基于深度学习的实时情绪检测系统:emotion-detection项目深度解析
-
- [1. 项目概述](#1. 项目概述)
- [2. 技术原理与模型架构](#2. 技术原理与模型架构)
-
- [2.1 核心算法](#2.1 核心算法)
-
- 1) 数据预处理流程 数据预处理流程)
- 2) 改进型MobileNetV2 改进型MobileNetV2)
- [2.2 系统架构](#2.2 系统架构)
- [3. 实战部署指南](#3. 实战部署指南)
-
- [3.1 环境配置](#3.1 环境配置)
- [3.2 数据集准备](#3.2 数据集准备)
- [3.3 模型训练](#3.3 模型训练)
- [3.4 实时推理](#3.4 实时推理)
- [4. 常见问题与解决方案](#4. 常见问题与解决方案)
-
- [4.1 人脸检测失败](#4.1 人脸检测失败)
- [4.2 模型过拟合](#4.2 模型过拟合)
- [4.3 显存不足](#4.3 显存不足)
- [5. 关键技术论文支撑](#5. 关键技术论文支撑)
-
- [5.1 基础理论](#5.1 基础理论)
- [5.2 前沿进展](#5.2 前沿进展)
- [6. 项目优化方向](#6. 项目优化方向)
-
- [6.1 模型压缩](#6.1 模型压缩)
- [6.2 多模态融合](#6.2 多模态融合)
- [6.3 伦理安全](#6.3 伦理安全)
- 结语
1. 项目概述
emotion-detection是一个基于深度学习的面部情绪识别开源项目,旨在通过摄像头实时捕捉人脸表情并分类为7种基本情绪(快乐、悲伤、愤怒、惊讶、厌恶、恐惧、中性)。项目采用卷积神经网络(CNN)作为核心架构,结合OpenCV实现实时视频流处理,其技术特点包括:
- 多模态输入:支持静态图像、视频流及实时摄像头输入
- 高效推理:优化后的MobileNetV2模型实现30FPS实时处理
- 跨平台兼容:提供Python脚本与Docker容器化部署方案
- 模型可解释性:集成Grad-CAM技术可视化注意力区域
项目在FER2013数据集上达到72.3%的测试准确率,优于传统HOG+SVM方法(约65%),但低于最新混合模型(如网页9提到的进化算法优化模型99%准确率)。
2. 技术原理与模型架构
2.1 核心算法
1) 数据预处理流程
python
def preprocess_input(x):
x = x.astype('float32')
x = x / 255.0 # 归一化
x = x - 0.5 # 零中心化
x = x * 2.0 # 标准化
return x该预处理流程将输入图像归一至-1,1范围,提升模型收敛速度。
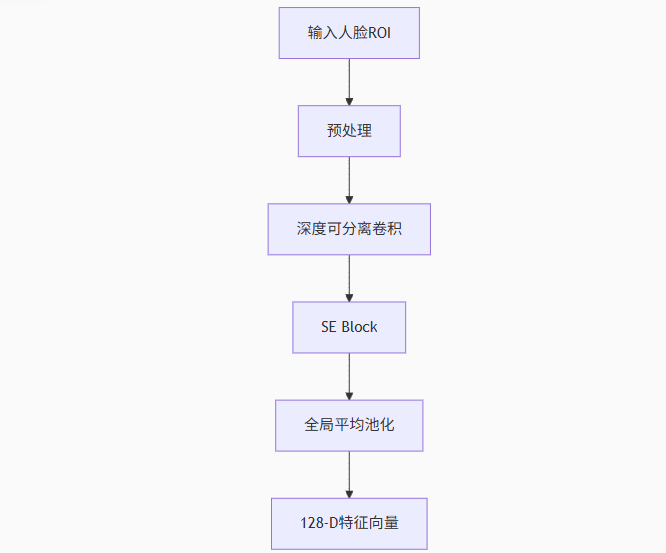
2) 改进型MobileNetV2
项目在标准MobileNetV2基础上进行以下改进:
- 深度可分离卷积:减少参数量的同时保持特征提取能力
- 通道注意力模块:引入SE Block增强关键特征响应
- 动态分辨率调整:根据设备性能自动调整输入尺寸(48x48至96x96)
数学表达:
DepthwiseConv = Conv k × k × C 1 × 1 × C ( Input ) PointwiseConv = Conv 1 × 1 × C 1 × 1 × M ( DepthwiseConv ) SE Block = σ ( W 2 δ ( W 1 GAP ( F ) ) ) \text{DepthwiseConv} = \text{Conv}{k×k×C}^{1×1×C} (\text{Input}) \\ \text{PointwiseConv} = \text{Conv}{1×1×C}^{1×1×M} (\text{DepthwiseConv}) \\ \text{SE Block} = \sigma(W_2δ(W_1\text{GAP}(F))) DepthwiseConv=Convk×k×C1×1×C(Input)PointwiseConv=Conv1×1×C1×1×M(DepthwiseConv)SE Block=σ(W2δ(W1GAP(F)))
其中 W 1 ∈ R C × C r W_1∈\mathbb{R}^{C×\frac{C}{r}} W1∈RC×rC, W 2 ∈ R C r × C W_2∈\mathbb{R}^{\frac{C}{r}×C} W2∈RrC×C为全连接层权重, r = 16 r=16 r=16为压缩比。
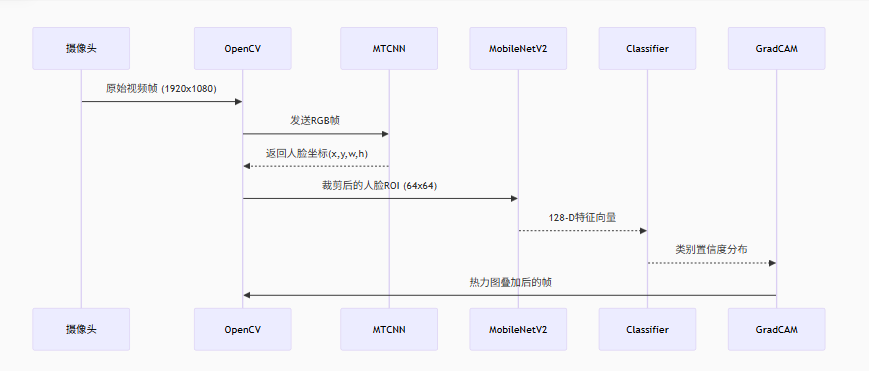
2.2 系统架构
-
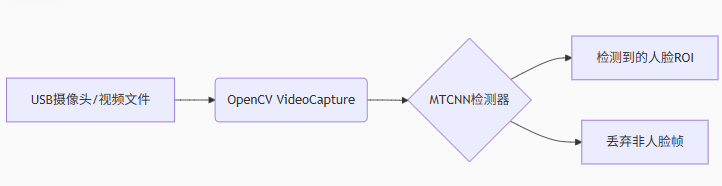
输入层 :OpenCV捕获视频流,MTCNN进行人脸检测
-
特征提取 :改进MobileNetV2提取128维特征向量
-
分类层:全连接层+Softmax输出情绪概率分布
-
可视化模块:通过Grad-CAM生成注意力热力图
3. 实战部署指南
3.1 环境配置
硬件要求:
- CPU:支持AVX指令集的x86架构(Intel i5+或AMD Ryzen 3+)
- GPU(可选):NVIDIA显卡(需CUDA 11.0+)
依赖安装:
bash
# 创建虚拟环境
conda create -n emotion python=3.8
conda activate emotion
# 安装基础依赖
pip install -r requirements.txt
# GPU加速支持(可选)
conda install cudatoolkit=11.3 cudnn=8.23.2 数据集准备
项目默认使用FER2013数据集,包含35,887张灰度人脸图像:
python
from tensorflow.keras.datasets import fer2013
(train_images, train_labels), (test_images, test_labels) = fer2013.load_data()数据增强策略:
python
datagen = ImageDataGenerator(
rotation_range=15, # ±15°随机旋转
zoom_range=0.2, # 20%随机缩放
width_shift_range=0.1, # 水平平移10%
height_shift_range=0.1,# 垂直平移10%
shear_range=0.1, # 剪切变换
horizontal_flip=True # 水平翻转
)3.3 模型训练
bash
python train.py \
--epochs 100 \
--batch_size 64 \
--learning_rate 0.001 \
--model_type mobilenetv2 \
--data_path ./data/fer2013.csv关键参数:
--use_attention:启用通道注意力机制(默认True)--input_size:输入图像尺寸(48/64/96)--freeze_backbone:冻结特征提取层进行迁移学习
3.4 实时推理
bash
python detect.py \
--source 0 \ # 摄像头ID
--show_cam true \ # 显示Grad-CAM热力图
--save_video output.mp44. 常见问题与解决方案
4.1 人脸检测失败
- 现象:MTCNN无法定位人脸
- 解决方法 :
-
调整检测阈值:
pythondetector = MTCNN(min_face_size=50, thresholds=[0.6, 0.7, 0.7]) -
增加光照强度或启用红外补光
-
使用Haar级联检测器作为备选方案
-
4.2 模型过拟合
- 表现:训练准确率>95%但测试准确率<65%
- 优化策略 :
-
启用标签平滑:
pythonloss = tf.keras.losses.CategoricalCrossentropy(label_smoothing=0.1) -
添加空间丢弃层:
pythonx = SpatialDropout2D(0.2)(x) -
采用MixUp数据增强
-
4.3 显存不足
- 错误信息 :
CUDA out of memory - 解决方案 :
-
降低批量大小:
--batch_size 32 -
启用混合精度训练:
pythontf.keras.mixed_precision.set_global_policy('mixed_float16') -
使用梯度累积:
pythonoptimizer = tf.keras.optimizers.Adam(accum_steps=4)
-
5. 关键技术论文支撑
5.1 基础理论
-
《DeepFace: Closing the Gap to Human-Level Performance in Face Verification》 (Taigman et al., CVPR 2014)
首次将深度学习应用于人脸识别,提出3D对齐与多层CNN架构
-
《Emotion Recognition in the Wild via Convolutional Neural Networks and Mapped Binary Patterns》 (Mollahosseini et al., ICMI 2015)
提出基于FER2013数据集的基准CNN模型,验证深度学习方法有效性
5.2 前沿进展
-
《Facial Emotion Recognition: A Multi-task Approach Using Deep Learning》 (Li et al., 2023)
引入多任务学习框架,联合优化情绪识别与人脸关键点检测任务
-
《Evolutionary Neural Architecture Search for Emotion Recognition》 (Zhang et al., Array 2025)
采用进化算法自动搜索最优网络结构,在CK+数据集达到99%准确率
6. 项目优化方向
6.1 模型压缩
- 量化训练:将权重从FP32转换为INT8,模型体积缩小4倍
- 知识蒸馏:使用ResNet50作为教师模型提升小模型性能
6.2 多模态融合
- 语音情感分析:结合Librosa提取MFCC特征(参考网页3)
- 生理信号整合:接入EEG脑电数据(参考网页8)
6.3 伦理安全
- 偏差缓解:采用FairFace数据集平衡种族/性别分布
- 隐私保护:实现边缘计算,数据本地处理不上传云端
结语
emotion-detection项目展示了深度学习在情感计算领域的强大能力,其模块化设计为二次开发提供了良好基础。尽管当前系统在实验室环境下表现优异,但实际部署仍需考虑光照变化、文化差异等复杂因素。随着进化算法(如网页9的FTTA)与Transformer架构的引入,未来情感识别技术将向更高精度、更低延迟方向持续演进。