概述
CAP
什么是CAP
CAP理论,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
三者关系如下
- 分布式系统要么满足CA,要么CP,要么AP。无法同时满足CAP
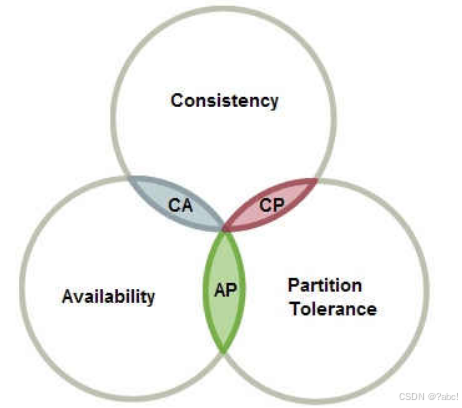
CAP说明
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
-
一致性(Consistency):在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值,即
要求分布式系统中的各节点时时刻刻保持数据的一致性。 -
可用性(Availability): 一直可以正常的做读写操作。即
客户端一直可以正常访问并得到系统的正常响应。
用户角度来看就是不会出现系统操作失败或者访问超时等问题。 -
分区容错性(Partition tolerance):指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。即
部分故障不影响整体使用。
L1&L2&L3分别代表是意思
二级缓存架构
-
L1:1级为本地缓存,或者进程内的缓存(如 Ehcache)速度快,进程内可用
-
L2:2级为集中式缓存(如 Redis)可同时为多节点提供服务
-
L3:数据库DB
数据库、本地缓存及分布式缓存的区别
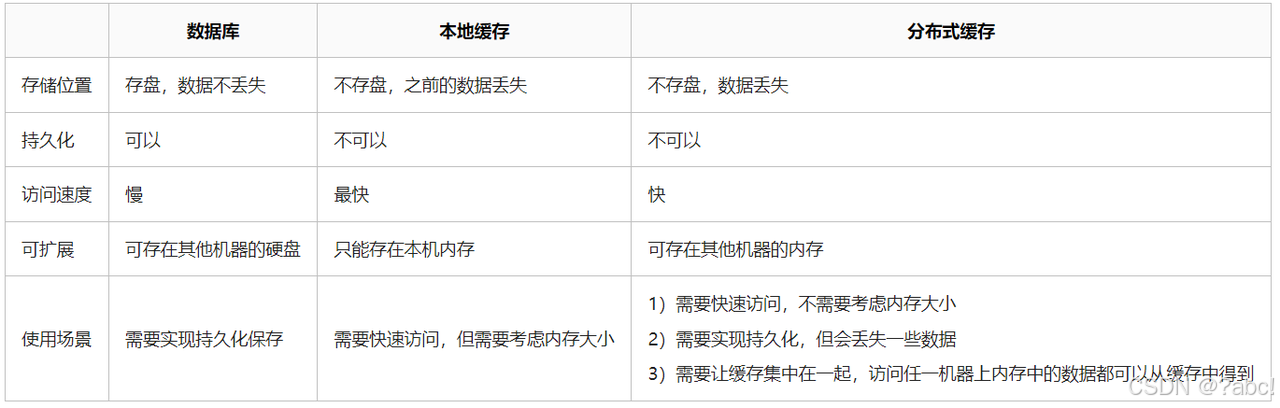
为什么要引入本地缓存?
本地缓存有如下优点:
相对于IO操作 速度快,效率高相对于Redis, Redis是一种优秀的分布式缓存实现,受限于网卡等原因,远水救不了近火
所以:DB + Redis + LocalCache = 高效存储,高效访问
本地缓存适用场景
本地缓存一般适合于缓存只读、量少、高频率访问的数据。
如秒杀商品数据。
或者每个部署节点独立的数据,如长连接服务中,每个部署节点由于都是维护了不同的连接,每个连接的数据都是独立的,并且随着连接的断开而删除。
如果数据在集群的不同部署节点需要共享和保持一致,则需要使用分布式缓存来统一存储,实现应用集群的所有应用进程都在该统一的分布式缓存中进行数据存取即可。
本地缓存优缺点
一:访问速度快,但无法进行大数据存储
- 本地缓存位于同一个JVM的堆中,相对于分布式缓存的好处是故
性能更好,减少了跨网络传输, - 但是
本地缓存由于占用 JVM 内存空间(或者进程的内存空间),故不能进行大数据量的数据存储。
二:数据一致性问题
- 本地缓存只支持被该应用进程访问,一般无法被其他应用进程访问,如果对应的数据库数据,
存在数据更新,则需要同步更新不同节点的本地缓存副本,来保证数据一致性 本地缓存的更新,复杂度较高并且容易出错,如基于 Redis 的发布订阅机制、或者消息队列MQ来同步更新各个部署节点
单独使用本地缓存与集中式缓存问题
单独使用本地缓存与集中式缓存,都会有各自的问题。
-
使用本地缓存时,- 一旦应用
重启后,由于缓存数据丢失,缓存雪崩,给数据库造成巨大压力,导致应用堵塞 多个应用节点无法共享缓存数据
- 一旦应用
-
使用集中式缓存,由于大量的数据通过缓存获取,导致缓存服务的数据吞吐量太大,带宽跑满。- 现象就是 Redis 服务负载不高,但是由于机器网卡带宽跑满,导致数据读取非常慢
如果一个网站,一天中有大量的访问量,当前缓存数据都存放在一个redis服务,那么这个redis的流量就要承受比其网卡带宽还大,这个问题当然可以通过两种办法去解决:
- 升级网卡:升级到万兆网卡,当然不是所有云主机都可以这样,而且很麻烦
- 搭建redis集群 ,流量分摊到多台机器
- 成本直接攀升,
- 改良建议:按照80/20原则 ,如果我们把20%的热点数据,放在本地缓存,如果我们不用每次页面访问的时候都去 Redis 读取数据,那么 Redis 上的数据流量至少降低 80%的带宽流量,甚至于一个很小的 Redis 集群可以轻松应付);
本地缓存与集中式缓存的2级缓存架构
第一级缓存使用内存(同时支持 Ehcache 2.x、Ehcache 3.x 、Guava、 Caffeine),
第二级缓存使用 Redis(推荐)/Memcached
读
从一级缓存获取 获取 get 更新 put key value 从二级缓存获取 更新一级缓存 从数据库获取 更新二级缓存 业务节点进程 数据读取来源 Ehcache 2.x/Ehcache 3.x/Guava/Caffeine... 获取/更新 本地缓存L1 Redis/Memcached... mysql
写
通过消息队列,或者其他广播模式的发布订阅,保持各个一级缓存的数据一致性。
与Cache-Aside模式不同,Cache-Aside只是删除缓存即可。但是热点数据,如果删除,很容易导致缓存击穿。
数据一致性实现策略
如果需要数据库和缓存数据保持强一致,就不适合使用缓存。
所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用缓存。
缓存一定要设置过期时间,这个时间太短、或者太长都不好:
- 太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。
- 太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态 ,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
3种方案保证数据库与缓存的一致性
- 延时双删策略
- 删除缓存重试机制
- 读取biglog异步删除缓存
延时双删策略
延时双删的步骤:
- 先删除缓存
- 再更新数据库
- 休眠一会(比如1秒),再次删除缓存。
- 这个休眠一会,一般多久呢? 这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。
流程图如下
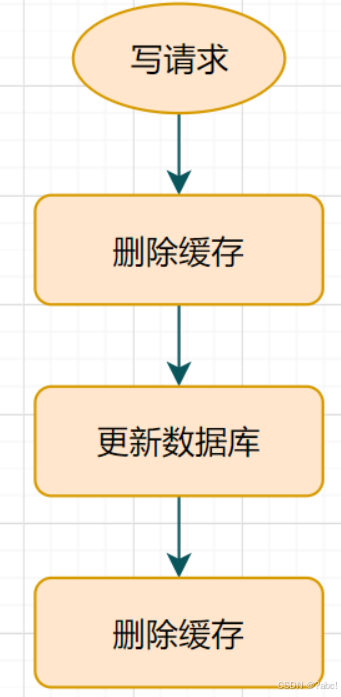
多做的一次删除目的:为了确保读请求结束,写请求 可以 删除读请求 可能带来的缓存脏数据。
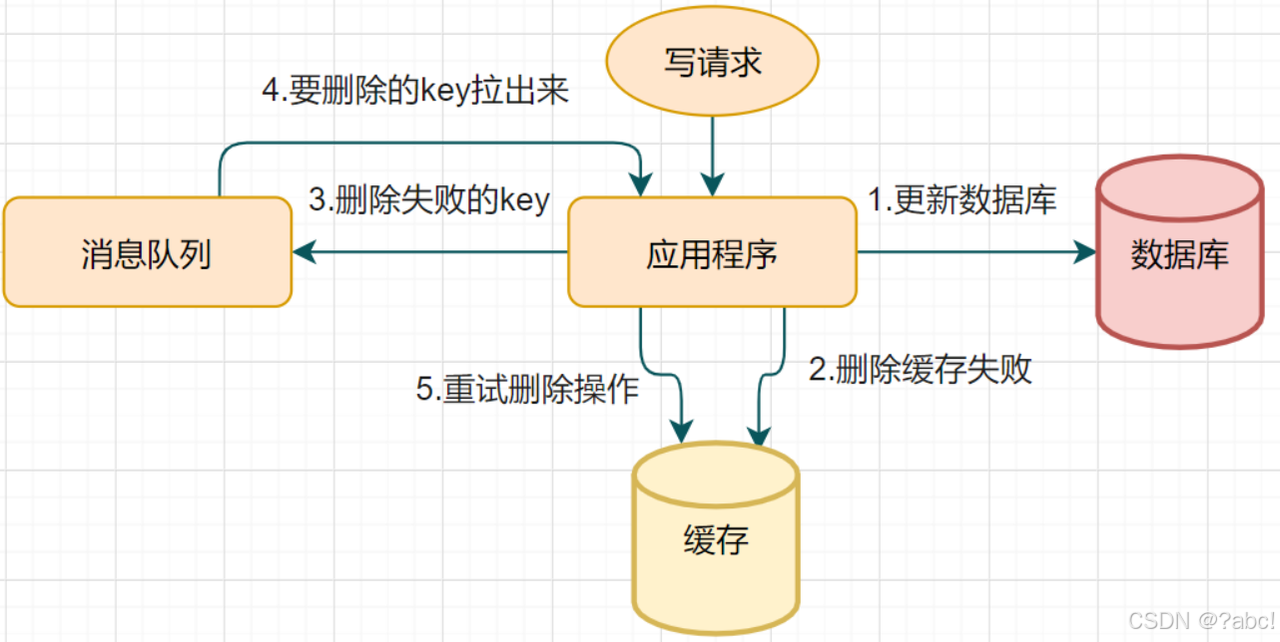
删除缓存重试机制
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存,如果第二步的删除缓存失败,会导致脏数据,那么就多删除几次, 保证删除缓存成功,由此引入删除缓存重试机制
删除缓存重试机制的大致步骤:
- 写请求更新数据库
- 缓存因为某些原因,删除失败
把删除失败的key放到消息队列- 消费消息队列的消息,获取要删除的key
重试删除缓存操作
流程图如下
读取biglog异步删除缓存
重试删除缓存机制,会造成很多业务代码入侵,
所以可以:
- 通过数据库的binlog来异步淘汰key。
- pub/sub机制 确保消费
基本逻辑
以mysql为例 可以使用阿里的canal
将binlog日志采集发送到MQ队列里面,- 然后编写一个简单的缓存删除消息者订阅binlog日志,
- 根据
更新log删除缓存,并且通过ACK机制确认处理这条更新log,保证数据缓存一致性
如何保证消费成功
使用方明确表示消费成功
PushConsumer为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功------即都会重新投递。
单数据库
为了保证消息是肯定被至少消费成功一次,RocketMQ会把这批消费失败的消息重发回Broker (topic不是原topic而是这个消费租的RETRY topic),在延迟的某个时间点(默认是10秒,业务可设置)后,再次投递到这个ConsumerGroup 。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。应用可以监控死信队列来做人工干预。
流程图如下
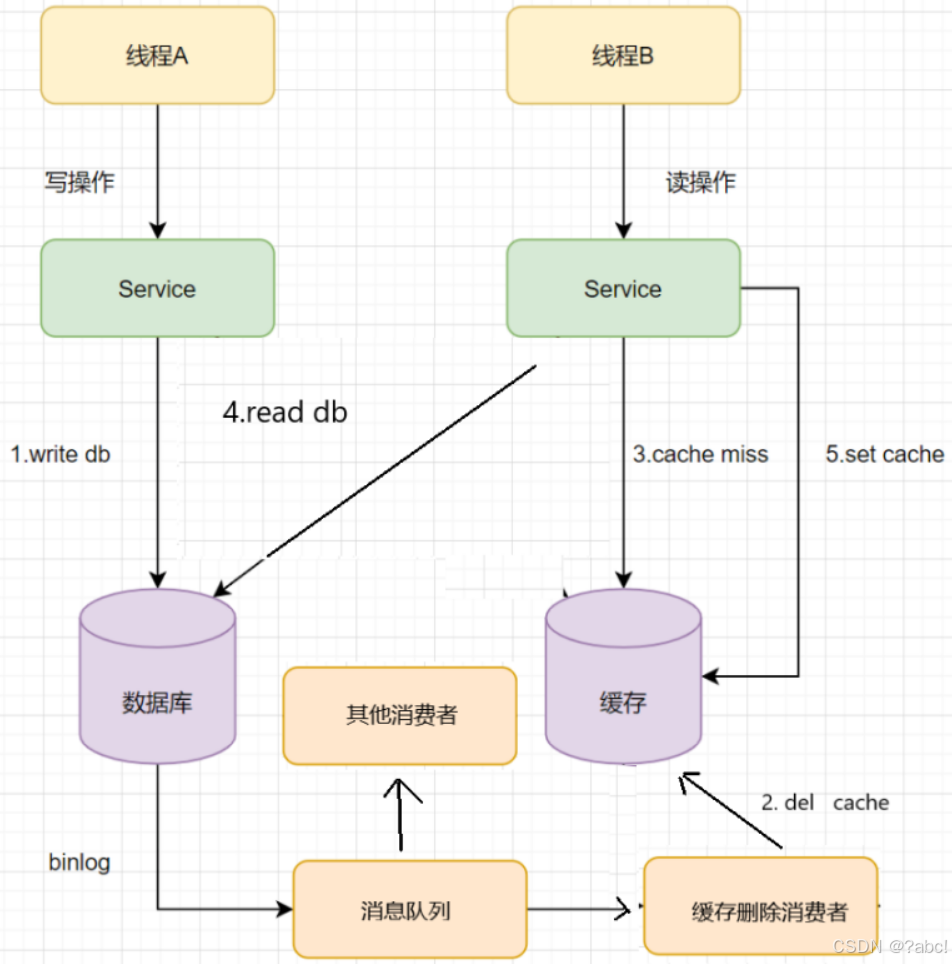
主从数据库
如果是主从数据库的话:主从数据库通过biglog异步删除
- 如果是主从数据库,
binglog取自于从库 - 如果是
一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存 ,或者 为了简单,收到一次更新log,删除一次缓存
流程图如下
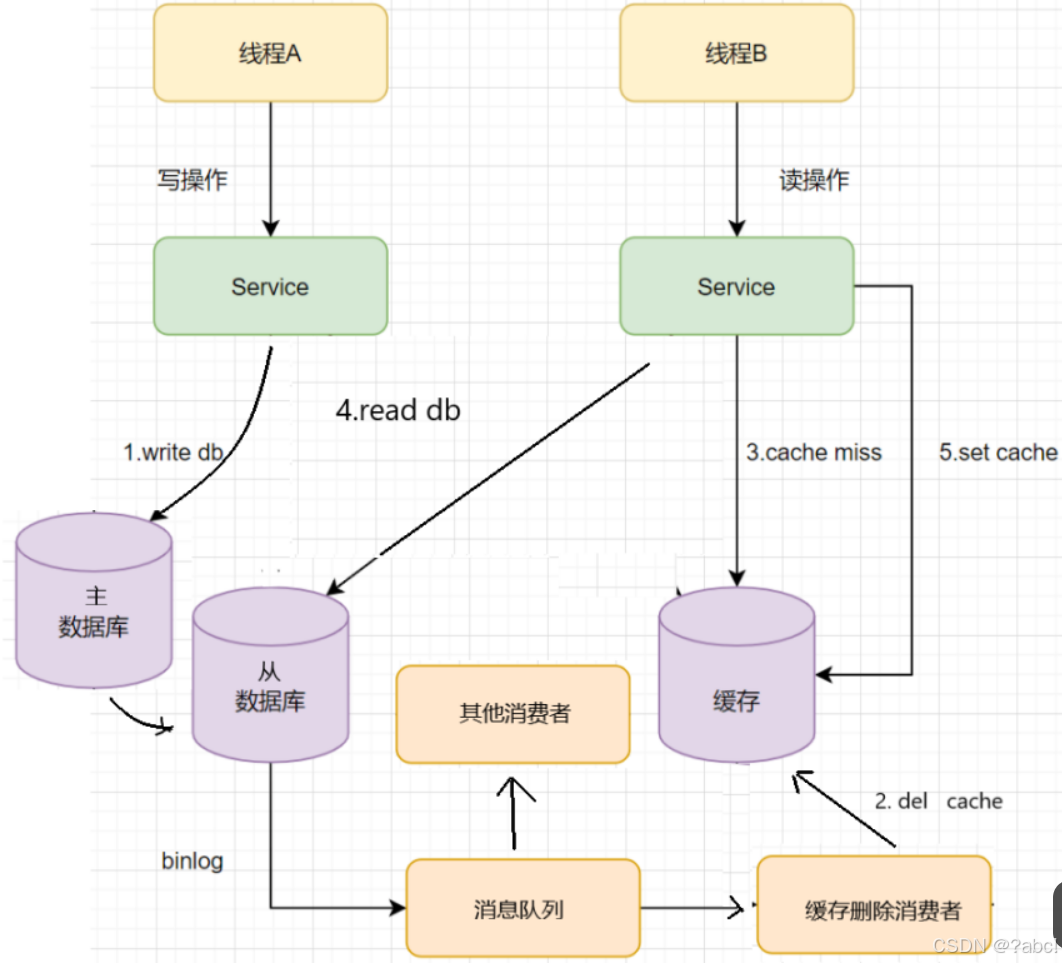
步骤总结
在分布式系统中,缓存和数据库同时存在时,如果有写操作的时候,「先操作数据库,再操作缓存」。
步骤如下:
- 读取缓存中是否有相关数据
- 如果缓存中有相关数据value,则返回
- 如果缓存中没有相关数据,则从数据库读取相关数据放入缓存中key->value,再返回
- 如果有更新数据,则先更新数据库,再删除缓存
- 为了保证第四步删除缓存成功,使用binlog异步删除
- 如果是主从数据库,binglog取自于从库
- 如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存,或者为了简单,收到一次更新log,删除一次缓存
Pub/Sub功能(means Publish, Subscribe)
Pub/Sub功能(means Publish, Subscribe)即发布及订阅功能。
Pub/Sub是目前广泛使用的通信模型,它采用事件作为基本的通信机制,提供大规模系统所要求的松散耦合的交互模式:
- 订阅者(如客户端)以事件订阅的方式表达出它有兴趣接收的一个事件或一类事件;
- 发布者(如服务器)可将订阅者感兴趣的事件随时通知相关订阅者。