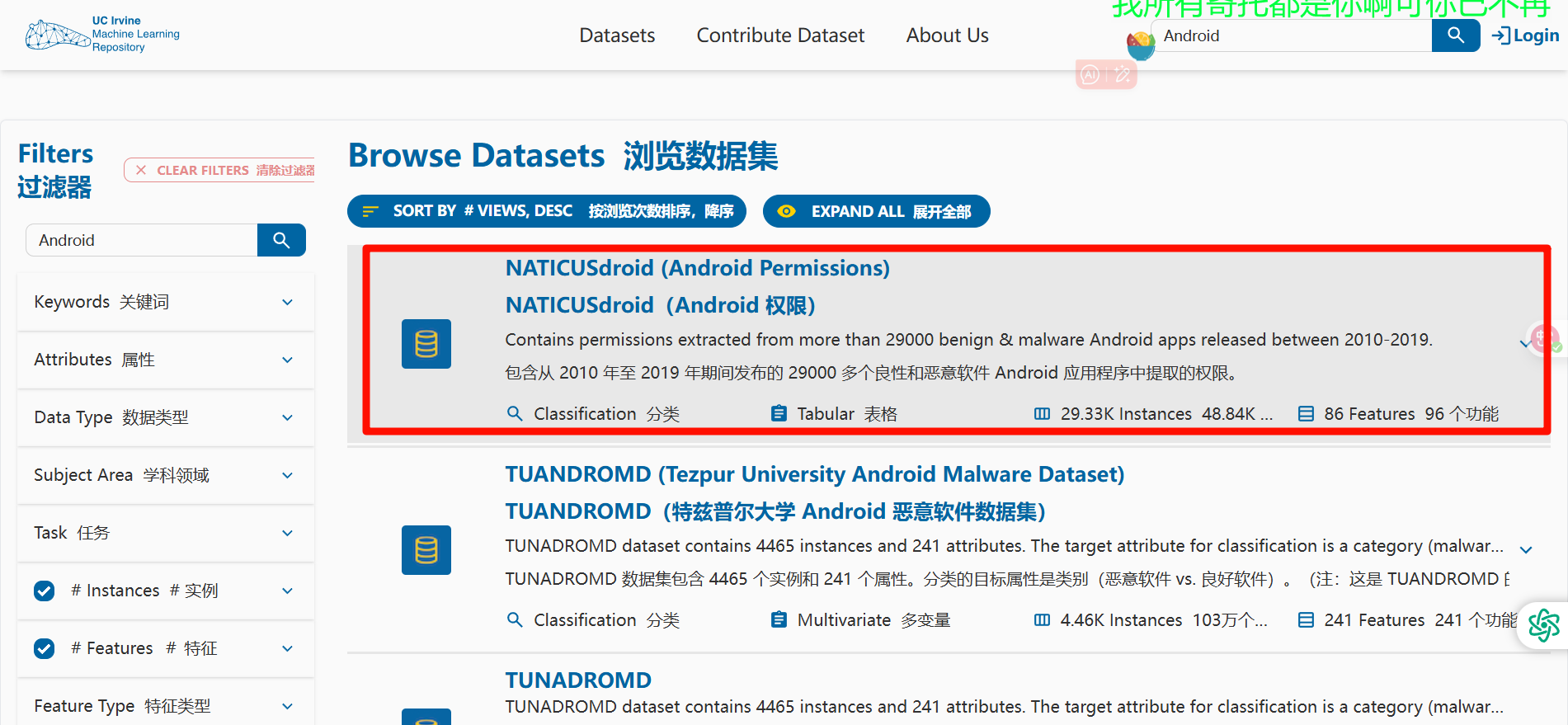
挑选数据集
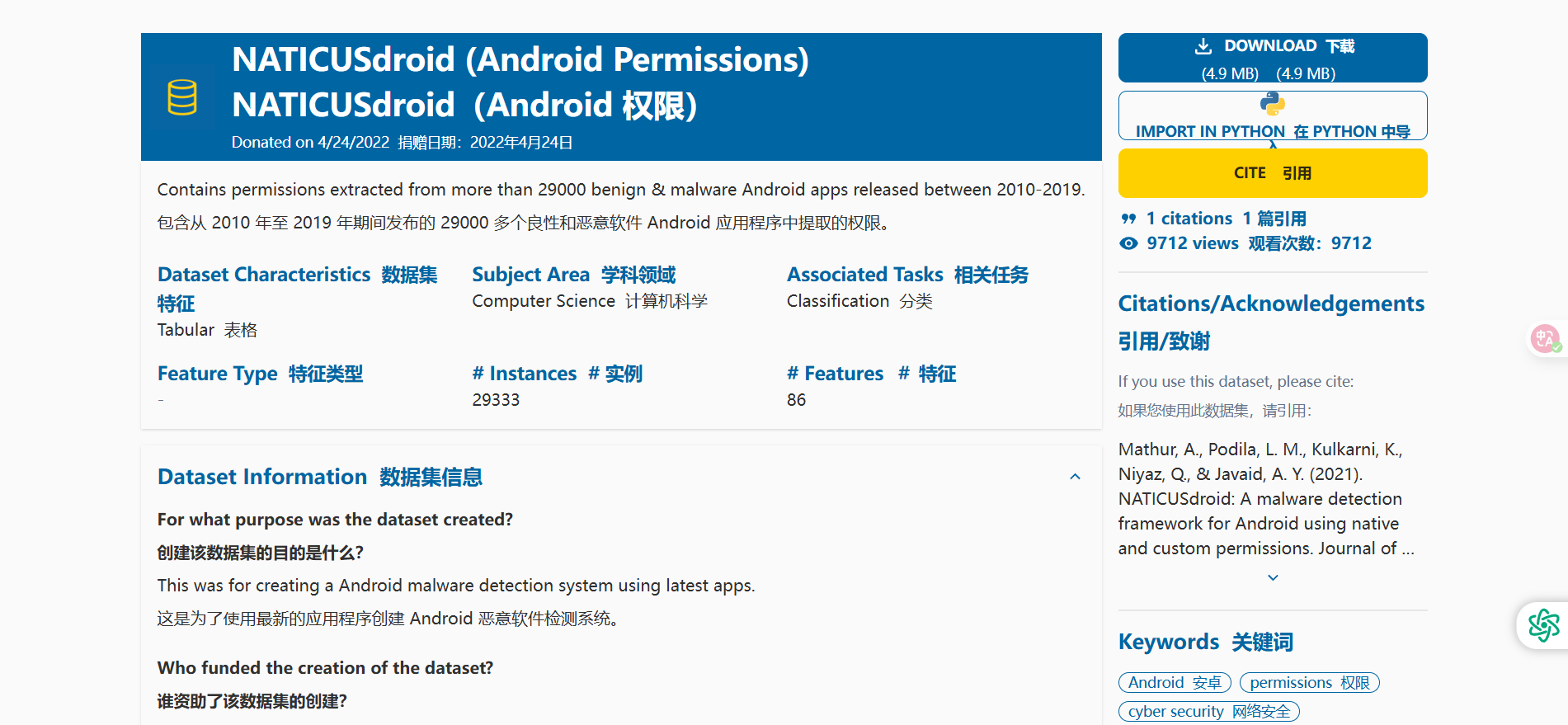
使用python模块导入数据集
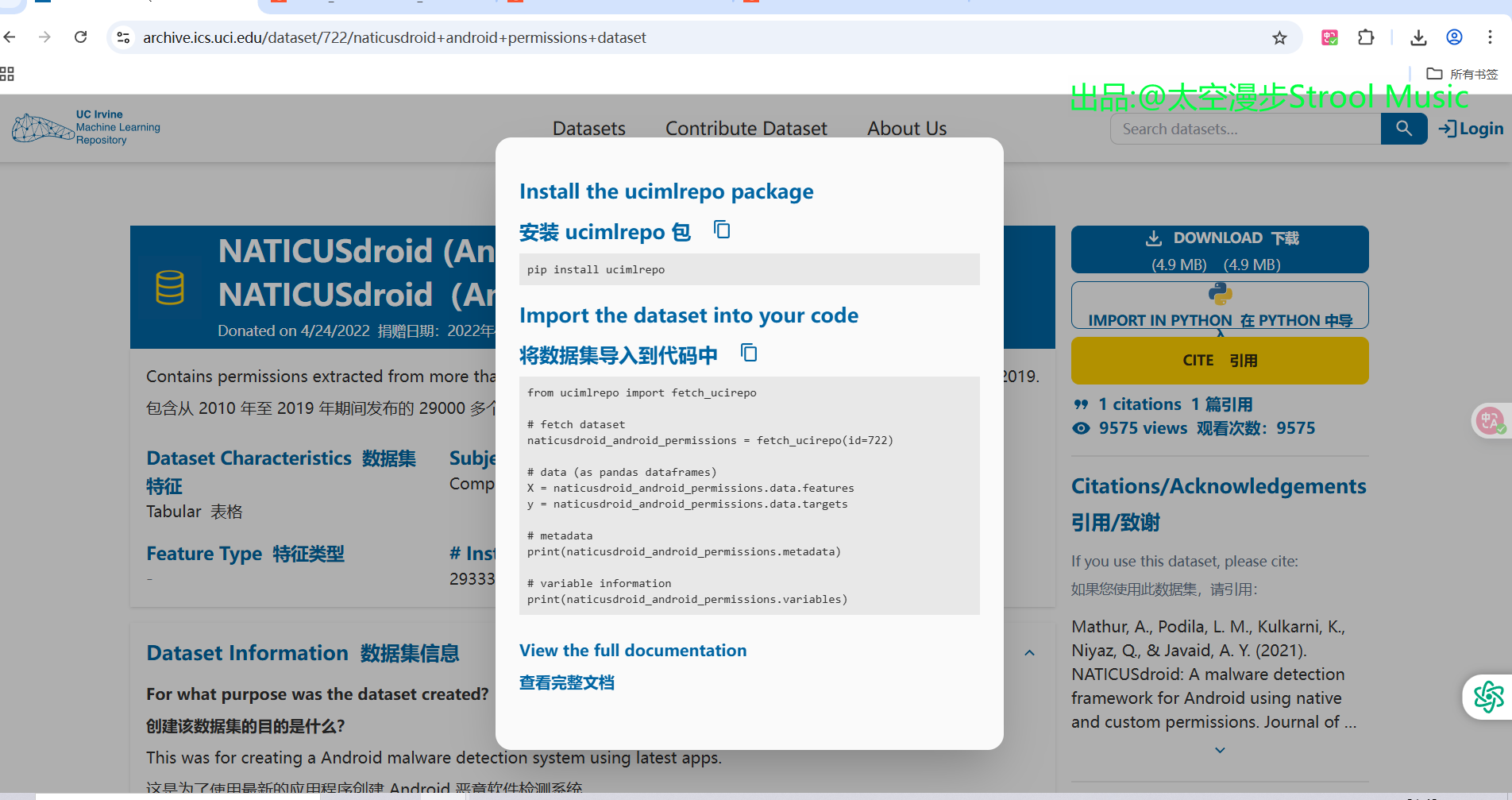
导入数据集
python
from ucimlrepo import fetch_ucirepo
# fetch dataset
# 数据集--NATICUSdroid(Android 权限)
naticusdroid_android_permissions = fetch_ucirepo(id=722)
# data (as pandas dataframes)
# 数据特征
X = naticusdroid_android_permissions.data.features
# 目标数据
y = naticusdroid_android_permissions.data.targets
# metadata
# 打印数据集的元数据信息
# 元数据包含了关于数据集的一些基本描述,例如数据集的名称、来源、创建时间、数据类型等
# 这些信息有助于我们更好地理解数据集的背景和特点
print(naticusdroid_android_permissions.metadata)
# variable information
# 打印数据集中变量的信息
# 变量信息会详细描述数据集中每个特征和目标变量的含义、数据类型、取值范围等
# 这对于我们了解数据集的结构和特征非常有帮助
print(naticusdroid_android_permissions.variables) 查看数据集
python
#查看数据规模
print(f"样本数量:{X.shape[0]},特征数量:{X.shape[1]}")
#查看目标变量分布
print("\n目标变量分布:")
#检查y的列名
#y.columns
print (y['Result']. value_counts(normalize=True))
bash
# 查看变量信息表的列名
print(naticusdroid_android_permissions.variables.columns.tolist())