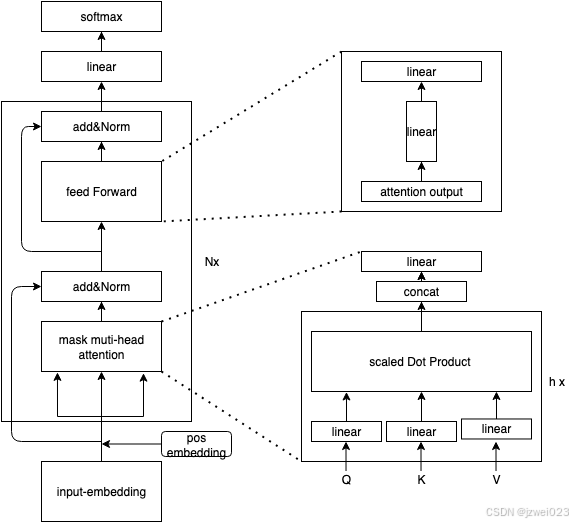
Transformer 的 Decoder-Only 架构(如 GPT 系列模型)是当前大语言模型的主流架构,其参数量主要由以下几个部分组成:
- 嵌入层(Embedding Layer)
- 自注意力层(Self-Attention Layers)
- 前馈网络(Feed-Forward Network, FFN)
- Layer Normalization 和偏置项
|--------------------------------|-----------------------------------------------------------------------------------------------------------------|
| Operation | Parameters |
| Embedding | ( n_vacab + n_ntx ) × d_model |
| Attention:QKV | 3 × n_layer × d_model × d_attn |
| Attention:Project | n_layer × d_model × d_attn |
| Feedforward | 2 × n_layer × d_model × d_ff |
| Layer Normalization 和偏置项 | 4 × n_layer × d_model |
| Total(Attention + Feedforward) | 2 × n_layer × d_model × ( 2 × d_attn + d_ff ) ≈ 12 × n_layer × d_model^2 假设d_attn = d_model,d_ff = 4 × d_model |
参数定义:
d_mdole:模型维度;
n_layer:层数;
d_attn:注意力输出维度;
d_ff:前馈网络维度;
n_ntx:最大上下文长度(token)
n_head:注意力头数
n_vacab:词汇表大小
1. 嵌入层(Embedding Layer)
嵌入层的作用是将输入 token 转换为高维向量表示。参数量为:n_vacab × d_model
此外,绝对位置编码通常由可学习的嵌入矩阵实现,其权重维度为: n_ntx × d_model
此外,在语言模型中,输出层通常与嵌入层共享权重矩阵(Tie Embedding),因此不需要额外计算输出层的参数量。
所以嵌入层总参数数:( n_vacab + n_ntx ) × d_model
备注:假设输入 x_i = (w_1, w_2,..., w_n_ntx),长度为n_ntx,batch 大小为b,则原始输入维度为:(b,n_ntx),经过embedding后输出维度为(b, n_ntx, d_model)
2. 自注意力层(Self-Attention Layers)
每个 Transformer 层包含一个多头自注意力机制(Multi-Head Self-Attention, MHSA),其参数量主要来自以下三部分:
- 线性变换矩阵:生成 Query、Key、Value
- 输出投影矩阵:将多头结果拼接后进行线性变换
假设:
- 输入的维度为
d_model - 注意力头数为
h - 每个头的维度为
d_k(通常满足 d_k = d_attn / h) - QKV输出维度d_attn,然后经过投影,输出维度 d_model
(1) 生成 Query、Key、Value 的线性变换矩阵
每个头的 Q、K、V 都需要一个独立的线性变换矩阵,因此总的参数量为:
Attention QKV Parameters = 3 × d_model × d_attn
(2) 输出投影矩阵
多头注意力的结果需要通过一个线性投影矩阵转换回 d_model 维度,因此参数量为:
Attention Project Parameters = d_attn × d_model
(3) 总自注意力层参数量
单个自注意力层的参数量为:
Self-Attention Parameters = 3 × d_model × d_attn + d_attn × d_model = 4 × d_model × d_attn
如果有 n_layer 个 Transformer 层,则总的自注意力层参数量为:
Total Self-Attention Parameters = 4 × n_layer × d_model × d_attn
备注:嵌入层输出的 x维度是(b, n_ntx, d_model),W_Q维度是(d_model, d_attn),则Q = x * W_Q维度是(b, n_ntx, d_attn),通过self-attention后,输出维度为(b, n_ntx, d_attn),然后通过attention project后维度是(b, n_ntx, d_model)
3. 前馈网络(Feed-Forward Network, FFN)
每个 Transformer 层包含一个两层的前馈网络(FFN),其参数量主要来自以下两部分:
- 第一层从
d_model映射到d_ff(通常是d_model的 4 倍)。 - 第二层从
d_ff映射回d_model。
(1) 第一层参数量
第一层将 d_model 映射到 d_ff,因此参数量为:
First Layer Parameters=d_model × d_ff
(2) 第二层参数量
第二层将 d_ff 映射回 d_model,因此参数量为:
Second Layer Parameters=d_ff × d_model
(3) 总前馈网络参数量
单个前馈网络的参数量为:
FFN Parameters=d_model ×d_ff + d_ff × d_model = 2 × d_model × d_ff
如果有 n_layer 个 Transformer 层,则总的前馈网络参数量为:
Total FFN Parameters = 2 × n_layer × d_model × d_ff
备注:(b, n_ntx, d_model)经过FFN后输出维度是(b, n_ntx, d_model)
4. Layer Normalization 和偏置项
每个 Transformer 层包含两个 Layer Normalization 操作(分别在自注意力和前馈网络之后),每个 Layer Normalization 包含两个可学习参数(缩放因子和偏移因子)。
总的 Layer Normalization 参数量为:
LayerNorm Parameters = n_layer × 2 × 2 × d_model = 4 × n_layer × d_model
5. 总参数量
Total Parameters = ( n_vacab + n_ntx ) × d_model + 4 × n_layer × d_model × d_attn + 2 × n_layer × d_model × d_ff + 4 × n_layer × d_model
Total Parameters ≈ 4 × n_layer × d_model × d_attn + 2 × n_layer × d_model × d_ff = 2 × n_layer × d_model × ( 2 × d_attn + d_ff )
假设d_attn = d_model, 以及d_ff = 4 × d_model,则
Total Parameters ≈ 12 × n_layer × d_model^2
6. 实际例子
以 GPT-3 为例:
- 词汇表大小 n_vacab = 50257
- 模型维度 d_model = 12288
- 前馈网络维度 d_ff=4 × d_model = 49152
- 层数 n_layer = 96
- 最大上下文长度 (token)n_ntx = 2048
代入公式:
Total Parameters = (50257 + 2048) ×12288 + 96×(4×122882+8×122882) + 4×96×12288
计算结果约为 175B 参数,与 GPT-3 的实际参数量一致。