Python
- 前言
-
- [1. 搭建Python环境](#1. 搭建Python环境)
- [2. 创建Python项目](#2. 创建Python项目)
- 一、基础语法
- [二、 条件语句和循环语句](#二、 条件语句和循环语句)
-
- [1. 条件语句](#1. 条件语句)
- [2. 循环语句](#2. 循环语句)
- [三、 函数](#三、 函数)
-
- [1. 语法格式](#1. 语法格式)
- [2. 变量的作用域](#2. 变量的作用域)
- [3. 参数默认值](#3. 参数默认值)
- [4. 关键字参数](#4. 关键字参数)
- [四、 列表和元组](#四、 列表和元组)
-
- [1. 列表](#1. 列表)
- [2. 元组](#2. 元组)
- 五、字典
-
- [1. 字典操作](#1. 字典操作)
- [2. 合法hash](#2. 合法hash)
- [六、 文件](#六、 文件)
- [七、 库](#七、 库)
-
- [1. 标准库](#1. 标准库)
- [2. 第三方库](#2. 第三方库)
- 补充
前言
1. 搭建Python环境
- 安装Python:
直接在Python官网下载。安装时直接默认路径,勾选好环境变量配置 - 安装PyCharm:(用来写代码的工具,运行还是需要Python解释器,所以要管理两者)
直接在PyCharm官网下载。可以安装到D盘,勾选上更新上下文菜单
2. 创建Python项目
关联PyCharm和Python并创建项目
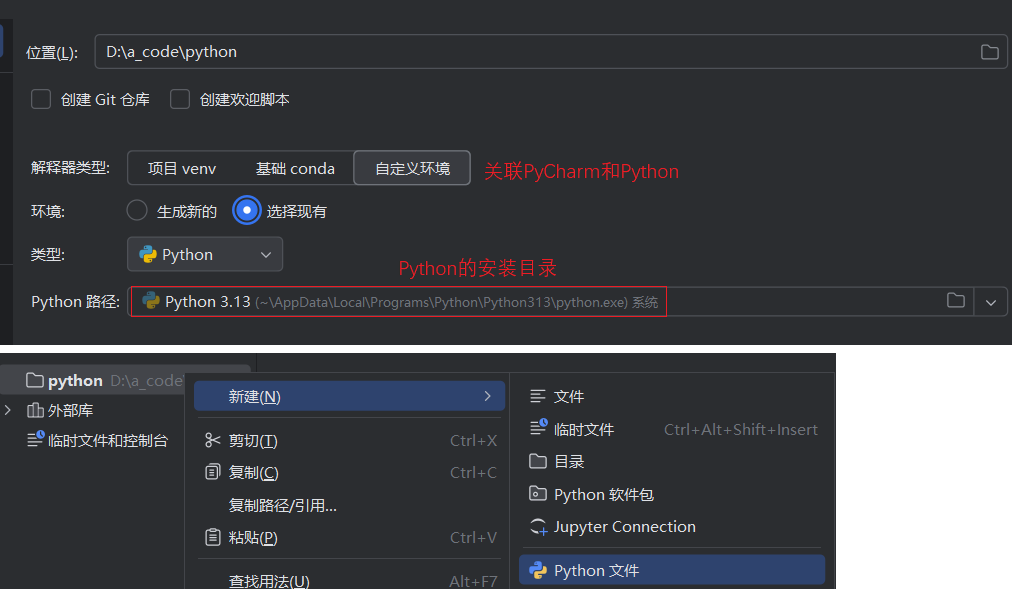
更改项目字体:设置中的编辑器里的font(字体)
更改背景:也可以进入设置,在搜索栏搜索background(背景)
一、基础语法
1. 常量和表达式
python
print(1 + 2 / 3)
# 输出结果:1.66666666666666651 + 2 / 3在编程语言中被称为表达式 ,结果称为表达式的返回值 。1,2,3成为字面值常量 ,+ - * /这种称为运算符 或者操作符
注意:
2 / 3的小数部分没用被直接截断,在Python中小数也保留下来- 编程中,一般没有"四舍五入"这样的规则。存储浮点数要遵循IEEE754标准。这套规则下,在内存中表示浮点数的时候,可能会存在微小的误差
2. 变量和类型
python
avg = (67.5 + 89.0 + 12.9 + 32.2) / 4
total = (67.5 - avg) ** 2 + (89.0 - avg) ** 2 + (12.9 - avg) ** 2 + (32.2 - avg) ** 2
result = total / 4
print(result)- 每次的运算结果都要保存这就是变量,如
avg/total **在 Python 中表示乘方运算,** 2即为求平方
①变量的语法
- 定义变量
python
a = 10 # a是变量名
# 显示类型定义
b:int = 10
c:float = 5.5
print(b, c)
# 输出结果:10 5,5注意:变量的名字要遵守一定规则
- 硬性规则
- 变量名由数字、字母、下划线构成
- 数字不能开头
- 变量名不能和 "关键字" 重复
- 变量名大小写敏感
- 软性规则
- 变量名使用有描述性的多单词来表示,尽量表达出变量的作用
- 当变量名包含多个单词的时候,建议使用 "驼峰命名法"。除首个单词外, 剩余单词首字母大写
- 变量的使用
python
a = 10
a = 20 # 修改变量的值
print(a)
b = 5
a = b # 变量给变量赋值
print(a) # 读取变量的值
# 输出结果:
# 20
# 5②变量的类型
- 整数
python
a = 10
print(type(a)) # 使用 type 来查看一个变量的类型
# 输出结果:<class 'int'>注意: Python的int类型变量表示的数据范围没有上限,只要内存足够大, 理论上就可以表示无限大小的数据
- 浮点数
python
a = 0.5
print(type(a))
# 输出结果:<class 'float'>注意: Python 的小数只有 float 一种类型, 但是实际上就相当于C++/Java的double,表示双精度浮点数
- 字符串
python
a = 'hello'
print(type(a))
# 输出结果:<class 'str'>注意: 在 Python 中,单引号构成的字符串和双引号构成的字符串,没有区别。
- 获取字符串长度
len:
python
a = 'hello'
print(len(a))
# 输出结果:5- 使用
+拼接两个字符串:
python
a = 'hello'
b = 'world'
print(a + b)
# 输出结果:helloworld注意:不能拿字符串和整数/浮点数相加(直接报错)
- 字符串中的引号
如果字符串里面包含了双引号,表示字符串就可以用单引号引起来
如果字符串里面包含了单引号,表示字符串就可以使用双引号引起来
如果同时有单引号和双引号,Python中还有一种字符串,使用三引号表示'''或者"""
python
Str = "This is "baidu"" # err
Str1 = 'This is "baidu"'
Str2 = '''This 'is' "baidu"'''- 布尔:布尔类型是一个特殊的类型, 取值只有两种True (真) 和 False (假)
python
a = True
print(type(a))
b = False
print(type(b))
# 输出结果:<class 'bool'>
# 输出结果:<class 'bool'>- 其他类型:Python中还有list、tuple、dict自定义类型等等
③类型小结
- 为什么有那么多类型
- 类型决定了数据在内存中占据多大空间,如float类型在内存中占据 8 个字节
- 约定了能对这个变量做什么样的操作,如 int / float 类型的变量,可以进行
+ - * /等操作,而 str 类型的变量,只能进行 + (并且行为是字符串拼接)
- 动态类型特性:在 Python 中, 一个变量是什么类型, 是可以在 "程序运行" 过程中发生变化
python
a = 10
print(type(a))
a = 'hello'
print(type(a))
# 输出结果:<class 'int'>
# 输出结果: <class 'str'>- 注: 动态类型特性是一把双刃剑
- 对于中小型程序, 可以大大的解约代码量
- 对于大型程序, 则提高了模块之间的交互成本(难理解)
3. 注释
目的:帮助程序员(n久后的自己)理解程序代码的执行逻辑
-
注释的语法:Python中有两种风格的注释
- 注释行:
#开头
# 这是一行注释
注:选中多行使用ctrl+/ - 文档字符串:使用三引号引起来的称为 "文档字符串", 也是一种注释
a. 可以包含多行内容
b. 一般放在文件、函数、类的开头
c. """ 或者 ''' 均可 (等价)
- 注释行:
-
注释的规范
- 内容准确:注释内容要和代码一致,及时更新
- 篇幅合理:不多不少
- 使用中文:外企另当别论
- 积极向上
4. 输入输出
输入输出的最基本的方法就是控制台,最常见方法是图形化界面
- 通过控制台输出:Python使用
print函数输出到控制台
示例:
python
num = 10
print(f"num = {num}")
# 输出结果:num = 10注意:
- 使用 f 作为前缀的字符串, 称为 f-string,即格式化字符串
- 里面可以使用 { } 来内嵌一个其他的变量/表达式
- 通过控制台输入:Python使用
input函数,从控制台读取用户的输入
示例:
python
num = 0
num = input('请输入一个整数: ')
print(f'你输入的整数是 {num}')
# 输出结果:
# 请输入一个整数: 10
# 你输入的整数是 10注意:
- input 的参数相当于一个 "提示信息",可以没有
- input 的返回值就是用户输入的内容,是字符串类型
- input 执行的时候,就会一直等待用户输入
示例:类型转换int()、float()、bool()、str( )
python
a = input('请输入第一个整数: ')
b = input('请输入第二个整数: ')
print(f'a + b = {a + b}') # 拼接
a = int(a) # 类型转换
b = int(b) # 类型转换
print(f'a + b = {a + b}') # 算术运算
# 输出结果:
# 请输入第一个整数: 3
# 请输入第二个整数: 4
# a + b = 34
# a + b = 75. 运算符
①算术运算符
+ - * / % ** // 这种进行算术运算的运算符,称为算术运算符
注意:
- 除0会抛异常
- 整数 / 整数结果可能是小数,而不会截断
%是求余数**是求乘方,不光能算整数次方,还能算小数次方- // 是取整除法(也叫地板除)。整数除以整数,结果还是整数(舍弃小数部分,并向下取整)
示例:
python
print(f'1 / 3 = {1 / 3}')
print(f'7 % 3 = {7 % 3}')
print(f'4 ** 2 = {4 ** 2}')
print(f'4 ** 0.5 = {4 ** 0.5}')
print(f'7 // 3 = {7 // 3}')
print(f'-7 // 3 = {-7 // 3}')
# 输出结果:
# 1 / 3 = 0.3333333333333333
# 7 % 3 = 1
# 4 ** 2 = 16
# 4 ** 0.5 = 2.0
# 7 // 3 = 2
# -7 // 3 = -3②关系运算符
< <= > >= == !=这一系列的运算符称为关系运算符,它们是在比较操作数之间的关系
- 关系符合,则表达式返回 True。如果关系不符合,则表达式返回 False
- 关系运算符不光针对整数/浮点数进行比较,还能针对字符串进行比较
注意:
- 直接使用 == 或者 != 即可对字符串内容判定相等
- 字符串比较大小规则一个单词在词典上越靠前,就越小。越靠后,就越大
- 对于浮点数来说,不要使用 == 判定相等,因为浮点数存储存在误差。所以可以使用做差的方式判定差值是否小于允许的误差范围
示例:
python
a = 10
b = 20
print(f'a <= b {a <= b}')
print(f'a >= b {a >= b}')
print(f'a == b {a == b}')
print(f'a != b {a != b}')
# a <= b True
# a >= b False
# a == b False
# a != b True
c = 'hello'
d = 'world'
print(f'c <= d {c <= d}')
print(f'c >= d {c >= d}')
print(f'c == d {c == d}')
print(f'c != d {c != d}')
# c <= d True
# c >= d False
# c == d False
# c != d True
print(f'0.1 + 0.2 == 0.3 {0.1 + 0.2 == 0.3}')
# 0.1 + 0.2 == 0.3 False
e = 0.1 + 0.2
f = 0.3
print(f'e == f {-0.0000001 < (e - f) < 0.0000001}')
# e == f True③逻辑运算符
and or not这一系列的运算符称为逻辑运算符
python
a = 10
b = 20
c = 30
print(a < b < c) # T
print(a < b and b > c) # F
print(a < b or b > c) # T
print(not a < b) # F注意:
a < b and b < c这个操作等价于a < b < c- Python也支持短路求值
④赋值运算符=
- 赋值运算符的使用
a. 链式赋值
b. 多元赋值,可以完成两个变量交换
示例:
python
a = b = 10
print(f'a = {a}') # 10
print(f'b = {b}') # 10
a = 20
a, b = b, a
print(f'a = {a}') # 10
print(f'b = {b}') # 20- 复合赋值运算符
Python还有一些复合赋值运算符,如+= -= *= /= %=用法同C++,但是Python不支持自加自减运算
其它
除了上述之外, Python中还有一些运算符,如身份运算符(is, is not),成员运算符(in, not in),位运算符( & | ~ ^ << >>) 等
二、 条件语句和循环语句
顺序语句:Python的代码执行顺序是按照从上到下的顺序依次执行
1. 条件语句
①语法格式
Python中使用if、elif、else关键字表示条件语句
语法格式
python
# expression值为True, 则执行 do_something1, do_something2, next_something
# expression值为False, 则只执行 next_something
if expression:
do_something1
do_something2
next_something
# 如果 expression 值为 True, 则执行do_something1
# 如果 expression 值为 False, 则执行 do_something2
if expression:
do_something1
else:
do_something2
if expression1:
do_something1
elif expression2:
do_something2
else:
do_something3注意:
if后面的条件表达式,没有( ),使用:作为结尾if / else命中条件后要执行的 "语句块",使用缩进来表示,而不是 { }- 对于多条件分支,不是写作else if, 而是
elif
缩进和代码块
代码块指的是一组放在一起执行的代码,在Python中使用缩进表示代码块。不同级别的缩进,程序的执行效果不同
示例:
python
# 这里input的返回值是字符,所以要和数字比较要转换类型
a = int(input('请输入一个整数(1是优秀 2是良好 3是合格 注:其他输入不合格):'))
if a == 1:
b = input('是非常优秀吗?是输入0')
if b == '0': # 内部嵌套
print('非常优秀')
# 同级缩进属于一个代码块,在a == 1的条件下执行
print('优秀')
print('做的很好,再接再厉')
elif a == 2:
print('良好')
elif a == 3:
print('合格')
else:
print('不合格')注: 在Python中,给负数取模不同于C++/java。如下
python
a = int(input('num:'))
# 在Python中 -19 % 2 == 1 是真
# 在C++/Java中 -19 % 2 == -1 是真
if a % 2 == 1:
print('odd')
else:
print('even')②空语句pass
pass表示空语句,就是占位置,保持Python语法格式要求
python
a = int(input("请输入一个整数:"))
if a != 1:
pass # 如果这里不写pass会造成语法错误
else:
print("hello")2. 循环语句
①while循环
语法格式
python
while 条件:
循环体示例:
python
count = 1
total = 0
while count <= 5:
factorResult = 1
i = 1
while i <= count:
factorResult *= i
i += 1
total += factorResult
count += 1
print(total)②for循环
语法格式
python
for 循环变量 in 可迭代对象:
循环体示例1:
python
for e in range(1, 11):
print(e)
for e in range(2, 12, 2):
print(e)注:
- 可迭代对象:内部包含多个元素, 能一个一个把元素取出来的特殊变量。
- range函数,能生成一个可迭代对象,范围是左闭右开。第三个参数是指定迭代时的"步长"(可以为负数)
示例2:
python
for i in range(10, 0, -1):
print(i)③continue和break
continue:结束本次循环开始下次循环
示例:
python
for e in range(1, 6):
if e == 3:
continue
print(e)break:结束整个循环
python
for e in range(1, 6):
if e == 3:
break
print(e)三、 函数
1. 语法格式
python
# 定义函数 形参列表中可以有多个形参,形参之间用逗号(,)隔开
def 函数名(形参列表):
函数体
return 返回值
# 调用函数
函数名(实参列表) # 不考虑返回值的调用
返回值 = 函数名(实参列表) # 考虑返回值的调用注:
- 函数必须先定义,再使用。定义要在使用之前
- 函数的形参不必指定类型,也就意味着一个函数就可以支持多种不同类型的参数,但是要保证传入的参数类型,在函数体中能够支持对应的运算操作
- 一个函数可以一次返回多个返回值。使用
,号分割。如return x, y,接收再用多元赋值的方式接收 - 如果只想关注其中的部分返回值, 可以使用
_来忽略不想要的返回值。_, b = getPoint(),这个_就是占位的作用
2. 变量的作用域
语法规则:
- 变量只能在所在函数内部生效,出了函数范围,变量就不在生效了
- 在不同的作用域,允许同名变量。如函数内部和全局
- 如果函数内部尝试访问的变量在局部不存在, 就会尝试去全局作用域中查找
- 想在函数内部, 修改全局变量的值, 需要使用 global 关键字声明(区别于C++/C)。如果没有global,则函数内部的
x = 20就被看做创建一个局部变量x,和全局的x无关
示例:
python
x = 10
def test():
global x
x = 20
print(f"函数内部 x = {x}")
test()
print(f"函数外部 x = {x}")
# 运行结果:
# 函数内部 x = 20
# 函数外部 x = 20- 在
if / while / for中定义的变量, 在语句外面也可以正常使用。(区别C/C++)
示例:
python
for i in range(1, 10):
pass
print(i)
# 运行结果:93. 参数默认值
在Python种可以给形参指定默认值
示例:
python
def add(x, y, debug=True):
if not debug:
print(f'调试信息:x={x}, y={y}', end=' ')
return x + y
print(add(1, 2))
print(add(1, 2, False))
# 运行结果:
# 3
# 调试信息:x=1, y=2 3注: 带有默认值的参数需要放到没有默认值的参数的后面
4. 关键字参数
一般默认情况下是按照形参的顺序,来依次传递实参。但是我们也可以通过关键字参数,来调整这里的传参顺序,显式指定当前实参传递给哪个形参
示例:
python
def test(x, y):
print(f'x = {x}', end = ' ')
print(f'y = {y}')
test(1, 2)
test(y = 1, x = 2) # 即为关键字参数
# 运行结果:
# x = 1 y = 2
# x = 2 y = 1四、 列表和元组
元组和列表相比是非常相似的,只是列表中元素可以修改调整,元组中元素是创建元组的时候就设定好的,不能修改调整。(可以理解为C++/C中的数组)
1. 列表
①创建列表和访问下标
python
# 创建列表
# 1. 创建列表的两种方式
alist = []
alist = list()
print(type(alist)) # <class 'list'>
# 2. 可以在创建的时候设置初始值, 列表中存放的元素允许是不同的类型
alist = [1, 'hello', True, 3.14]
print(alist)
# 输出结果:[1, 'hello', True, 3.14]
# 访问下标
# 1. 通过下标访问操作符,获取列表中的元素
print(alist[2]) # True
# 2. 通过下标访问修改元素
alist[2] = 100
print(alist)
# 输出结果:[1, 'hello', 100, 3.14]
# 3. 下标访问超出有效范围会抛出异常
#print(alist[100]) # err
# 4. len内建函数,求列表长度
print(len(alist)) # 4
# 5. 下标可以取负数,等价于len(alist)+负数
print(alist[3]) # 3.14
print(alist[-1]) # 3.14②切片操作和遍历列表元素
- 切片操作
字符串也支持切片操作
示例:
python
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 切片操作:一次取出一组连续的元素
# 1. 使用 [ : ] 的方式进行切片操作
# [1:3]表示的是[1,3)这样由下标构成的前闭后开区间
blist = alist[1:3]
print(blist)
# 输出结果:[2, 3]
# 2. 可以省略边界
print(alist[1:]) # 省略后边界,表示获取到列表末尾
print(alist[:-1]) # 省略前边界,表示从列表开始获取,这里的-1等价于len(alist)-1
print(alist[:]) # 省略两边界,表示获取整个列表
# 3. 切片操作还可以指定步长
print(alist[::2])
# 输出结果:[1, 3, 5, 7, 9]
# 4. 步长可以为负数,此时从后向前取元素
print(alist[::-2])
# 输出结果:[10, 8, 6, 4, 2]
# 5. 如果切片的范围越界,不会有异常,只会尽可能的取
print(alist[8:100]) # [9, 10]- 遍历列表操作:使用循环
python
alist = [1, 2, 3, 4, 5]
for elem in alist: # 这里的elem实际是可迭代对象中拷贝过来的元素
print(elem)
for i in range(0, len(alist)):
print(alist[i])③新增元素、查找元素、删除元素
方法:就是函数,但是方法要依附于某个"对象"
示例:
python
# 新增元素
# 1. append方法,向列表末尾插入一个元素
alist = [1,2,3,4]
alist.append('hello')
print(alist)
# 输出结果:[1, 2, 3, 4, 'hello']
# 2. insert方法向任意位置插入一个元素。
# 插入的下标非常大也没关系,不会报错,会尽可能放在后面
alist.insert(len(alist),'world')
print(alist)
# 输出结果:[1, 2, 3, 4, 'hello', 'world']
# 查找元素
# 1. 使用in操作符,返回值是bool类型
print('hello' in alist) # True
print('!' in alist) # False
# 2. 使用index方法,查找列表中的下标,返回整数.元素不存在抛出异常
print(alist.index("hello")) # 4
# 删除元素
# 1. 使用pop方法删除末尾元素
alist.pop()
print(alist)
# 输出结果:[1, 2, 3, 4, 'hello']
# 2. pop使用下标删除
alist.pop(3)
print(alist)
# 输出结果:[1, 2, 3, 'hello']
# 使用remove方法,按照值删除
alist.remove(1)
print(alist)
# 输出结果:[2, 3, 'hello']④连接列表
python
# 连接列表
# 1. 使用 + 把两个列表拼接在一起,不会影响原来的列表
alist = [1, 2, 3, 4]
blist = [5, 6, 7, 8]
clist = alist + blist
print(clist)
# 输出结果:[1, 2, 3, 4, 5, 6, 7, 8]
# 2. 使用extend方法,把一个列表拼接在另一个列表上。消耗小相对于a += b
alist.extend(blist)
print(alist)
# 输出结果:[1, 2, 3, 4, 5, 6, 7, 8]2. 元组
元组的功能和列表类似,用()表示。元素不能修改里面的元素
示例:因为和列表很相似就不分开介绍
python
# 创建元组
# 1. 创建元组的两种方式
a = ()
a = tuple()
print(type(a))
# 输出结果:# <class 'tuple'>
# 2. 创建元组的时候指定初始值,元组中的元素可以是任意类型
a = (1, 2, 'hello', True, 3.14)
print(a)
# 输出结果:(1, 2, 'hello', True, 3.14)
# 访问下标
print(a[1]) # 2
print(a[-1]) # 3.14
# a[1] = 100 # 元组不支持修改
# print(a[100]) # 下标访问超过范围
print(len(a)) # 5
# 切片操作
a = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
aTuple = a[1:5] # 可以省略边界,或超出不报错
print(aTuple)
# 输出结果:(2, 3, 4, 5)
# 遍历
for elem in a:
print(elem)
for i in range(0, 10):
print(a[i])
# 拼接
a = (1,2,3,4)
b = (4,5,6,7)
print(a+b)
# 输出结果:(1, 2, 3, 4, 4, 5, 6, 7)
# 查找
print(1 in a) # True
print(a.index(2)) # 1注: 元组在Python中很多时候是默认的集合类型,如
python
def getPoint():
return 10, 20
print(type(getPoint()))
# 输出结果:<class 'tuple'五、字典
字典是一种存储键值对的结构,即把键(key)和值(value)一一映射
注:
- 字典被设计出来的初衷是为了增删查改(效率很高),不是为了遍历
- 对于字典来说
in或者[]来获取value都比较高效,而列表里的in需要遍历列表
1. 字典操作
①创建字典
python
# 创建字典
# 1. 创建字典的两种方式
a = {}
a = dict()
print(type(a))
# 输出结果:<class 'dict'>
# 2. 创建时指定初始值,最后一对键值对后面的逗号(,)可以省略
student = {
'id': 1,
'name': 'zhangsan',
'age': 18
}
print(student)
# 输出结果:{'id': 1, 'name': 'zhangsan', 'age': 18}②增删查改
python
# 增删查改
student = {
'id': 1,
'name': 'zhangsan'
}
# 新增
student["age"] = 18
# 修改
student['id'] = 2
student['name'] = 'lisi'
# 删除
student.pop('age')
print(student)
# 输出结果:{'id': 2, 'name': 'lisi'}
# 查找
if 'id' in student:
print(student['id']) # 在返回key对应的value,不在字典中会抛异常③遍历和取出所有字典元素
注:
- Python虽然是哈希表(但是不纯),但是做了特殊处理,在遍历的时候是有序的,即插入顺序
- 下面示例中有很多类型,如
<class 'dict_keys'>都是特殊类型,大部分元组可使用的操作,此类型也可以
示例:
python
aDict = {
'id': 1,
'name': 'wangwu',
'age': 18,
'face': 'cool'
}
# 循环遍历
for key in aDict:
print(key, aDict[key])
# 取出键值对
# 1. 使用keys方法获取字典中所有key
keys = aDict.keys()
print(type(keys))
# 输出结果:<class 'dict_keys'>
print(keys)
# 输出结果:dict_keys(['id', 'name', 'age', 'face']) # 返回值像列表,又不完全是
# 2. 使用values方法获取字典中所用value
values = aDict.values()
print(type(values))
# 输出结果:<class 'dict_values'>
print(values)
# 输出结果:dict_values([1, 'wangwu', 18, 'cool'])
# 3. 使用items方法获取字典中所有键值对
items = aDict.items()
print(type(items))
# 输出结果:<class 'dict_items'>
print(items)
# 返回值首先是一个自定义类型,里面是列表一样的结构,列表中的元素又是元组,元组里包含着键值对
# 输出结果:dict_items([('id', 1), ('name', 'wangwu'), ('age', 18), ('face', 'cool')])
# 遍历
for key, value in aDict.items():
print(key, value)2. 合法hash
字典中的key类型不一定都一样,但是有约束。字典本质上是一个hash表,可以用hash函数计算一个对象的哈希值,只要能计算出哈希值,都可以作为字典的key。一般不可变对象是可以hash的
python
# 合法的key值类型
print(hash('hello'))
print(hash(0))
print(hash(3.14))
print(hash(True))
print(hash(())) # ()是一个元组
# 不合法的key值类型
print(hash([])) # []是一个列表
print(hash({})) # {}是一个字典六、 文件
文件路径:
- D:表示盘符。不区分大小写
- 每一个
\表示一级目录。 - 目录之间的分隔符,可以使用
\也可以使用/(常用)
1. 文件操作
①打开和关闭文件
-
打开文件使用内建函数open
①第一个参数是字符串,表示要打开的文件路径
②第二个参数表示要打开的方式。其中
r是读方式,w是写方式,a是追加写方式打开③返回值:成功返回一个文件对象,失败会抛异常。
文件对象: 就是远程操控文件的handler(句柄) -
关闭文件,避免系统资源的浪费
方式:
对象.close
示例:文件打开不关闭,最多能打开count = 8189。当然这个可以进行设置
python
fList = []
count = 0
while True:
f = open('D:/a_code/python/practice/test.txt', 'r')
fList.append(f)
count += 1
print(f"count = {count}")注: 上述代码中,使用列表保存了文件对象。如果不进行保存,那么Python内置的垃圾回收机制(GC),会自动把不使用的变量释放。因为垃圾回收操作不一定及时,所以考虑手动关闭
③读写文件
- 写操作使用
write方法,同时打开文件方式使用w。方式要对应,否则会抛异常。
注: 区别w和a,前者一旦打开文件成功,就会清空文件原有数据。后者是追加写,原有内容不变,在文件内容末尾追加写
示例:
python
f = open('d:/a_code/python/practice/text.txt', 'w')
f.write('hello')
f.close()
# 文件内容:hello
f = open('d:/a_code/python/practice/text.txt', 'a')
f.write(' world')
f.close()
# 文件内容:hello world- 读操作使用
read方法,同时打开文件方式使用r
注:
read的参数表示"读取几个字符"- 文本如果是多行文本可以使用for循环一次读取一行
示例:
python
f = open('d:/a_code/python/practice/text.txt', 'r', encoding='utf8')
res = f.read(2)
print(res)
f.close()
f = open('d:/a_code/python/practice/text.txt', 'r', encoding='utf8')
for line in f:
print(f"line = {line}", end='') # end的作用去掉print默认在末尾加的换行符
f.close()- 使用
readlines直接把文件整个内容读取出来,返回一个列表,每个元素即为一行。超大文件还是一行一行的读取
示例:
python
f = open('d:/a_code/python/practice/text.txt', 'r', encoding='utf8')
lines = f.readlines()
print(lines)
f.close()
# 输出结果:['床前明月光\n', '疑是地上霜\n', '举头望明月\n', '低头思故乡\n', '床前明月光']2. 中文的encoding
当文件内容存在中文,读取文件的内容不一定顺利。因为存在多种字符集(常用的GBK和UTF-8)
必须要保证文件本身的编码方式,和 Python 代码中读取文件使用的编码方式匹配
- Python3 中默认打开文件的字符集跟随系统,而 Windows 简体中文版的字符集采用了 GBK,所以文件本身是 GBK 的编码,直接就能正确处理。如果文件本身是其他编码(比如 UTF-8),就会出问题
- 编码为 ANSI , 则表示 GBK 编码。为 UTF-8 , 则表示 UTF-8 编码
示例:编码方式不匹配的解决办法,加参数encoding。显式的指定为同文本相同的字符集,问题即可解决
python
f = open('d:/a_code/python/practice/text.txt', 'r', encoding='utf8')3. 上下文管理器
文件打开之后还是忘记关闭,那么Python提供了上下文管理器,帮助开发人员关闭文件
上下文管理器:
- 使用with语句打开文件
- 当with内部的代码执行完毕后,自动调用关闭方法
示例:
python
with open('d:/a_code/python/practice/text.txt', 'r') as f:
lines = f.readlines()
print(lines[4])
print(type(f))
# 文件类型:<class '_io.TextIOWrapper'>七、 库
库就是别人写好的代码。实际在开发中,也并非所有代码都自己手写,而是充分利用库,简化开发过程。
Python是流行语言,主要原因是因为语法简单方便学习,另一方面是生态完备(有足够丰富的库,应对各种场景)
库分为两大类:
- 标准库:Python自带的库。只要安装了Python就可以直接使用
- 第三方库:其他人实现的库要想使用,需要额外安装
1. 标准库
标准库官网主要内容包括:
- 内置函数 (如 print, input 等)
- 内置类型 (针对 int, str, bool, list, dict 等类型内置的操作)
- 文本处理
- 时间日期
- 数学计算
- 文件目录
- 数据存储 (操作数据库, 数据序列化等)
- 加密解密
- 操作系统相关
- 并发编程相关 (多进程, 多线程, 协程, 异步等).
- 网络编程相关
- 多媒体相关 (音频处理, 视频处理等)
- 图形化界面相关
- ...
①使用import导入模块
所谓的模块就是单独的.py文件,导入模块就是使用import语句把这个外部的.py导入到当前的.py中,并执行其中代码
使用方式:
python
import 模块名②代码示例
日期计算示例:
python
# 1. 三种不同的导入方式+使用
# import datetime
# date1 = datetime.datetime(year=2024, month=5, day=9, hour=21, minute=30)
# date2 = datetime.datetime(year=2025, month=5, day=14, hour=15, minute=40)
# print(date2 - date1)
# from datetime import datetime
# date1 = datetime(year=2024, month=5, day=9, hour=21, minute=30)
# date2 = datetime(year=2025, month=5, day=14, hour=15, minute=40)
# print(date2 - date1)
import datetime as dt
date1 = dt.datetime(year=2024, month=5, day=9, hour=21, minute=30)
date2 = dt.datetime(year=2025, month=5, day=14, hour=15, minute=40)
print(date2 - date1)字符串操作示例:
可以直接使用,不用导入模块
python
# 反转单词顺序
def reverseWords(s:str):
# 指定空格为分隔符,返回结果是一个列表
tokens = s.split()
# 将列表的内容逆序
tokens.reverse()
# 把列表中的内容合并,用空格间隔
return ' '.join(tokens)
print(reverseWords("I am a student!!!"))
python
# 旋转字符串
def rotateString(s:str, goal:str):
# 先判断长度是否相等,然后拼接两个s,判定goal在没在拼接后的字符串内部即可
return len(s) == len(goal) and goal in s + s
print(rotateString('abcde', 'cdeab'))
python
def countPrefixes(words, s:str):
res = 0
for word in words:
# 判断当前字符串是否是s的前缀
if s.startswith(word):
res += 1
return res
print(countPrefixes(["a","b","c","ab","bc","abc"], "abc"))文件查找工具示例 :
示例1:介绍os.walk
python
import os
inputPath = input('输入路径:')
# os.walk每次调用会自动的去针对子目录进行递归,只需要使用循环就可以把所有的文件信息获取
for dirpath, dirnames, filenames in os.walk(inputPath):
# 遍历到当前位置对应的路径
print(f'Path:{dirpath}')
# 当前目录下,都有那些目录,是一个列表
print(f'dirnames:{dirnames}')
# 当前目录下,有哪些文件名,也是一个列表
print(f'filenames:{filenames}')示例2:文件查找
python
import os
inputPath = input('输入路径:')
pattern = input('搜索关键词:')
# 不需要获取的元素,可以使用占位符
for dirpath, _, filenames in os.walk(inputPath):
for f in filenames:
if pattern in f:
print(f'Path:{dirpath}/{f}')2. 第三方库
第三方库太多了,所以当我们遇到一个需求场景是就需要搜索了。确定之后可以用pip安装第三方库。
①使用pip
pip:python内置的包管理器,即应用商店。也是一个可执行程序,在Python的安装目录中。Python官方提供的一个网站搜集第三方库
打开cmd(或者Python命令行、PyCharm终端)直接输入pip,显示相关信息就证明pip可以使用。
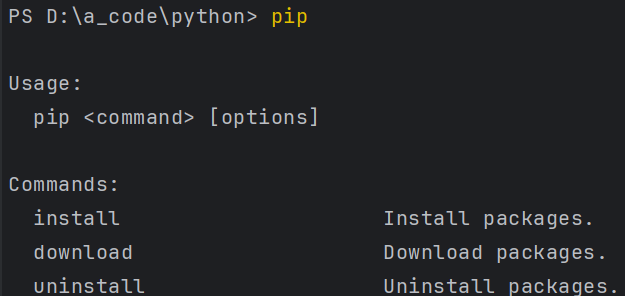
如果提示:'pip'不是内部或外部命令,也不是可运行的程序或批处理文件。那就是当初安装Python时没有勾选Add Python ... to PATH。就是没有配置环境变量,这里建议卸载重新安装
使用以下命令,即可安装第三方库。如果安装完成后,PyCharm提示找不到对应的模块,则可能是因为安装了多个版本的Python。直接搜索 Python Interpreter更改版本
python
pip install [库名]②代码示例:二维码和操作excel
二维码:
- 第一步:通过搜索引擎搜索是哪一个库,得到结果:
qrcode - 第二步:去Python提供的官方网站搜索
qrcode - 第三步:安装,看文档
示例:
python
import qrcode
img = qrcode.make('吴某真好看')
img.save('qrcode.jpg')操作excel: 加入一个年级有很多班,且所有班级同学都是杂乱排序,选择数个班求其平均分
- 第一步:通过搜索引擎搜索使用那个库才能完成任务,结果:读取excel使用
xlrd模块。修改excel使用xlwt模块。该需求只需要读取即可 - 第二步:去Python提供的官方网站搜索
xlrd - 第三步:安装(
pip install xlrd==1.2.0)指定版本号,最新版不支持xlsx格式的文件
示例:
python
# 1. 首先要打开文件
xlsx = xlrd.open_workbook('C:/Users/kkkkkkkkkkkkkkkkkkkk/Desktop/新建 Microsoft Excel 工作表.xlsx')
# 2. 获取标签页,只有一个Sheet1所以直接获取0号标签页。我们也可以命名获取
# table = xlsx.sheet_by_name('Sheet1')
table = xlsx.sheet_by_index(0)
# 3. 获取总行数
nrows = table.nrows
# 4. 遍历数据
count = 0
total = 0
for i in range(1, nrows):
# 使用 cell_value(row, col)获取指定坐标单元格的值,这里第一行和第一列我们不使用
classId = table.cell_value(i, 1)
if classId == 100:
count += 1
total += table.cell_value(i, 2)
print(total / count)补充
-
模块
在Python中,如果想引入其他模块,需要先使用import语句,把模块导入进来。PyCharm有个功能能够自动导入当前使用的模块,如
import random。random、sys、time都是Python中的一个模块(别人写的,我们直接用)①
random.randint(1, 6)生成一个1, 6的随机数。②
sys.exit(0)退出程序③
time.sleep(1)使程序暂停执行1s -
变量重命名:
shift+F6可以把所有需要修改的地方统一替换(可能要搭配Fn使用) -
PyCharm的调试器
①插入断点
②
shift+F9进入调试。每次执行到断点停止③
F7可以逐行执行代码 -
打包成exe程序发布
需要借助
pyinstaller来把Python程序打包成 exe 程序①安装:
pip install pyinstaller②打包程序:
pyinstall -F [文件名].py-F表示打包成单个exe(不带动态库)