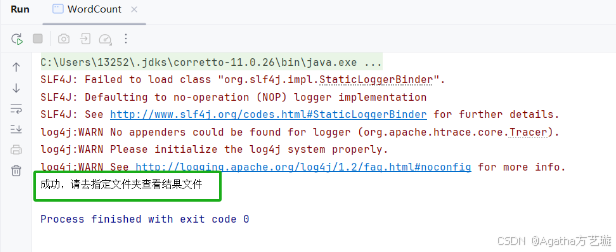
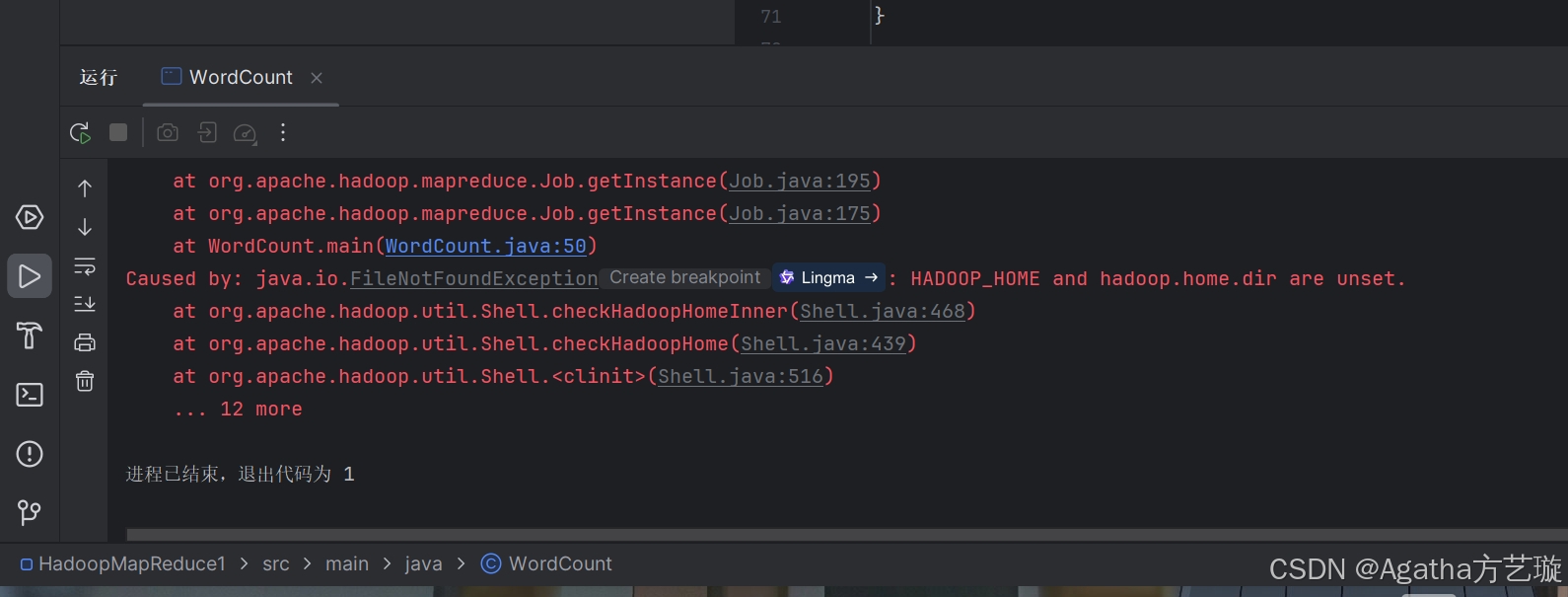
运行课程讲解内容出现这个报错:
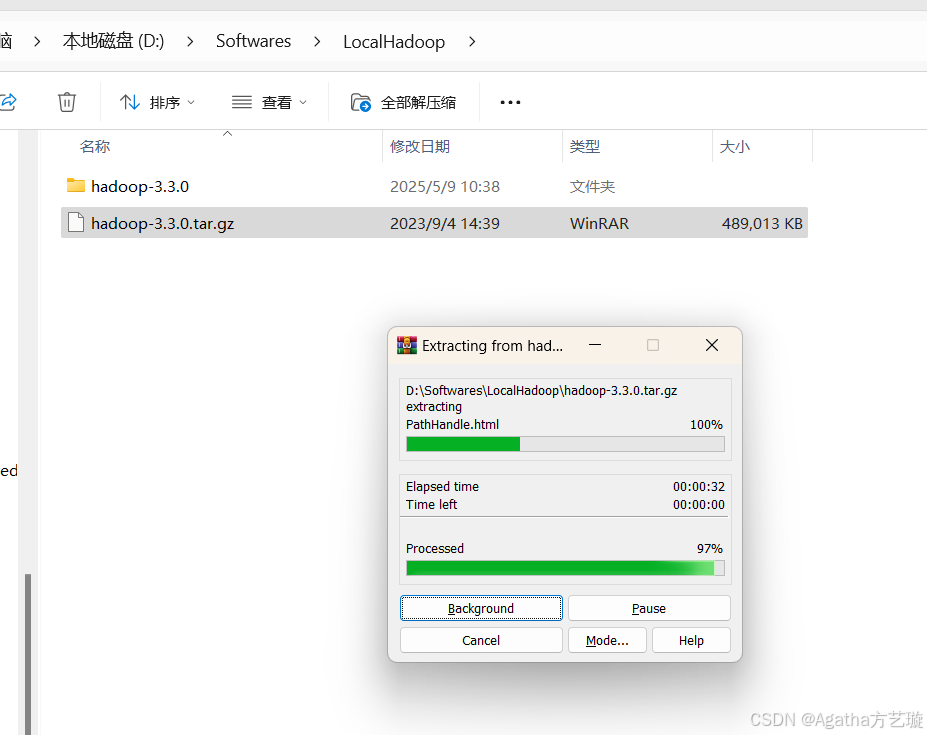
1、在电脑里解压之前发过的Hadoop安装包
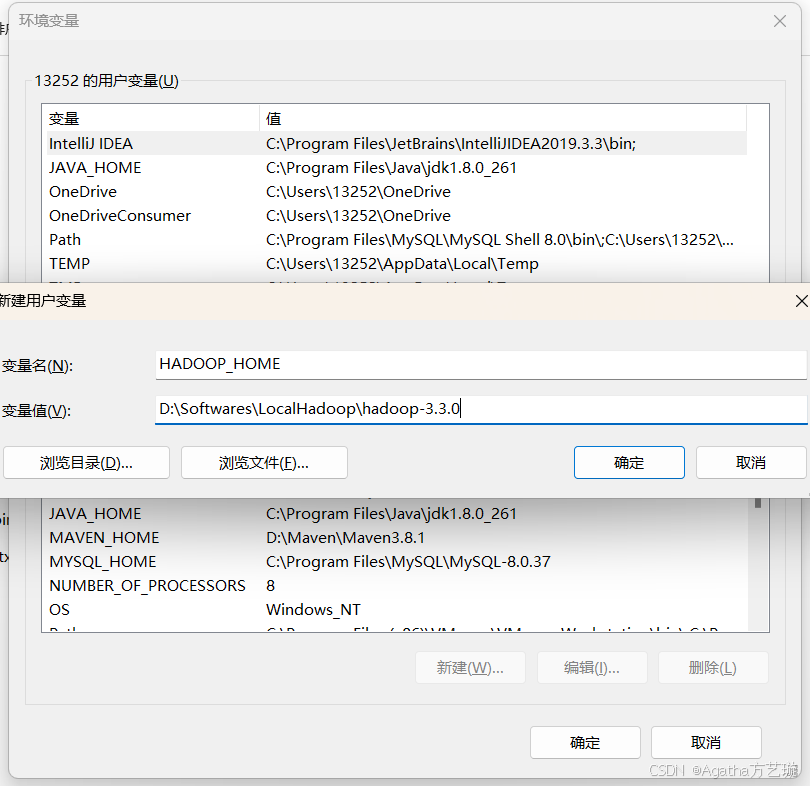
2、配置用户变量
3、配置系统变量
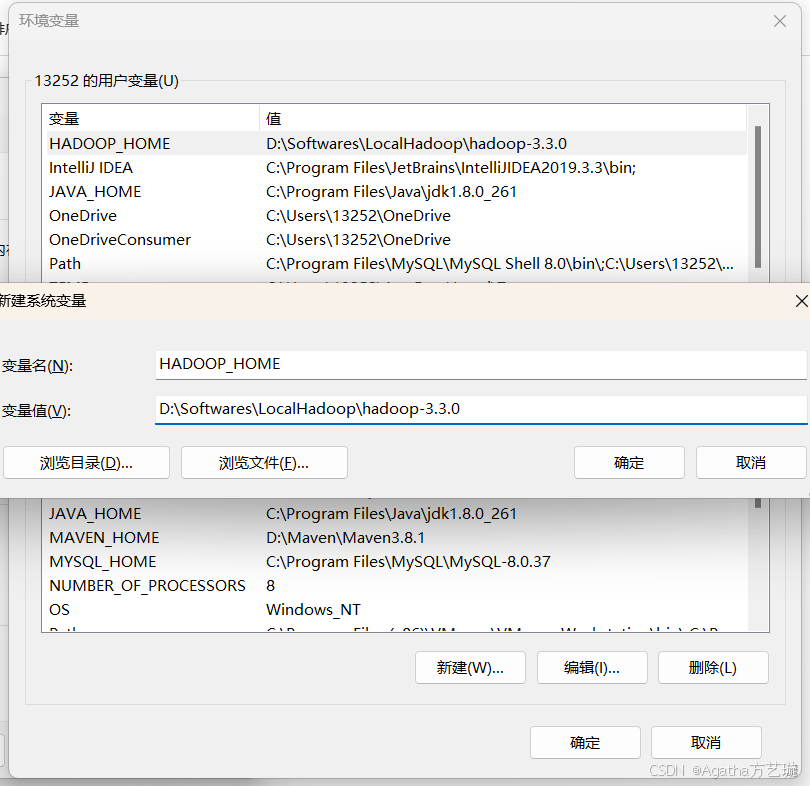
4、配置系统Path变量
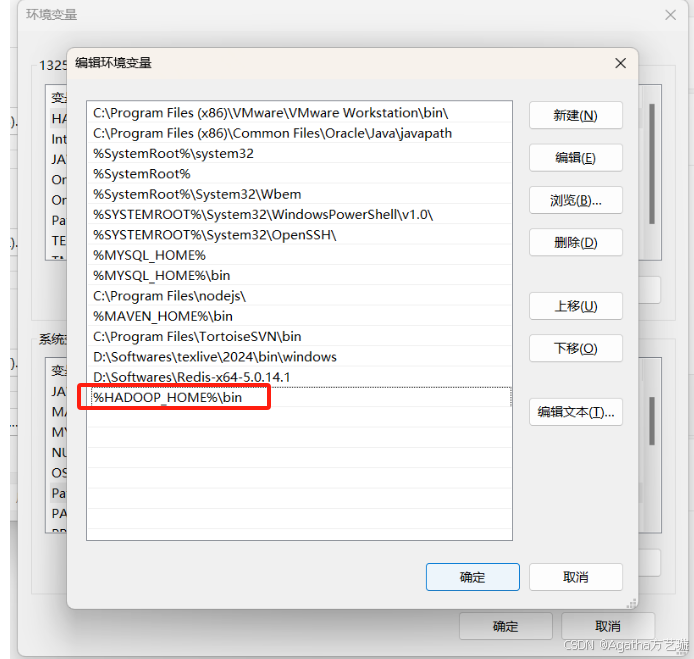
5、下载链接的两个文件:
链接: https://pan.baidu.com/s/1aCcpGGR1EE4hEZW624rFmQ?pwd=56tv 提取码: 56tv
--来自百度网盘超级会员v7的分享
6、放到刚刚解压路径的bin文件夹里
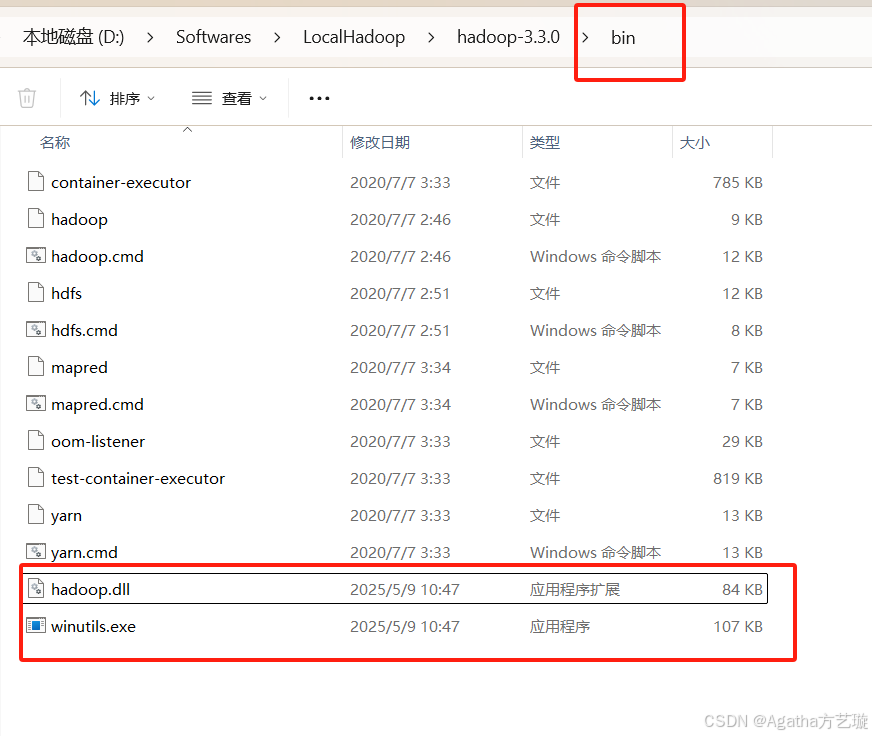
7、再把hadoop.dll复制一份放C:Windows\System32里

8、重启idea
9、再运行代码就可以了