背景意义
研究背景与意义
随着智能设备的普及和自动化技术的快速发展,表盘指针的检测与识别在工业自动化、智能家居和车载系统等领域中变得愈发重要。表盘指针作为信息传递的一种重要方式,其准确检测直接关系到设备的性能和用户体验。传统的指针检测方法多依赖于图像处理技术,然而这些方法在复杂环境下的鲁棒性和准确性往往不足。因此,基于深度学习的目标检测技术,尤其是YOLO(You Only Look Once)系列模型,因其高效性和实时性,成为了研究的热点。
本研究旨在基于改进的YOLOv11模型,构建一个高效的表盘指针检测系统。该系统将利用一个包含3700张图像的数据集,专注于单一类别"pointer"的实例分割任务。通过对数据集的精细标注和多样化增强处理,模型将能够在不同的光照、角度和背景条件下,准确识别和定位表盘指针。这一研究不仅有助于提升指针检测的准确性和实时性,还能为相关领域的应用提供理论支持和技术基础。
在数据集的构建过程中,采用了多种数据增强技术,如随机旋转、亮度和曝光调整等,以增加模型的泛化能力。这些预处理和增强措施将有效提升模型在实际应用中的表现,使其能够适应多变的环境和条件。此外,改进YOLOv11模型的引入,将为指针检测任务提供更为先进的技术手段,推动计算机视觉领域的进一步发展。
综上所述,基于改进YOLOv11的表盘指针检测系统的研究,不仅具有重要的理论意义,还具备广泛的应用前景,能够为智能设备的自动化和智能化提供强有力的技术支持。
图片效果
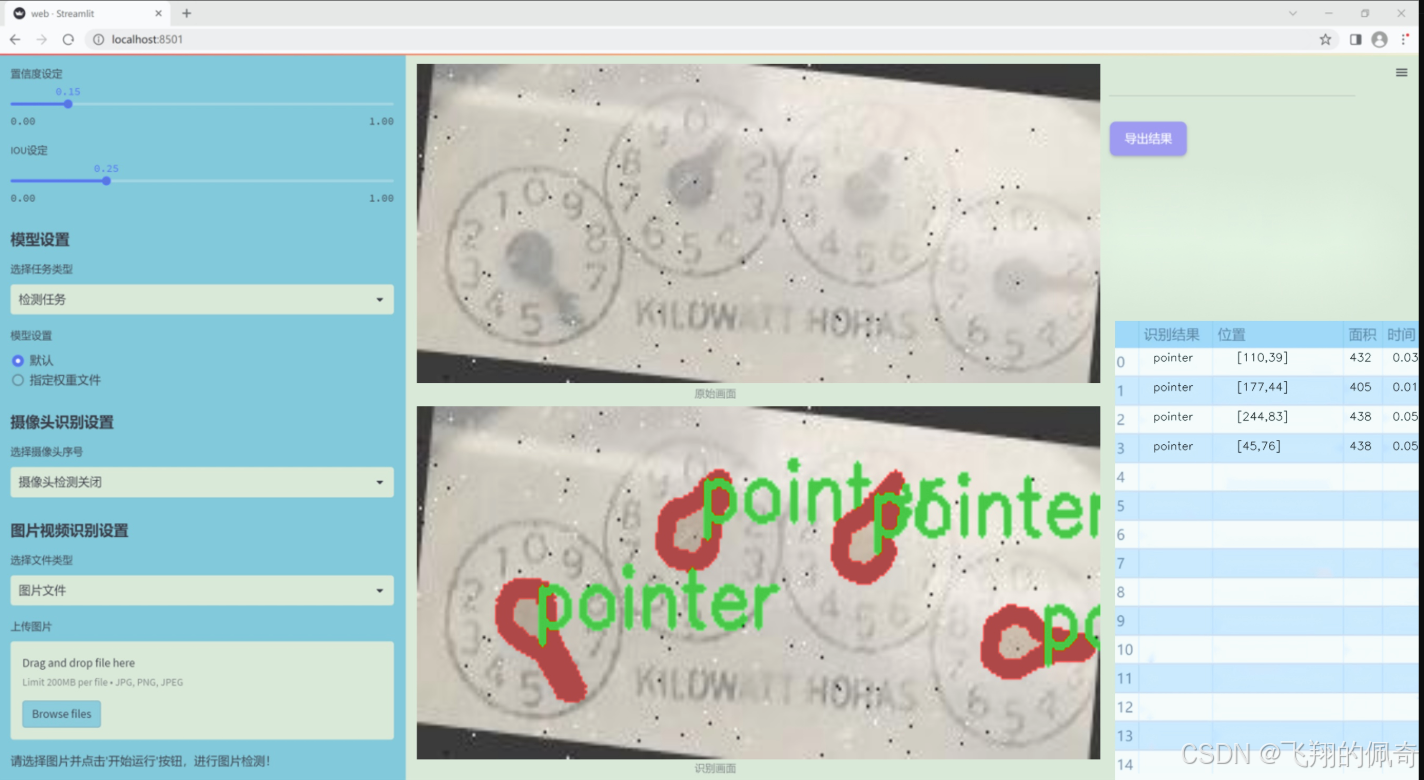
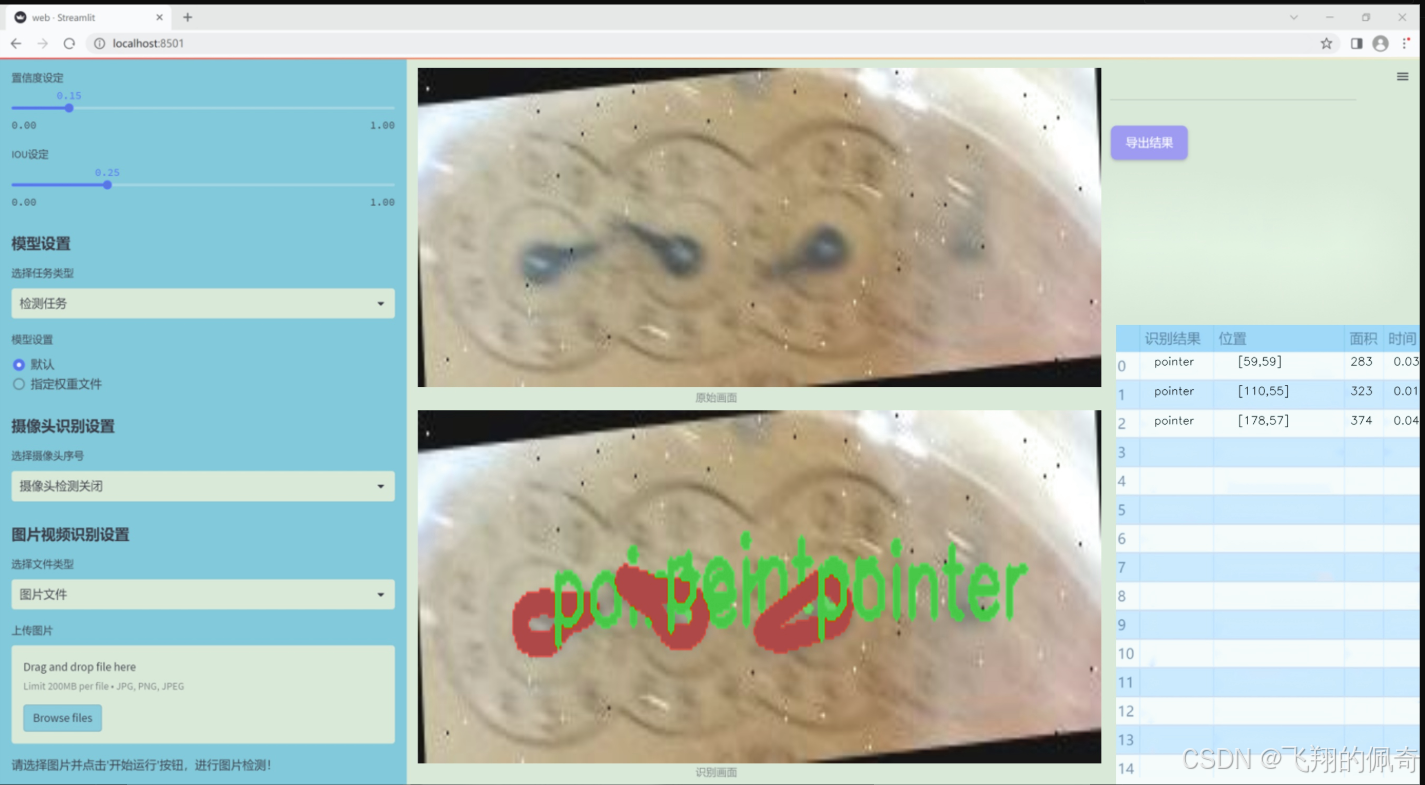
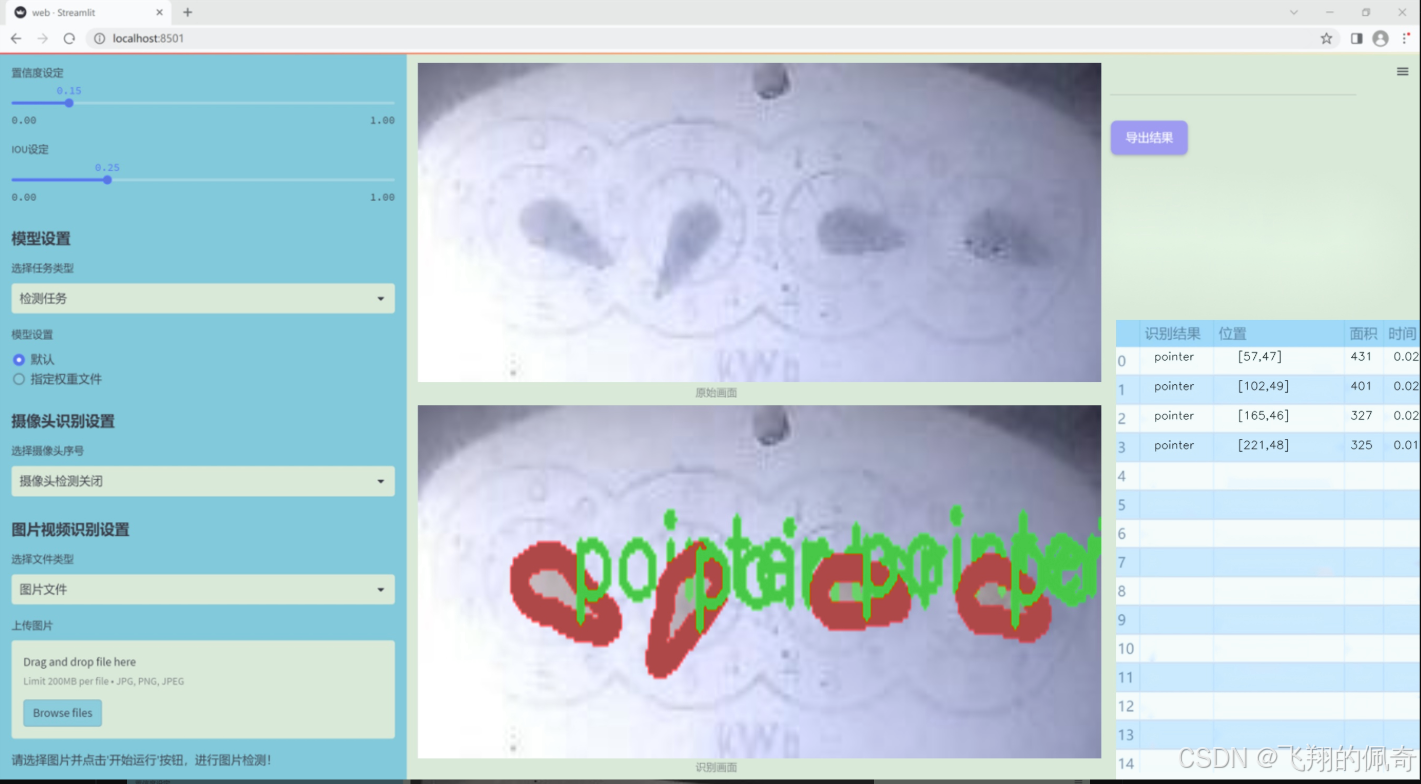
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的表盘指针检测系统,所使用的数据集"det_ponteiros_seg"专注于表盘指针的检测与识别。该数据集的设计考虑到了表盘指针在不同环境和条件下的多样性,以确保训练出的模型具备良好的泛化能力和准确性。数据集中包含的类别数量为1,主要针对"pointer"这一类别进行深入研究与分析。通过集中关注这一特定类别,数据集能够为模型提供更为精确的特征学习,从而提升指针检测的性能。
在数据集的构建过程中,收集了大量包含表盘指针的图像,这些图像涵盖了多种表盘类型、不同的指针样式以及多样的背景环境。这种多样性不仅增强了数据集的代表性,还为模型提供了丰富的训练样本,帮助其在实际应用中更好地应对各种复杂场景。此外,数据集中的图像经过精心标注,确保每个指针的位置和形状都得到了准确的识别。这种高质量的标注为模型的训练提供了坚实的基础,使其能够有效学习到指针的特征。
在数据预处理阶段,数据集还进行了图像增强处理,以模拟不同的光照条件、视角变化和噪声干扰,从而进一步提高模型的鲁棒性。通过这些措施,数据集不仅为YOLOv11的训练提供了丰富的样本,也为后续的模型评估和优化奠定了良好的基础。总之,数据集"det_ponteiros_seg"在表盘指针检测任务中发挥着至关重要的作用,为实现高效、准确的指针检测系统提供了强有力的支持。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttentionModule(nn.Module):
def init (self):
super(SpatialAttentionModule, self).init ()
定义一个卷积层,用于生成空间注意力图
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid() # 使用Sigmoid激活函数将输出限制在0到1之间
def forward(self, x):
# 计算输入特征图的平均值和最大值
avgout = torch.mean(x, dim=1, keepdim=True) # 沿通道维度计算平均值
maxout, _ = torch.max(x, dim=1, keepdim=True) # 沿通道维度计算最大值
out = torch.cat([avgout, maxout], dim=1) # 将平均值和最大值拼接在一起
out = self.sigmoid(self.conv2d(out)) # 通过卷积层和Sigmoid激活函数生成注意力图
return out * x # 将注意力图与输入特征图相乘,得到加权后的特征图class LocalGlobalAttention(nn.Module):
def init (self, output_dim, patch_size):
super().init ()
self.output_dim = output_dim
self.patch_size = patch_size
定义两个全连接层和一个卷积层
self.mlp1 = nn.Linear(patch_size * patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
定义可学习的参数
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1) # 调整输入的维度顺序
B, H, W, C = x.shape # 获取批量大小、高度、宽度和通道数
P = self.patch_size
# 提取局部特征
local_patches = x.unfold(1, P, P).unfold(2, P, P) # 提取局部patch
local_patches = local_patches.reshape(B, -1, P * P, C) # 重塑形状
local_patches = local_patches.mean(dim=-1) # 沿最后一个维度计算平均值
# 通过全连接层和层归一化处理局部特征
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # 计算局部注意力
local_out = local_patches * local_attention # 加权局部特征
# 计算与prompt的余弦相似度
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # B, N, 1
mask = cos_sim.clamp(0, 1) # 限制相似度在0到1之间
local_out = local_out * mask # 应用mask
local_out = local_out @ self.top_down_transform # 进行变换
# 恢复形状并进行上采样
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2) # 调整维度顺序
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False) # 上采样
output = self.conv(local_out) # 通过卷积层得到最终输出
return outputclass PPA(nn.Module):
def init (self, in_features, filters) -> None:
super().init ()
定义多个卷积层和注意力模块
self.skip = nn.Conv2d(in_features, filters, kernel_size=1, stride=1) # 跳跃连接
self.c1 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c2 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c3 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.sa = SpatialAttentionModule() # 空间注意力模块
self.lga2 = LocalGlobalAttention(filters, 2) # 局部全局注意力模块
self.lga4 = LocalGlobalAttention(filters, 4) # 局部全局注意力模块
self.bn1 = nn.BatchNorm2d(filters) # 批归一化
self.silu = nn.SiLU() # SiLU激活函数
def forward(self, x):
x_skip = self.skip(x) # 跳跃连接
x_lga2 = self.lga2(x_skip) # 局部全局注意力
x_lga4 = self.lga4(x_skip) # 局部全局注意力
x1 = self.c1(x) # 第一层卷积
x2 = self.c2(x1) # 第二层卷积
x3 = self.c3(x2) # 第三层卷积
# 将所有特征图相加
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.sa(x) # 应用空间注意力
x = self.bn1(x) # 批归一化
x = self.silu(x) # 激活
return x # 返回最终输出以上代码主要实现了空间注意力模块、局部全局注意力模块和PPA模块。每个模块都有其特定的功能,通过组合使用这些模块,可以有效地提取和增强特征。
这个程序文件 hcfnet.py 实现了一种深度学习模型的组件,主要用于图像处理任务。文件中定义了多个类,每个类实现了特定的功能模块。
首先,SpatialAttentionModule 类实现了空间注意力机制。它通过计算输入特征图的平均值和最大值来生成注意力图,然后通过卷积层和 Sigmoid 激活函数对这些特征进行处理,最终将生成的注意力图与输入特征图相乘,以突出重要的空间信息。
接下来,LocalGlobalAttention 类结合了局部和全局注意力机制。它首先将输入特征图划分为多个小块,并对每个小块进行处理,提取局部特征。然后,利用多层感知机(MLP)对这些特征进行变换,并通过 Softmax 函数计算注意力权重。最后,将局部特征与全局特征结合,恢复特征图的形状,并通过卷积层进行进一步处理。
ECA 类实现了有效的通道注意力机制。它通过自适应平均池化将输入特征图压缩为一维向量,然后使用一维卷积来生成通道注意力权重,最后将这些权重应用于输入特征图,以增强重要通道的特征。
PPA 类是一个复合模块,结合了前面提到的空间注意力、局部全局注意力和通道注意力。它通过多个卷积层提取特征,并将不同的特征融合在一起,最终输出经过注意力机制处理的特征图。
Bag 类实现了一种简单的加权机制,用于结合不同来源的特征。它通过对输入特征进行加权求和,来生成最终的特征表示。
最后,DASI 类是一个更复杂的模块,结合了不同层次的特征。它通过多个卷积层和跳跃连接来处理高、中、低层特征,并利用 Bag 类来融合这些特征。最终输出经过归一化和激活函数处理的特征图。
整体来看,这个文件实现了一个多层次、多注意力机制的深度学习模型组件,旨在提高图像处理任务中的特征提取能力和模型性能。
10.4 fadc.py
以下是提取出的核心部分代码,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init (self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init ()
计算注意力通道数
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 温度参数,用于控制注意力的平滑程度
# 定义平均池化层
self.avgpool = nn.AdaptiveAvgPool2d(1)
# 定义全连接层
self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)
self.bn = nn.BatchNorm2d(attention_channel) # 批归一化
self.relu = nn.ReLU(inplace=True) # ReLU激活函数
# 定义通道注意力
self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)
self.func_channel = self.get_channel_attention
# 定义滤波器注意力
if in_planes == groups and in_planes == out_planes: # 深度可分离卷积
self.func_filter = self.skip
else:
self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)
self.func_filter = self.get_filter_attention
# 定义空间注意力
if kernel_size == 1: # 点卷积
self.func_spatial = self.skip
else:
self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)
self.func_spatial = self.get_spatial_attention
# 定义核注意力
if kernel_num == 1:
self.func_kernel = self.skip
else:
self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)
self.func_kernel = self.get_kernel_attention
self._initialize_weights() # 初始化权重
def _initialize_weights(self):
# 初始化卷积层和批归一化层的权重
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def get_channel_attention(self, x):
# 计算通道注意力
channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)
return channel_attention
def get_filter_attention(self, x):
# 计算滤波器注意力
filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)
return filter_attention
def get_spatial_attention(self, x):
# 计算空间注意力
spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)
spatial_attention = torch.sigmoid(spatial_attention / self.temperature)
return spatial_attention
def get_kernel_attention(self, x):
# 计算核注意力
kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)
kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)
return kernel_attention
def forward(self, x):
# 前向传播
x = self.avgpool(x) # 平均池化
x = self.fc(x) # 全连接层
x = self.bn(x) # 批归一化
x = self.relu(x) # ReLU激活
return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x) # 返回各类注意力示例使用
omni_attention = OmniAttention(in_planes=64, out_planes=128, kernel_size=3)
output = omni_attention(input_tensor)
代码说明:
OmniAttention类:实现了一种全局注意力机制,能够根据输入的特征图生成通道、滤波器、空间和核的注意力。
初始化方法:定义了各个注意力的计算方式,并初始化权重。
前向传播:通过平均池化、全连接层、批归一化和激活函数处理输入,并计算不同类型的注意力。
该代码片段展示了如何通过注意力机制来增强特征图的表达能力,适用于图像处理和计算机视觉任务。
这个程序文件 fadc.py 是一个使用 PyTorch 实现的深度学习模块,主要包含了自适应膨胀卷积(Adaptive Dilated Convolution)和频率选择(Frequency Selection)等功能。以下是对文件中主要组件的详细说明。
首先,文件引入了必要的库,包括 PyTorch 和 NumPy,并尝试从 mmcv 库中导入一些特定的模块,如果导入失败,则使用默认的 nn.Module 作为替代。接下来,定义了一个名为 OmniAttention 的类,这个类实现了一种全局注意力机制。它的构造函数接受多个参数,包括输入和输出通道数、卷积核大小、组数、通道缩减比例等。该类的主要功能是通过自适应平均池化、全连接层和激活函数来计算通道注意力、过滤器注意力、空间注意力和卷积核注意力。
OmniAttention 类中还定义了一些辅助方法,如 _initialize_weights 用于初始化权重,update_temperature 用于更新温度参数,以及多个用于计算不同类型注意力的静态方法。forward 方法实现了前向传播过程,计算并返回不同的注意力值。
接下来,定义了一个名为 generate_laplacian_pyramid 的函数,该函数用于生成拉普拉斯金字塔。拉普拉斯金字塔是一种图像处理技术,用于提取图像的不同频率成分。该函数通过逐层下采样输入张量并计算高频成分来构建金字塔。
然后,定义了 FrequencySelection 类,该类实现了频率选择机制。构造函数接受多个参数,包括输入通道数、频率列表、低频注意力标志、特征选择类型等。该类的主要功能是根据输入特征生成频率选择的权重,并在前向传播中应用这些权重。根据不同的 lp_type,该类可以实现不同的频率选择策略,如平均池化、拉普拉斯金字塔或频域选择。
AdaptiveDilatedConv 类是一个自适应膨胀卷积的实现,继承自 ModulatedDeformConv2d。该类的构造函数接受多个参数,包括输入和输出通道数、卷积核大小、步幅、填充、膨胀因子等。它还支持频率选择和注意力机制的集成。该类的 forward 方法实现了自适应膨胀卷积的前向传播过程,结合了频率选择和注意力机制。
最后,AdaptiveDilatedDWConv 类是对 AdaptiveDilatedConv 的扩展,主要用于深度可分离卷积。它的构造函数和 forward 方法与 AdaptiveDilatedConv 类似,但增加了对正常卷积维度的支持。
整体来看,这个文件实现了一个复杂的卷积神经网络模块,结合了自适应卷积、注意力机制和频率选择等先进技术,适用于图像处理和计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻