一、软件介绍
文末提供程序和源码下载
ebook2audiobook开源程序使用动态 AI 模型和语音克隆将电子书转换为带有章节和元数据的有声读物。支持 1,107+ 种语言。从电子书到带有章节和元数据的有声读物的 CPU/GPU 转换器,使用 XTTSv2、Bark、Vits、Fairseq、YourTTS 等。支持语音克隆和 +1110 种语言!
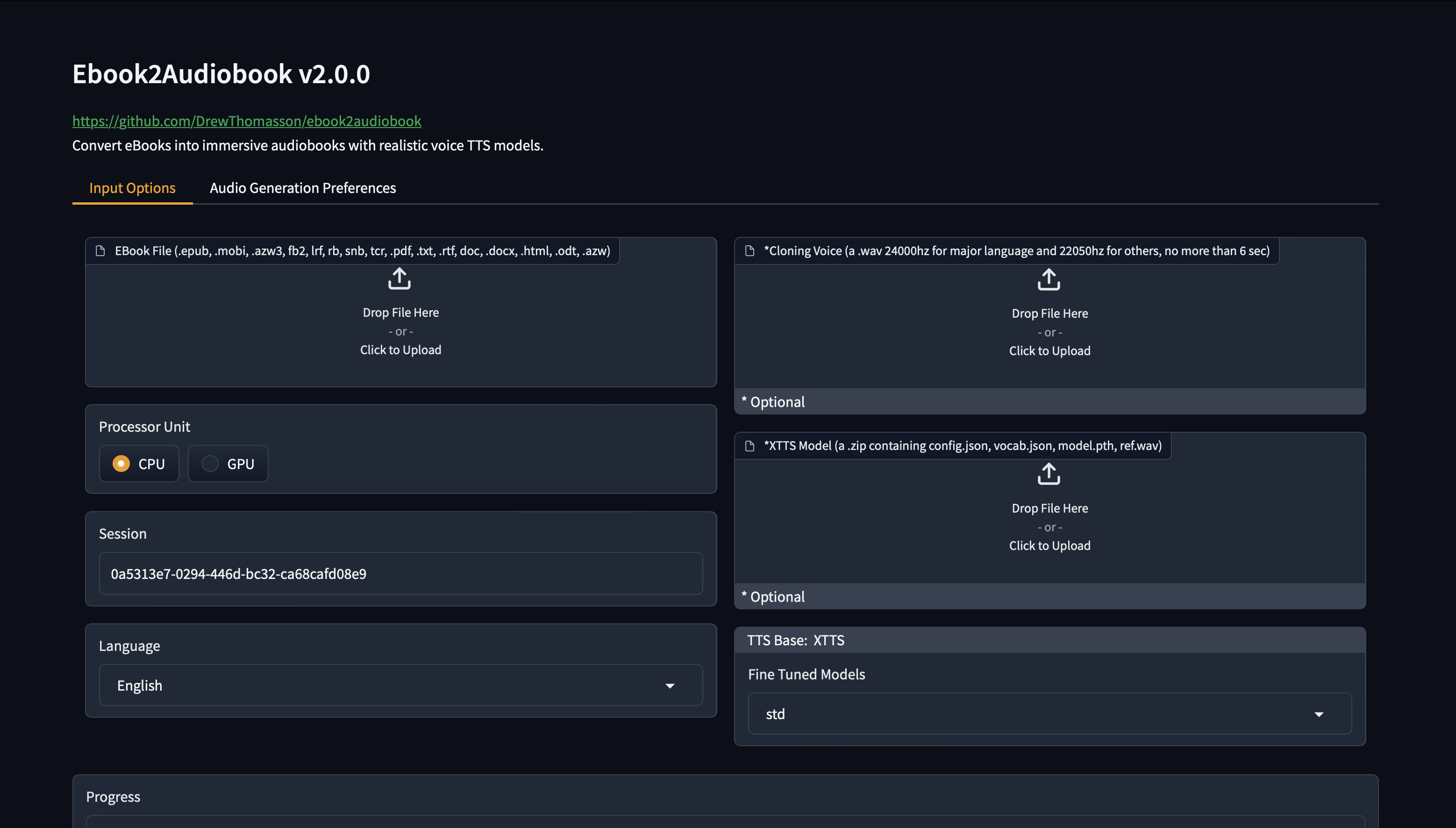
二、Features 特征
- 📚 Splits eBook into chapters for organized audio.
📚 将电子书拆分为多个章节,以便有组织的音频。 - 🎙️ High-quality text-to-speech with Coqui XTTSv2 and Fairseq (and more).
🎙️ 使用 Coqui XTTSv2 和 Fairseq(以及更多)实现高质量的文本转语音。 - 🗣️ Optional voice cloning with your own voice file.
🗣️ 使用您自己的语音文件进行可选的语音克隆。 - 🌍 Supports +1110 languages (English by default). List of Supported languages
🌍 支持 +1110 种语言(默认为英语)。支持的语言列表 - 🖥️ Designed to run on 4GB RAM.
🖥️ 设计为在 4GB RAM 上运行。
Supported Languages 支持的语言
| Arabic (ar) 阿拉伯语 (ar) | Chinese (zh) 中文 (zh) | English (en) 英语 (en) | Spanish (es) 英语 (en) |
|---|---|---|---|
| French (fr) 法语 (fr) | German (de) 德语 (de) | Italian (it) 意大利语 (it) | Portuguese (pt) 葡萄牙语 (pt) |
| Polish (pl) 波兰语 (pl) | Turkish (tr) 土耳其语 (tr) | Russian (ru) 俄语 (ru) | Dutch (nl) 荷兰语 (nl) |
| Czech (cs) 捷克语 (cs) | Japanese (ja) 日语 (ja) | Hindi (hi) 印地语 (hi) | Bengali (bn) 孟加拉语 (bn) |
| Hungarian (hu) 匈牙利语 (胡) | Korean (ko) 韩语 (ko) | Vietnamese (vi) 越南语 (vi) | Swedish (sv) 瑞典语 (sv) |
| Persian (fa) 波斯语 (fa) | Yoruba (yo) 约鲁巴语 (yo) | Swahili (sw) 斯瓦希里语 (sw) | Indonesian (id) 印度尼西亚语 (id) |
| Slovak (sk) 斯洛伐克语 (sk) | Croatian (hr) 克罗地亚语 (hr) | Tamil (ta) 泰米尔语 (ta) | Danish (da) 丹麦语 (da) |
三、Hardware Requirements 硬件要求
- 4gb RAM minimum, 8GB recommended
最低 4GB RAM,推荐 8GB - Virtualization enabled if running on windows (Docker only)
如果在 Windows 上运行,则启用虚拟化(仅限 Docker) - CPU (intel, AMD, ARM), GPU (Nvidia, AMD*, Intel*) (Recommended), MPS (Apple Silicon CPU) *available very soon
CPU(英特尔、AMD、ARM)、GPU(Nvidia、AMD*、Intel*)(推荐)、MPS(Apple Silicon CPU)*即将推出
四、安装说明
- Clone repo 克隆存储库(下载很慢的话,文末提供网盘下载)
git clone https://github.com/DrewThomasson/ebook2audiobook.git
cd ebook2audiobookLaunching Gradio Web Interface
启动 Gradio Web 界面
-
Run ebook2audiobook: 运行 ebook2audiobook:
-
Linux/MacOS Linux/MacOS作系统
./ebook2audiobook.sh # Run launch script -
Mac Launcher Mac 启动器
Double click
Mac Ebook2Audiobook Launcher.command双击Mac Ebook2Audiobook Launcher.command -
Windows 窗户
ebook2audiobook.cmd # Run launch script or double click on it -
Windows Launcher Windows 启动器
Double click
ebook2audiobook.cmd双击ebook2audiobook.cmd -
Manual Python Install 手动安装 Python
REQUIRED_PROGRAMS=("calibre" "ffmpeg" "nodejs" "mecab" "espeak-ng" "rust" "sox") REQUIRED_PYTHON_VERSION="3.12" pip install -r requirements.txt # Install Python Requirements python app.py # Run Ebook2Audiobook
-
-
Open the Web App : Click the URL provided in the terminal to access the web app and convert eBooks.
http://localhost:7860/打开 Web 应用程序:单击终端中提供的 URL 以访问 Web 应用程序并转换电子书。
http://localhost:7860/ -
For Public Link :
python app.py --share(all OS)./ebook2audiobook.sh --share(Linux/MacOS)ebook2audiobook.cmd --share(Windows)对于公共链接:
python app.py --share(所有作系统)./ebook2audiobook.sh --share(Linux/MacOS)ebook2audiobook.cmd --share(Windows)
Important 重要
If the script is stopped and run again, you need to refresh your gradio GUI interface
如果脚本已停止并再次运行,则需要刷新 gradio GUI 界面
to let the web page reconnect to the new connection socket.
让网页重新连接到新的连接套接字。
五、Basic Usage 基本用法
-
Linux/MacOS: Linux/MacOS:
./ebook2audiobook.sh --headless --ebook <path_to_ebook_file> \ --voice [path_to_voice_file] --language [language_code] -
Windows 窗户
ebook2audiobook.cmd --headless --ebook <path_to_ebook_file> --voice [path_to_voice_file] --language [language_code] -
--ebook : Path to your eBook file
--ebook:您的 eBook 文件的路径
-
--voice : Voice cloning file path (optional)
--voice:语音克隆文件路径(可选)
-
--language : Language code in ISO-639-3 (i.e.: ita for italian, eng for english, deu for german...).
--language:ISO-639-3 中的语言代码(即:ita 代表意大利语,eng 代表英语,deu 代表德语......
Default language is eng and --language is optional for default language set in ./lib/lang.py.
默认语言为 eng,对于 ./lib/lang.py 中设置的默认语言,--language 是可选的。
The ISO-639-1 2 letters codes are also supported.
还支持 ISO-639-1 2 字母代码。
Example of Custom Model Zip Upload
自定义模型 zip 上传示例
(must be a .zip file containing the mandatory model files. Example for XTTS: config.json, model.pth, vocab.json and ref.wav)
(必须是包含必需模型文件的 .zip 文件。XTTS 示例:config.json、model.pth、vocab.json 和 ref.wav)
-
Linux/MacOS Linux/MacOS作系统
./ebook2audiobook.sh --headless --ebook <ebook_file_path> \ --voice <target_voice_file_path> --language <language> --custom_model <custom_model_path> -
Windows 窗户
ebook2audiobook.cmd --headless --ebook <ebook_file_path> \ --voice <target_voice_file_path> --language <language> --custom_model <custom_model_path> -
<custom_model_path> : Path to
model_name.zipfile, which must contain (according to the tts engine) all the mandatory files
:model_name.zip文件的路径,必须包含(根据 tts 引擎)所有必需的文件
(see ./lib/models.py). (参见 ./lib/models.py)。
For Detailed Guide with list of all Parameters to use
有关详细指南,其中包含要使用的所有参数的列表
-
Linux/MacOS Linux/MacOS作系统
./ebook2audiobook.sh --help -
Windows 窗户
ebook2audiobook.cmd --help -
Or for all OS
python app.py --help
或适用于所有作系统python app.py --help
usage: app.py [-h] [--script_mode SCRIPT_MODE] [--session SESSION] [--share]
[--headless] [--ebook EBOOK] [--ebooks_dir EBOOKS_DIR]
[--language LANGUAGE] [--voice VOICE] [--device {cpu,gpu,mps}]
[--tts_engine {xtts,bark,vits,fairseq,yourtts}]
[--custom_model CUSTOM_MODEL] [--fine_tuned FINE_TUNED]
[--output_format OUTPUT_FORMAT] [--temperature TEMPERATURE]
[--length_penalty LENGTH_PENALTY] [--num_beams NUM_BEAMS]
[--repetition_penalty REPETITION_PENALTY] [--top_k TOP_K] [--top_p TOP_P]
[--speed SPEED] [--enable_text_splitting] [--output_dir OUTPUT_DIR]
[--version]
Convert eBooks to Audiobooks using a Text-to-Speech model. You can either launch the Gradio interface or run the script in headless mode for direct conversion.
options:
-h, --help show this help message and exit
--session SESSION Session to resume the conversion in case of interruption, crash,
or reuse of custom models and custom cloning voices.
**** The following option are for gradio/gui mode only:
Optional
--share Enable a public shareable Gradio link.
**** The following options are for --headless mode only:
--headless Run the script in headless mode
--ebook EBOOK Path to the ebook file for conversion. Cannot be used when --ebooks_dir is present.
--ebooks_dir EBOOKS_DIR
Relative or absolute path of the directory containing the files to convert.
Cannot be used when --ebook is present.
--language LANGUAGE Language of the e-book. Default language is set
in ./lib/lang.py sed as default if not present. All compatible language codes are in ./lib/lang.py
optional parameters:
--voice VOICE (Optional) Path to the voice cloning file for TTS engine.
Uses the default voice if not present.
--device {cpu,gpu,mps}
(Optional) Pprocessor unit type for the conversion.
Default is set in ./lib/conf.py if not present. Fall back to CPU if GPU not available.
--tts_engine {xtts,bark,vits,fairseq,yourtts}
(Optional) Preferred TTS engine (available are: ['xtts', 'bark', 'vits', 'fairseq', 'yourtts'].
Default depends on the selected language. The tts engine should be compatible with the chosen language
--custom_model CUSTOM_MODEL
(Optional) Path to the custom model zip file cntaining mandatory model files.
Please refer to ./lib/models.py
--fine_tuned FINE_TUNED
(Optional) Fine tuned model path. Default is builtin model.
--output_format OUTPUT_FORMAT
(Optional) Output audio format. Default is set in ./lib/conf.py
--temperature TEMPERATURE
(xtts only, optional) Temperature for the model.
Default to config.json model. Higher temperatures lead to more creative outputs.
--length_penalty LENGTH_PENALTY
(xtts only, optional) A length penalty applied to the autoregressive decoder.
Default to config.json model. Not applied to custom models.
--num_beams NUM_BEAMS
(xtts only, optional) Controls how many alternative sequences the model explores. Must be equal or greater than length penalty.
Default to config.json model.
--repetition_penalty REPETITION_PENALTY
(xtts only, optional) A penalty that prevents the autoregressive decoder from repeating itself.
Default to config.json model.
--top_k TOP_K (xtts only, optional) Top-k sampling.
Lower values mean more likely outputs and increased audio generation speed.
Default to config.json model.
--top_p TOP_P (xtts only, optional) Top-p sampling.
Lower values mean more likely outputs and increased audio generation speed. Default to 0.85
--speed SPEED (xtts only, optional) Speed factor for the speech generation.
Default to config.json model.
--enable_text_splitting
(xtts only, optional) Enable TTS text splitting. This option is known to not be very efficient.
Default to config.json model.
--output_dir OUTPUT_DIR
(Optional) Path to the output directory. Default is set in ./lib/conf.py
--version Show the version of the script and exit
Example usage:
Windows:
Gradio/GUI:
ebook2audiobook.cmd
Headless mode:
ebook2audiobook.cmd --headless --ebook '/path/to/file'
Linux/Mac:
Gradio/GUI:
./ebook2audiobook.sh
Headless mode:
./ebook2audiobook.sh --headless --ebook '/path/to/file'NOTE: in gradio/gui mode, to cancel a running conversion, just click on the X from the ebook upload component.
注意:在 gradio/gui 模式下,要取消正在运行的转换,只需单击电子书上传组件中的 X 即可。
Docker GPU Options Docker GPU 选项
Available tags: latest (CUDA 11), cpu, rocm, cuda11, cuda12, cuda128, xpu (x86 only)
可用标签: latest (CUDA 11)、 cpu 、 rocm cuda11 cuda12 cuda128 xpu (仅限 x86)
Running the Docker Container
运行 Docker 容器
To run the Docker container and start the Gradio interface, use the following command:
要运行 Docker 容器并启动 Gradio 接口,请使用以下命令:
-Run with CPU only
- 仅使用 CPU 运行
docker run --pull always --rm -p 7860:7860 athomasson2/ebook2audiobook-Run with GPU Speedup (NVIDIA compatible only)
- 使用 GPU 加速运行(仅兼容 NVIDIA)
docker run --pull always --rm --gpus all -p 7860:7860 athomasson2/ebook2audiobookBuilding the Docker Container
构建 Docker 容器
- You can build the docker image with the command:
您可以使用以下命令构建 docker 镜像:
docker build -t athomasson2/ebook2audiobook .This command will start the Gradio interface on port 7860.(localhost:7860)
此命令将在端口 7860 上启动 Gradio 接口。(本地主机:7860)
- For more options add the parameter
--help
有关更多选项,请添加参数--help
Docker container file locations
Docker 容器文件位置
All ebook2audiobooks will have the base dir of /app/ For example: tmp = /app/tmp audiobooks = /app/audiobooks
所有 ebook2audiobooks 的基本目录均为 /app/ 例如: tmp = /app/tmp audiobooks = /app/audiobooks
Docker headless guide Docker 无头指南
- Before you do run this you need to create a dir named "input-folder" in your current dir which will be linked, This is where you can put your input files for the docker image to see
在运行此命令之前,您需要在当前目录中创建一个名为"input-folder"的目录,该目录将被链接,这是您可以放置输入文件供 docker 映像查看的地方
mkdir input-folder && mkdir Audiobooks- In the command below swap out YOUR_INPUT_FILE.TXT with the name of your input file
在下面的命令中,将 YOUR_INPUT_FILE.TXT 替换为输入文件的名称
docker run --pull always --rm \
-v $(pwd)/input-folder:/app/input_folder \
-v $(pwd)/audiobooks:/app/audiobooks \
athomasson2/ebook2audiobook \
--headless --ebook /input_folder/YOUR_EBOOK_FILE- The output Audiobooks will be found in the Audiobook folder which will also be located in your local dir you ran this docker command in
输出有声读物将在 Audiobook 文件夹中找到,该文件夹也位于您运行此 docker 命令的本地目录中
To get the help command for the other parameters this program has you can run this
要获取该程序具有的其他参数的 help 命令,您可以运行此命令
docker run --pull always --rm athomasson2/ebook2audiobook --helpThat will output this Help command output
这将输出此 Help 命令输出
Docker Compose
This project uses Docker Compose to run locally. You can enable or disable GPU support by setting either *gpu-enabled or *gpu-disabled in docker-compose.yml
此项目使用 Docker Compose 在本地运行。您可以通过在 *gpu-enabled *gpu-disabled docker-compose.yml
Steps to Run 运行步骤
-
Clone the Repository (if you haven't already):
克隆存储库(如果尚未克隆):git clone https://github.com/DrewThomasson/ebook2audiobook.git cd ebook2audiobook -
Set GPU Support (disabled by default) To enable GPU support, modify
docker-compose.ymland change*gpu-disabledto*gpu-enabled
设置 GPU 支持(默认处于禁用状态)要启用 GPU 支持,请修改docker-compose.yml并更改为*gpu-disabled*gpu-enabled -
Start the service: 启动服务:
docker-compose up -d -
Access the service: The service will be available at http://localhost:7860.
访问服务:该服务将在 http://localhost:7860 提供。
Common Docker Issues 常见的 Docker 问题
-
python: can't open file '/home/user/app/app.py': [Errno 2] No such file or directory(Just remove all post arguments as I replaced theCMDwithENTRYPOINTin the Dockerfile)
python: can't open file '/home/user/app/app.py': [Errno 2] No such file or directory(只需删除所有 post 参数,因为我在 Dockerfile 中替换了CMDwithENTRYPOINT)- Example:
docker run --pull always athomasson2/ebook2audiobook app.py --script_mode full_docker- > corrected - >docker run --pull always athomasson2/ebook2audiobook
示例:docker run --pull always athomasson2/ebook2audiobook app.py --script_mode full_docker- 已更正> - >docker run --pull always athomasson2/ebook2audiobook - Arguments can be easily added like this now
docker run --pull always athomasson2/ebook2audiobook --share
现在可以docker run --pull always athomasson2/ebook2audiobook --share像这样轻松添加参数
- Example:
-
Docker gets stuck downloading Fine-Tuned models. (This does not happen for every computer but some appear to run into this issue) Disabling the progress bar appears to fix the issue, as discussed here in #191 Example of adding this fix in the
docker runcommandDocker 在下载 Fine-Tuned 模型时遇到困难。(并非每台计算机都会发生这种情况,但有些计算机似乎会遇到此问题)禁用进度条似乎可以解决问题,如 #191 在
docker run命令中添加此修复程序的示例中所述
docker run --pull always --rm --gpus all -e HF_HUB_DISABLE_PROGRESS_BARS=1 -e HF_HUB_ENABLE_HF_TRANSFER=0 \
-p 7860:7860 athomasson2/ebook2audiobookSupported eBook Formats 支持的电子书格式
.epub,.pdf,.mobi,.txt,.html,.rtf,.chm,.lit,.pdb,.fb2,.odt,.cbr,.cbz,.prc,.lrf,.pml,.snb,.cbc,.rb,.tcr- Best results :
.epubor.mobifor automatic chapter detection
最佳结果:.epub或.mobi用于自动章节检测
Output Formats 输出格式
- Creates a
['m4b', 'm4a', 'mp4', 'webm', 'mov', 'mp3', 'flac', 'wav', 'ogg', 'aac'](set in ./lib/conf.py) file with metadata and chapters.
创建一个['m4b', 'm4a', 'mp4', 'webm', 'mov', 'mp3', 'flac', 'wav', 'ogg', 'aac']包含元数据和章节的(在 ./lib/conf.py 中设置)文件。
六、软件下载
本文信息来源于GitHub作者地址:https://github.com/DrewThomasson/ebook2audiobook