
 国际人工智能联合会议(IJCAI)是人工智能领域最古老、最具权威性的学术会议之一,自1969年首次举办以来,至今已有近六十年的历史。它见证了人工智能从萌芽到蓬勃发展的全过程,是全球人工智能研究者、学者、工程师和行业专家汇聚交流的重要平台,也是CCF A类会议。IJCAI 2025将于2025年8月16日至8月22日在加拿大蒙特利尔举办。IJCAI 2025共有5404份投稿,录用1024篇,录取率为 19.3%。
国际人工智能联合会议(IJCAI)是人工智能领域最古老、最具权威性的学术会议之一,自1969年首次举办以来,至今已有近六十年的历史。它见证了人工智能从萌芽到蓬勃发展的全过程,是全球人工智能研究者、学者、工程师和行业专家汇聚交流的重要平台,也是CCF A类会议。IJCAI 2025将于2025年8月16日至8月22日在加拿大蒙特利尔举办。IJCAI 2025共有5404份投稿,录用1024篇,录取率为 19.3%。

导读
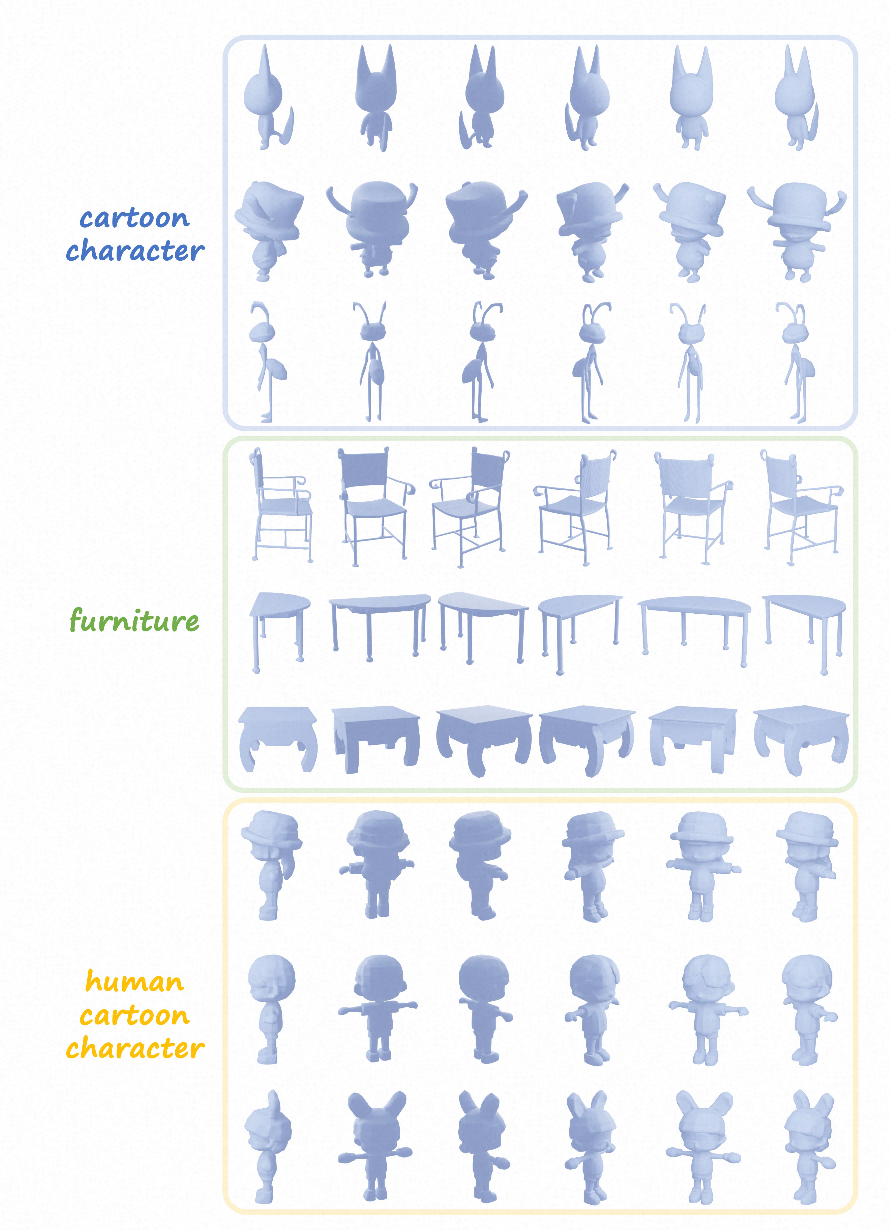
G3PT是高德地图自研的3D生成基座大模型,也是自动化3D资产生产的核心引擎,目前已广泛支持用于地图渲染的3D内容资产,包括3D世界建筑、导航车标以及3D数字人等。这项突破性技术大幅度降低了3D资产的制作成本,并且极大地扩展了用户在地图上的消费内容场,未来具有巨大的商业空间。
随着OpenAI推出GPT-4o图像生成功能,首次实现了基于大型语言模型(LLM)自回归架构的原生图像生成,其性能突破了当前主流的扩散模型(Diffusion Model)架构,引发了业界对基于自回归架构统一多模态建模的高度关注与广泛期待。
我们团队同样秉持对自回归架构价值的坚定信念,历经一年的技术攻坚,成功打造了业界首个基于自回归架构的原生3D生成基座大模型------G3PT。该模型通过单张图像即可生成高质量3D Mesh,其核心创新之处在于提出了Cross-scale Querying Transformer模块,实现了3D 数据的多尺度1D Tokenizer,并且引入了Next-scale Autoregressive架构,取代了传统GPT中的Next-token Autoregressive架构,从而巧妙地解决了3D数据无序性这一长期困扰自回归建模的关键难题。
尤为值得一提的是,我们在3D生成领域首次验证了自回归架构的Scaling Law,其生成效果与业界基于扩散模型架构的同类闭源产品持平,并且生成速度远优于扩散模型架构,有力地证明了自回归架构在3D生成任务中的巨大潜力与优势。目前,我们正全力推进相关工作的开源,旨在进一步推动3D生成社区的发展,敬请期待。
-
**论文主题:**G3PT: Unleash the Power of Autoregressive Modeling in 3D Generation via Cross-Scale Querying Transformer
-
**论文链接:**https://arxiv.org/abs/2409.06322
Introduction
近年来,3D形状生成领域取得了显著进展,主要方法包括利用大型重建模型(LRMs)将图像转换为3D形状,以及将2D扩散模型扩展到3D领域。然而,这些方法存在一些局限性:依赖多视图图像的保真度,难以生成高质量的网格,尤其是在捕捉复杂的几何细节方面。此外,一些基于3D变分自编码器和扩散模型的方法虽然能够生成3D形状,但受限于训练时间长和缺乏扩展策略,限制了其效果和可扩展性。
与此同时,自回归(AR)大型语言模型和多模态AR模型的出现开启了人工智能的新纪元。这些模型通过将数据转换为离散tokens,利用自监督生成学习进行下一步token预测,在语言处理和图像生成领域取得了显著成功。然而,将这些模型扩展到3D生成任务面临挑战,因为它们依赖于序列化的token预测,这与3D数据的无序性质不兼容。
G3PT的提出正是为了解决这一挑战。3D数据本质上具有多分辨率特性,不同尺度之间存在自然的序列关系。基于这一见解,G3PT通过多尺度分词器(CVQ)和多尺度自回归建模(CAR),将无序的3D数据映射为不同细节层次的离散tokens,从而建立适合自回归建模的序列关系。这种方法不仅避免了对人工指定顺序的依赖,还能够自然地连接不同细节层次的tokens,实现从粗到细的3D内容生成,并支持多种条件模态,如基于图像和文本的输入。
Approach
G3PT的核心在于其创新的CVQ和CAR框架,以及跨尺度查询变换器(CQT)的应用。在CVQ阶段,G3PT首先使用基于Transformer的标记器将高分辨率点云编码为潜在tokens。具体来说,输入的点云通过交叉注意力层整合到可学习的潜在查询中。然后,CQT利用注意力机制和可学习的"下采样"及"上采样"查询,将这些tokens分解为不同尺度的离散tokens。这一过程通过多层次的残差量化实现,能够有效地捕捉不同分辨率下的几何细节。最终,通过解码器将这些量化后的tokens重新转换为3D占用网格,生成最终的3D形状。
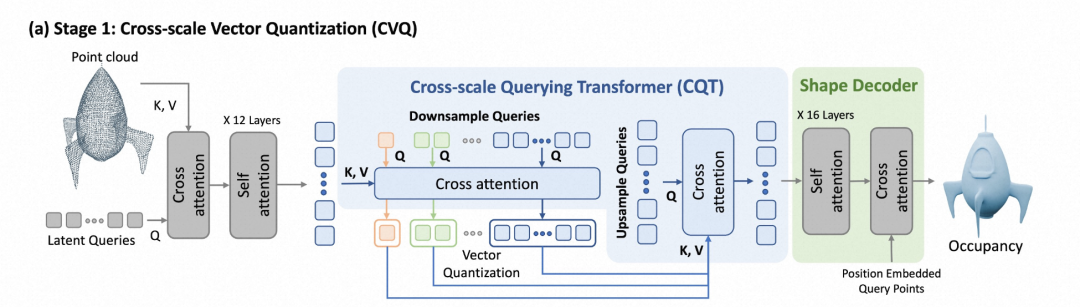
在CAR阶段,G3PT利用CVQ阶段训练得到的CQT对不同尺度的tokens进行对齐,并通过自回归变换器预测下一个尺度的tokens。这种方法从最粗的尺度开始,逐步细化,直至达到所需的细节层次。CAR阶段的关键在于通过跨尺度的维度对齐,使得模型能够在不同尺度之间传递信息,实现逐步精细化的3D生成。
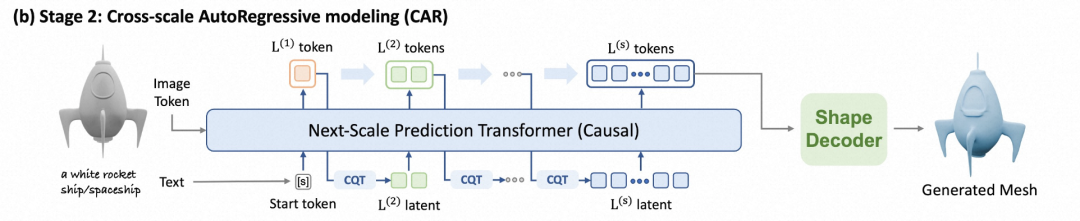
此外,G3PT还支持条件控制生成,即根据图像或文本输入生成相应的3D形状。对于图像条件,G3PT使用预训练的DINO-v2模型提取图像特征,并将其与3D tokens融合,通过注意力机制确保生成的3D形状与输入图像的语义一致性。对于文本条件,G3PT使用预训练的CLIP模型提取文本特征,并通过AdaLN机制控制生成过程,确保生成的3D形状与文本描述的语义一致。
Experiments
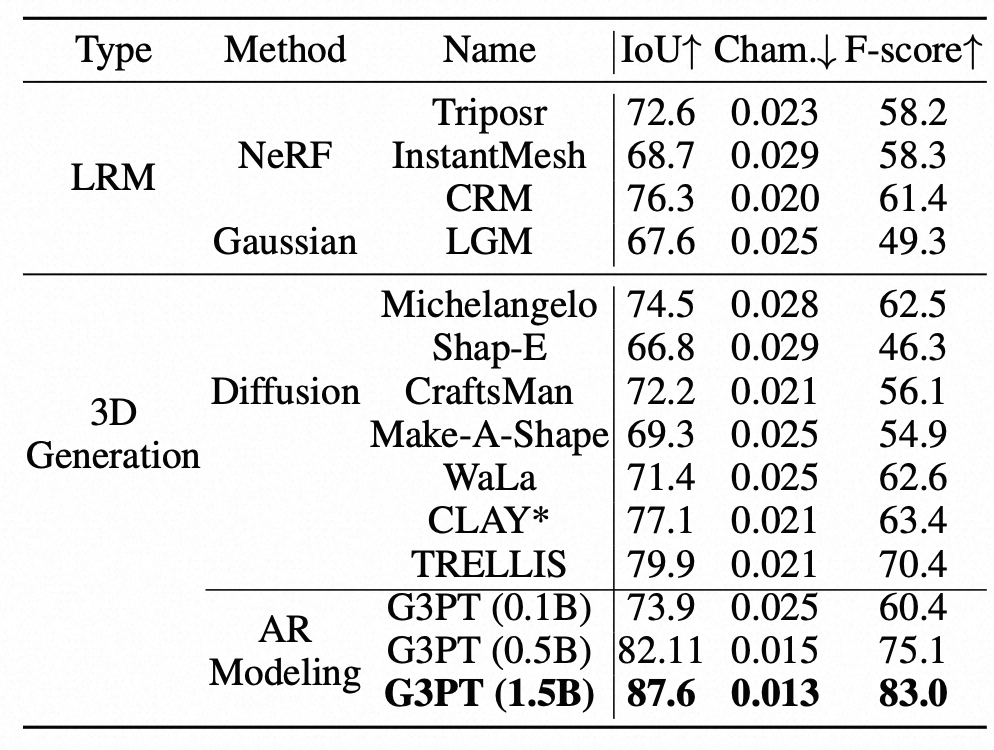
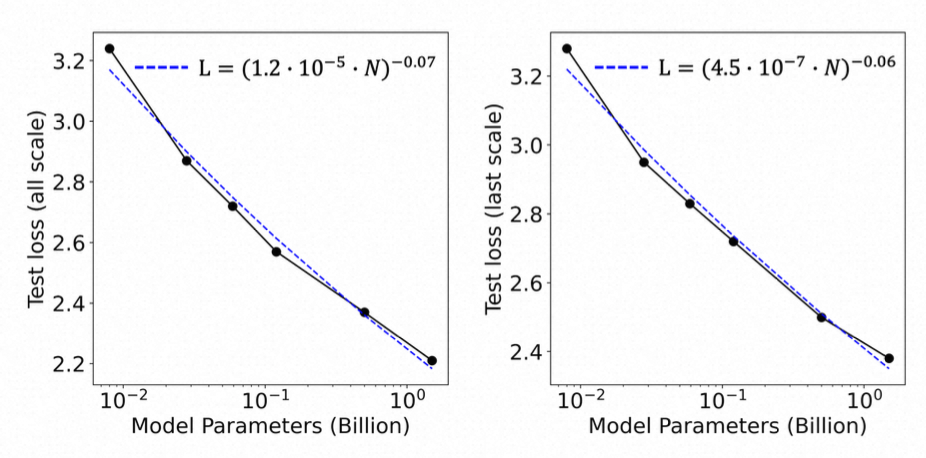
实验部分,G3PT在图像到3D形状生成任务中表现出色。在Objaverse数据集上,与多种LRM和扩散模型相比,G3PT在IoU、Chamfer距离和F-score等指标上均优于其他方法,尤其在15亿参数规模时性能显著提升。其首次揭示了3D生成中的幂律扩展行为,表明随着模型参数增加,测试损失呈幂律下降。此外,G3PT在文本到3D生成任务中也展示了出色的性能,能够根据文本提示生成高质量且语义一致的3D网格。
- 定量指标对比
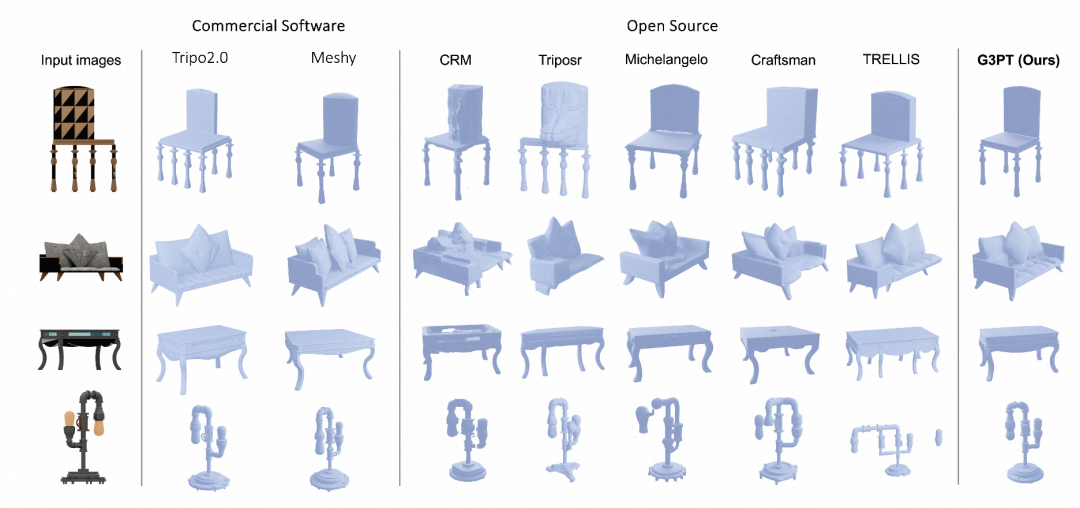
- 可视化对比
- 文本控制生成效果
- 3D自回归的Scaling Law
Conclusion
G3PT通过引入交叉尺度查询变换器(CQT)和交叉尺度自回归建模(CAR),为无序3D数据的生成提供了一种创新的自回归建模框架。它有效地解决了3D数据的无序性和多分辨率特性带来的挑战,实现了从粗到细的高质量3D内容生成,并支持多种条件模态。实验结果表明,G3PT在生成质量上超越了现有的3D生成方法,成为3D内容创作的新标杆。然而,G3PT的训练需要大量的计算资源,训练过程耗时较长。未来的工作可以探索更高效的训练技术,以及更丰富的控制条件,以进一步提升模型的性能和适用性。
