集合框架
Java 集合框架是 Java 提供的一组用于存储和操作数据的类和接口,它提供了高效、灵活且安全的数据存储和处理方式。
1. 集合框架的架构
Java 集合框架主要由两大接口派生而出:Collection 和 Map。
-
Collection接口:存储一组对象,它有三个主要的子接口:List、Set和Queue。 -
Map接口:存储键值对,键是唯一的,每个键对应一个值。 -
其继承关系如下
Collection ├── List(有序,允许重复) │ ├── ArrayList │ ├── LinkedList │ └── Vector ├── Set(无序,元素唯一) │ ├── HashSet │ ├── LinkedHashSet │ └── TreeSet └── Queue(队列结构) ├── LinkedList(可作队列) └── PriorityQueue(优先级队列) Map ├── HashMap ├── LinkedHashMap ├── TreeMap └── Hashtable(线程安全但过时)
2. Collection 接口及其子接口
2.1 List 接口
List 是有序的集合,允许存储重复的元素。常见的实现类有 ArrayList、LinkedList 和 Vector。
ArrayList:基于动态数组实现,支持随机访问,插入和删除操作效率较低。
java
import java.util.ArrayList;
import java.util.List;
public class ArrayListExample {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple");
list.add("banana");
System.out.println(list.get(0)); // 输出: apple
}
}LinkedList:基于双向链表实现,插入和删除操作效率较高,随机访问效率较低。
java
import java.util.LinkedList;
import java.util.List;
public class LinkedListExample {
public static void main(String[] args) {
List<String> list = new LinkedList<>();
list.add("apple");
list.add("banana");
System.out.println(list.get(0)); // 输出: apple
}
}Vector:与ArrayList类似,但它是线程安全的,不过性能相对较低。(已逐渐被替代)
2.2 Set 接口
Set 是不允许存储重复元素的集合。常见的实现类有 HashSet、TreeSet 和 LinkedHashSet。
HashSet:基于哈希表实现,不保证元素的顺序。
java
import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
System.out.println(set.contains("apple")); // 输出: true
}
}HashSet 集合的主要特性之一是不允许存储重复元素。判断元素是否重复,依赖于元素的 hashCode() 和 equals() 方法。
- 原理 :当向
HashSet中添加元素时,首先会调用元素的hashCode()方法计算哈希码,根据哈希码确定元素在内部存储结构(哈希表)中的位置。如果该位置已经有其他元素,则会调用equals()方法来比较这两个元素是否相等。若相等,则认为是重复元素,不会添加到集合中。 - 示例 :以下是一个自定义类的示例,展示了正确重写
hashCode()和equals()方法的重要性。
java
import java.util.HashSet;
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 重写 hashCode 方法
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
// 重写 equals 方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && (name != null ? name.equals(person.name) : person.name == null);
}
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
Person p1 = new Person("Alice", 20);
Person p2 = new Person("Alice", 20);
set.add(p1);
set.add(p2);
System.out.println(set.size()); // 输出 1,因为 p1 和 p2 被认为是重复元素
}
}- 空元素的添加
HashSet 允许添加一个 null 元素。因为 null 的 hashCode() 始终为 0,且在 HashSet 中只会存在一个 null 元素。
java
import java.util.HashSet;
public class NullElementInHashSet {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add(null);
set.add(null);
System.out.println(set.size()); // 输出 1,因为只允许有一个 null 元素
}
}TreeSet:基于红黑树实现,元素会按照比较器(元素所属的类必须实现java.lang.Comparable接口,并实现compareTo()方法)进行排序。如果元素所属的类没有实现Comparable接口,可以使用定制排序。定制排序需要在创建TreeSet时传入一个Comparator对象,Comparator接口定义了compare()方法,用于指定元素之间的比较规则。
java
import java.util.TreeSet;
import java.util.Set;
public class TreeSetExample {
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("apple");
set.add("banana");
System.out.println(set.first()); // 输出: apple
}
}
java
import java.util.Comparator;
import java.util.TreeSet;
public class CustomSortingExample {
public static void main(String[] args) {
// 创建一个 Comparator 对象,按照字符串长度进行比较
Comparator<String> lengthComparator = new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
return Integer.compare(s1.length(), s2.length());
}
};
// 使用定制的 Comparator 创建 TreeSet
TreeSet<String> treeSet = new TreeSet<>(lengthComparator);
treeSet.add("apple");
treeSet.add("banana");
treeSet.add("cherry");
treeSet.add("date");
// 遍历 TreeSet,元素会按照字符串长度从小到大排序
for (String str : treeSet) {
System.out.println(str);
}
}
}LinkedHashSet:基于哈希表和链表实现,保证元素的插入顺序。
java
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args) {
// 创建一个 LinkedHashSet 实例
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
// 添加元素到 LinkedHashSet
linkedHashSet.add("apple");
linkedHashSet.add("banana");
linkedHashSet.add("cherry");
// 尝试添加重复元素,不会被添加
linkedHashSet.add("apple");
// 输出 LinkedHashSet 的元素,元素顺序与插入顺序一致
System.out.println("LinkedHashSet 中的元素:");
for (String element : linkedHashSet) {
System.out.println(element);
}
// 检查元素是否存在
boolean containsBanana = linkedHashSet.contains("banana");
System.out.println("是否包含 banana: " + containsBanana);
// 移除元素
linkedHashSet.remove("cherry");
System.out.println("移除 cherry 后,LinkedHashSet 中的元素:");
for (String element : linkedHashSet) {
System.out.println(element);
}
// 检查集合是否为空
boolean isEmpty = linkedHashSet.isEmpty();
System.out.println("LinkedHashSet 是否为空: " + isEmpty);
// 获取集合的大小
int size = linkedHashSet.size();
System.out.println("LinkedHashSet 的大小: " + size);
}
} 2.3 Queue 接口
Queue 是队列接口,遵循先进先出(FIFO)原则。常见的实现类有 LinkedList(也实现了 Queue 接口)和 PriorityQueue。
PriorityQueue:基于堆实现。- 元素按自然序或
Comparator排序(使用场景:任务优先级处理、堆排序)
java
import java.util.PriorityQueue;
import java.util.Queue;
public class PriorityQueueExample {
public static void main(String[] args) {
Queue<Integer> queue = new PriorityQueue<>();
queue.add(3);
queue.add(1);
queue.add(2);
System.out.println(queue.poll()); // 输出: 1
}
}3. Map 接口及其实现类
Map 存储键值对,键是唯一的。常见的实现类有 HashMap、TreeMap 和 LinkedHashMap。
HashMap:基于哈希表实现,不保证键值对的顺序。
java
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
System.out.println(map.get("apple")); // 输出: 1
}
}TreeMap:基于红黑树实现,键会按照自然顺序或指定的比较器进行排序。
java
import java.util.TreeMap;
import java.util.Map;
public class TreeMapExample {
public static void main(String[] args) {
Map<String, Integer> map = new TreeMap<>();
map.put("apple", 1);
map.put("banana", 2);
System.out.println(map.firstKey()); // 输出: apple
}
}LinkedHashMap:基于哈希表和链表实现,保证键值对的插入顺序。 是 Java 中Map接口的一个实现类,它继承自HashMap,同时维护了一个双向链表,用来记录元素的插入顺序或者访问顺序- 当构造函数中设置
accessOrder=true时,每次调用get()或put()方法访问元素时,该元素会被移动到双向链表的尾部(即最近访问的元素排在最后)
java
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
遍历结果:A → B → C
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 访问元素 "B"
Integer b = map.get("B");
System.out.println("============访问了B元素的值:"+b);
// 遍历结果:A → C → B(B 被移动到末尾)
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}构建 LRU 缓存
通过重写 removeEldestEntry 方法,可自动淘汰最久未访问的元素
java
LinkedHashMap<Integer, String> lruCache = new LinkedHashMap<>(3, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, String> eldest) {
return size() > 3; // 容量超过3时移除最旧元素
}
};
lruCache.put(1, "One");
lruCache.put(2, "Two");
lruCache.put(3, "Three");
lruCache.get(1); // 访问元素1,使其保留
lruCache.put(4, "Four"); // 触发淘汰,移除元素2
System.out.println(lruCache); // 输出:{1=One, 3=Three, 4=Four}LinkedHashMap 本身非线程安全,多线程环境下需通过 Collections.synchronizedMap() 或并发包(如 ConcurrentHashMap)实现同步
4. 集合的遍历
可以使用迭代器、for-each 循环或 Java 8 的 Stream API 来遍历集合。
java
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class CollectionTraversal {
public static void main(String[] args) {
List<String> c = new ArrayList<>();
c.add("apple");
c.add("banana");
// 使用迭代器遍历
Iterator<String> iterator = c.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 使用 for-each 循环遍历
for (String element : c) {
System.out.println(element);
}
// 使用 Stream API 遍历
c.stream().forEach(System.out::println);
}
}集合 forEach 遍历
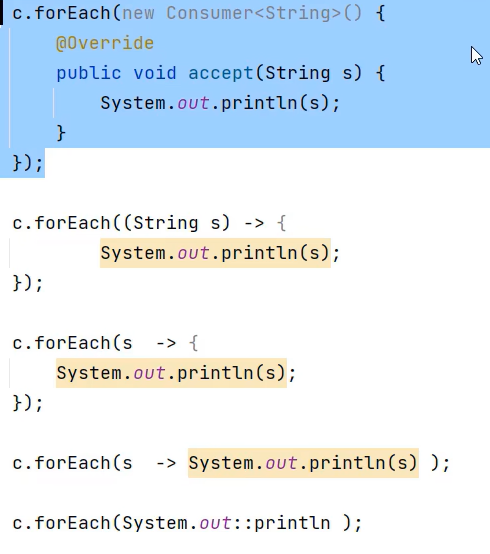
5. 线程安全的集合
Java 提供了一些线程安全的集合类,如 Vector、Hashtable,以及 Collections.synchronizedXXX 方法返回的同步集合,还有 Java 并发包中的 ConcurrentHashMap、CopyOnWriteArrayList 等。
java
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class ThreadSafeCollection {
public static void main(String[] args) {
// 使用 Collections.synchronizedMap 方法创建线程安全的 Map
Map<String, Integer> map = new HashMap<>();
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(map);
}
}Java 集合框架提供了丰富的类和接口,以满足不同的需求。在实际开发中,需要根据具体的场景选择合适的集合类。
Stream流
1. Stream 是 Java 8 引入的一个新的抽象概念,
它代表了一个来自数据源的元素序列,支持聚合操作。数据源可以是集合、数组、I/O 通道等。Stream 操作分为中间操作和终端操作。
2. Stream 流的创建
2.1 从集合创建
可以通过集合的 stream() 或 parallelStream() 方法创建 Stream 流。
java
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class StreamCreationFromCollection {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple");
list.add("banana");
list.add("cherry");
// 创建顺序流
Stream<String> sequentialStream = list.stream();
// 创建并行流
Stream<String> parallelStream = list.parallelStream();
}
}2.2 从数组创建
使用 Arrays.stream() 方法从数组创建 Stream 流。
java
import java.util.Arrays;
import java.util.stream.Stream;
public class StreamCreationFromArray {
public static void main(String[] args) {
String[] array = {"apple", "banana", "cherry"};
Stream<String> stream = Arrays.stream(array);
}
}2.3 使用 Stream.of() 方法
可以直接使用 Stream.of() 方法创建 Stream 流。
java
import java.util.stream.Stream;
public class StreamCreationUsingOf {
public static void main(String[] args) {
Stream<String> stream = Stream.of("apple", "banana", "cherry");
}
}3. 中间操作
中间操作会返回一个新的 Stream,允许进行链式调用。常见的中间操作有:
3.1 filter()
用于过滤满足条件的元素。
java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class FilterExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
System.out.println(evenNumbers);
}
}3.2 map()
用于对元素进行转换。
java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class MapExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
List<Integer> squaredNumbers = numbers.stream()
.map(n -> n * n)
.collect(Collectors.toList());
System.out.println(squaredNumbers);
}
}3.3 sorted()
用于对元素进行排序。
java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class SortedExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(3, 1, 2);
List<Integer> sortedNumbers = numbers.stream()
.sorted()
.collect(Collectors.toList());
System.out.println(sortedNumbers);
}
}3.4 distinct()
用于去除重复元素。
java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class DistinctExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 3, 3);
List<Integer> distinctNumbers = numbers.stream()
.distinct()
.collect(Collectors.toList());
System.out.println(distinctNumbers);
}
}4. 终端操作
终端操作会触发 Stream 流的处理,并产生一个结果或副作用。常见的终端操作有:
4.1 forEach()
用于对每个元素执行操作。
java
import java.util.Arrays;
import java.util.List;
public class ForEachExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
numbers.stream()
.forEach(n -> System.out.println(n));
}
}4.2 collect()
用于将 Stream 流中的元素收集到一个集合中。
java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class CollectExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
List<Integer> squaredNumbers = numbers.stream()
.map(n -> n * n)
.collect(Collectors.toList());
System.out.println(squaredNumbers);
}
}4.3 reduce()
用于将 Stream 流中的元素进行合并。
java
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
public class ReduceExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
Optional<Integer> sum = numbers.stream()
.reduce((a, b) -> a + b);
sum.ifPresent(System.out::println);
}
}4.4 count()
用于统计 Stream 流中元素的数量。
java
import java.util.Arrays;
import java.util.List;
public class CountExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
long count = numbers.stream().count();
System.out.println(count);
}
}5. 并行流
并行流可以利用多核处理器的优势,并行处理 Stream 流中的元素,提高处理性能。但需要注意线程安全问题。
java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class ParallelStreamExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> squaredNumbers = numbers.parallelStream()
.map(n -> n * n)
.collect(Collectors.toList());
System.out.println(squaredNumbers);
}
}