【堆 + 堆排序 + TOP-K】目录

往期《数据结构初阶》回顾:
【时间复杂度 + 空间复杂度】
【顺序表 + 单链表 + 双向链表】
【顺序表/链表 精选15道OJ练习】
【顺序栈 + 链式队列 + 循环队列】
【链式二叉树】
前言:
Hi~ 宝子们~(๑・̀ㅂ・́)و✧,今天是周一,阳光明媚。新一周的旅程又要开始了是不是感觉活力满满呀!💪
在之前的数据结构的学习旅程中🚀,咱们已经积累了不少经验啦~🎉
⏳现在,是时候来深入学习《数据结构初阶》里 "堆 + 堆排序 + TOP - K🏆 " 的内容了!
这就像是给我们的编程秘籍又添上了超厉害的几页📖💫,解锁新技能指日可待!
什么是堆?
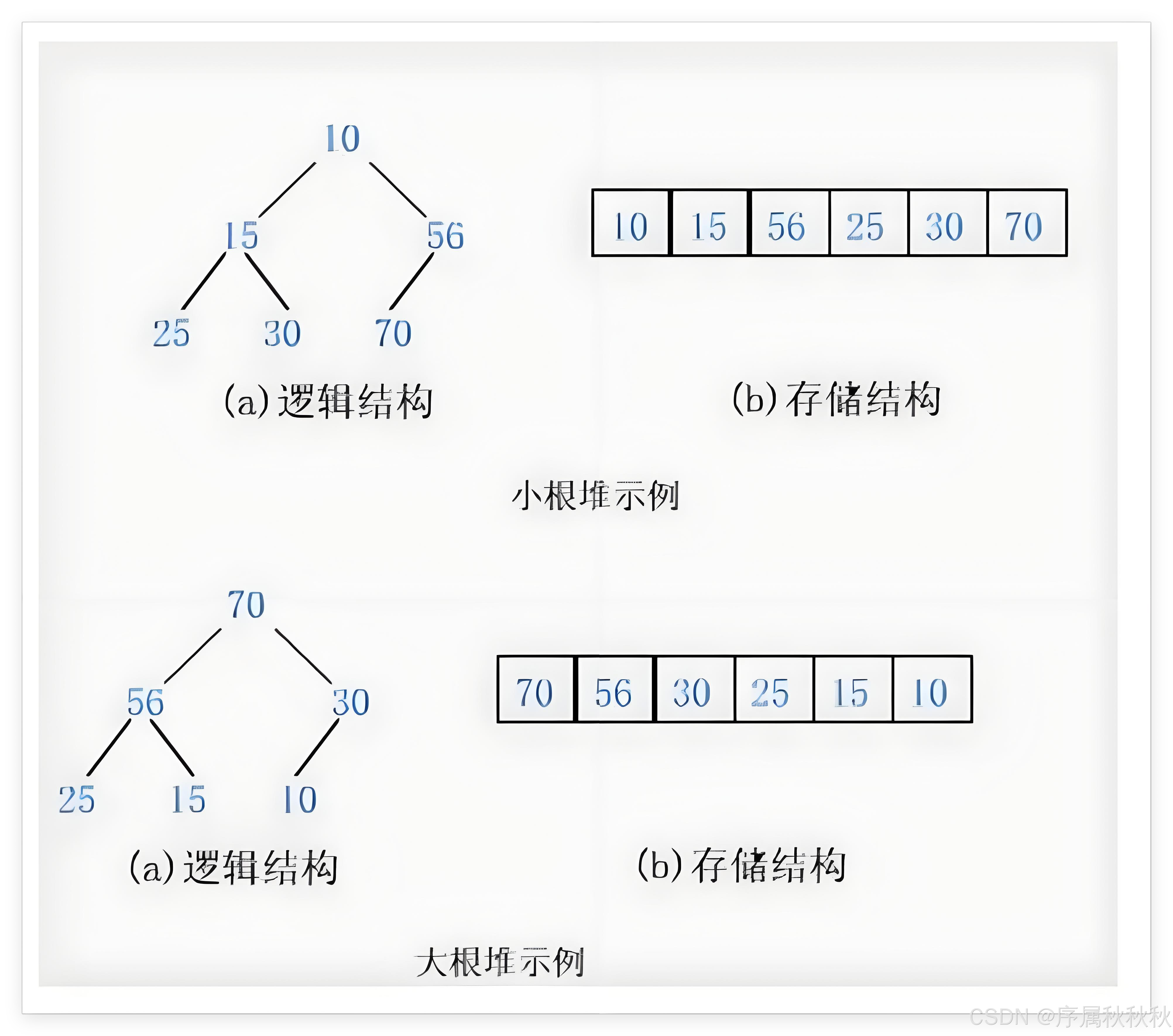
堆(Heap):是一种特殊的完全二叉树结构。满足以下性质:
堆序性:每个节点的值必须满足与子节点的大小关系。
- 最大堆(大根堆):父节点的值 ≥ 子节点的值(根节点最大)
- 最小堆(小根堆):父节点的值 ≤ 子节点的值(根节点最小)
完全二叉树:除了最后一层,其他层必须填满,且最后一层从左到右填充。
堆的实现方式有哪些?我们要选择哪种方式进行实现?
堆常见的实现方式主要是基于数组 ,这是因为堆是完全二叉树,而数组能高效地存储完全二叉树结构。
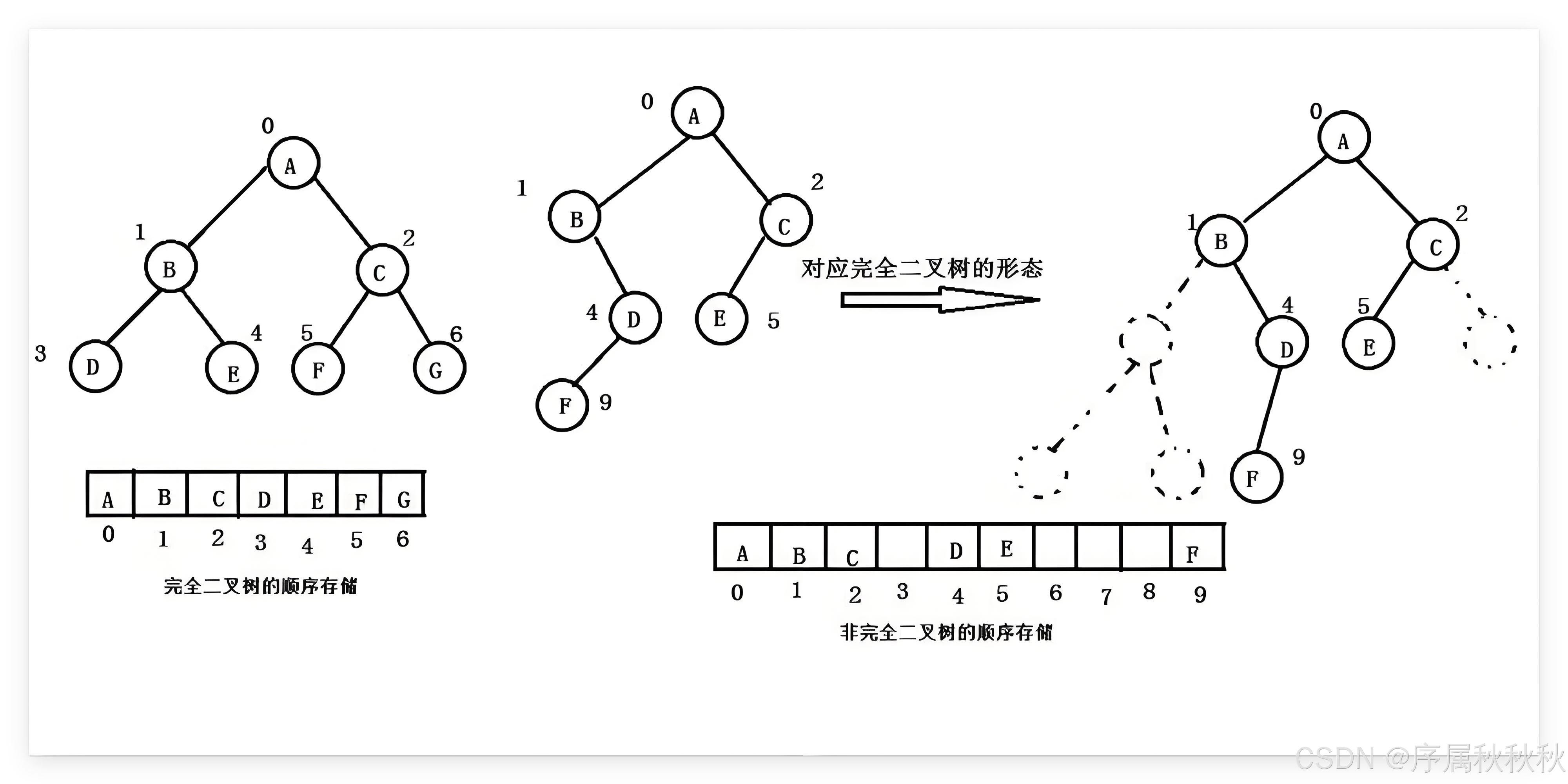
数组实现的存储规则:把堆中的元素按完全二叉树的层序遍历顺序存放在数组里。
假设根节点在数组中的索引为 0 0 0 ,对于节点 i i i ,其:
左子节点索引为: 2 ∗ i + 1 2 * i + 1 2∗i+1右子节点索引为: 2 ∗ i + 2 2 * i + 2 2∗i+2父节点索引为: ( i − 1 ) / 2 (i - 1) / 2 (i−1)/2例如:有一个最小堆 1, 3, 4, 7, 8, 9 ,根节点 1 的索引是 0 ,其左子节点 3 索引为 1 ,右子节点 4 索引为 2
c
typedef int HPDataType;
typedef struct Heap
{
//核心思路:堆是完全二叉树所以使用数组实现比较好
//1.记录数组的容量 ---> 一个int变量
//2.记录当前数组中元素的数量 --> 一个int变量
//3.使用数组存储堆中的节点 ---> 定义一个动态数组
int capacity;
int size;
HPDataType* a;
}HP;----------------堆的实现----------------
堆作为一种重要的数据结构,其高效性依赖于两个核心算法:
向上调整算法(Heapify Up)和向下调整算法(Heapify Down)这两种算法是堆操作的基础,直接支撑了堆的各类接口实现。
基于这些,在使用数组实现堆之前我们要先来学习一下这两个算法。
什么是向上调整算法,要怎么实现?
向上调整算法:当新元素插入 堆的末尾时,通过向上调整使其满足堆序性。
向上调整的执行流程
- 将新元素插入堆的末尾(数组的最后位置)
- 比较新元素与其父节点的值:
- 若不满足堆序性(如:在最小堆中,新元素比父节点小),则交换两者
- 重复此过程,直到新元素到达合适位置 或成为根节点
时间复杂度 : O ( log n ) O(\log n) O(logn),其中 n n n 为堆的元素数量。
- 因为 :堆的高度为 log n \log n logn,最坏情况下需调整至根节点。
什么是向下调整算法,要怎么实现?
向下调整算法:当堆顶 元素被删除或替换时,通过向下调整重新恢复堆序性。
向下调整的执行流程
- 将堆顶元素替换为堆的最后一个元素(或者:删除堆顶元素后,移动最后元素至堆顶)
- 比较当前节点与其子节点的值:
- 在最小堆中,若当前节点大于其子节点中的最小值,则与该最小值交换。
- 在最大堆中,若当前节点小于其子节点中的最大值,则与该最大值交换。
- 重复此过程,直到当前节点到达合适位置或成为叶子节点。
时间复杂度 : O ( log n ) O(\log n) O(logn)
- 因为:最坏情况下需从根节点调整至叶子节点。
向上调整算法/向下调整算法的注意事项?
向上调整算法要求原树必须已经是一个堆
因为向上调整算法是在已知当前节点的父节点到根节点的路径上已经是一个堆的情况下,将新插入的节点从下往上调整,使其满足堆的性质。
- 例如:在向小根堆中插入一个新元素时,将新元素先放在堆的最后一个位置,然后从该位置开始向上调整,比较当前节点与父节点的值,如果当前节点的值小于父节点的值,则交换它们,直到满足堆的性质或者到达根节点。
向下调整算法要求根节点的左右子树必须是一个堆
因为向下调整算法在执行过程中,是假设根节点的左右子树已经是符合堆性质的堆结构,然后通过比较根节点与左右孩子节点的值,并在必要时进行交换,来使整个树重新满足堆的性质。如果左右子树不是堆,那么算法无法保证最终调整后的树是一个堆。
- 例如:对于一个小根堆,要将根节点向下调整,会先比较根节点与左右孩子中较小的那个,如果左右子树不是小根堆,那么这个较小值不一定是真正应该与根节点交换的值,就无法正确调整。
现在我们给出一个数组,在逻辑上可以将其看作一颗完全二叉树。例如 :对于数组
int array[] = {27, 15, 19, 18, 28, 34, 65, 49, 25, 37},在使用向下调整算法前,需要保证其左右子树符合堆的特性,否则无法正确调整为小堆 。
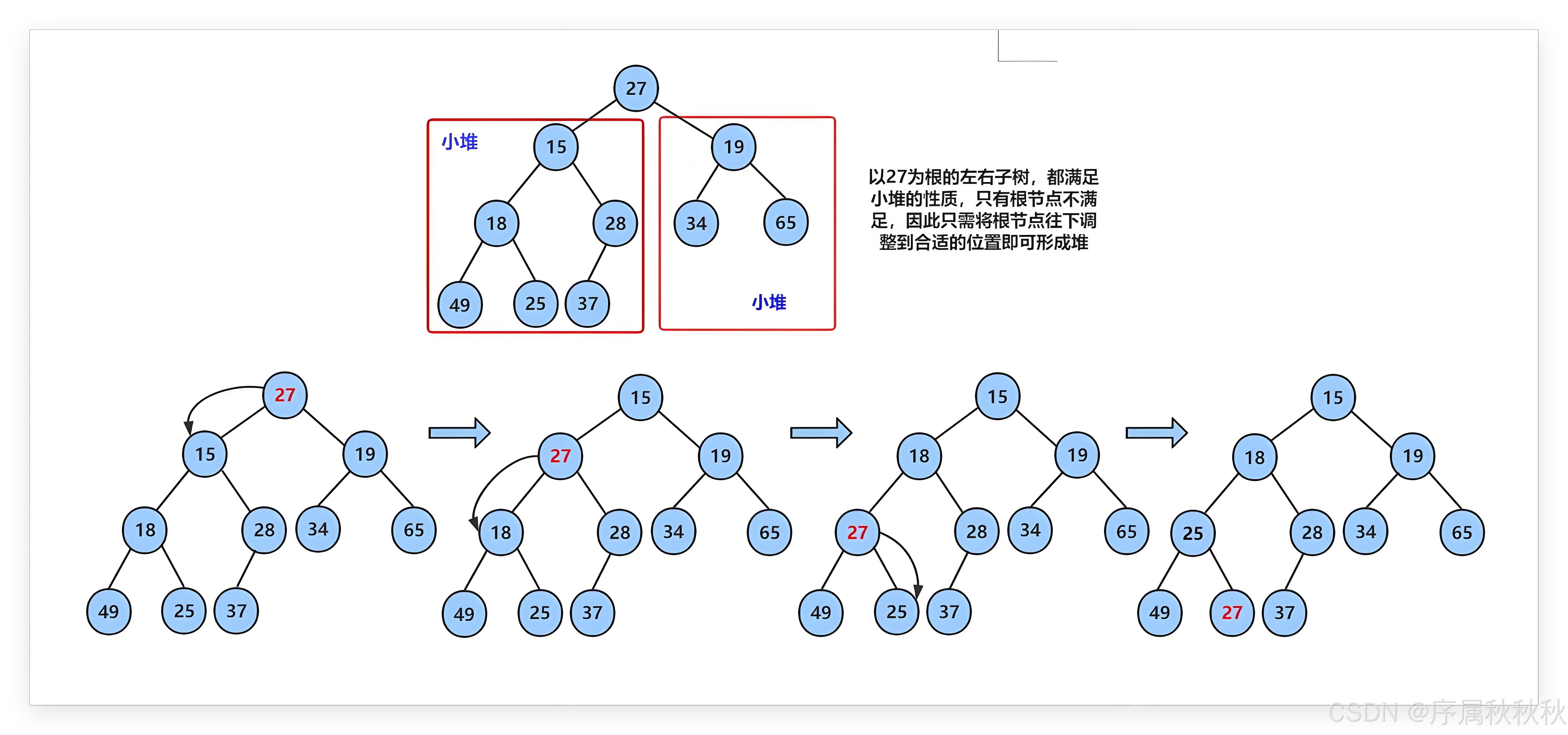
堆的数组实现
怎么建堆?建堆的方法有哪些?
建堆:是将一个无序的完全二叉树调整为堆结构的过程。常见的建堆方法有两种 :
自顶向下的调整方法和自底向上的调整方法
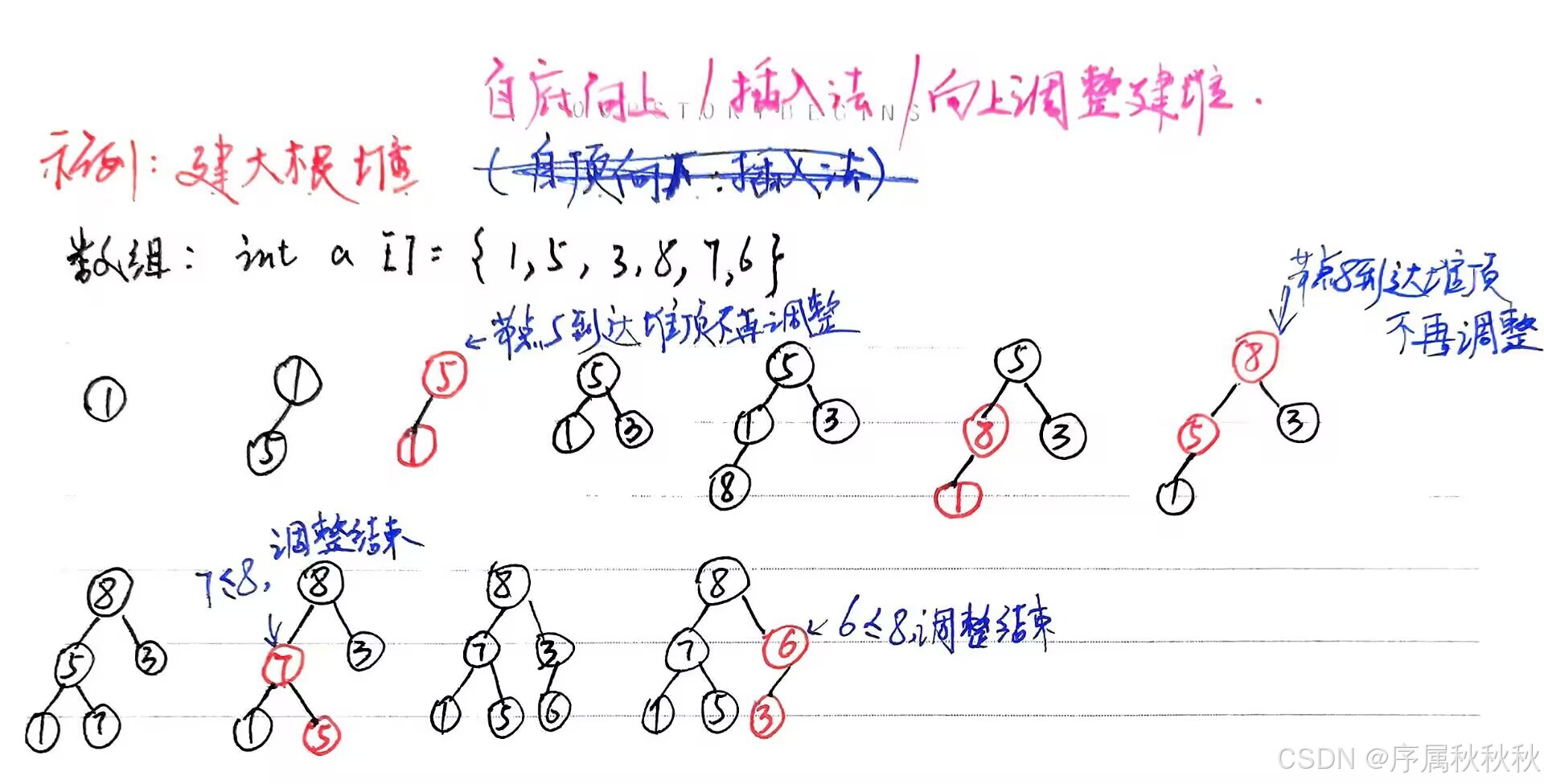
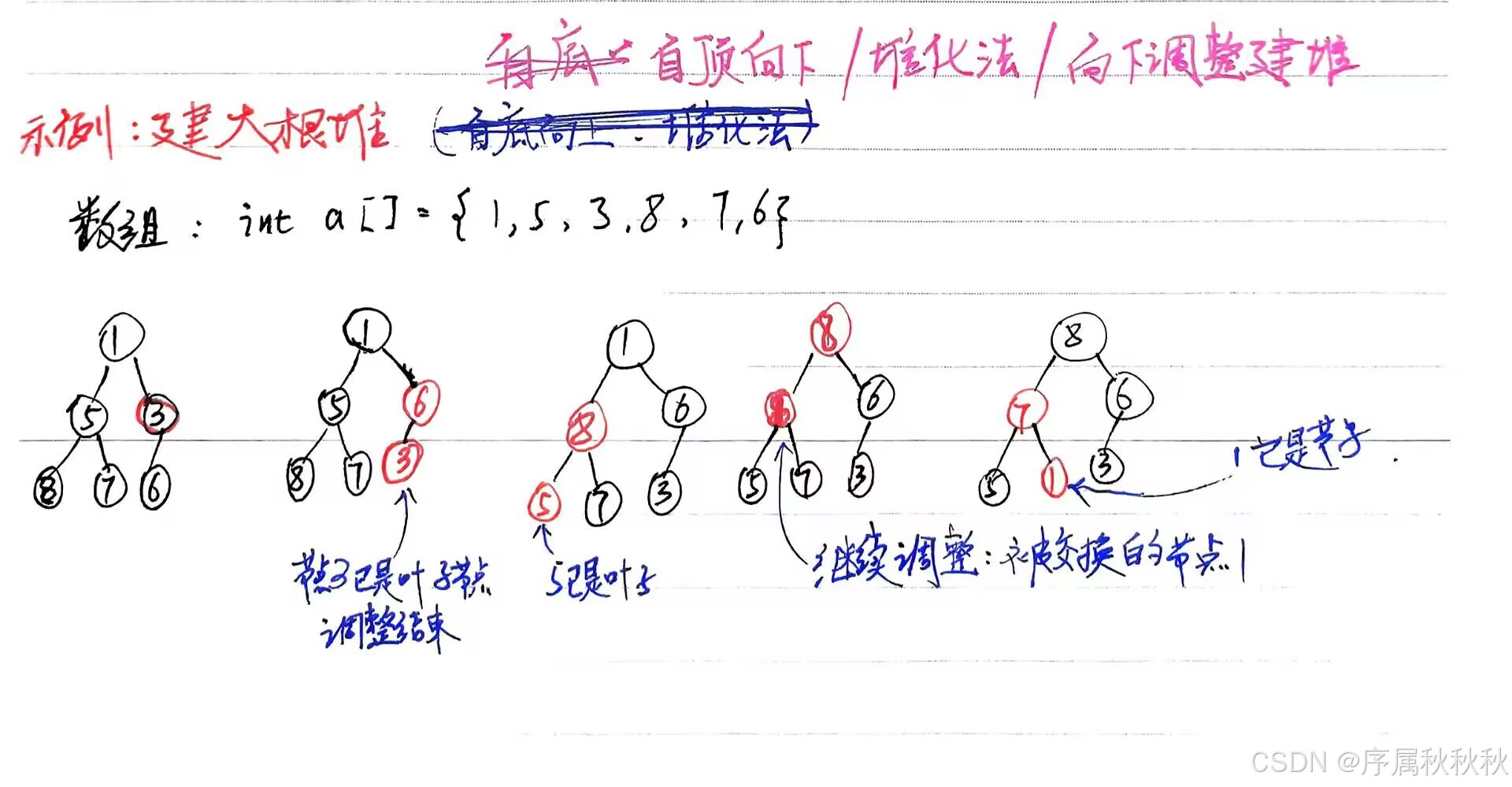
自底向上(插入法):将元素逐个插入空堆,每次插入后通过 向上调整(Heapify Up) 维护堆性质。步骤:(示例:建大根堆)
- 假设初始时堆中只有一个元素,即数组的第一个元素,它本身就是一个堆。
- 依次将数组中的其他元素插入到堆中。
- 对于每个插入的元素,将其与父节点比较,如果大于父节点,则交换位置
- 继续向上比较,直到满足堆的性质(父节点大于等于子节点)
自顶向下(堆化法):从最后一个非叶子节点开始,向前遍历并对每个节点执行 向下调整(Heapify Down) 来维护堆性质。步骤:
- 找到最后一个非叶子节点(索引为: ( n − 1 ) / 2 (n-1)/2 (n−1)/2)
- 从该节点开始向前遍历到根节点
- 对每个节点执行向下调整,使其子树满足堆性质
温习提示 :建堆的时候我们更多的使用的
堆化法进行建堆,因为:
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 自底向上(插入法) | O ( n l o g n ) O(nlogn) O(nlogn) | O ( n ) O(n) O(n) |
| 自顶向下(堆化法) | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) |
为什么堆化法建堆时从最后一个非叶子节点开始?
在建堆过程中,我们需要从最后一个非叶子节点(即:
(n-1)/2)开始,自底向上依次调用向下调整,这是因为:
- 所有叶子节点位于该节点之后,叶子节点本身天然满足堆性质(因为它们没有子节点,无需调整)
- 从最后一个非叶子节点开始调整,可以保证每次调用 向下调整(Heapify Down) 时,其左右子树已经是堆
插入法/堆化法建堆的时间复杂度是怎么计算出来的?
我们先来看看
插入法的时间复杂度:
- 每次插入的向上调整操作需 O ( l o g n ) O(logn) O(logn),共 n n n 次操作 → 总复杂度 O ( n l o g n ) O(nlogn) O(nlogn)
接下来我们再来看看
堆化法的时间复杂度:因为堆是完全二叉树,而满二叉树也是完全二叉树,所以此处为了简化问题,使用满二叉树来证明(时间复杂度本来看的 就是近似值,所以多几个结点并不影响最终结果)
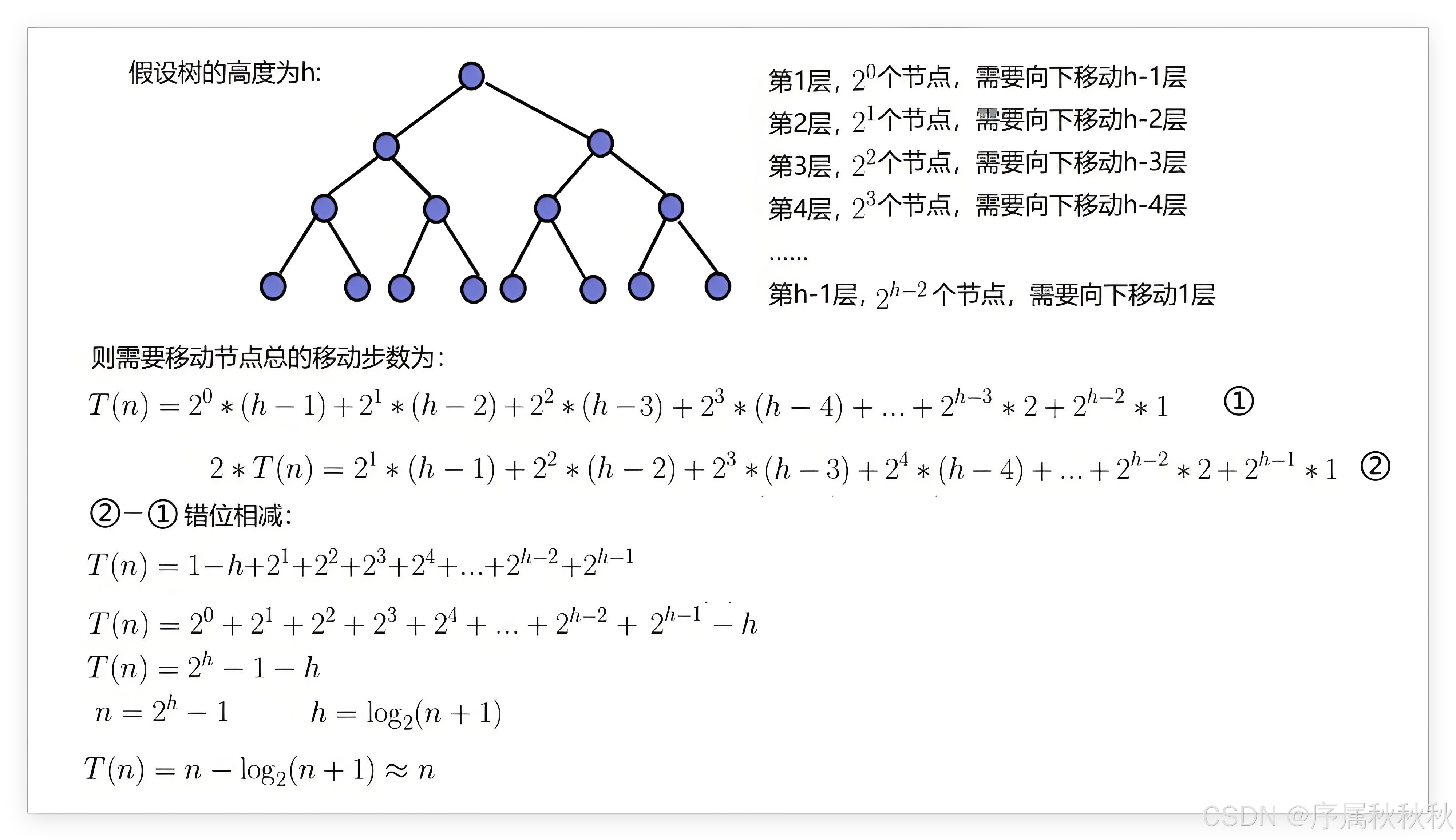
因此 :使用堆化法建堆的时间复杂度为: O ( n ) O(n) O(n)
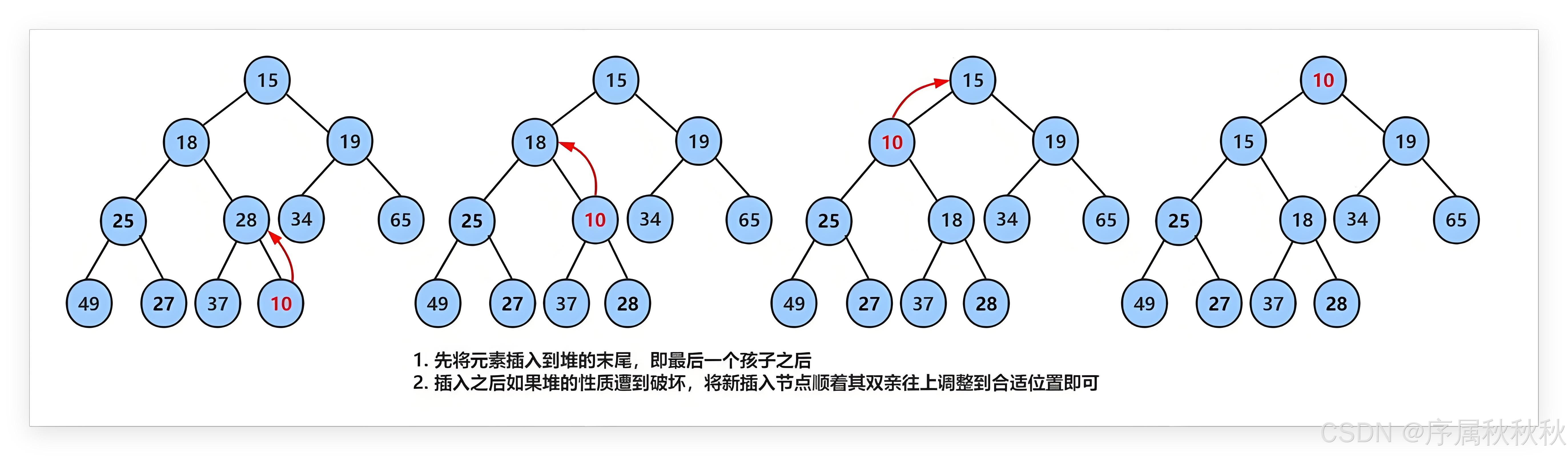
怎么实现堆的插入操作?
堆的插入操作实现步骤(以数组表示完全二叉树)
前提条件:
大顶堆:每个父节点的值 ≥ 子节点的值小顶堆:每个父节点的值 ≤ 子节点的值通用步骤:
- 将新元素插入堆尾
- 将元素添加到数组末尾,保持完全二叉树的结构特性
- 新元素的索引为
n(数组长度),其父节点索引为(n-1)/2(向下取整)向上调整(Heapify Up)/插入法
- 从新节点开始,自底向上比较并交换,直到满足堆性质或到达根节点。
- 比较逻辑 :
大顶堆:若当前节点 > 父节点,则交换两者(确保父节点值最大)小顶堆:若当前节点 < 父节点,则交换两者(确保父节点值最小)- 终止条件
大顶堆:当前节点 ≤ 父节点 或 到达根节点。小顶堆:当前节点 ≥ 父节点 或 到达根节点。
图像演示:小根堆的插入
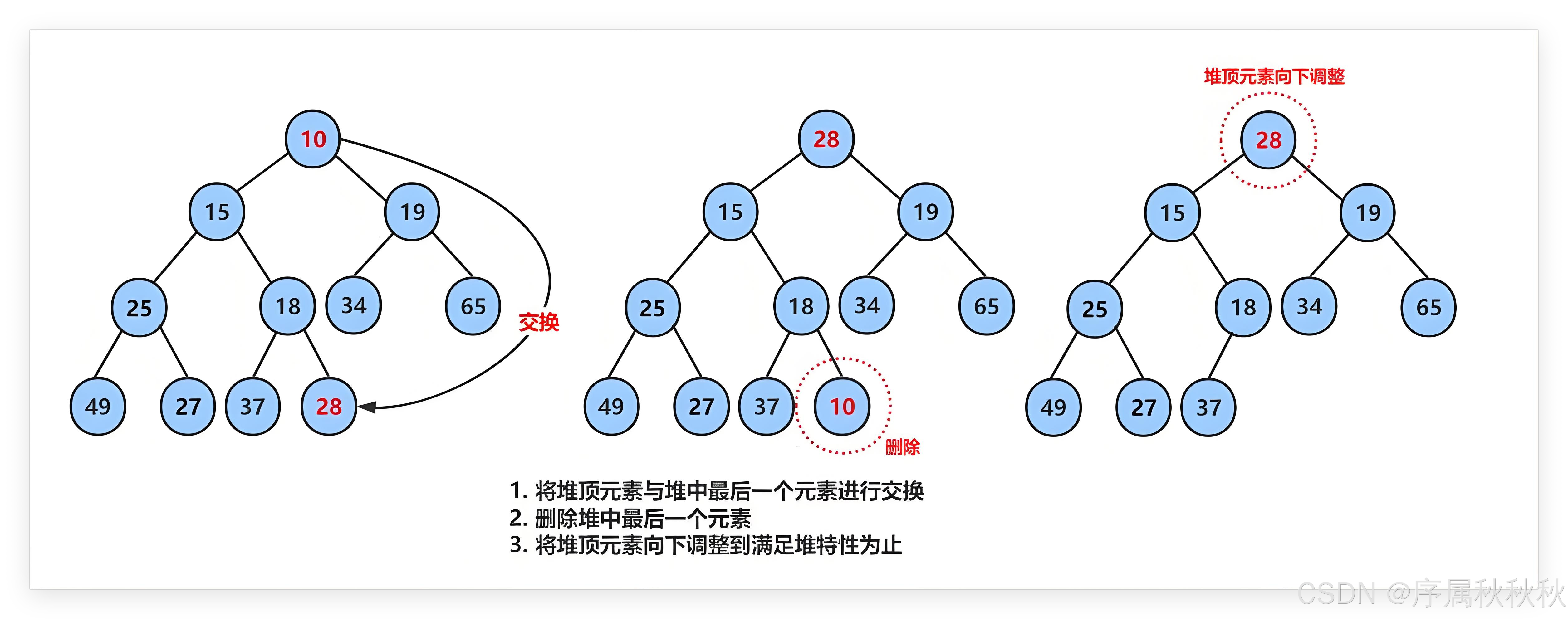
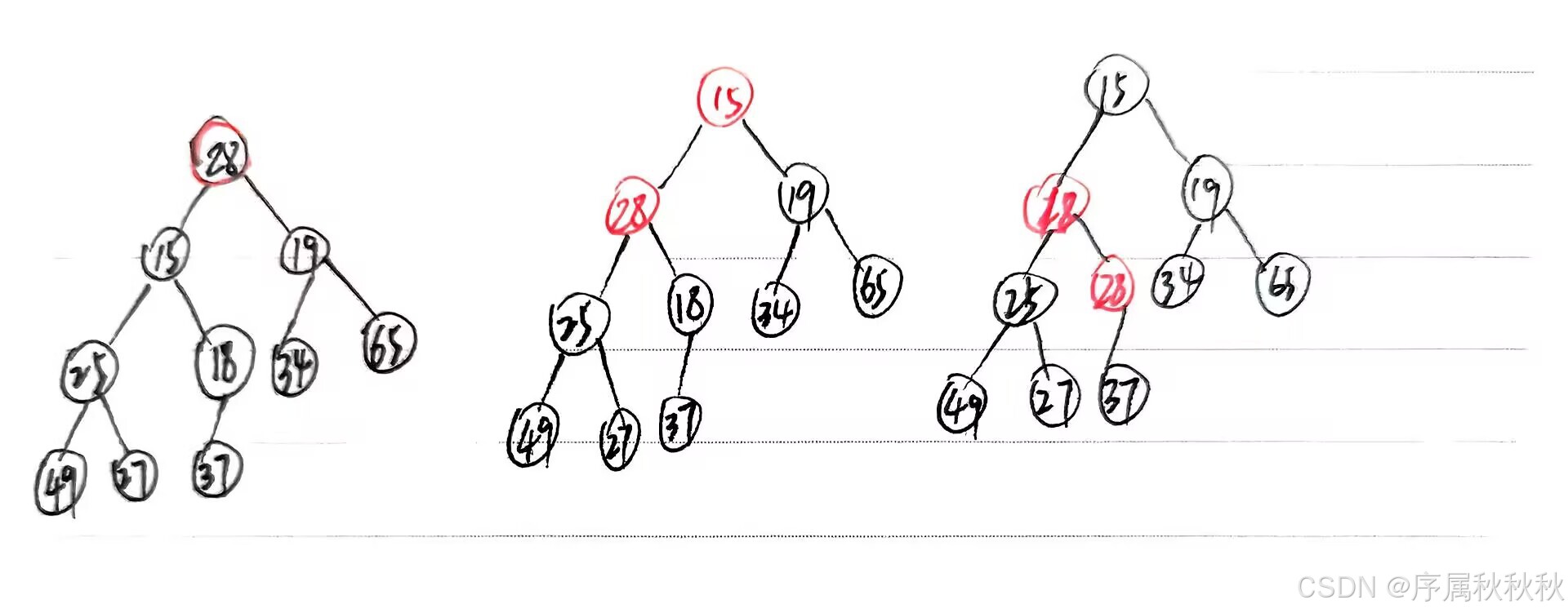
怎么实现堆的删除操作?
堆的删除操作实现步骤(以数组表示完全二叉树)
前提条件:
大顶堆:每个父节点的值 ≥ 子节点的值小顶堆:每个父节点的值 ≤ 子节点的值通用步骤:
- 移除堆顶元素
- 将堆顶元素(数组首元素)与堆尾元素(数组尾元素)交换。
- 删除数组最后一个元素(原堆顶),保持完全二叉树的结构特性。
- 新的堆顶元素移至索引
0,数组长度减1向下调整(Heapify Down)/堆化法
- 从新堆顶开始,自顶向下比较并交换,直到满足堆性质或到达叶子节点。
- 比较逻辑 :
大顶堆:若当前节点 < 任一子节点,选择 较大的子节点 交换(确保父节点值最大)小顶堆:若当前节点 > 任一子节点,选择 较小的子节点 交换(确保父节点值最小)- 终止条件
大顶堆:当前节点 ≥ 所有子节点 或 到达叶子节点。小顶堆:当前节点 ≤ 所有子节点 或 到达叶子节点。
图像演示:小根堆的删除
--------------------------------
头文件
cpp
---------------------------------Heap.h---------------------------------
#pragma once
//任务1:声明需要使用的头文件
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
//任务2:定义堆的结构体(存储类型)
typedef int HPDataType;
typedef struct Heap
{
//核心思路:堆是完全二叉树所以使用数组实现比较好
//1.记录数组的容量 ---> 一个int变量
//2.记录当前数组中元素的数量 --> 一个int变量
//3.使用数组存储堆中的节点 ---> 定义一个动态数组
int capacity;
int size;
HPDataType* a;
}HP;
//任务3:声明堆的常用的工具函数
//1.交换数组中两个元素
//2.堆的向上调整算法(用于插入元素后维护堆的性质)
//3.堆的向下调整算法(用于删除元素后维护堆的性质)
void Swap(HPDataType* a, HPDataType* b);
void AdjustUp(HPDataType* a, int child);
void AdjustDown(HPDataType* a, int parent, int n);
//注意:这里我们使用的这些工具函数的形参不是:堆,;而是:动态数组
//原因:传参时传入动态数组是因为这些工具函数不仅可以用在实现"堆"这种的数据结构上,还可以继续使用在"堆排序"上
//任务4:声明堆的接口
//1.堆的初始化
//2.堆的销毁
//3.堆的插入
//4.堆的删除
//5.堆的取出堆元素
//6.堆的判空
void HPInit(HP* php);
void HPDestroy(HP* php);
void HPPush(HP* php, HPDataType x);
void HPPop(HP* php);
HPDataType HPTop(HP* php);
bool HPEmpty(HP* php);实现文件
cpp
--------------------------------Heap.c--------------------------------
#include "Heap.h"
//1.实现:"交换两个元素的值"工具函数
void Swap(HPDataType* a, HPDataType* b)//形参是是指针类型,函数中的修改会影响到原数组中的值
{
HPDataType tmp = *a;
*a = *b;
*b = tmp;
}
//2.实现:"向上调整算法"工具函数
void AdjustUp(HPDataType* a, int child)
{
//1.计算出父节点在数组中的下标(我们有孩子 ---> 得到双亲)
int parent = child - 1 >> 1;
//2.接下来不断的进行向上调整,何时调整结束? ---> 回答:1.当孩子已经调整成根节点时 2.当孩子不满小堆的性质时(这里我们模拟小根堆)
while (child > 0)
{
//3.使用if-else语句进行小根堆的条件检查(小根堆:谁小谁当爹)
if (a[child] >= a[parent]) return;
else
{
//4.1:交换的孩子节点和双亲节点的值
Swap(&a[child], &a[parent]);
//4.2:更新孩子的索引 ---> 因为我们要为孩子找到一个合适的位置
child = parent;
//4.3:求出现在孩子的双亲节点的索引
parent = child - 1 >> 1;
}
}
}
//3.实现:"向下调整算法"工具函数
void AdjustDown(HPDataType* a, int parent, int n)
{
//1.计算出孩子节点在数组中的下标(我们有双亲节点 ---> 得到"值最小的"孩子)
//这里和向上调整有点不一样:找双亲节点就只有一个,但是找孩子节点有两个,要找哪一个呢?---> 找值最小的孩子
//注:这里使用假设法:假设双亲的左孩子是最小的孩子
int minchild = parent << 1 + 1;
//2.接下来不断地进行向下调整,何时调整结束 ---> 1.当孩子节点的索引已经大于数组的容量,即:孩子不存在时 2.当孩子不满足小根堆的条件检查时
while (minchild < n)
{
//3.调整出minchild代表是最小的孩子
if (minchild + 1 < n && a[minchild] > a[minchild + 1])
{
minchild++; //切换到右孩子
}
//3.使用if-else语句进行小根堆的条件检查
if (a[minchild] >= a[parent]) return;
else
{
//4.1:交换孩子节点和双亲节点的值
Swap(&a[minchild], &a[parent]);
//4.1:更新双亲节点的索引
parent = minchild;
//4.2:求出现在双亲节点的孩子节点的索引
minchild = parent << 1 + 1;
}
}
}
//--------------------------------------------------------------------------------------------------------------------------------------
//1.实现:"堆的初始化"操作
void HPInit(HP* php)
{
assert(php);
php->capacity = 0;
php->size = 0;
php->a = NULL;
}
//2.实现:"堆的销毁"操作
void HPDestroy(HP* php)
{
assert(php);
php->capacity = 0;
php->size = 0;
free(php->a);
php->a = NULL;
}
//3.实现:"堆的插入"操作
void HPPush(HP* php,HPDataType x)
{
assert(php);
//1.插入操作要先判断:isfull + 选择进行扩容
if (php->size == php->capacity)
{
//1.1进行扩容:(扩容可能有两种情况:1.我们没有分配空间进行扩容 2.我们现在的空间不足进行的扩容)
//1.1.1:先判断一下我们是因为哪种情况才进行扩容的
int newCapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
//1.1.2:realloc新的内存空间
HPDataType* tmp = (HPDataType*)realloc(php->a, newCapacity * sizeof(HPDataType));
//1.2.判断空间是否分配成功
if (tmp == NULL)
{
perror("realloc fail");
}
//1.3.更新动态数组的内存空间
php->a = tmp;
//1.4.更新动态数组的容量
php->capacity = newCapacity;
}
//2.1.将元素插入到数组的末尾
php->a[php->size] = x;
//2.2.更新动态数组的容量
php->size++;
//3.向上调整新插入的元素
AdjustUp(php->a, php->size - 1);// 注意:向上调整算法的第二个形参是"孩子在数组中的索引"
}
//4.实现:"堆的删除"操作
void HPPop(HP* php)
{
assert(php);
///0.删除元素要先判断堆中是否还有元素
assert(php->size > 0);
//1.将堆顶的元素与末尾的元素进行交换
Swap(&php->a[0], &php->a[php->size - 1]);
//2.更新动态数组的容量-->删除堆末尾的元素
php->size--;
//3.从堆顶开始向下调整
AdjustDown(php->a, 0, php->size);
}
//5.实现:"堆的取堆顶元素"操作
HPDataType HPTop(HP* php)
{
assert(php);
assert(php->size > 0);
return php->a[0];
}
//6.实现:"堆的判空"操作
bool HPEmpty(HP* php)
{
assert(php);
return php->size == 0;
}测试文件
c
#include "Heap.h"
/*-------------------------打印堆内容(辅助函数)-------------------------*/
void PrintHeap(HP* php)
{
printf("堆内容(大小=%d, 容量=%d): ", php->size, php->capacity);
for (int i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
printf("\n");
}
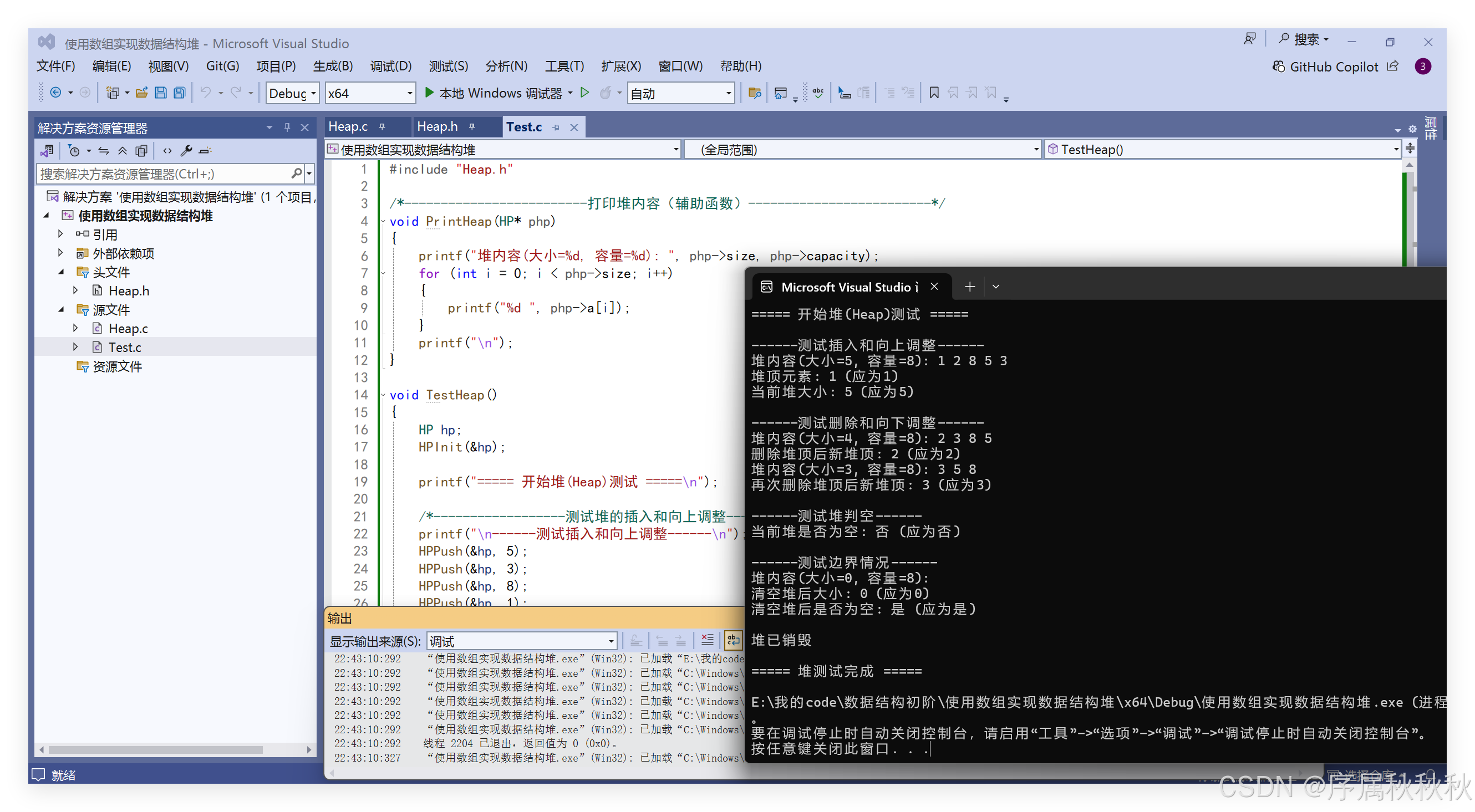
void TestHeap()
{
HP hp;
HPInit(&hp);
printf("===== 开始堆(Heap)测试 =====\n");
/*------------------测试堆的插入和向上调整------------------*/
printf("\n------测试插入和向上调整------\n");
HPPush(&hp, 5);
HPPush(&hp, 3);
HPPush(&hp, 8);
HPPush(&hp, 1);
HPPush(&hp, 2);
PrintHeap(&hp);
printf("堆顶元素: %d (应为1)\n", HPTop(&hp));
printf("当前堆大小: %d (应为5)\n", hp.size);
/*------------------测试堆的删除和向下调整------------------*/
printf("\n------测试删除和向下调整------\n");
HPPop(&hp);
PrintHeap(&hp);
printf("删除堆顶后新堆顶: %d (应为2)\n", HPTop(&hp));
HPPop(&hp);
PrintHeap(&hp);
printf("再次删除堆顶后新堆顶: %d (应为3)\n", HPTop(&hp));
/*------------------测试堆的判空------------------*/
printf("\n------测试堆判空------\n");
printf("当前堆是否为空: %s (应为否)\n", HPEmpty(&hp) ? "是" : "否");
/*------------------测试边界情况------------------*/
printf("\n------测试边界情况------\n");
while (!HPEmpty(&hp))
{
HPPop(&hp);
}
PrintHeap(&hp);
printf("清空堆后大小: %d (应为0)\n", hp.size);
printf("清空堆后是否为空: %s (应为是)\n", HPEmpty(&hp) ? "是" : "否");
/*------------------清理堆------------------*/
HPDestroy(&hp);
printf("\n堆已销毁\n");
printf("\n===== 堆测试完成 =====\n");
}
int main()
{
TestHeap();
return 0;
}运行结果
----------------堆的应用----------------
堆排序
什么是堆排序?
堆排序(Heap Sort):是一种基于二叉堆数据结构 的高效排序算法,利用堆的 最大堆(大 顶/根 堆) 或 最小堆(小 顶/根 堆) 性质,通过反复提取堆顶元素实现排序。堆的性质:
- 大顶堆 :每个父节点的值 ≥ 子节点的值 (堆顶为最大值)
- 小顶堆 :每个父节点的值 ≤ 子节点的值 (堆顶为最小值)
从上面关于大顶堆和小顶堆的性质我们可以发现:堆这种数据结构有一种(微弱的)顺序性:我们可能不知道堆中所有元素的排列顺序,但是我们一定可以确定的是堆顶元素一定就是这些元素中最大或最小的那一个。
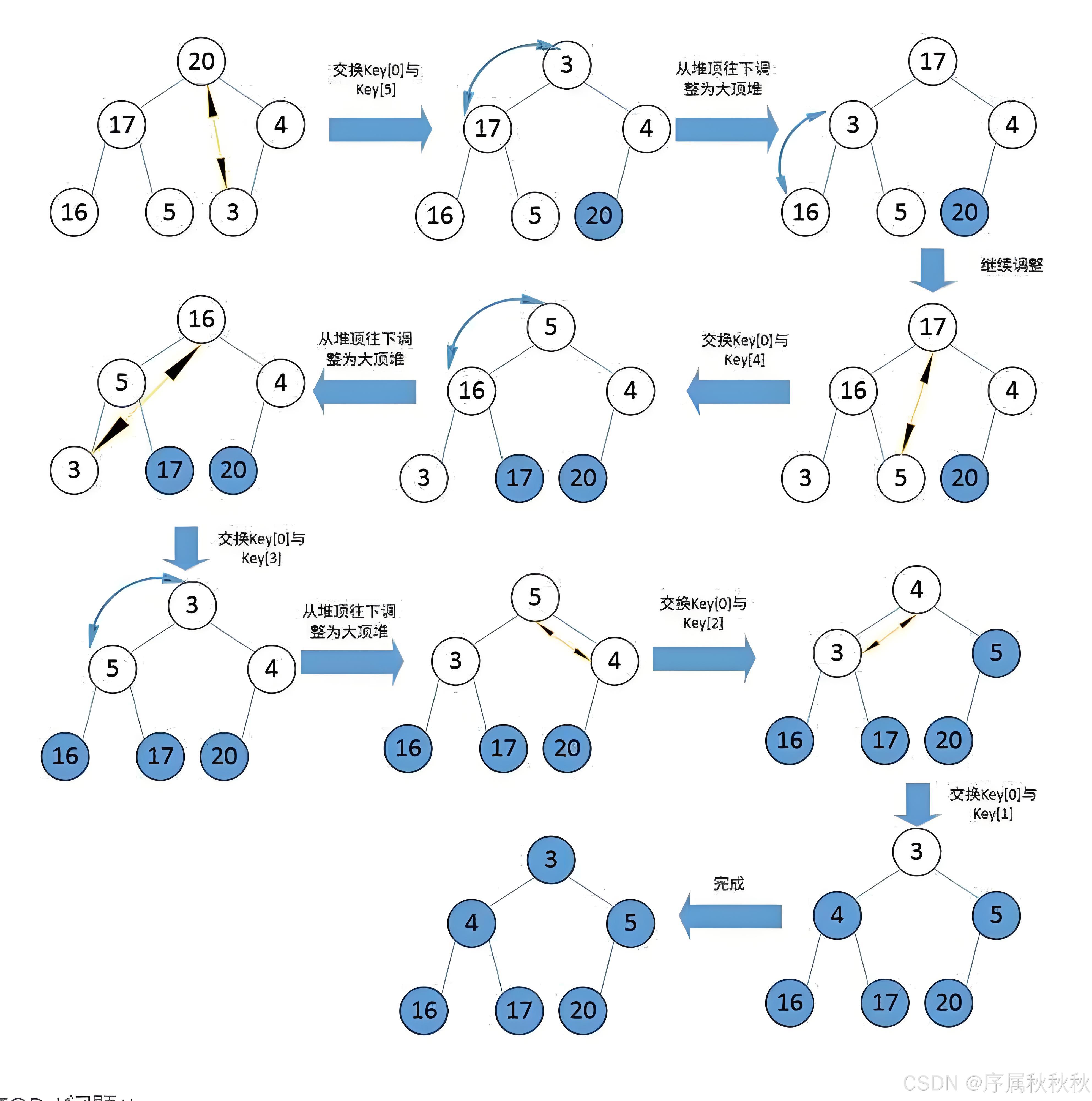
怎么实现堆排序?
堆排序 的核心就两步操作分别是:建堆 和排序,这两步操作会在堆排序中的重复执行。
建堆:将待排序数组构建成一个堆。
- 从最后一个非叶子节点开始,自下而上、从右到左对每个节点进行向下调整,使其满足堆的性质。
排序:将堆顶元素与堆尾元素交换,此时堆尾元素就是当前堆中的最大(大顶堆)或最小(小顶堆)元素。排序策略:
- 升序排序:使用大顶堆,每次将堆顶最大值交换到数组末尾。
- 降序排序:使用小顶堆,每次将堆顶最小值交换到数组末尾。
接下来就是:
- 对堆顶元素所在的子树进行调整,使其重新成为一个堆
- 继续进行排序的操作,将堆顶元素与堆尾元素进行交换
重复这个过程,直到堆中只剩下一个元素,此时数组已经有序。
堆排序的效率和属性?
时间复杂度 :堆排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
- 建堆的时间复杂度为 O ( n ) O(n) O(n),排序过程中每次调整堆的时间复杂度为 O ( l o g n ) O(logn) O(logn),一共需要进行 n − 1 n - 1 n−1次调整,所以总的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
空间复杂度 :堆排序的空间复杂度为 O ( 1 ) O(1) O(1)
- 因为它是在原数组上进行排序,不需要额外的存储空间。
稳定性 :堆排序是一种
不稳定的排序算法,在排序过程中,可能会改变相同元素的相对顺序。
- 例如:在大顶堆中,如果有两个相同的元素,其中一个是堆顶元素,另一个是其兄弟节点,当堆顶元素与堆尾元素交换后,这两个相同元素的相对顺序就可能会改变。
--------------------------------
头文件
c
---------------------------------Heap.h---------------------------------
#pragma once
#include <stdio.h>
typedef int HPSortType;
//任务1:声明堆的常用的工具函数
//1.交换数组中两个元素
//2.堆的向上调整算法(用于插入元素后维护堆的性质)
//3.堆的向下调整算法(用于删除元素后维护堆的性质)
void Swap(HPSortType* a, HPSortType* b);
void AdjustUp(HPSortType* a, int child);
void AdjustDown(HPSortType* a, int parent, int n);
//注意:这里我们使用的这些工具函数的形参不是:堆,;而是:动态数组
//原因:传参时传入动态数组是因为这些工具函数不仅可以用在实现"堆"这种的数据结构上,还可以继续使用在"堆排序"上
//任务2:实现:"堆排序"函数
void Heapsort(HPSortType* arr, int n); 实现文件
c
---------------------------------HeapSort.c---------------------------------
#include "Heap.h"
//1.实现:"交换两个元素的值"工具函数
void Swap(HPSortType* a, HPSortType* b)//形参是是指针类型,函数中的修改会影响到原数组中的值
{
HPSortType tmp = *a;
*a = *b;
*b = tmp;
}
//2.实现:"向上调整算法"工具函数
void AdjustUp(HPSortType* a, int child)
{
//1.计算出父节点在数组中的下标(我们有孩子 ---> 得到双亲)
int parent = child - 1 >> 1;
//2.接下来不断的进行向上调整,何时调整结束? ---> 回答:1.当孩子已经调整成根节点时 2.当孩子不满小堆的性质时(这里我们模拟小根堆)
while (child > 0)
{
//3.使用if-else语句进行小根堆的条件检查(小根堆:谁小谁当爹)
if (a[child] >= a[parent]) return;
else
{
//4.1:交换的孩子节点和双亲节点的值
Swap(&a[child], &a[parent]);
//4.2:更新孩子的索引 ---> 因为我们要为孩子找到一个合适的位置
child = parent;
//4.3:求出现在孩子的双亲节点的索引
parent = child - 1 >> 1;
}
}
}
//3.实现:"向下调整算法"工具函数
void AdjustDown(HPSortType* a, int parent, int n)
{
//1.计算出孩子节点在数组中的下标(我们有双亲节点 ---> 得到"值最小的"孩子)
//这里和向上调整有点不一样:找双亲节点就只有一个,但是找孩子节点有两个,要找哪一个呢?---> 找值最小的孩子
//注:这里使用假设法:假设双亲的左孩子是最小的孩子
int minchild = (parent << 1) + 1;
//2.接下来不断地进行向下调整,何时调整结束 ---> 1.当孩子节点的索引已经大于数组的容量,即:孩子不存在时 2.当孩子不满足小根堆的条件检查时
while (minchild < n)
{
//3.调整出minchild代表是最小的孩子
if (minchild + 1 < n && a[minchild + 1] < a[minchild])
{
minchild++; //切换到右孩子
}
//3.使用if-else语句进行小根堆的条件检查
if (a[minchild] >= a[parent]) return;
else
{
//4.1:交换孩子节点和双亲节点的值
Swap(&a[minchild], &a[parent]);
//4.1:更新双亲节点的索引
parent = minchild;
//4.2:求出现在双亲节点的孩子节点的索引
minchild = (parent << 1) + 1;
}
}
}
//实现:"堆排序"操作
void Heapsort(HPSortType* arr, int n)
{
//1.建堆阶段:(在原数组上进行建堆)
//1)实现:向上调整建堆:时间复杂度O(nlogn)
/*
//强调:这里的i是孩子节点的索引
for (int i = 0; i < n; i++)
{
AdjustUp(arr, i);
}
*/
//2)实现:向下调整建堆:时间复杂度O(n)
//强调:这里的i是双亲节点的索引
for (int i = n - 1 - 1 >> 1; i >= 0; i--)
{
AdjustDown(arr, i, n);
}
//2.排序阶段:(本质是删除堆的堆顶元素)
//2.0:存储堆中最后一个元素的索引
int end = n - 1;
while (end > 0)
{
//2.1:将堆顶元素和末尾元素进行交换
Swap(&arr[0], &arr[end]);
//2.2:更新数组的容量 --- 将堆的末尾的元素删除掉
end--;
//2.3:重新调整堆
AdjustDown(arr, 0, end + 1); //注意:这里的第三个参数:是堆中元素的数量
}
}测试文件
c
--------------------------------Test.c--------------------------------
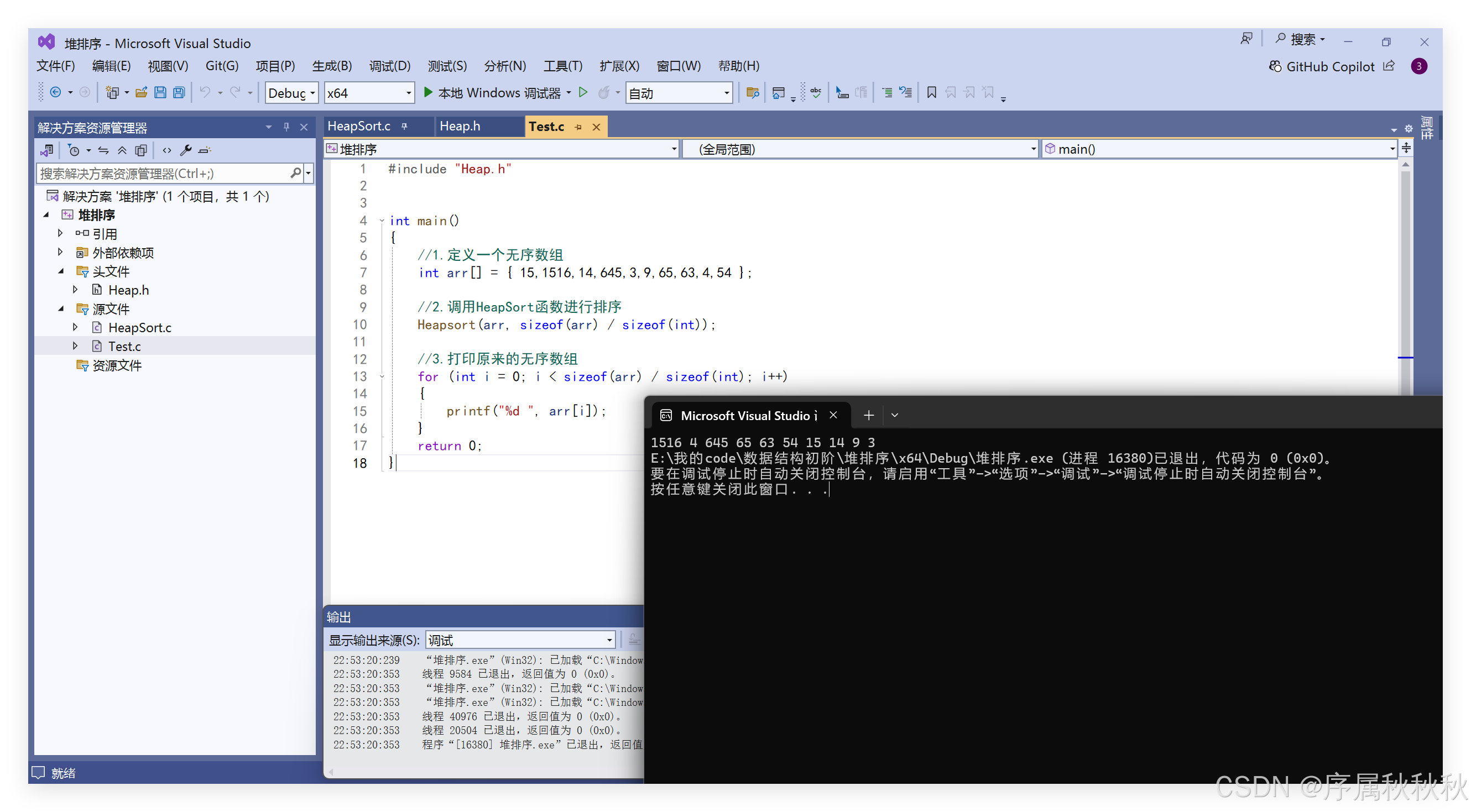
#include "Heap.h"
int main()
{
//1.定义一个无序数组
int arr[] = { 15,1516,14,645,3,9,65,63,4,54 };
//2.调用HeapSort函数进行排序
Heapsort(arr, sizeof(arr) / sizeof(int));
//3.打印原来的无序数组
for (int i = 0; i < sizeof(arr) / sizeof(int); i++)
{
printf("%d ", arr[i]);
}
return 0;
}运行结果
TOP-K问题
什么是TOP-K问题?
TOP-K 问题:是指从一个大规模数据集中快速找出前 K 个最大(或最小)的元素
解决TOP-K问题的思路和实现的步骤?
核心思路:
- 选择堆的类型 :
- 找最大的K个元素 :使用最小堆(堆顶是当前第K大的元素,堆顶为门槛值,便于快速淘汰较小值)
- 找最小的K个元素 :使用最大堆(堆顶是当前第K小的元素,堆顶为门槛值,便于快速淘汰较大值)
- 遍历数据并动态调整堆 :
- 初始时,堆为空或部分填充。
- 遍历每个元素时,将其与堆顶比较:
- 若元素优于堆顶(如更大或更小),则替换堆顶并调整堆。
- 否则,跳过该元素。
- 最终堆中的元素即为所求 :
- 遍历结束后,堆中保存的 K 个元素即为最大或最小的 K 个元素。
实现步骤(以找最大的K个元素为例):
步骤1:初始化最小堆
- 创建一个大小为K的最小堆
- 若数据量小于等于 K,直接返回全部数据
步骤2:遍历数据集中的每个元素并更新堆
若堆未满(元素数 < K):直接插入堆。
若堆满(元素数 = K):
- 若当前元素 > 堆顶,替换堆顶并调整堆(下沉操作)
- 若当前元素 ≤ 堆顶,跳过该元素
遍历结束后,堆中元素即为最大的 K 个元素:
- 堆顶为第 K 大元素,整个堆按小顶堆有序
使用堆解决TOP-K问题的性能怎么样?好处又是什么?
时间复杂度分析
- 构建初始堆的时间复杂度为 O ( K ) O(K) O(K),因为最多需要对 K K K 个元素进行简单的插入操作,每个插入操作的时间复杂度为 O ( 1 ) O(1) O(1)
- 遍历数据集中剩余的 n − K n - K n−K 个元素,对于每个元素,进行一次堆顶元素的比较和可能的替换以及堆调整操作。
- 堆调整操作的时间复杂度为 O ( l o g K ) O(logK) O(logK),因为堆的高度为 l o g K logK logK
- 所以这部分的时间复杂度为 O ( ( n − K ) l o g K ) O((n - K)logK) O((n−K)logK),近似为 O ( n l o g K ) O(nlogK) O(nlogK)
- 总体时间复杂度为 O ( K + n l o g K ) O(K + nlogK) O(K+nlogK),由于在实际应用中 n n n 通常远大于 K K K,所以时间复杂度可以近似看作 O ( n l o g K ) O(nlogK) O(nlogK)
空间复杂度分析
使用堆解决 TOP - K 问题只需要维护一个大小为 K K K 的堆来存储当前的 TOP - K 元素,所以空间复杂度为 O ( K ) O(K) O(K)
使用堆的优点:
高效性时间复杂度为 O ( n l o g K ) O(nlogK) O(nlogK),优于一些简单排序算法如直接排序再取前 K K K 个元素的 O ( n l o g n ) O(nlogn) O(nlogn),在处理大规模数据且 K K K 远小于 n n n 时优势显著。
内存友好只需维护大小为 K K K 的堆,空间复杂度为 O ( K ) O(K) O(K),适合处理海量数据,可处理超出内存容量的数据,无需一次性加载全部数据。
动态适应性数据动态变化时,新数据可方便地与堆顶比较并按需插入调整,无需重新处理整个数据集,能实时更新 TOP - K 元素。
--------------------------------
源文件
c
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
/*****************************************************************
* @brief 测试TopK算法实现(查找最大的前k个数)
* @note 算法核心思想:
* 1. 使用小堆维护当前最大的k个数
* 2. 堆顶始终是这k个数中的最小值
* 3. 遇到更大的数时替换堆顶并调整堆
* 时间复杂度:O(N logK) 空间复杂度:O(K)
* 适用场景:海量数据中查找极值(内存无法容纳全部数据时)
*****************************************************************/
//任务1:实现:"交换两个元素的值"工具函数
void Swap(int* a, int* b)//形参是是指针类型,函数中的修改会影响到原数组中的值
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//任务2:实现:"堆的向下调整的算法"工具函数
void AdjustDown(int* a, int parent, int n)
{
//1.计算出孩子节点在数组中的下标(我们有双亲节点 ---> 得到"值最小的"孩子)
//这里和向上调整有点不一样:找双亲节点就只有一个,但是找孩子节点有两个,要找哪一个呢?---> 找值最小的孩子
//注:这里使用假设法:假设双亲的左孩子是最小的孩子
int minchild = parent << 1 + 1;
//2.接下来不断地进行向下调整,何时调整结束 ---> 1.当孩子节点的索引已经大于数组的容量,即:孩子不存在时 2.当孩子不满足小根堆的条件检查时
while (minchild < n)
{
//3.调整出minchild代表是最小的孩子
if (minchild + 1 < n && a[minchild] > a[minchild + 1])
{
minchild++; //切换到右孩子
}
//3.使用if-else语句进行小根堆的条件检查
if (a[minchild] >= a[parent]) return;
else
{
//4.1:交换孩子节点和双亲节点的值
Swap(&a[minchild], &a[parent]);
//4.1:更新双亲节点的索引
parent = minchild;
//4.2:求出现在双亲节点的孩子节点的索引
minchild = parent << 1 + 1;
}
}
}
//任务3:生成随机的测试数据文件
void CreateData()
{
/*--------------------第一阶段:参数设置--------------------*/
//1.定义数据量的大小
int n = 1e5;
//2.定义数据源文件路径
const char* file = "data.txt";
/*--------------------第二阶段:初始化随机数发生器--------------------*/
srand(time(0));
/*--------------------第三阶段:打开输出文件--------------------*/
FILE* fin = fopen(file, "w");
//2.处理打开失败的情况
if (fin == NULL)
{
perror("file fail");
return;
}
/*--------------------第四阶段:生成数据到文件中--------------------*/
//1.循环生成随机数
for (int i = 0; i < n; i++)
{
/*
1. rand()生成伪随机数
2. 加入循环变量i避免连续重复
3. 取模限制数值范围
*/
int x = (rand() + i) % 10000000; //注意:这里10000000不要写成1e7的形式
//2.将生成的随机数写入到文件中
fprintf(fin, "%d\n", x);
}
/*--------------------第五阶段:资源清理--------------------*/
fclose(fin); //关闭文件
}
//在main函数中实现topK问题的测试
int main()
{
CreateData();
/*--------------------第一阶段:初始化--------------------*/
//1.定义topK的K
int k;
printf("请输入K的值\n");
scanf("%d", &k);
//2.动态创建堆数组(模拟容量是K的小根堆)
//2.1:使用malloc开辟动态空间
int* kminheap = (int*)malloc(k * sizeof(int));
//2.2:处理空间开辟失败的情况
if (kminheap == NULL)
{
perror("malloc fail");
return 0;
}
/*--------------------第二阶段:加载数据--------------------*/
//1.定义数据源文件路径
const char* file = "data.txt";
//2.将文件以只读的模式打开
FILE* fout = fopen(file, "r");
//3.处理文件打开失败的情况
if (fout == NULL)
{
//3.1:输出错误的信息
perror("fopen fail");
//3.2:释放已经分配的内存空间 + 直接进行返回
free(kminheap);
return 0;
}
//4.加载文件中的前K个数到数组
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &kminheap[i]);
}
/*--------------------第三阶段:堆的构建--------------------*/
//使用向下调整堆进行堆的构建操作
for (int i = k - 1 - 1 >> 1; i >= 0; i--)
{
AdjustDown(kminheap, i, k);
}
/*--------------------第三阶段:topK筛选--------------------*/
//1.存储从文件中读到的数据
int x = 0;
//2.逐行从文件中读取剩余的数据 (直到读到文件结束符)
while (fscanf(fout, "%d", &x) > 0)
{
//3.将大于小根堆堆顶的元素添加到堆中
if (x > kminheap[0])
{
//3.1:替换堆顶元素
kminheap[0] = x;
//3.2:调整堆的结构
AdjustDown(kminheap, 0, k);
}
}
/*--------------------第三阶段:输出结果--------------------*/
printf("最大的前K个元素是:\n");
for (int i = 0; i < k; i++)
{
printf("%d ", kminheap[i]);
}
printf("\n");
/*--------------------第三阶段: 资源释放--------------------*/
free(kminheap); //释放堆内存
fclose(fout); //关闭文件
return 0;
}运行结果
TOP-K
