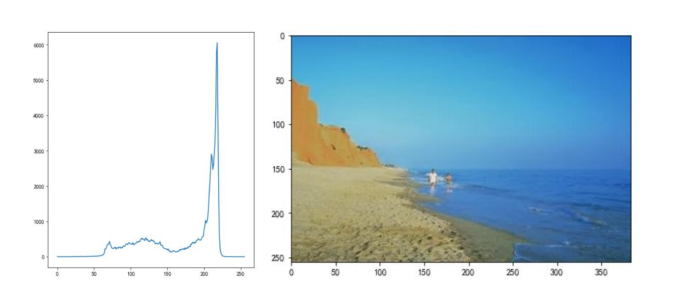
代码:
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from skimage.feature import hog
from skimage import data, exposure
import glob
设置中文字体显示
plt.rcParams'font.sans-serif' = 'SimHei' # 用来正常显示中文标签
plt.rcParams'axes.unicode_minus' = False # 用来正常显示负号
class ImageClassifier:
def init(self, data_path='./photo2'):
"""初始化图像分类器"""
self.data_path = data_path
self.class_names = \[\]
self.X = \[\] # 图像路径
self.Y = \[\] # 图像标签
self.Z = \[\] # 图像像素数据
self.X_train = \[\]
self.X_test = \[\]
self.y_train = \[\]
self.y_test = \[\]
self.model = None
self.scaler = StandardScaler()
self.pca = PCA(n_components=0.95) # 保留95%的方差
def load_data(self):
"""加载图像数据"""
获取类别名称
self.class_names = os.path.basename(name) for name in glob.glob(f'{self.data_path}/\*')
print(f"发现 {len(self.class_names)} 个类别: {self.class_names}")
遍历每个类别文件夹
for class_id, class_name in enumerate(self.class_names):
class_dir = os.path.join(self.data_path, class_name)
if not os.path.isdir(class_dir):
continue
获取该类别下的所有图像文件
image_files = glob.glob(os.path.join(class_dir, '*.jpg')) + \
glob.glob(os.path.join(class_dir, '*.jpeg')) + \
glob.glob(os.path.join(class_dir, '*.png'))
print(f"从 {class_name} 类别加载了 {len(image_files)} 张图像")
读取图像并存储路径和标签
for img_path in image_files:
self.X.append(img_path)
self.Y.append(class_id)
self.X = np.array(self.X)
self.Y = np.array(self.Y)
print(f"总共加载了 {len(self.X)} 张图像")
def split_data(self, test_size=0.2, random_state=42):
"""划分训练集和测试集"""
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
self.X, self.Y, test_size=test_size, random_state=random_state, stratify=self.Y
)
print(f"训练集大小: {len(self.X_train)}, 测试集大小: {len(self.X_test)}")
def extract_hog_features(self, img_path, visualize=False):
"""提取图像的HOG特征"""
读取图像并调整大小
img = cv2.imread(img_path)
if img is None:
print(f"无法读取图像: {img_path}")
return None
img = cv2.resize(img, (128, 128)) # 调整图像大小为128x128
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
提取HOG特征
fd, hog_image = hog(gray, orientations=9, pixels_per_cell=(8, 8),
cells_per_block=(2, 2), visualize=True, multichannel=False)
if visualize:
显示原始图像和HOG特征图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4), sharex=True, sharey=True)
ax1.axis('off')
ax1.imshow(img, cmap=plt.cm.gray)
ax1.set_title('原始图像')
调整HOG图像的对比度以便于查看
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
ax2.axis('off')
ax2.imshow(hog_image_rescaled, cmap=plt.cm.gray)
ax2.set_title('HOG特征图')
plt.tight_layout()
plt.show()
return fd
def prepare_features(self, visualize=False):
"""准备训练和测试数据的特征"""
print("正在提取训练集的HOG特征...")
X_train_features = \[\]
for img_path in self.X_train:
features = self.extract_hog_features(img_path, visualize=visualize)
if features is not None:
X_train_features.append(features)
print("正在提取测试集的HOG特征...")
X_test_features = \[\]
for img_path in self.X_test:
features = self.extract_hog_features(img_path)
if features is not None:
X_test_features.append(features)
X_train_features = np.array(X_train_features)
X_test_features = np.array(X_test_features)
print(f"训练集特征形状: {X_train_features.shape}")
print(f"测试集特征形状: {X_test_features.shape}")
特征标准化
print("正在进行特征标准化...")
X_train_scaled = self.scaler.fit_transform(X_train_features)
X_test_scaled = self.scaler.transform(X_test_features)
应用PCA降维
print("正在应用PCA降维...")
X_train_pca = self.pca.fit_transform(X_train_scaled)
X_test_pca = self.pca.transform(X_test_scaled)
print(f"PCA降维后训练集特征形状: {X_train_pca.shape}")
print(f"PCA降维后测试集特征形状: {X_test_pca.shape}")
return X_train_pca, X_test_pca
def train_model(self, X_train, y_train, kernel='rbf', C=1.0, gamma='scale'):
"""训练SVM模型"""
print(f"使用{kernel}核训练SVM模型...")
self.model = SVC(kernel=kernel, C=C, gamma=gamma, probability=True, random_state=42)
self.model.fit(X_train, y_train)
print("模型训练完成")
def evaluate_model(self, X_test, y_test):
"""评估模型性能"""
if self.model is None:
print("模型尚未训练")
return
在测试集上进行预测
y_pred = self.model.predict(X_test)
计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")
打印分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=self.class_names))
绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
self.plot_confusion_matrix(cm)
return accuracy
def plot_confusion_matrix(self, cm):
"""绘制混淆矩阵"""
plt.figure(figsize=(10, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('混淆矩阵')
plt.colorbar()
tick_marks = np.arange(len(self.class_names))
plt.xticks(tick_marks, self.class_names, rotation=45)
plt.yticks(tick_marks, self.class_names)
在混淆矩阵上标注数值
thresh = cm.max() / 2.
for i in range(cm.shape0):
for j in range(cm.shape1):
plt.text(j, i, format(cmi, j, 'd'),
horizontalalignment="center",
color="white" if cmi, j > thresh else "black")
plt.tight_layout()
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
def predict_image(self, img_path):
"""预测单张图像的类别"""
if self.model is None:
print("模型尚未训练")
return None
提取特征
features = self.extract_hog_features(img_path)
if features is None:
return None
特征标准化和PCA降维
features_scaled = self.scaler.transform(features)
features_pca = self.pca.transform(features_scaled)
预测类别
prediction = self.model.predict(features_pca)0
confidence = self.model.predict_proba(features_pca)0prediction
显示预测结果
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(6, 4))
plt.imshow(img)
plt.title(f"预测结果: {self.class_namesprediction}\n置信度: {confidence:.2f}")
plt.axis('off')
plt.show()
return prediction, confidence
def main():
"""主函数"""
创建图像分类器实例
classifier = ImageClassifier(data_path='./photo2')
加载数据
classifier.load_data()
划分训练集和测试集
classifier.split_data(test_size=0.2, random_state=42)
准备特征,可视化第一个样本的HOG特征
X_train, X_test = classifier.prepare_features(visualize=True)
训练模型
classifier.train_model(X_train, classifier.y_train, kernel='rbf', C=10, gamma='scale')
评估模型
classifier.evaluate_model(X_test, classifier.y_test)
预测示例图像(使用测试集中的第一张图像)
if len(classifier.X_test) > 0:
classifier.predict_image(classifier.X_test0)
if name == "main":
main()