Spark on YARN(Yet Another Resource Negotiator)是 Spark 框架在 Hadoop 集群中运行的一种部署模式,它借助 Hadoop YARN 来管理资源和调度任务。
架构组成:
ResourceManager:作为 YARN 的核心,负责整个集群的资源管理和调度。它会接收来自各个应用程序的资源请求,并根据集群资源的使用情况进行合理分配。
NodeManager:部署在集群中的每个节点上,负责管理该节点上的资源使用情况,监控容器的运行状态,并且与 ResourceManager 保持通信,汇报节点的资源使用信息。
ApplicationMaster:在 Spark 应用启动时,YARN 会为其分配一个 ApplicationMaster。它的主要职责是向 ResourceManager 申请资源,并且与 NodeManager 协作,启动和管理 Spark 的 Executor 进程。
Spark Driver:负责执行用户编写的 Spark 应用程序代码,将其转化为一系列的任务,并调度这些任务到各个 Executor 上执行。
Executor:运行在 NodeManager 管理的容器中,负责具体执行 Spark 任务,并将执行结果返回给 Driver。
1.上传并解压spark-3.1.2-bin-hadoop3.2.tgz,重命名解压之后的目录为spark-yarn。对应的命令是:tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module

2. 修改一下spark的环境变量,/etc/profile.d/my_env.sh 。

3.修改hadoop的配置。/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml。因为测试环境虚拟机内存较少,防止执行过程进行被意外杀死,添加如下配置。
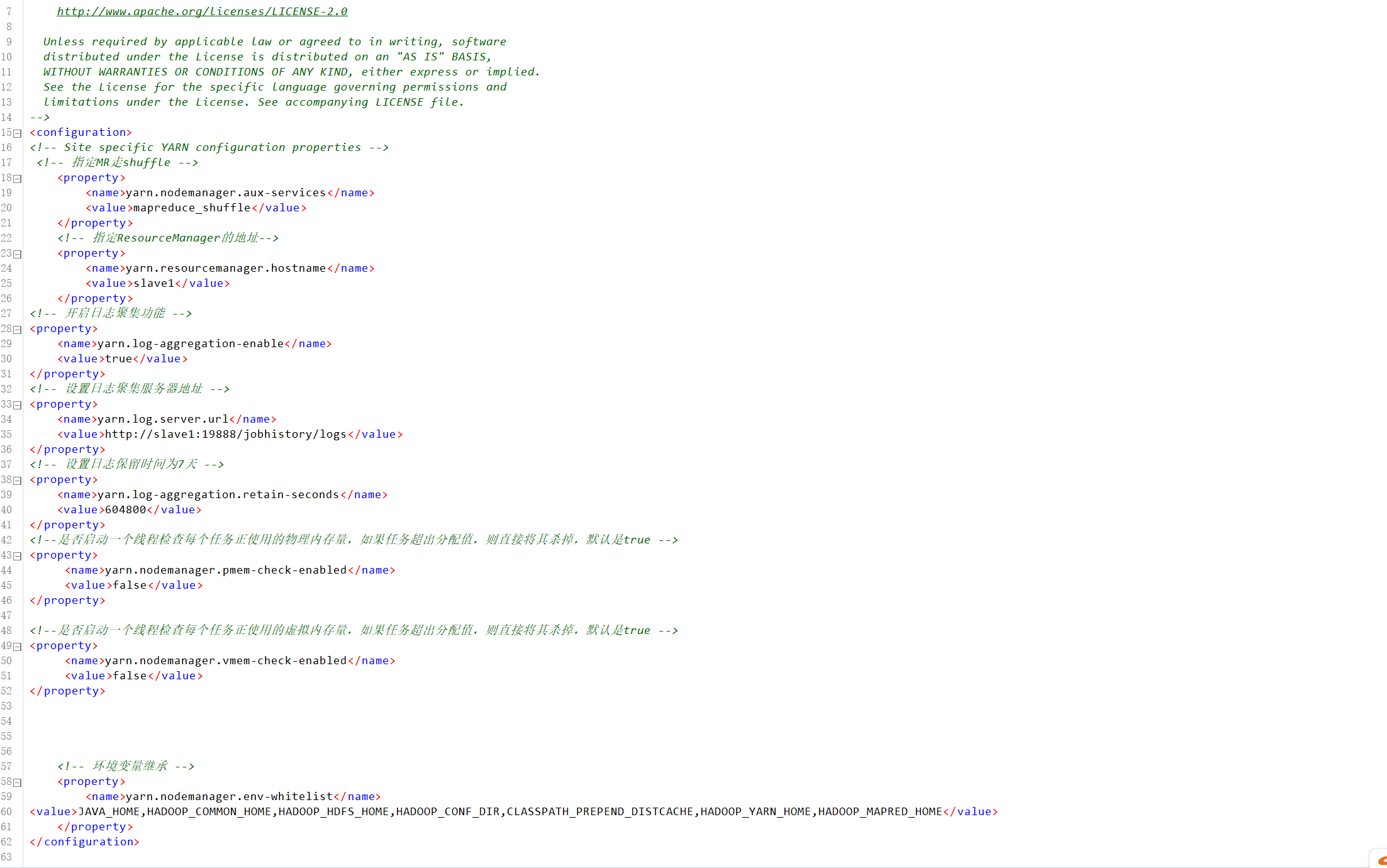
使用xsync /opt/module/hadoop-3.1.3/etc/hadoop/同步一下。
4.修改spark配置。 把三个文件的名字重新设置一下:
workers.tempalte 改成 workers,spark-env.sh.template 改成 spark-env.sh,
spark-defaults.conf.template 改成 spark-defaults.conf。
5.然后,在workers文件中添加:

在spark-env.sh文件中,添加如下:

在spark-defaults.conf文件中,添加如下:

6.同步配置文件到其他设备。xsync /opt/module/spark-yarn/sbin