文章目录
- 前言
- YOLO框架v2
-
- 1、YOLOv1与v2的比较
- 2、BatchNorm
- 3、分辨率变化
- 4、v2网络结构
- 5、聚类先验框
- [6、YOLO v2 Anchor Box](#6、YOLO v2 Anchor Box)
- [7、Directed Location Prediction直接位置预测](#7、Directed Location Prediction直接位置预测)
- 8、感受野
- [9、YOLO v2 Fine Grained Feature](#9、YOLO v2 Fine Grained Feature)
- 10、YOLO-V2-Multi-Scale多尺度融合
- 总结
前言
YOLOv2(You Only Look Once, Version 2)是目标检测领域的重要模型,由Joseph Redmon等人在2016年提出。它在YOLOv1的基础上进行了多项改进,显著提升了检测精度和速度,同时保持了实时性。
YOLO框架v2
1、YOLOv1与v2的比较
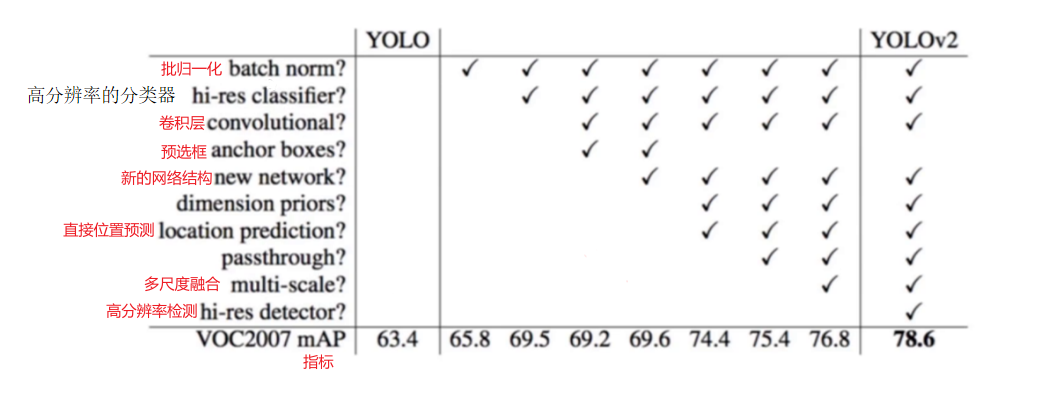
2、BatchNorm
V2版本舍弃Dropout (抛弃神经元比例),卷积后全部加入BatchNormalization ,网络的每一层的输入都做了归一化,经过卷积后输出特征图,特征图输出到下一层卷积,收敛相对更容易,经过Batch Normalization处理后的网络会提升2%的mAP,从现在的角度来看,Batch Normalization已经成网络必备处理。
3、分辨率变化
V1训练时用的是224224,测试时使用448448,可能导致模型水士不服;
V2训练时额外又进行了10次448*448 的微调使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
4、v2网络结构
YOLOv2的主干网络为Darknet-19,包含19个卷积层和5个最大池化层,结构轻量高效:
-
使用3×3卷积核,参数量少。
-
引入Batch Normalization(加速收敛,防止过拟合)。
-
分类任务使用全局平均池化替代全连接层。

没有FC层,输入的特征图片尺寸可以不像v1那样,自由的输入特征图片尺寸;
因为进行了5次降采样,
唯一的限制就是输入的特征图片尺寸要为2**5(32)的倍数。
5、聚类先验框
YOLO v1的预选框有2个,而YOLO v2则有5个预选框,预选框越多找到的目标就越精确,但是算力越多,faster-rcnn系列一共有9种预选框,这9种分为3类,每个类别大小不同,类别内的比例不同(每个类,1:1、2:1、1:2)。
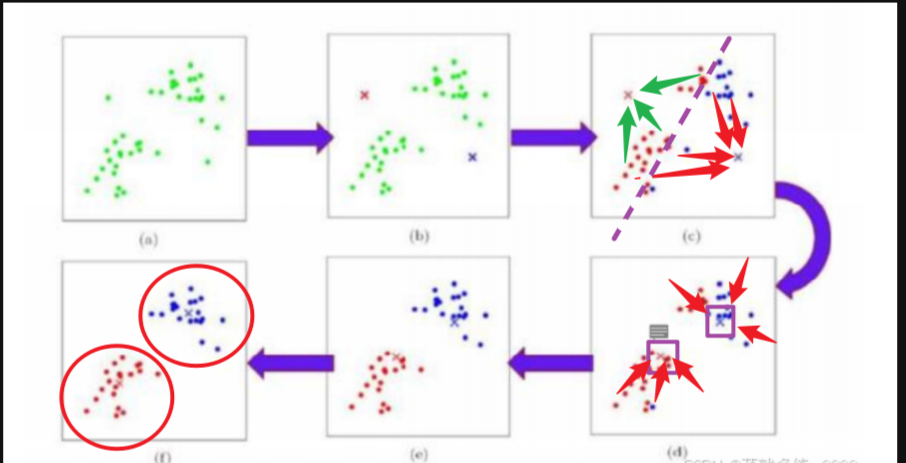
YOLO v2使用K-means聚类算法来提取先验框。K-means是一种无监督学习算法,用于将数据点分为K个不同的簇,以便找到数据的聚类结构。参考这篇博客:K-Means聚类算法:从原理到实践
YOLO v2中假如有100万张图片,需要对其进行训练,每个图片都有标记框,此时有起码100万个标记框,每个标记框都有其高宽的信息,那么将这个w宽和h高当做成一个坐标(w,h),即表示每个框的信息,然后使用k-means对其进行聚类,以此来区分
k-means聚类(如下所示)中的距离:d(box,centroids) = 1-IOU(box,centroids),之前用的是欧氏距离,而yolo v2使用1-交并集比值的大小来将其当做距离。
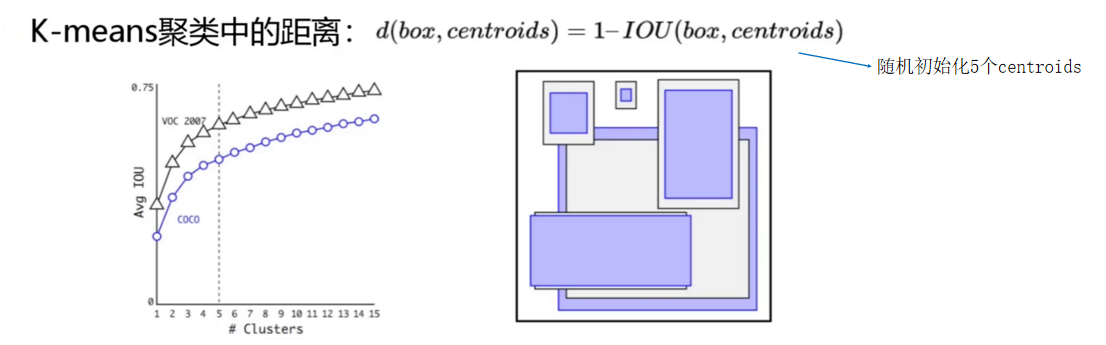
流程:在模型训练之前,提前把训练集的标签值提取出来,通过k-means聚类的方法,聚类出5个类别。结果当作是先验框,最后在进行模型训练。
6、YOLO v2 Anchor Box
通过引入聚类先验框,使得预测的box数量更多(1313 n),跟faster-rcnn系列不同的是,先验框并不是直接按照长宽固定比给定。

YOLOv1直接预测边界框坐标,容易导致定位不稳定。YOLOv2借鉴Faster R-CNN的Anchor Box机制,通过预定义的先验框(Anchors)预测边界框偏移量。
优势:
-
提升召回率(Recall)和边界框定位精度。
-
每个网格单元预测多个Anchor Box(默认5个),更好地处理重叠目标。
7、Directed Location Prediction直接位置预测
Directed Location Prediction是一种方法,其目的是进行位置微调,预测偏移量。它用于限制偏移量,以防止在训练时出现发散。这种方法预测的是相对位置,即相对于网格的偏移量。
或者说,是一种改进的目标边界框位置预测方法,其核心在于它直接在卷积层的特征图上预测边界框的位置,而不是像一些传统方法那样通过全连接层进行预测。

在v2中并没有直接使用偏移量,而是选择相对grid cell的偏移量。
1)计算:
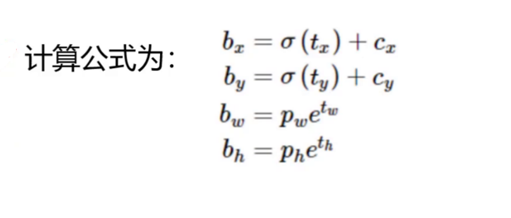
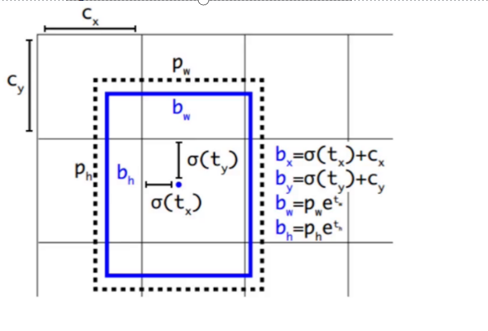
预测的偏移量包括tx、ty、tw、th(第一次为先验框及初始化的中心坐标在模型中输出的结果与真实框损失值得到的偏移量值)。调整后的预测值bx、by、bw、bh是通过计算得到的。
2)例如

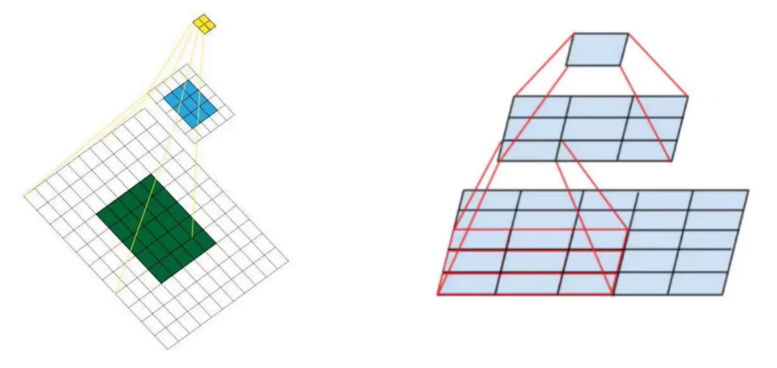
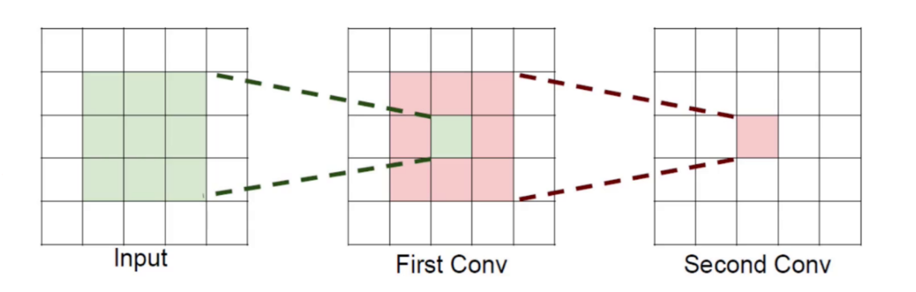
8、感受野
感受野概述来说就是特征图上的点能看到原始图像的多大区域


9、YOLO v2 Fine Grained Feature
当最后一层感受野过大时,其中的小目标可能会丢失,这时要融合前面的特征。
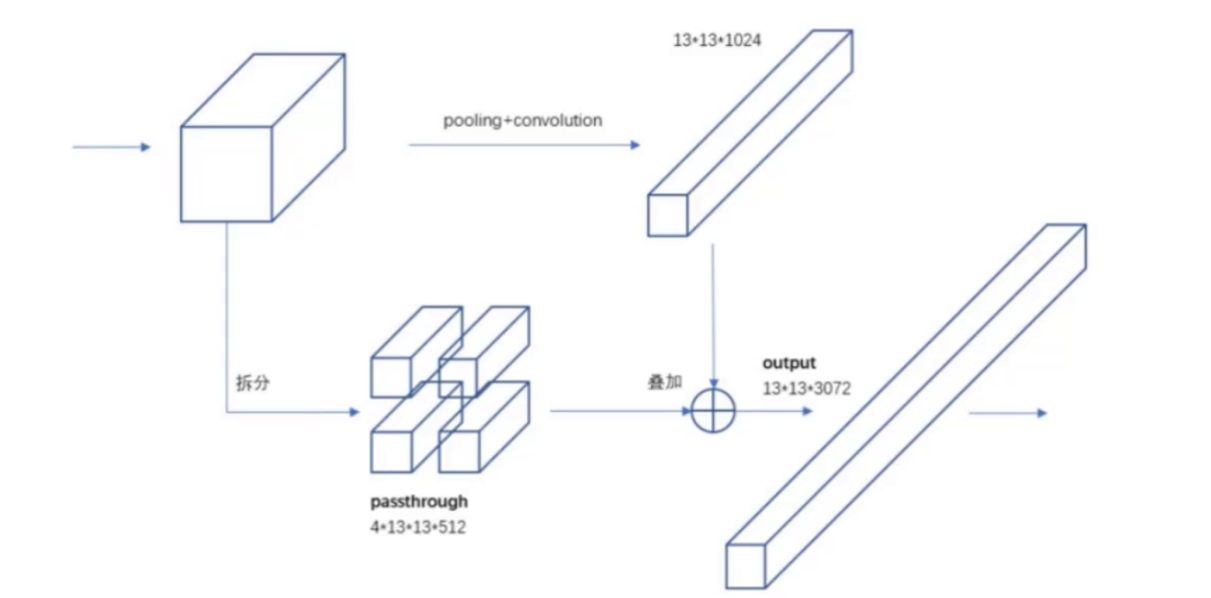
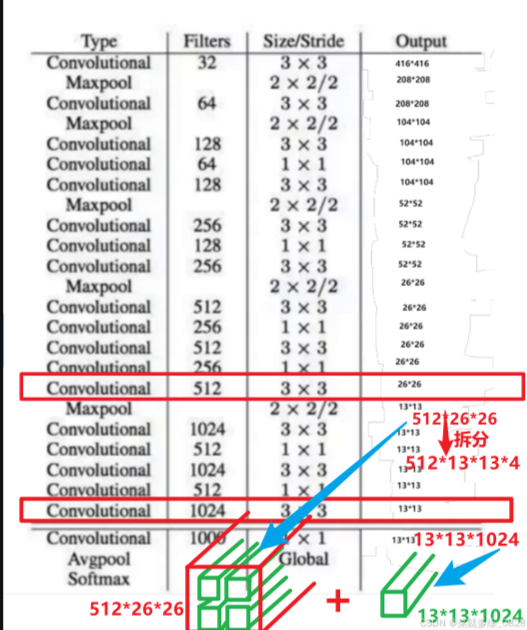
在网络结构中特征图为512 * 26 * 26的时候,将其额外复制出来,然后将其分割成四份,改编成4 * 13 * 13 * 512的格式,然后再将其拼接到最后产生的1024 * 13 * 13的特征图后,以此来保留部分的小目标信息。
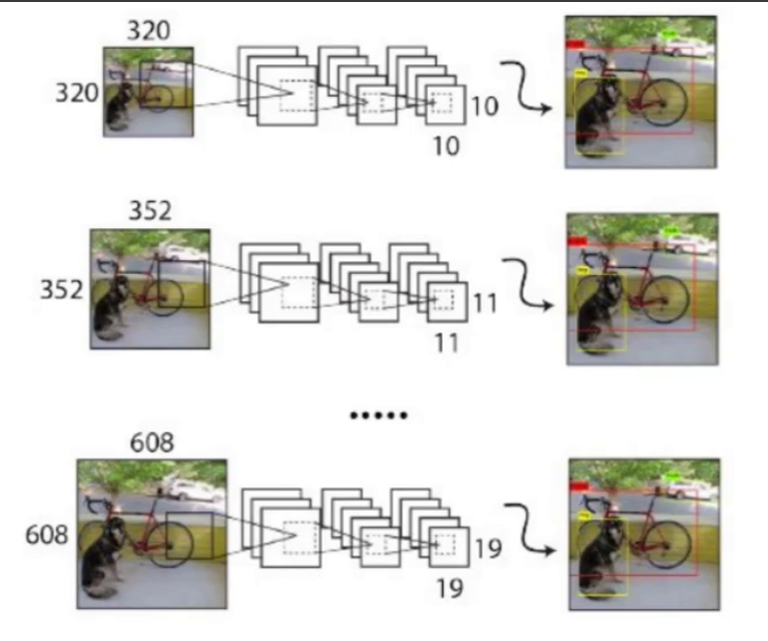
10、YOLO-V2-Multi-Scale多尺度融合
整个网络结构不包含全连接层,因此输入图片的大小可以任意
最小的图像尺寸为320 * 320
最大的图像尺寸为608 * 608
再次注意 :输入的图片应该需要被32整除。
总结
YOLOv2通过引入Anchor Box、多尺度训练、Darknet-19等关键技术,在速度和精度之间取得了更好的平衡。尽管后续版本(如YOLOv3、YOLOv4)进一步优化,YOLOv2仍是理解YOLO系列演进的重要里程碑。