复习日
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
就是很简单很草率地走了一遍机器学习的经典流程,其实数据还可以提取新特征,但懒得搞了,特征也少不需要降维。就是这个项目本身就分了训练集和测试集,需要注意一下数据预处理跟之前不太一样
python
# 导入相关库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from sklearn.ensemble import RandomForestClassifier
from skopt import BayesSearchCV
from skopt.space import Integer, Categorical
import time
import shap
python
# 读取数据
train_data = pd.read_csv('/kaggle/input/titanic/train.csv')
test_data = pd.read_csv('/kaggle/input/titanic/test.csv')分别执行吧,就不放结果图了
python
train_data.head()
train_data.info()
train_data.isnull().sum()
test_data.isnull().sum()
train_data.describe() # 看看数值型数据的分布
train_data.describe(include=['O']) # 看看对象型数据的分布
train_data.groupby(['Sex'], as_index=False)['Survived'].mean() # 很显然性别跟存活率有关
train_data.groupby(['Pclass'], as_index=False)['Survived'].mean() # 票价等级越高存活率越高
train_data.groupby(['Age'], as_index=False)['Survived'].mean()
# 年龄这个不太好看,还是画图吧
sns.histplot(train_data, x='Age',hue='Survived', multiple='dodge') # 婴儿、80岁左右老年人和年轻人存活率高点可以看看每个特征与最后标签的相关性来确定是否需要去除,这里只看了几个特征,最后直接根据特征的含义评判了,数据探索还可以再多一点数据可视化一下更明确,这里的处理其实蛮粗糙的,比如名字还可以看出头衔阶层啥的对吧,和幸存率可能还是有关系的(
- Age、Sex 年龄性别特征肯定与幸存相关;
- Pclass 票价等级也和幸存有关
- Embarked 登船港口可能与幸存或其他重要特征相关;
- Ticket 票号包含较高重复率(22%),并且和幸存之间可能没有相关性,因此可能会从我们的分析中删除;
- Cabin 客舱号可能被丢弃,因为它在训练和测试集中缺失值过多(数据高度不完整);
- PassengerId 乘客编号可能会从训练数据集中删除,因为它对幸存没有作用;
- Name 名字特征比较不规范,可能也对幸存没有直接贡献,因此可能会被丢弃。
下面是数据预处理
python
PassengerId = test_data["PassengerId"] # 保存ID便于提交
# 清除无用特征
cols_to_drop = ['PassengerId', 'Name', 'Ticket', 'Cabin']
train_data = train_data.drop([col for col in cols_to_drop if col in train_data.columns], axis=1)
test_data = test_data.drop([col for col in cols_to_drop if col in test_data.columns], axis=1)
# 缺失值处理一下
train_data['Embarked'].fillna(train_data['Embarked'].mode()[0], inplace=True)
train_data['Age'].fillna(train_data['Age'].median(), inplace=True)
test_data['Age'].fillna(test_data['Age'].median(), inplace=True)
test_data['Fare'].fillna(test_data['Fare'].median(), inplace=True)
# 离散变量编码
train_data = pd.get_dummies(train_data, columns=['Embarked'])
train_data2 = pd.read_csv('/kaggle/input/titanic/train.csv')
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in train_data.columns:
if i not in train_data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
train_data[i] = train_data[i].astype(int) # 这里的i就是独热编码后的特征名
test_data = pd.get_dummies(test_data, columns=['Embarked'])
test_data2 = pd.read_csv('/kaggle/input/titanic/test.csv')
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in test_data.columns:
if i not in test_data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
test_data[i] = test_data[i].astype(int) # 这里的i就是独热编码后的特征名
sex_mapping = {
'male':1,
'female':0,
}
train_data['Sex'] = train_data['Sex'].map(sex_mapping)
test_data['Sex'] = test_data['Sex'].map(sex_mapping)数据集不用划分,直接训练
python
X_train = train_data.drop(['Survived'], axis=1) # 特征,axis=1表示按列删除
y_train = train_data['Survived'] # 标签
X_test = test_data.copy() # 特征
python
# --- 1. 默认参数的随机森林 ---
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
acc_rf = round(rf_model.score(X_train, y_train) * 100, 2) # 看不了测试集的评估指标那就看看训练集的
print(f'训练集分类准确率:{acc_rf}')
python
# --- 2. 贝叶斯优化调参的随机森林 ---
print("--- 2. 贝叶斯优化调参的随机森林 (训练集 -> 测试集) ---")
param_space = {
'n_estimators': (50, 500), # 树的数量(50~500)
'max_depth': (3, 15), # 树的最大深度(3~15)
'min_samples_split': (2, 10), # 分裂所需最小样本数(2~10)
'min_samples_leaf': (1, 5), # 叶节点最小样本数(1~5)
'max_features': ['sqrt', 'log2'], # 特征选择方式
'bootstrap': [True, False] # 是否使用bootstrap采样
}
# 定义优化器(迭代50次)
opt = BayesSearchCV(
estimator=RandomForestClassifier(random_state=42),
search_spaces=param_space,
n_iter=50, # 迭代次数
cv=5, # 5折交叉验证
scoring='accuracy', # 优化目标(准确率)
random_state=42,
n_jobs=-1 # 使用所有CPU核心
)
start_time = time.time()
opt.fit(X_train, y_train) # 执行贝叶斯优化
best_rf = opt.best_estimator_
rf_pred_opt = best_rf.predict(X_test)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.2f} 秒")
print(f"最佳参数: {opt.best_params_}")
acc_rf_opt = round(best_rf.score(X_train, y_train) * 100, 2)
print(f'优化后训练集准确率: {acc_rf_opt}%')最后还是用shap看看吧
python
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer.shap_values(X_test)
shap_values
python
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[0], X_test, plot_type="bar",show=False)
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()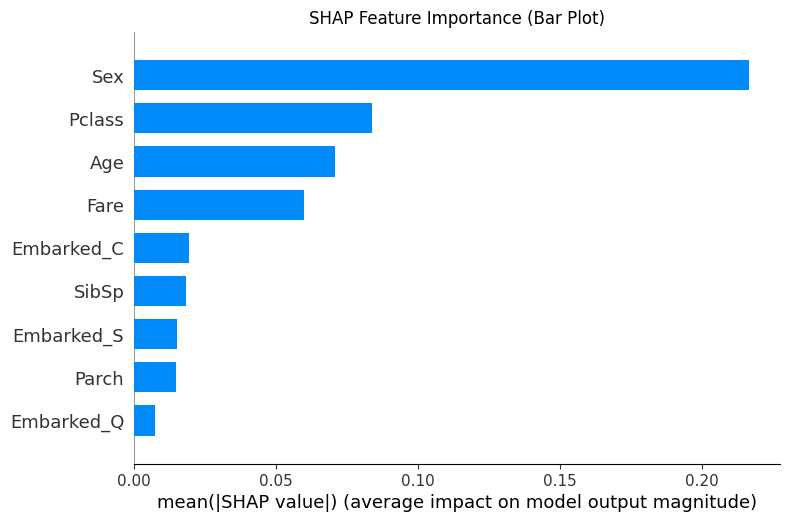
python
# --- 2. SHAP 特征重要性蜂巢图 (Summary Plot - Violin) ---
print("--- 2. SHAP 特征重要性蜂巢图 ---")
shap.summary_plot(shap_values[0], X_test,plot_type="violin",show=False,max_display=10)
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()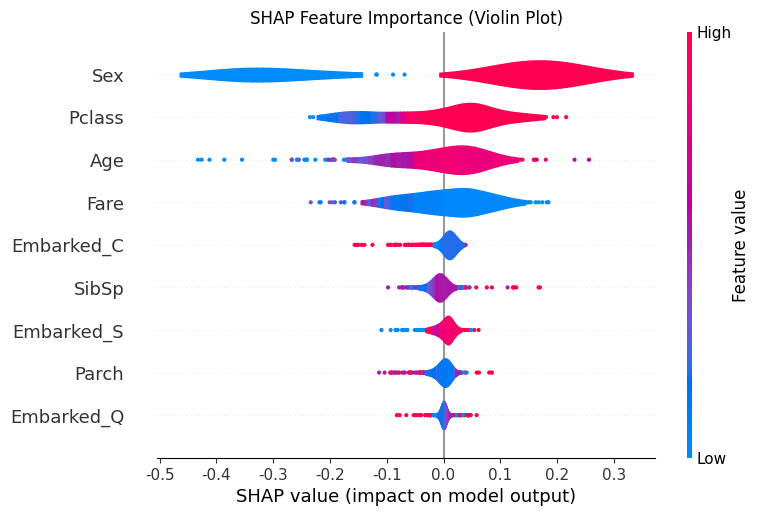
保存csv文件,调参谦和调参后都提交了一下做对比,还是贝叶斯优化后准确率高点
python
submission = pd.DataFrame({
"PassengerId": PassengerId,
"Survived": rf_pred
})
submission.to_csv('./submission.csv', index=False)
print("Your submission was successfully saved!")
submission2 = pd.DataFrame({
"PassengerId": PassengerId,
"Survived": rf_pred_opt
})
submission2.to_csv('./submission2.csv', index=False)
print("Your submission was successfully saved!")