当 PDF 文件中包含有价值的图片,如艺术画作、设计素材、报告图表等,提取图片可以将这些图像资源进行单独保存,方便后续在不同的项目中使用,避免每次都要从 PDF 中查找。本文将介绍如何使用C#通过代码从PDF文档中提取图片,包含以下两个示例:
- C# 提取指定 PDF 页面中的图片
- C# 提取PDF 文档中所有图片
提取PDF图片需要用到 **Spire.PDF for .NET**库。可以通过此链接下载产品包后手动添加引用,或者直接通过NuGet安装。
C# 提取指定 PDF 页面中的图片
PdfImageHelper 类可用于帮助用户管理 PDF 文档中的图像,要从某个指定的PDF页面中提取图片,参考以下步骤:
- 使用 PdfDocument 类的 LoadFromFile() 方法加载 PDF 文件。
- 通过 PdfDocument 类的 Pagesindex 属性获取指定页面。
- 创建PdfImageHelper 对象,然后使用其 GetImagesInfo() 方法获取页面中图像信息集合。
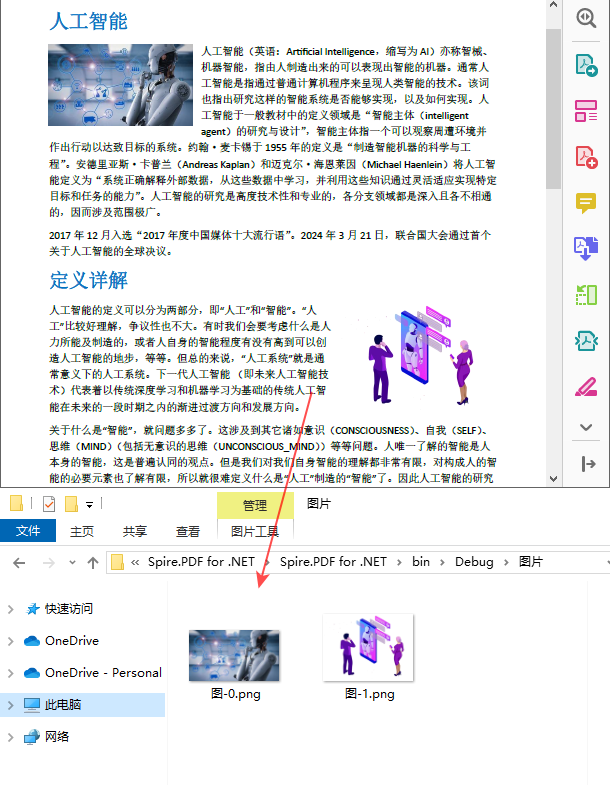
- 遍历图像信息集合,并使用 PdfImageInfo.Image.Save() 方法将每一张图片以PNG格式储存到指定文件路径。
C# 代码:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Drawing;
namespace ExtractImagesFromSpecificPage
{
class Program
{
static void Main(string[] args)
{
// 加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("AI.pdf");
// 获取第一页
PdfPageBase page = pdf.Pages[0];
// 创建PdfImageHelper对象
PdfImageHelper imageHelper = new PdfImageHelper();
// 获取页面上的图片信息
PdfImageInfo[] imageInfos = imageHelper.GetImagesInfo(page);
// 遍历图片信息
for (int i = 0; i < imageInfos.Length; i++)
{
// 获取某个指定图片信息
PdfImageInfo imageInfo = imageInfos[i];
// 获取指定图片
Image image = imageInfo.Image;
// 将图片保存为png格式
image.Save("图片\\图-" + i + ".png");
}
pdf.Dispose();
}
}
}
C# 提取PDF 文档中所有图片
要获取整个PDF文档中的图片,就需要遍历每一页然后再提取,具体参考以下步骤:
- 使用 PdfDocument 类的 LoadFromFile() 方法加载 PDF 文件。
- 创建 PdfImageHelper 对象。
- 遍历文档中的每一个页面。
- 通过 PdfDocument 类的 Pagesindex 属性获取指定页面。
- 使用 PdfImageHelper.GetImagesInfo() 方法获取页面中图像信息集合。
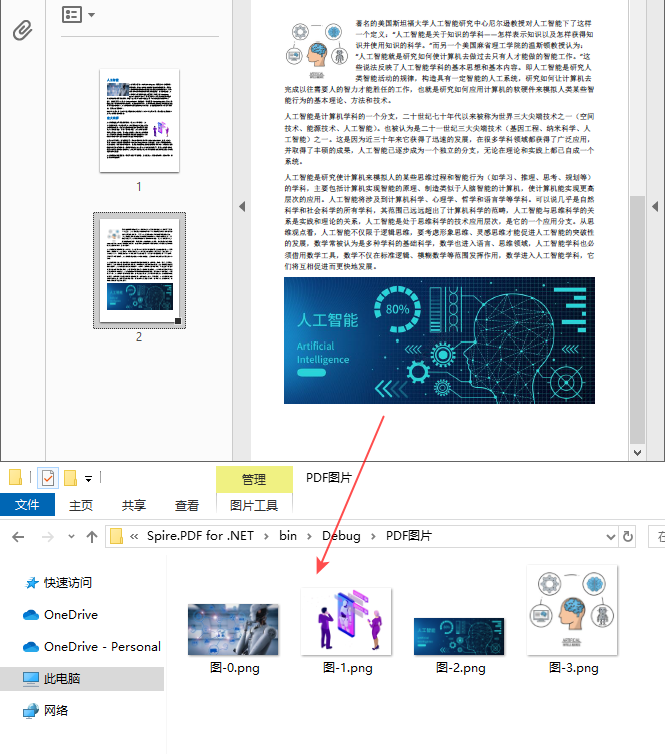
- 遍历图像信息集合,并使用 PdfImageInfo.Image.Save() 方法将每一张图片以PNG格式储存到指定文件路径。
C# 代码:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Drawing;
namespace ExtractAllImages
{
class Program
{
static void Main(string[] args)
{
// 加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("AI.pdf");
// 创建PdfImageHelper对象
PdfImageHelper imageHelper = new PdfImageHelper();
int m = 0;
// 遍历PDF页面
for (int i = 0; i < pdf.Pages.Count; i++)
{
// 获取指定页面
PdfPageBase page = pdf.Pages[i];
// 获取页面上的图片信息
PdfImageInfo[] imageInfos = imageHelper.GetImagesInfo(page);
// 遍历图片信息
for (int j = 0; j < imageInfos.Length; j++)
{
// 获取某个指定图片信息
PdfImageInfo imageInfo = imageInfos[j];
// 获取指定图片
Image image = imageInfo.Image;
// 将图片保存为png格式
image.Save("PDF图片\\图-" + m + ".png");
m++;
}
}
pdf.Dispose();
}
}
}
- 通过C# 操作PDF中图片以及其他元素的更多教程可参考:
https://www.e-iceblue.cn/spirepdfnet/spire-pdf-for-net-program-guide-content.html
- 移除水印可以点击申请试用授权: