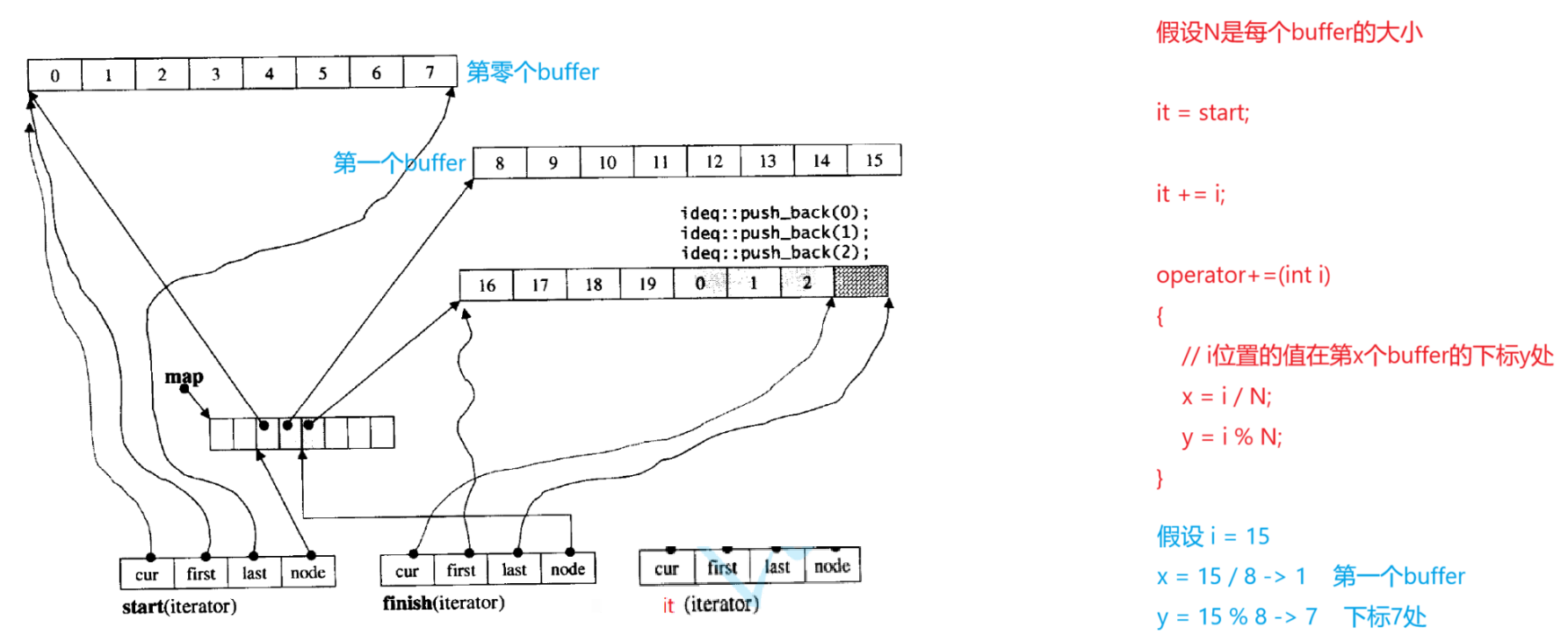
迭代器start赋值给it,假设 i 比较大,x求出结果后迭代器it的node不用一个一个跳,而是node直接跳过x个buffer即可,就相当于从start跳到第x个buffer,重置迭代器it的三个指针:node、first、last,y的结果对应it的cur指向的位置。
源码还考虑到了第一个 buffer 没有满的情况,上述分析是基于第一个buffer已满。若第一个 buffer 未满,迭代器start赋值给it,求x时没有办法整除一个buffer的大小,因为第一个buffer没有满,也没有办法得出y的值。源码这里采取的解决办法就是把第一个buffer里缺的值补上,利用偏移值offset,若第一个buffer是满的,cur - first 是0;若第一个buffer未满,那么offset就会算上cur - first 之间的个数,即还是从第一个buffer的第一个数据开始向后 +=。offset的出现就是解决头插或头删后第一个buffer不满的问题,重新算相对第一个buffer的第一个位置的下标位置。
假设从start位置开始 +=3 就相当于从第一个buffer的第一个位置开始 +=9:
operator\[\] 也是依靠迭代器来实现的,就等于调用 迭代器start里面实现的 operator\[\] ,访问第n个数据就是start迭代器加n再解引用,operator+ 再调用 operator+=:
deque的优势:比链表的访问速度更快一点,但是还是需要一定的运算,需计算第几个buffer的第几个位置,所以比vector的访问速度慢。
所以下标的随机访问i,本质上就是利用迭代器+=出来的再解引用。
两种方法实现deque中间位置的insert、erase,但是效率低:
1、所有的数据往后/前挪动再放数据,这样就与vector一样效率低下。
2、只对插入位置的当前buffer进行扩容,只挪动当前一个buffer里的数据再放入新插入的数据,相对效率好一点,但是又会影响operator\[\]的计算,即影响 operator+= ,因为个别buffer扩容会导致每个buffer的大小不一样,那么就计算不出在第几个buffer里了。所以我们就大胆的猜测,SGI版本下deque对于insert、erase的实现就是挪动数据方法,否则会影响其他接口的实现。
总结deque:
优点:
1、头尾插入删除效率很高。
相比vector和list好:vector涉及扩容,deque扩容很少且空间浪费的不多。deque相比list有CPU高速缓存命中率,还不用在需要大量申请一个又一个小块内存的情况下出现内存碎片和效率的问题。正是因为deque的头尾插入删除效率很高,所以适合做stack、queue的默认适配容器。
2、下标随机访问效率也不错,但是相比vector还是差一些。下面有示例。
因为deque要进行一系列的运算。而vector是原生数组,指向数组的指针就是天然的迭代器,访问第i个位置的值迭代器直接加到第i个位置再解引用即可。虽然时间复杂度都是O(1),但是vector还是更高效一点。
缺点:
1、中间位置的插入删除效率一般。
2、对比vector和list,没有那么极致。(什么都看起来还行,但是什么都不能成为绝对优势。例如,list完全按需申请释放,而deque不是,因为buffer存在空间浪费并且中控数组还涉及扩容;list中间位置的插入删除效率高,但是deque效率低...)
有关下标的随机访问 operator\[\] 的程序效率对比:
示例1:deque、vector存储相同的数据,调用算法库的sort排序。
C++库里的sort是快排,会大量用到下标的随机访问 operator\[\] 。下面代码中vector、deque用的都是算法库里的sort,它们之间唯一的差异就是 operator\[\] 的效率不同,有2倍左右的效率差异。
cpp
#include <iostream>
#include <deque>
#include <vector>
#include <algorithm>
using namespace std;
void test_op1()
{
srand(time(0));
const int N = 1000000;
deque<int> dq;
vector<int> v;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
dq.push_back(e);
v.push_back(e);
}
int begin1 = clock();
sort(dq.begin(), dq.end());
int end1 = clock();
int begin2 = clock();
sort(v.begin(), v.end());
int end2 = clock();
printf("deque : %d\n", end1 - begin1);
printf("vector : %d\n", end2 - begin2);
}注意一定是Release版本下:
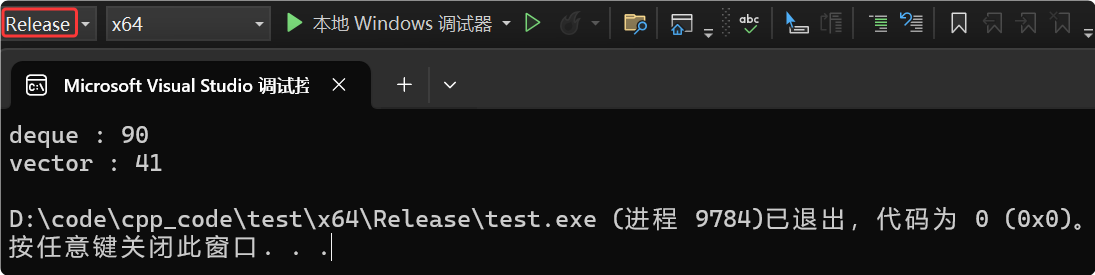
像排序这种需要大量数据的下标的随机访问deque效率会很低,不过数据量小的情况下可以使用deque下标访问。
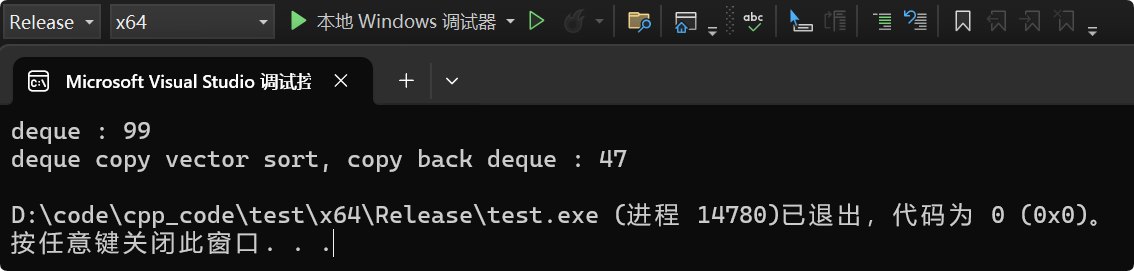
示例2:两个deque,有一样的数据。一个deque直接sort,一个deque将数据拷贝给vector再sort,再赋值给这个deque。效率依旧差了2倍。与deque的下标的随机访问对比,就连拷贝的代价都不是很大。
cpp
void test_op2()
{
srand(time(0));
const int N = 1000000;
deque<int> dq1;
deque<int> dq2;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
dq1.push_back(e);
dq2.push_back(e);
}
int begin1 = clock();
sort(dq1.begin(), dq1.end());
int end1 = clock();
int begin2 = clock();
vector<int> v(dq2.begin(), dq2.end());
sort(v.begin(), v.end());
dq2.assign(v.begin(), v.end());
int end2 = clock();
printf("deque : %d\n", end1 - begin1);
printf("deque copy vector sort, copy back deque : %d\n", end2 - begin2);
}
deque的适用场景:正是因为deque的头尾插入删除效率很高,所以适合做stack、queue的默认适配容器。实现头尾插入删除,但是少量的用到随机访问,也可以使用deque,因为list不支持随机访问,vector不支持头插头删。
所以deque是不能替代vector、list的。
四、优先级队列priority_queue的使用及其模拟实现
1、priority_queue的使用
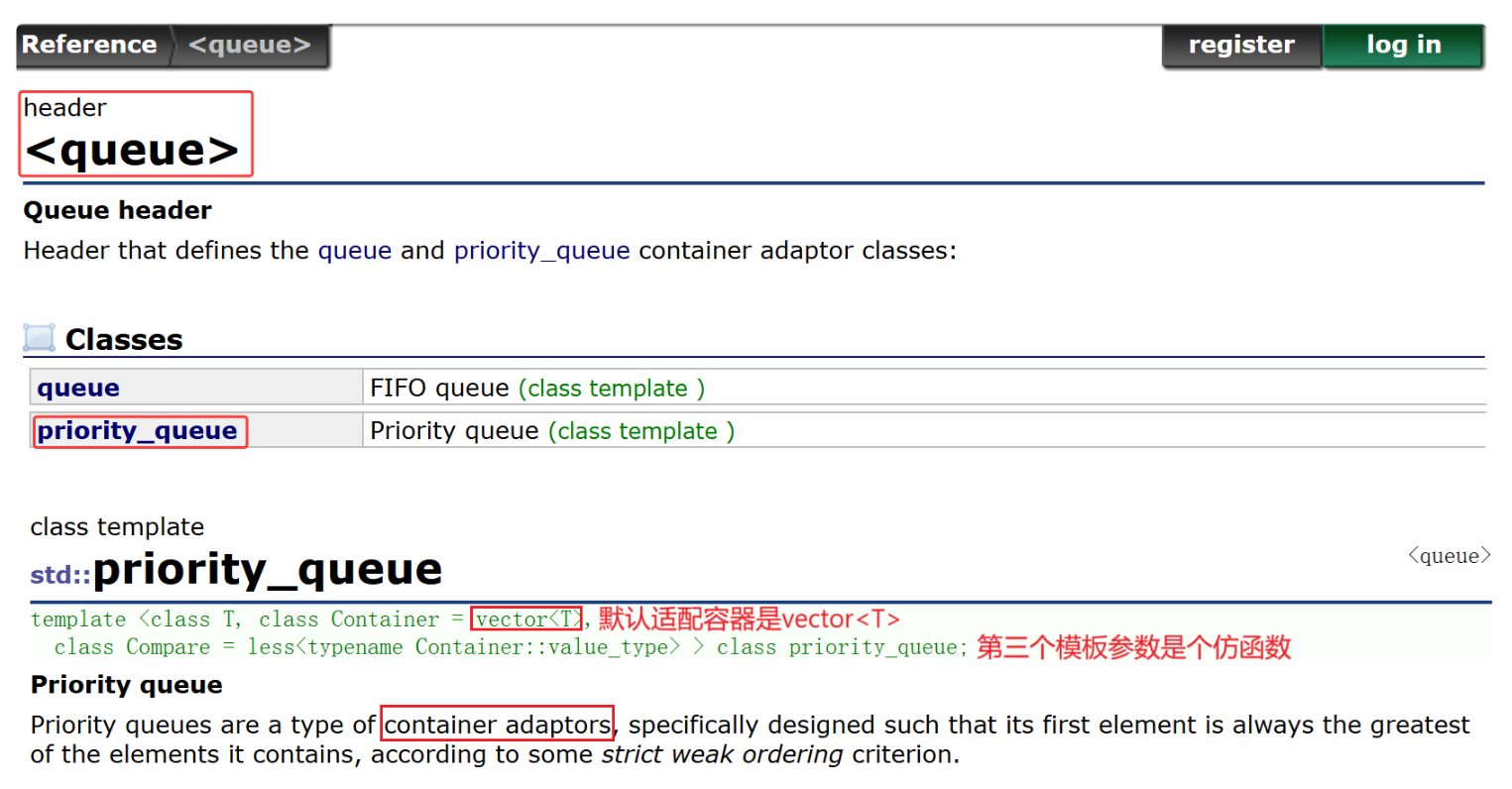
top、pop:取/删优先级高的,默认是大的数优先级更高。
push:随便插入,不管顺序。
优先级队列底层就是一个堆,默认下就是大堆,top就是堆顶,这也是我们用C语言模拟实现堆时使用top作为堆顶名字的原因,其实模拟实现堆时就是照搬优先级队列写的。
大堆:父结点大于等于孩子,根结点最大;小堆:父结点小于等于孩子。优先级队列底层就是一个堆,堆是个完全二叉树,用数组结构实现,所以优先级队列的默认适配容器是vector,建堆调整等会用到大量的下标访问,不用deque作为适配容器的原因就是因为其下标访问的效率不及vector。实现小堆就要控制第三个模板参数,greater,对应比较符号是 > 。
cpp
#include <queue>
using namespace std;
int main()
{
// 默认大的优先级更高
priority_queue<int> pq;
pq.push(5);
pq.push(1);
pq.push(5);
pq.push(6);
pq.push(3);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
cpp
// 小堆
priority_queue<int, vector<int>, greater<int>> pq;
双端队列、优先级队列都不是先进先出。双端队列是vector、list功能的融合体,优先级队列是优先级高的先出,可以是大的优先级高,也可以是小的优先级高,看具体的需求,默认是大的优先级高,小的优先级高需传递第三个模板参数 greater< T > 。但是由于历史的原因,优先级队列设计的地方有要注意的地方,默认大的是优先级高的,大堆,但是却传递的是比较符号是小于的仿函数;若要控制小的优先级高,就要传递大于的仿函数。
算法题
解析:LeetCode 215题解 | 数组中的第K个最大元素
2、priority_queue的模拟实现
优先级队列模拟实现、仿函数:
优先级队列先实现出来再上仿函数
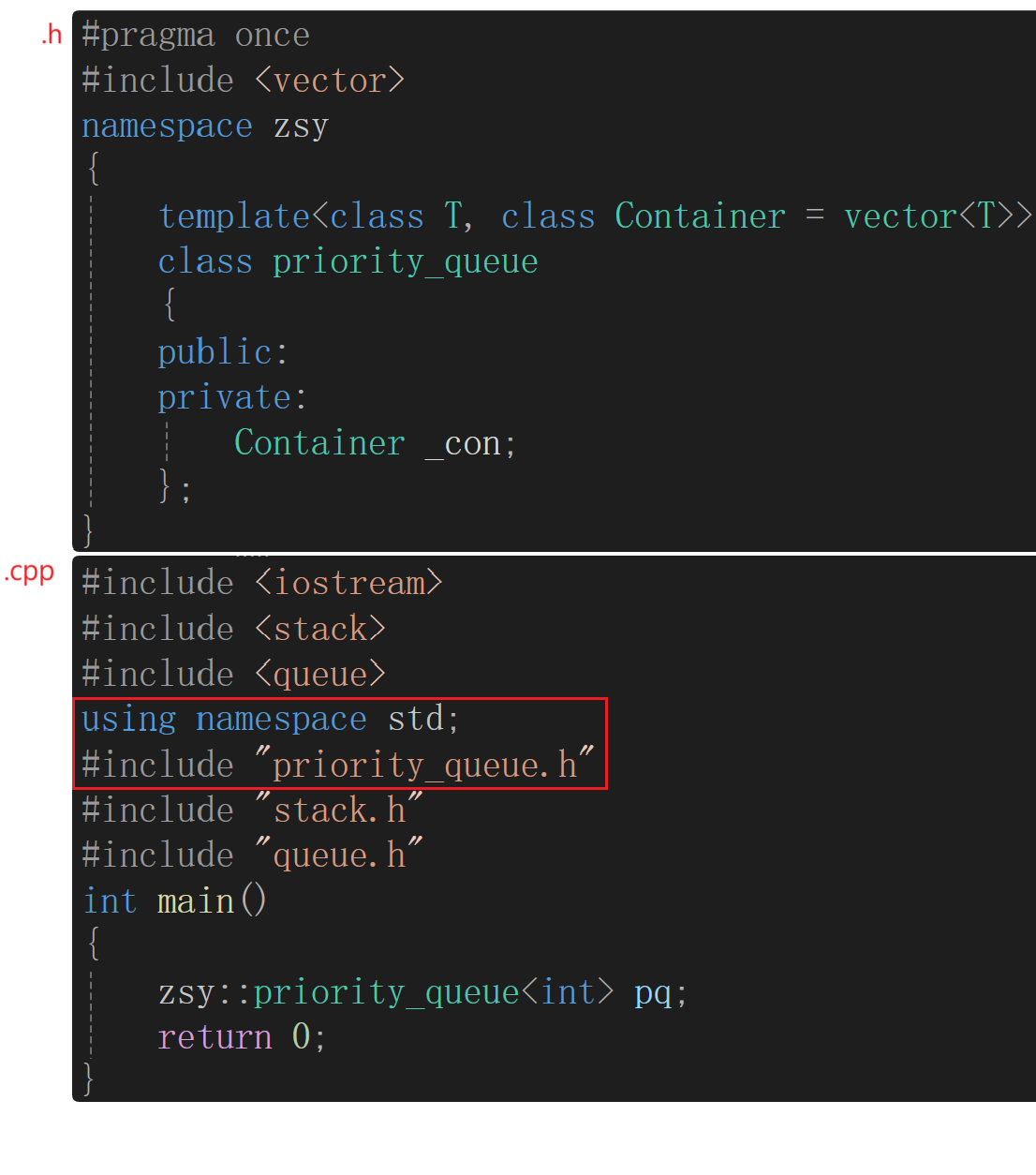
命名空间的展开与自己写的头文件在.cpp文件中的顺序
自己写的头文件包在命名空间的展开下面不会出现问题,但是包在命名空间的展开上面可能会出现问题,所以为了避免出现这样的问题,统一将自己写的头文件包在命名空间的展开下面。
- 示例1:自己写的头文件包在命名空间的展开下面不会出现问题。
- 示例2:自己写的头文件包在命名空间的展开上面可能不会出现问题。
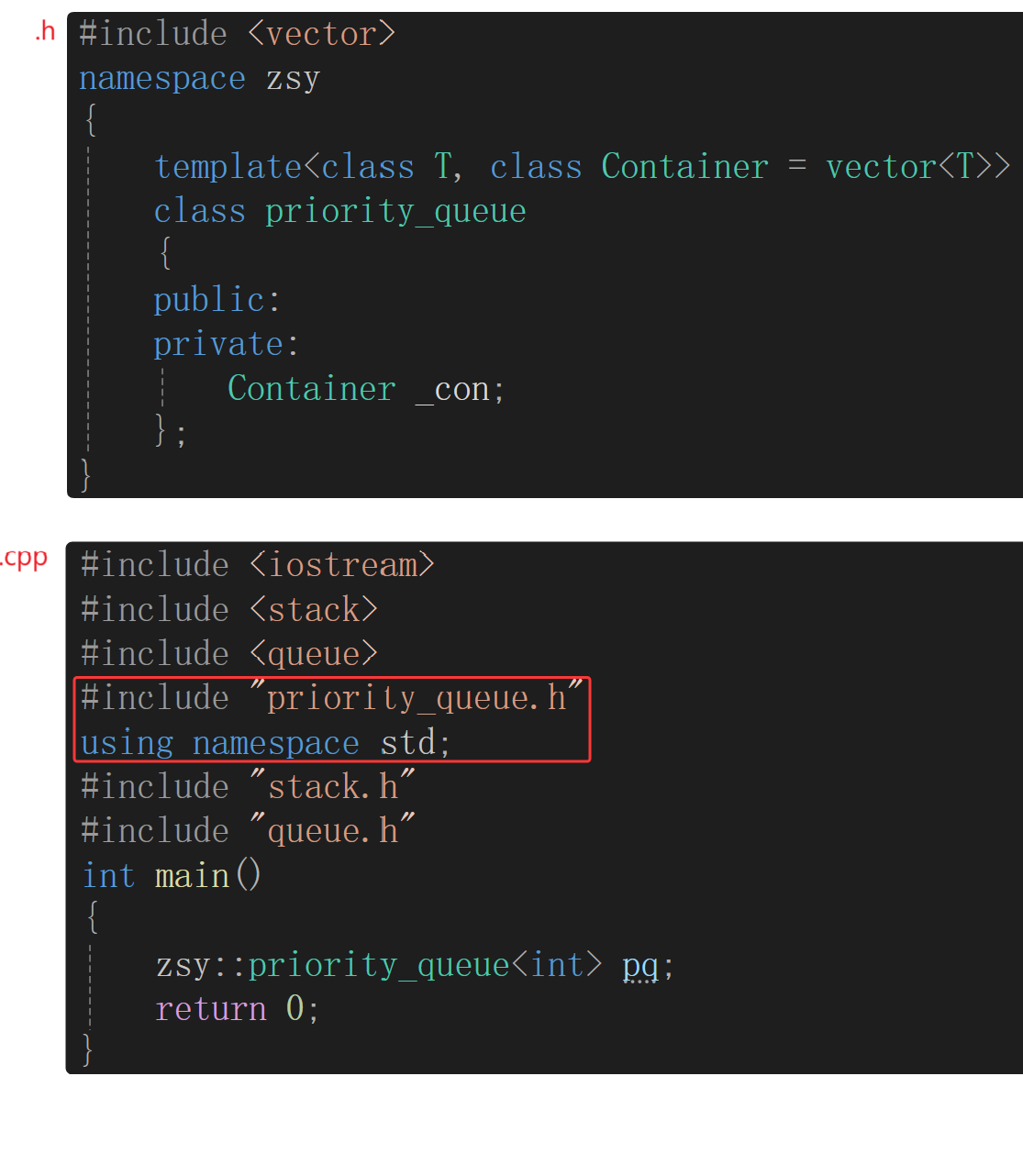
在std命名空间里可能找不到vector,但是这里没有出现问题,那么没有出现问题的原因是什么呢?
在zsy::priority_queue<int> pq;里面才是真正用到 vector 的地方,没传递第二个模板参数默认用缺省值vector< T >,实例化后是zsy::priority_queue<int, vector<int>> pq;,这时才会向上找vector的出处,向上找vector的头文件是找得到的,因为包了头文件priority_queue.h,这个头文件在.cpp文件中展开,该头文件中包了vector的头文件<vector>,都在.cpp中展开,又因为后面接着展开命名空间std中的所有成员#include "priority_queue.h" using namespace std;,所以没有报错。
- 示例3:自己写的头文件包在命名空间的展开上面可能会出现问题。
编译器编译时没有priority_queue.h,因为.h在预处理阶段都会在.cpp展开,相当于这里只有一个Test.cpp:
相当于在Test.cpp里的 #include "priority_queue.h"会替换为该头文件里的内容。
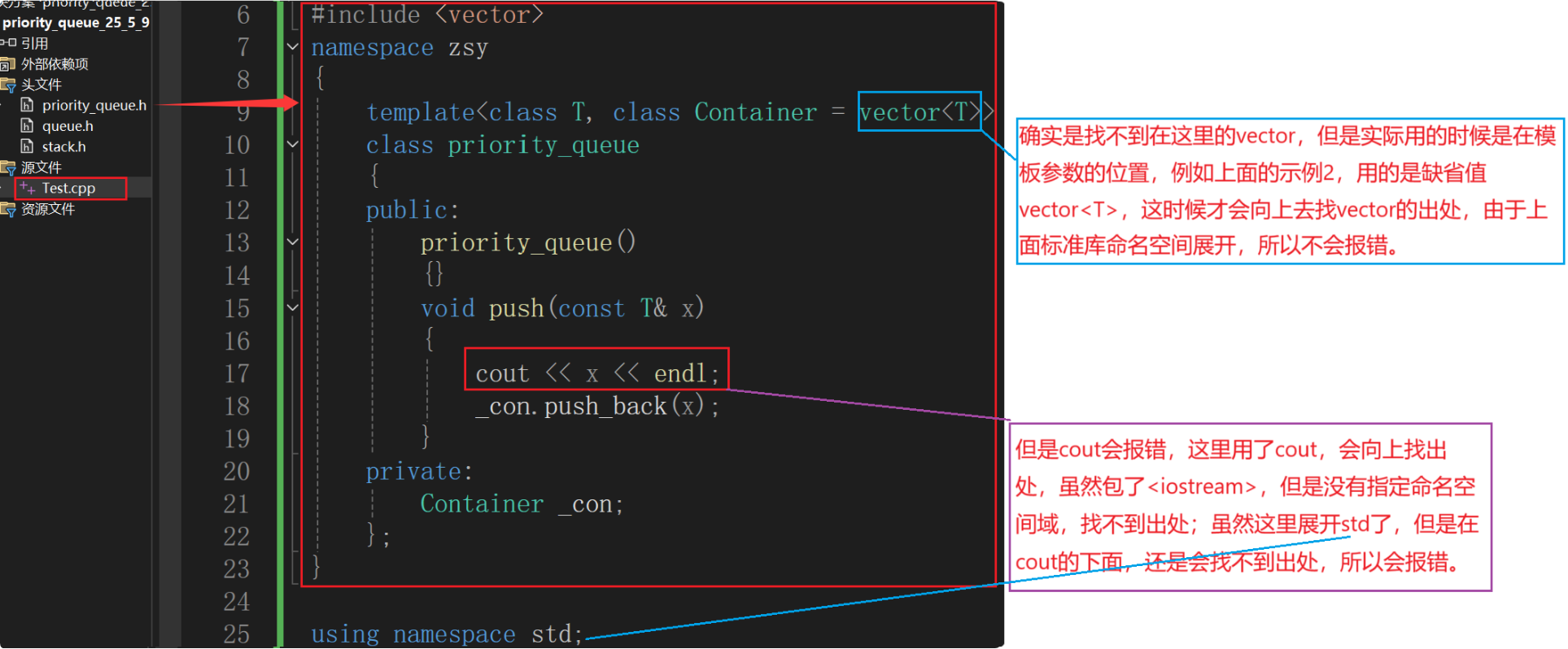
示例2与示例3的区别:示例2vector是在展开之后用的,所以不会报错;示例3cout是在展开之前用的,所以会报错。
所以统一的建议就是将自己写的头文件包在展开命名空间之后,避免找不到出处:
接着模拟实现优先级队列:
push
不只是把数据push进去,还要保证是一个堆结构。
接下来就需要回顾堆相关的概念了。以大堆为例进行讲解(切换小堆借助仿函数即可,具体操作稍后讲解~):
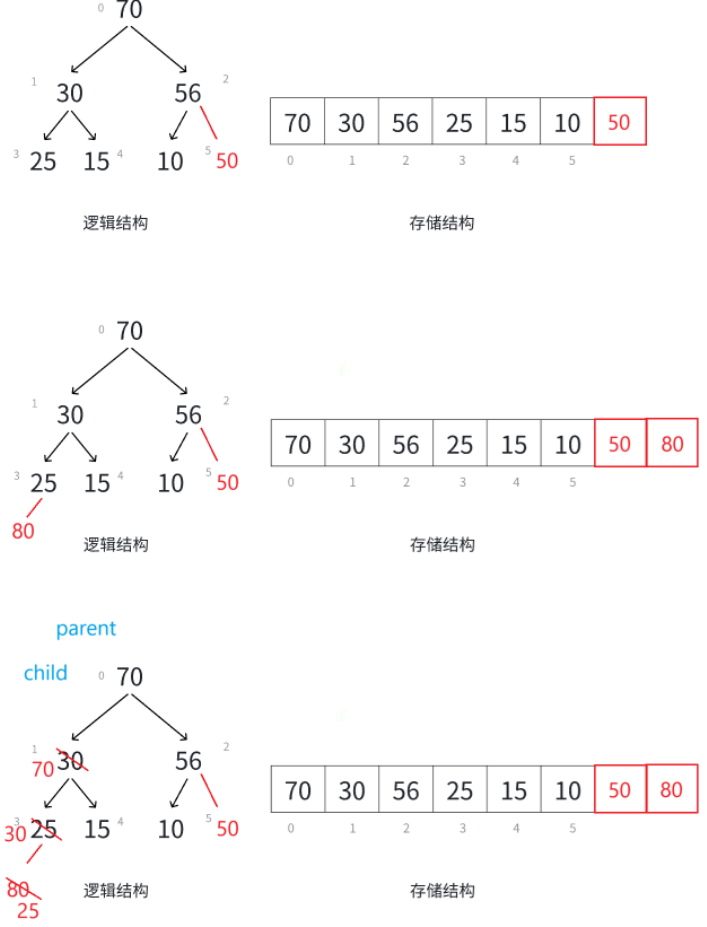
例如连续push数据50、80。
插入数据50后还是大堆结构,不用改动。再插入数据80,35物理结构上是插入在50的后面,逻辑结构上是插入在25的左边,此时不是一个堆结构了,除插入的数据,其余的数据构成堆结构,满足使用向上调整算法的前提,那么就要写一个向上调整算法:
cpp
template<class T, class Container = vector<T>>
class priority_queue
{
public:
void push(const T& x)
{
_con.push_back(x);
adjustup(_con.size() - 1);
}
private:
void adjustup(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
private:
Container _con;
};push的时间复杂度是O(logn)
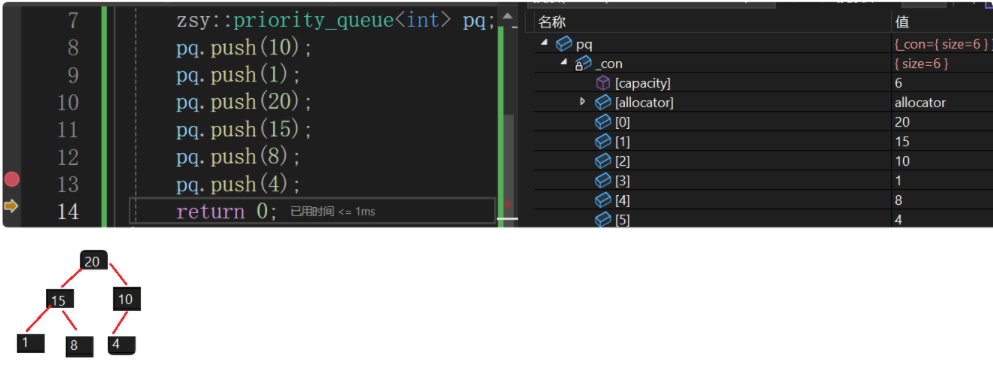
验证几个值看是否构成大堆:
pop
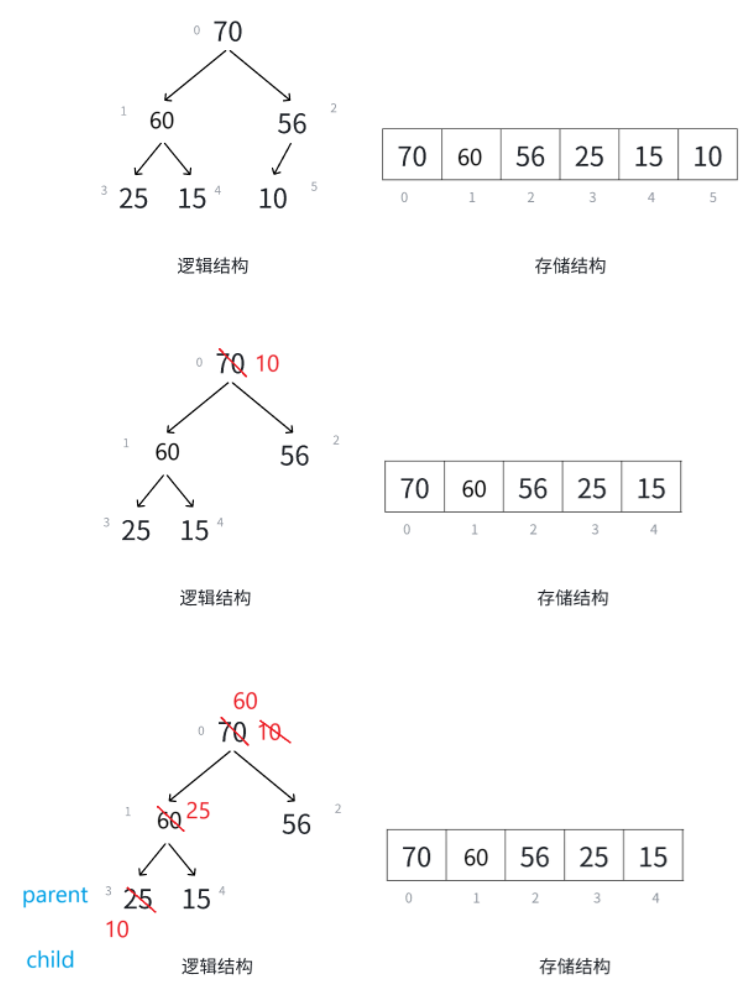
pop三步走:交换、删除、向下调整。
不能去直接覆盖删除,否则逻辑结构就变了,就不是一个堆结构了。交换删除后除根以外,左右子树都是堆结构,满足使用向下调整算法的前提,那么需要写一个向下调整算法:
cpp
template<class T, class Container = vector<T>>
class priority_queue
{
public:
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjustdown(0);
}
private:
void adjustdown(size_t parent)
{
size_t child = 2 * parent + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && _con[child + 1] > _con[child]) child++;
if (_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = 2 * parent + 1;
}
else break;
}
}
private:
Container _con;
};验证pop后是否是堆结构:
top
获取堆顶的值:
cpp
const T& top() const
{
return _con[0];
}
区分:
1、接口名字一样,但是含义不一样:
stack的top:栈顶元素
priority_queue的top:堆顶元素
2、库里实现的版本的差异:stack的top实现了两个版本而priority_queue的top只实现的const版本。这是为什么呢?这是因为,对于栈,可以修改栈顶元素。但是对于优先级队列,由于底层结构是堆,若修改了堆顶元素,那么可能会改变堆的结构。所以priority_queue的top只有const版本,是普通对象、const对象都可以调用的。
size、empty
cpp
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
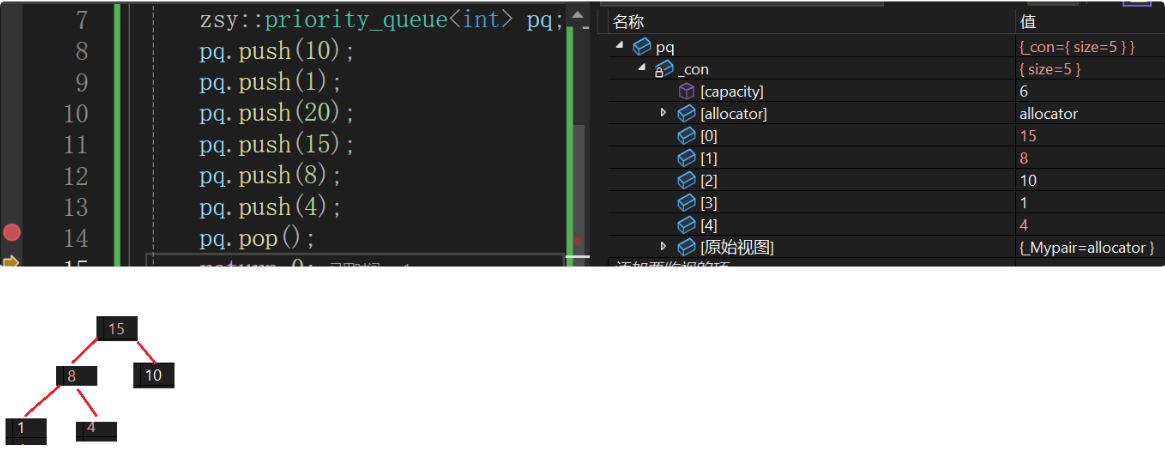
}测试当前priority_queue的结构
cpp
#include <iostream>
using namespace std;
#include "priority_queue.h"
int main()
{
zsy::priority_queue<int> pq;
pq.push(10);
pq.push(1);
pq.push(20);
pq.push(15);
pq.push(8);
pq.push(4);
pq.pop();
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
容器适配器的接口不都是像stack、queue那样单纯的包一下容器的接口,有可能还要做其他的行为,例如priority_queue的push、pop接口,里面还有调整、交换等算法。从数据结构的角度,priority_queue就是用一个顺序表适配出一个堆。
第二个模板参数是deque也是可以的,也是可以输出正确结果:
cpp
zsy::priority_queue<int, deque<int>> pq;(适配器不仅仅有容器适配器,反向迭代器就是一个迭代器适配器,各个容器的正向迭代器就可以适配出各个容器的反向迭代器------作为拓展内容学习。)
上层看的角度都是优先级队列,底层分别用vector、deque适配却是天差地别的。封装的缘故,屏蔽了底层的细节,从功能角度看都是一样的。因此,堆的底层不一定是个数组,还可能是deque(注意:deque不是一个数组,它是由多个小数组(buffer)组成的更复杂的结构),只要是支持下标访问的容器就可以。但是实际中不会用deque作为优先级队列的适配容器的,因为建堆调整等操作,需要用到大量的下标访问,而deque的operator\[\] 效率不及vector。
仿函数/函数对象:模仿函数调用的类/类对象
重载了operator()的类就叫仿函数,或者叫函数对象。
- 仿函数:具体指的是类。让类模仿函数调用的功能,类实例化出的对象是个函数对象,这个对象可以像函数调用一样去调用
operator()。- 函数对象:具体指的是类实例化出的对象。
仿函数是个类,写成类模板的形式,用struct/class都行。仿函数里面重载了operator(),重载的就是函数调用时后面跟的()运算符:
cpp
// 仿函数/函数对象
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
int main()
{
Less<int> lessFunc;
cout << lessFunc(2, 3) << endl;
//cout << lessFunc.operator()(2, 3) << endl;// 显示调用
Greater<int> greaterFunc;
cout << greaterFunc(2, 3) << endl;
//cout << greaterFunc.operator()(2, 3) << endl;// 显示调用
return 0;
}返回值可以作为if/while语句的表达式。1则执行语句,0则不执行语句:

单独看很像函数的调用,实际是函数对象调用运算符重载operator() 。
cpp
lessFunc(2, 3)- 利用仿函数控制比较逻辑
之前的模板参数控制的是数据类型;仿函数用模板参数Compare接收并实例化出不同的类,这里的模板参数控制的是比较逻辑(>或<)。
升序 <,传Less
降序 >,传Greater
例如用C++写一个直接插入排序:
c
// C实现版本
void InsertSort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else {
break;
}
}
arr[end + 1] = tmp;
}
}严格来说,形参 int* arr这里要改成迭代器,因为会传递迭代器区间过来。但是这里就不要改动这么大了,会很麻烦。并且以后自己用C++写排序也不用迭代器的方式。因为STL的算法写成迭代器区间是因为要与STL进行深度融合,自己写的话写成普通的数组,或者vector实例化出的类,也不用多加个参数n了:
cpp
template<class T>
void InsertSort(T* arr, int n)
{}
template<class T>
void InsertSort(vector<T>& a)
{
for (int i = 0; i < a.size() - 1; i++)
{}
}
可以传递有名对象/匿名对象,实践中更喜欢传递匿名对象:
cpp
InsertSort(v, Less<int>());// 匿名对象
Less<int> lessFunc;// 有名对象
InsertSort(v, lessFunc);完整用C++实现的直接插入排序算法:
cpp
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
template<class T, class Compare>
void InsertSort(vector<T>& arr, Compare com)
{
for (int i = 0; i < arr.size() - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
//if (arr[end] > tmp)
if (com(tmp, arr[end]))
{
arr[end + 1] = arr[end];
end--;
}
else {
break;
}
}
arr[end + 1] = tmp;
}
}
int main()
{
vector<int> v = { 1, 5, 6, 8, 9, 2 };
InsertSort(v, Less<int>());// 升序
for (auto& e : v)
{
cout << e << " ";
}
cout << endl;
return 0;
}
cpp
// 降序
InsertSort(v, Greater<int>());
若像库里的一样,排序在默认情况下是排升序的,怎么自己模拟实现呢?只需要在上述排序算法中改动:
cpp
template<class T, class Compare = Less<T>>
void InsertSort(vector<T>& arr, Compare com = Less<T>())
{}- 将上述仿函数的逻辑代码套用在priority_queue中
优先级队列也要用大于小于来控制建立大堆还是小堆。与库里的保持一致,仿函数类名写成小写的。
比较逻辑不是写死的,是可以通过仿函数决定的,而仿函数是通过(传递的)参数实例化决定的。
cpp
// priority_queue.h
#include <vector>
namespace zsy
{
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
// 只能从右往左连续给缺省值
template<class T, class Container = vector<T>, class Compare = less<T>>
class priority_queue
{
public:
priority_queue()
{}
void push(const T& x)
{
_con.push_back(x);
adjustup(_con.size() - 1);
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjustdown(0);
}
const T& top() const
{
return _con[0];
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
void adjustup(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
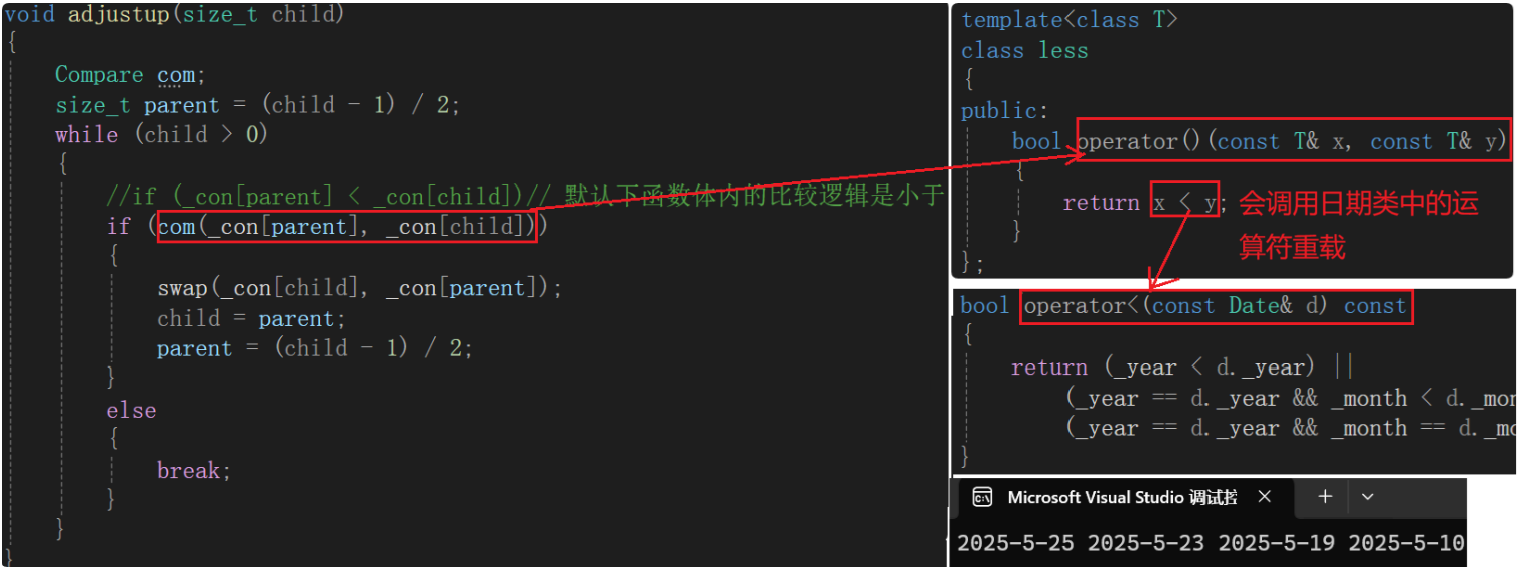
//if (_con[parent] < _con[child])// 默认下函数体内的比较逻辑是小于
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void adjustdown(size_t parent)
{
Compare com;
size_t child = 2 * parent + 1;
while (child < _con.size())
{
// 默认下函数体内的比较逻辑是小于
//if (child + 1 < _con.size() && _con[child] < _con[child + 1]) child++;
if (child + 1 < _con.size() && com(_con[child], _con[child + 1])) child++;
//if (_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = 2 * parent + 1;
}
else break;
}
}
private:
Container _con;
};
}
cpp
// Test.cpp
#include <iostream>
#include <deque>
using namespace std;
#include "priority_queue.h"
int main()
{
zsy::priority_queue<int, vector<int>, greater<int>> pq;
pq.push(10);
pq.push(1);
pq.push(20);
pq.push(15);
pq.push(8);
pq.push(4);
pq.pop();
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
- 利用仿函数自行调整比较逻辑
利用仿函数控制比较逻辑,不仅能解决不用自己写建大、小堆算法的问题,而是利用模板借助编译器写出建立大小堆算法,不仅如此还能解决下列特殊的问题:
- 如果在priority_queue中放自定义类型的数据,用户需要在自定义类型中提供 > 或者 < 的重载:
cpp
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
:_year(year)
,_month(month)
,_day(day)
{}
bool operator<(const Date& d) const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
friend ostream& operator<<(ostream& _cout, const Date& d);
private:
int _year;
int _month;
int _day;
};
ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
int main()
{
zsy::priority_queue<Date> pq;
pq.push({ 2025, 5, 10 });
pq.push({ 2025, 5, 19 });
pq.push({ 2025, 5, 25 });
pq.push({ 2025, 5, 23 });
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
注意:
- 可以放在类里面,但是不太好。最好做声明和定义的分离:
cpp
friend ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}- push匿名/有名对象都行,不过更推荐这样的写法,因为更简单:多参数构造函数支持隐式类型转换
cpp
pq.push(Date(2025, 5, 10));// 匿名对象
pq.push({ 2025, 5, 10 });// 多参数构造函数支持隐式类型转换-
若在priority_queue中放自定义类型的数据,用户没有在自定义类型中提供对应的 > 或者 < 的重载呢?那么需要自己写仿函数作为参数传递。
-
- 示例1,更特殊的场景:插入的不是日期类,而是日期类的指针。
cpp
int main()
{
zsy::priority_queue<Date*> pq;
pq.push(new Date(2025, 5, 10));
pq.push(new Date(2025, 5, 19));
pq.push(new Date(2025, 5, 23));
while (!pq.empty())
{
cout << *pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}但是运行结果不一定是有序的,而且每一次运行结果总是变化的:
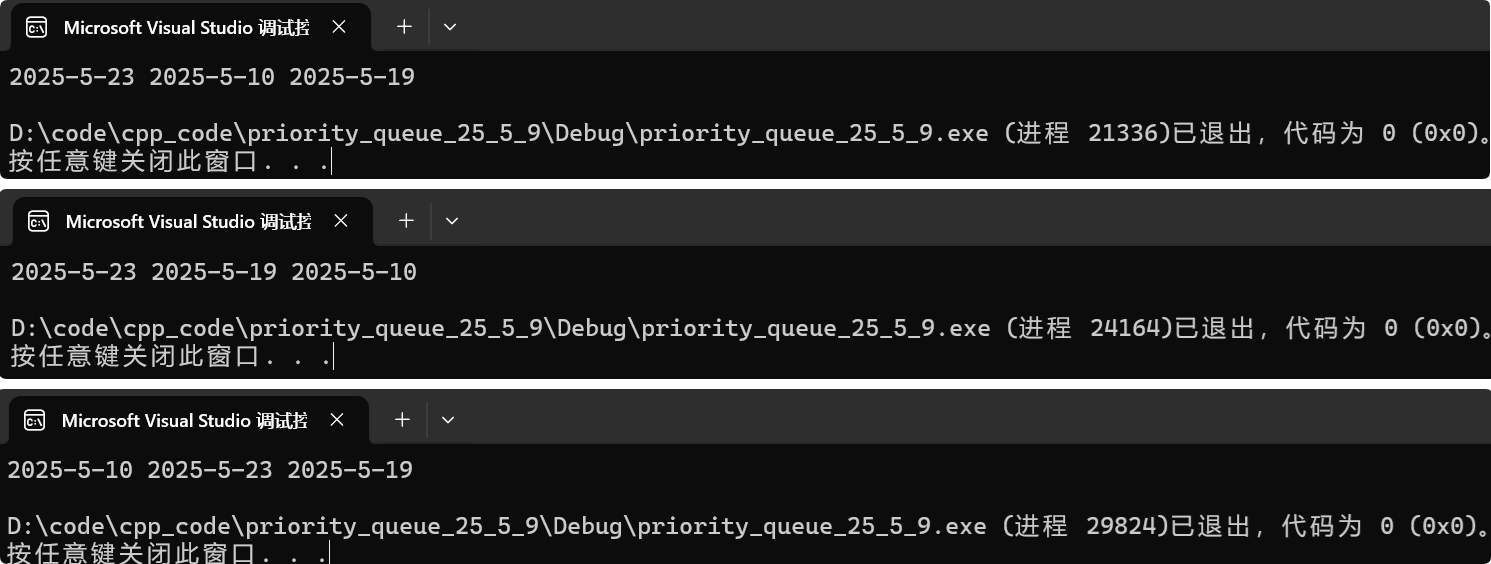
因为比较的是指针大小,而new出来的地址的大小是不确定的。那么怎么解决呢?
假设在里面加解引用:
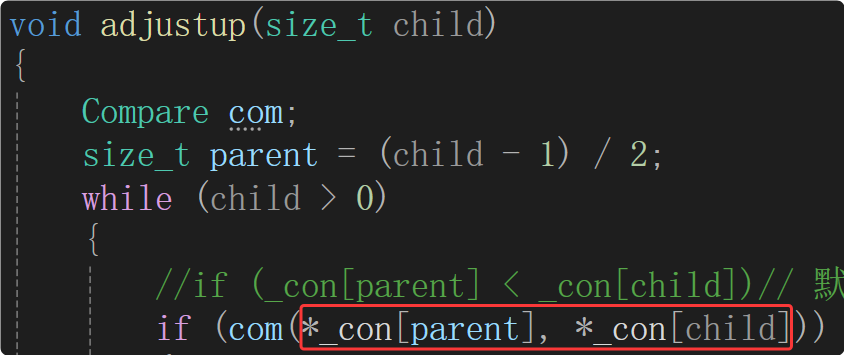
不行的,假如存储的数据类型不是指针,而是int,但是int不能解引用。
解决办法如下,再写一个仿函数,专门接收指针类型,比较的不是指针,而是指针指向的内容:
cpp
struct PDataCompare
{
bool operator()(const Date* p1, const Date* p2)
{
return *p1 < *p2;// < Less,大堆
}
};
int main()
{
zsy::priority_queue<Date*, vector<Date*>, PDataCompare> pq;
pq.push(new Date(2025, 5, 10));
pq.push(new Date(2025, 5, 19));
pq.push(new Date(2025, 5, 23));
while (!pq.empty())
{
cout << *pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
仿函数总结
仿函数:
- 控制比较逻辑(>/<)。
- 自行调整比较逻辑。不仅仅是升降序、大小堆。若想按照特定的方式去比较,则自己写一个仿函数,满足用户需求。比如数据类型是指针,但是不想比较指针的大小,想比较指向的数据的大小;再比如数据是string字符串,默认是按照ASCII比较,但是想按照长度去比较...
-
- 示例2:string默认按照ASCII比较:
cpp
int main()
{
zsy::priority_queue<string> pqstr;
pqstr.push("11111");
pqstr.push("2222");
pqstr.push("33");
while (!pqstr.empty())
{
cout << pqstr.top() << " ";
pqstr.pop();
}
cout << endl;
return 0;
}
但是现在不期望按照ASCII逻辑比较大小,而是想按照字符串的长度比较大小,为了满足这一需求,需要自己写一个仿函数:
cpp
struct StringCompare
{
bool operator()(const string& str1, const string& str2)
{
return str1.size() < str2.size();
}
};
int main()
{
zsy::priority_queue<string, vector<string>, StringCompare> pqstr;
pqstr.push("11111");
pqstr.push("2222");
pqstr.push("33");
while (!pqstr.empty())
{
cout << pqstr.top() << " ";
pqstr.pop();
}
cout << endl;
return 0;
}
priority_queue的模拟实现代码
cpp
// priority_queue.h
#include <vector>
namespace zsy
{
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
// 只能从右往左连续给缺省值
template<class T, class Container = vector<T>, class Compare = less<T>>
class priority_queue
{
public:
priority_queue()
{}
void push(const T& x)
{
_con.push_back(x);
adjustup(_con.size() - 1);
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjustdown(0);
}
const T& top() const
{
return _con[0];
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
void adjustup(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
//if (_con[parent] < _con[child])// 默认下函数体内的比较逻辑是小于
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void adjustdown(size_t parent)
{
Compare com;
size_t child = 2 * parent + 1;
while (child < _con.size())
{
// 默认下函数体内的比较逻辑是小于
//if (child + 1 < _con.size() && _con[child] < _con[child + 1]) child++;
if (child + 1 < _con.size() && com(_con[child], _con[child + 1])) child++;
//if (_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = 2 * parent + 1;
}
else break;
}
}
private:
Container _con;
};
}