文章目录
前言
本文介绍一篇来自腾讯的开放词汇检测工作,发表自CVPR2024,论文链接,开源地址。
1、出发点
GroundingDINO在开放词汇检测任务中大放异彩,因此本文希望在轻量化的YOLOv8上也搞一个轻量化的开放词汇检测算法。最终效果吧,是模型又快而且精度基本持平。
2、方法
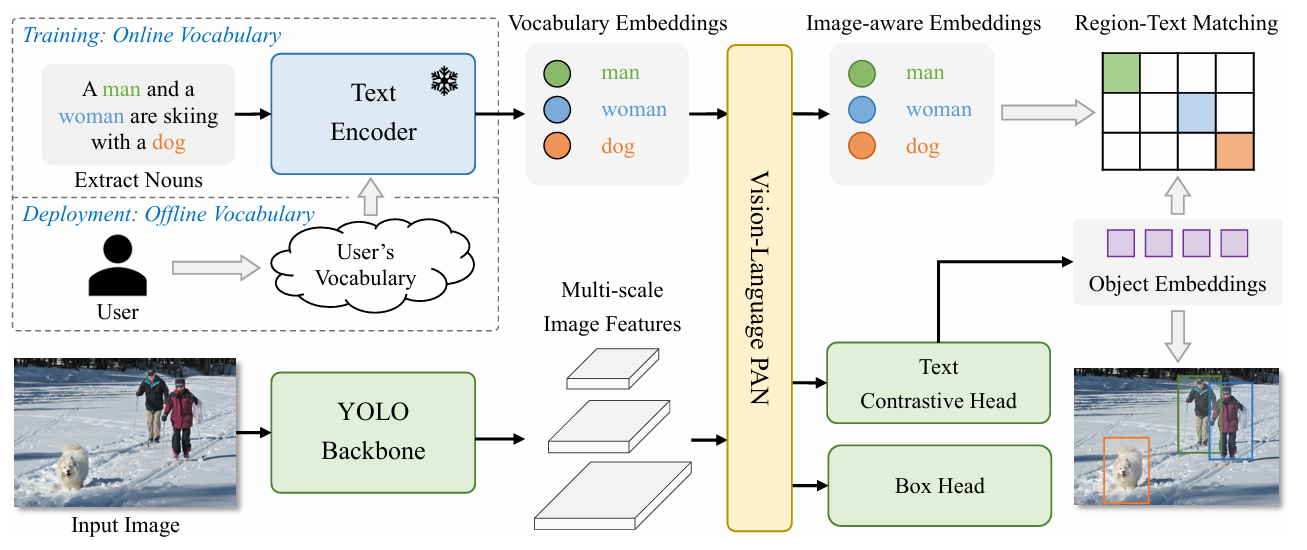
模型总体结构比较简单,主体检测网络采用的是YOLOv8,为了实现开放词汇检测任务,将分类头替换成"特征之间比对头",具体来说就是将检测网络每个anchor所对应的特征向量和文本嵌入向量做对比,计算相似性,进而实现开放词汇检测目的。
2.1.TextEncoder
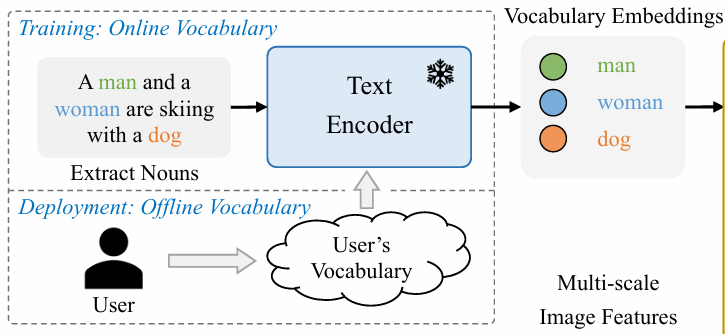
首先说下TextEncoder,在训练阶段,需要带着庞大的TextEncoder,而在部署阶段,则可以首先离线提取出文本的嵌入向量,这样在部署阶段就能省一个TextEncoder的计算量,使其更加轻量。
2.2.ReparmVLPAN
在得到TextEmbedding和图像特征向量C3-C5后,本文设计了一个VLPAN交互模块,简单来说:用图像特征向量更新文本,在用文本更新图像特征向量。当然,在部署阶段,TextEmbedding也是可以被作为权重写入到onnx里面的。
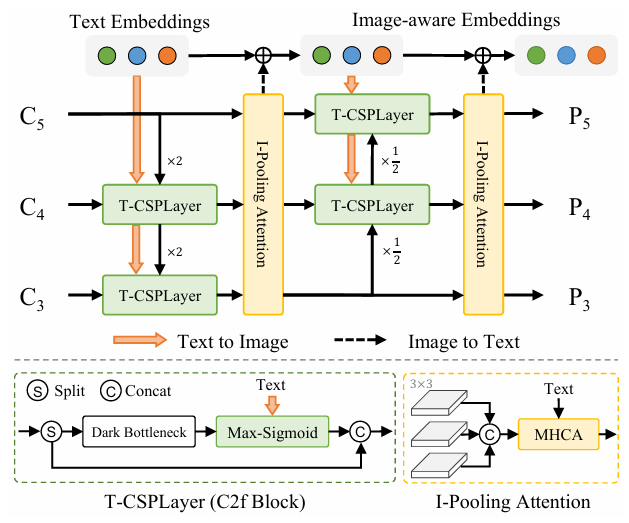
本人不想在此过多介绍这个模块,因为在实际应用中,建议还是用PAN比较好,因为这个模块收益不多,而且若检测的文本顺序不同,会导致检测结果不同。原因是Max-Sigmoid算子,读者有兴趣可自己check下。
2.3.输出头
样本分配策略是SIMOTA,跟v8一样。检测头就是yolov8,每个anchor预测4个上下左右距离,损失用的是DFL Loss;而分类头则是对比损失头,最终输出维度为: n u m _ a n c h o r ∗ 80 num\_anchor * 80 num_anchor∗80,做二元交叉熵损失,即对应正样本anchor为1,其余为0。
3、实验
3.1.数据集
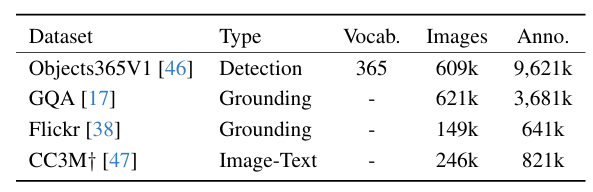
数据集采用O365+GoldG(GQA+Flickr)。
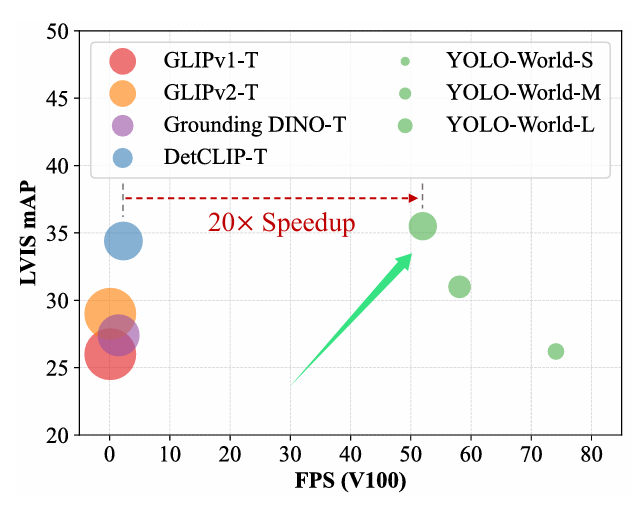
3.2.LVIS测试集
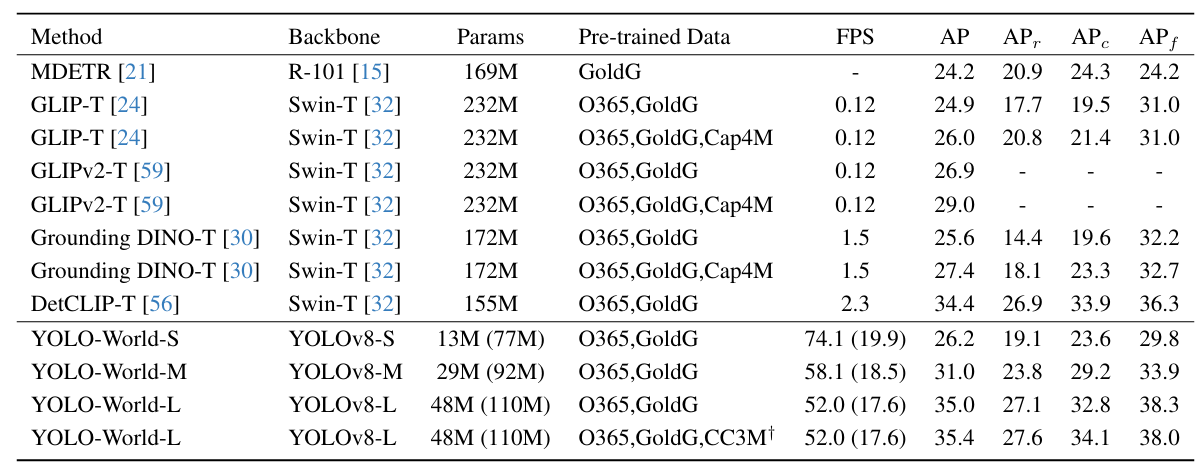
没啥可说的,FPS高,而且精度跟一系列开放词汇检测算法持平。但paper中指标跟git开源有出入,后续改进论文均以git为准。
总结
总之是一篇不错的轻量化OVD算法,算是挖了个新坑。每个模块其实都有值得探索改进的空间,包括后来的YOLOE , YOLOUniOW等,后续会逐个介绍,包括这类算法的一些不足,敬请期待。