在现代 Web 开发中,语音识别技术的应用越来越广泛。它为用户提供了更加便捷、自然的交互方式,例如语音输入、语音指令等。本文将介绍如何使用 React 实现一个简单的语音识别并转换的功能。
功能概述
我们要实现的功能是一个语音识别测试页面,用户可以选择不同的语言,录制音频,然后将录制的音频转换为文本。整个过程使用了 React 作为前端框架,RecordRTC 库用于录制音频,以及一个自定义的 CallAsr 函数用于调用语音识别服务。
注意⚠️:CallAsr 函数在博客已有相应的描述:前端 AI 开发实战:基于自定义工具类的大语言模型与语音识别调用指南_音频理解类大模型调用-CSDN博客
实现步骤
1.导入必要的模块
首先,我们需要导入 React 的钩子 useState 和 useRef,以及 RecordRTC 库和自定义的 CallAsr 函数和 AsrLanguage 枚举。
import { useState, useRef } from "react";
import { CallAsr, AsrLanguage } from "../../util/AIUtil";
import RecordRTC from "recordrtc";useState和useRef是 React 的钩子,useState用于管理组件的状态,useRef用于引用 DOM 元素或在组件重新渲染时保存值。CallAsr和AsrLanguage从../../util/AIUtil导入(AI工具类),CallAsr是用于调用语音识别服务的函数,AsrLanguage是一个枚举类型,用于表示支持的语言。RecordRTC是一个用于录制音频和视频的库。
2.定义接口
为了更好地处理语音识别服务的返回数据,我们定义了一个 AsrResponse 接口。
interface AsrResponse {
code: number;
msg: string;
data?: {
text_arr: string[];
detail_arr?: Array<{
text: string;
time_from: number;
time_end: number;
}>;
};
}3.定义组件和状态管理
我们创建了一个名为 ASRTest 的函数式组件,并使用 useState 钩子来管理组件的状态,例如是否正在录制、音频数据、识别结果等。
const ASRTest = () => {
const [recording, setRecording] = useState<boolean>(false);
const [audioBlob, setAudioBlob] = useState<Blob | null>(null);
const [transcription, setTranscription] = useState<string>("");
const [loading, setLoading] = useState<boolean>(false);
const [selectedLanguage, setSelectedLanguage] = useState<AsrLanguage>(
AsrLanguage.ZH_CN
);
const [error, setError] = useState<string | null>(null);
const recorderRef = useRef<RecordRTC | null>(null);
// ...
};recording:表示是否正在录制音频。audioBlob:存储录制的音频数据。transcription:存储语音识别的结果。loading:表示是否正在进行语音识别。selectedLanguage:表示用户选择的语言。error:存储可能出现的错误信息。recorderRef:用于引用RecordRTC实例。
4.处理语言选择
用户可以通过下拉框选择不同的语言,我们使用 handleLanguageChange 函数来处理语言选择事件。
const handleLanguageChange = (e: React.ChangeEvent<HTMLSelectElement>) => {
setSelectedLanguage(e.target.value as AsrLanguage);
};5. 录制音频
用户可以点击 "开始录制" 按钮开始录制音频,点击 "停止录制" 按钮停止录制。我们使用 navigator.mediaDevices.getUserMedia 方法请求用户的麦克风权限,并使用 RecordRTC 库进行音频录制。
const startRecording = async () => {
try {
const stream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 16000,
echoCancellation: false,
noiseSuppression: false,
autoGainControl: false,
},
});
const recorder = new RecordRTC(stream, {
type: "audio",
mimeType: "audio/wav",
recorderType: RecordRTC.StereoAudioRecorder,
numberOfAudioChannels: 1,
desiredSampRate: 16000,
disableLogs: true,
// @ts-ignore
sampleBits: 16,
bufferSize: 16384,
});
recorder.startRecording();
recorderRef.current = recorder;
setRecording(true);
} catch (error) {
console.error("获取麦克风权限失败:", error);
setError("无法访问麦克风,请确保您已授予麦克风权限。");
}
};
const stopRecording = () => {
if (recorderRef.current && recording) {
recorderRef.current.stopRecording(() => {
const blob = recorderRef.current!.getBlob();
setAudioBlob(blob);
// 停止并释放音频流
const mediaStream =
recorderRef.current!.getInternalRecorder().mediaStream;
if (mediaStream) {
mediaStream.getTracks().forEach((track) => track.stop());
}
setRecording(false);
});
}
};6. 语音识别
用户可以点击 "转换" 按钮将录制的音频转换为文本。我们使用 CallAsr 函数调用语音识别服务,并根据返回结果更新识别结果或错误信息。
const handleTranscribe = async () => {
if (!audioBlob) {
setError("请先录制音频");
return;
}
setLoading(true);
setError(null);
try {
// 创建一个带有适当后缀名的文件对象
const audioFile = new File([audioBlob], "recording.wav", {
type: "audio/wav",
});
const response = await CallAsr(audioFile, selectedLanguage);
const result: AsrResponse = await response.json();
if (result.code === 0 && result.data) {
setTranscription(result.data.text_arr.join(" "));
} else {
setError(`识别失败: ${result.msg || "未知错误"}`);
}
} catch (error) {
console.error("语音识别错误:", error);
setError(
`识别过程中发生错误: ${
error instanceof Error ? error.message : String(error)
}`
);
} finally {
setLoading(false);
}
};7. 渲染组件
最后,我们将所有的功能组合在一起,渲染出一个包含语言选择、录制按钮、音频预览、错误信息和识别结果的 UI。
return (
<div className="container mx-auto p-4 max-w-2xl">
<h1 className="text-2xl font-bold mb-6 text-center">ASR 语音识别测试</h1>
<div className="mb-4">
<label
htmlFor="language-select"
className="block mb-2 text-sm font-medium"
>
选择语言:
</label>
<select
id="language-select"
value={selectedLanguage}
onChange={handleLanguageChange}
className="bg-white border border-gray-300 text-gray-900 text-sm rounded-lg focus:ring-blue-500 focus:border-blue-500 block w-full p-2.5"
>
<option value={AsrLanguage.ZH_CN}>简体中文</option>
<option value={AsrLanguage.YUE_CN}>粤语</option>
<option value={AsrLanguage.EN_US}>美式英语</option>
<option value={AsrLanguage.EN_UK}>英式英语</option>
<option value={AsrLanguage.FR}>法语</option>
<option value={AsrLanguage.JA}>日语</option>
<option value={AsrLanguage.ES}>西班牙语</option>
<option value={AsrLanguage.DE}>德语</option>
</select>
</div>
<div className="flex flex-col items-center gap-4 mb-6">
<div className="flex gap-4">
<button
onClick={recording ? stopRecording : startRecording}
className={`px-6 py-2 rounded focus:outline-none focus:ring-2 ${
recording
? "bg-red-500 hover:bg-red-600 text-white focus:ring-red-500"
: "bg-blue-500 hover:bg-blue-600 text-white focus:ring-blue-500"
}`}
>
{recording ? "停止录制" : "开始录制"}
</button>
<button
onClick={handleTranscribe}
disabled={!audioBlob || loading}
className={`px-6 py-2 rounded focus:outline-none focus:ring-2 focus:ring-green-500 ${
!audioBlob || loading
? "bg-gray-300 text-gray-500 cursor-not-allowed"
: "bg-green-500 hover:bg-green-600 text-white"
}`}
>
{loading ? "转换中..." : "转换"}
</button>
</div>
{audioBlob && (
<div className="w-full mt-4">
<p className="text-sm text-gray-600 mb-2">录音预览:</p>
<audio controls className="w-full">
<source src={URL.createObjectURL(audioBlob)} type="audio/wav" />
您的浏览器不支持音频标签。
</audio>
</div>
)}
</div>
{loading && (
<div className="text-center py-4">
<div className="loader">转换中...</div>
</div>
)}
{error && (
<div className="mt-4 p-4 bg-red-100 text-red-700 rounded-lg">
{error}
</div>
)}
{transcription && (
<div className="mt-6 border-t pt-4">
<h2 className="font-semibold text-lg mb-2">识别结果:</h2>
<div className="bg-gray-100 p-4 rounded whitespace-pre-wrap">
{transcription}
</div>
</div>
)}
</div>
);整体实现效果
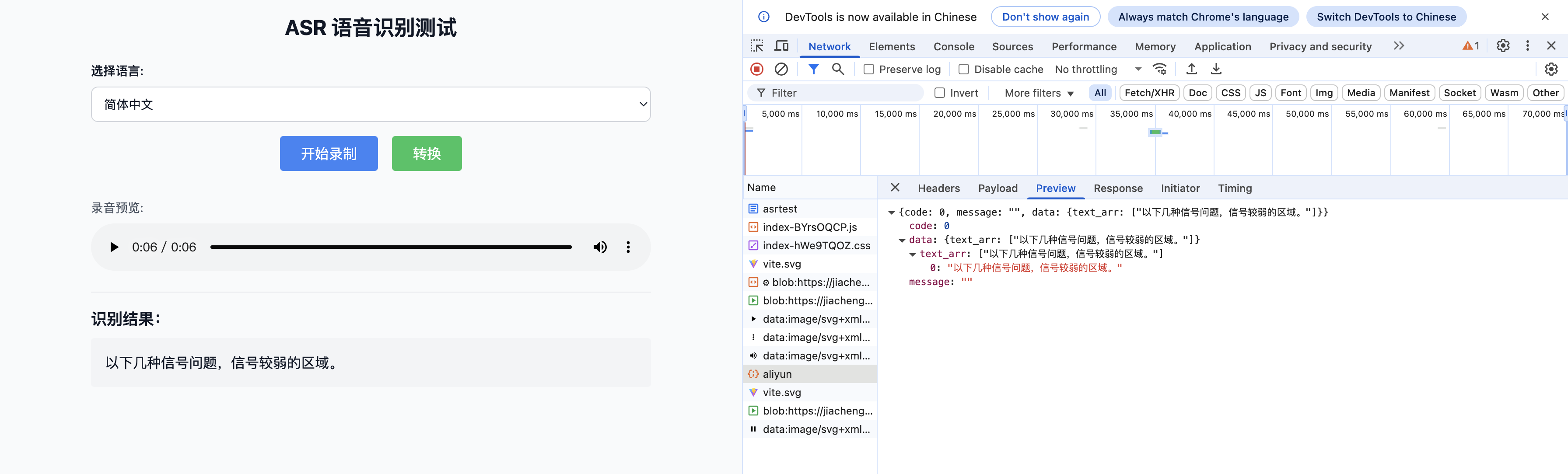
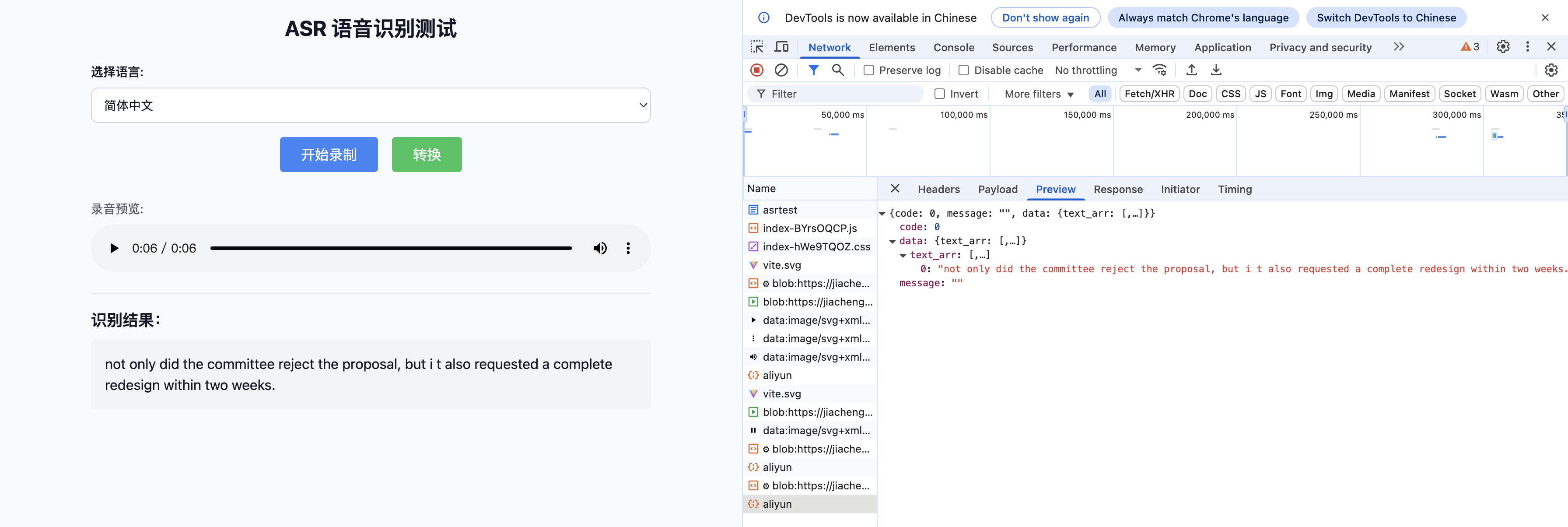
总结
通过以上步骤,我们成功实现了一个简单的语音识别并转换的功能。这个功能不仅可以帮助用户更方便地输入文本,还可以为 Web 应用增加更多的交互性。在实际应用中,我们可以根据需要对代码进行扩展,例如添加更多的语言支持、优化音频录制的质量等。