一、背景
项目中对性能要求极高,因此使用多级缓存,最终方案决定是Redis+Caffeine。其中Redis作为二级缓存,Caffeine作为一级本地缓存。
二、Caffeine简单介绍
Caffeine是一款基于Java 8的高性能、灵活的本地缓存库。它提供了近乎最佳的命中率,低延迟的读写操作,并且支持多种缓存策略,号称本地缓存之王。
核心特性
- Caffeine的底层数据存储采用ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突严重时也能有良好的读性能。
- Caffeine采用了先进的缓存淘汰算法,如Window TinyLfu,以提供极高的缓存命中率和低延迟的读写操作。
- Caffeine支持多种缓存策略,包括过期时间、容量限制和引用权重等。用户可以根据实际需求,为不同的缓存对象设置合适的策略,以优化缓存性能。
- Caffeine内部采用了细粒度的锁机制(ConcurrentHashMap),保证了缓存的线程安全。用户无需担心并发访问导致的缓存一致性问题。
- Caffeine允许用户为缓存对象添加监听器,以便在缓存事件发生时(如创建、更新、删除等)执行自定义逻辑。
清除策略
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限。
java
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();- 基于时间:设置缓存的有效时间
java
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
java
// 构建cache对象
Cache<String, String> cache = Caffeine.newBuilder()
.weakKeys().weakValues().build();Caffeine.weakKeys() 使用弱引用存储key。如果没有强引用这个key,则GC时允许回收该条目
Caffeine.weakValues() 使用弱引用存储value。如果没有强引用这个value,则GC时允许回收该条目
Caffeine.softValues() 使用软引用存储value, 如果没有强引用这个value,则GC内存不足时允许回收该条目

三、Window TinyLfu算法浅析
最让人吃惊的是,Caffeine的性能甚至超越了java中自身的map等内存。这是因为它采用的算法Window TinyLfu提供了一个近乎最佳的命中率,在此简单介绍一下Caffeine采用的核心算法,不想看的也可以跳过这部分。
W-TinyLFU(Window Tiny Least Frequently Used)算法是对传统LFU算法的优化与增强。
算法流程如下:当一个新数据进入时,首先会经过筛选比较,进入W-LRU窗口队列。这一设计旨在应对流量突增的情况。经过W-LRU窗口队列的筛选后,数据会进入过滤器。在过滤器中,算法会根据数据的访问频率来判断是否应将其加入缓存。若某个数据的最近访问次数较低,则被视为在未来被访问的可能性也较低。当缓存空间不足时,这些访问频率低的数据将优先被淘汰。
W-TinyLFU的优点在于:
- 它使用Count-Min Sketch算法来存储访问频率,这种算法极大地节省了存储空间。
- 通过定期衰减操作,算法能够灵活应对访问模式的变化。
- W-LRU机制有助于避免缓存污染,确保高频访问的数据得以保留。
- 过滤器内部的筛选处理能够有效防止低频数据替换高频数据。
然而,W-TinyLFU也存在一些局限性。它是由谷歌工程师发明的算法,目前主要应用于Caffeine Cache组件,应用范围相对有限。
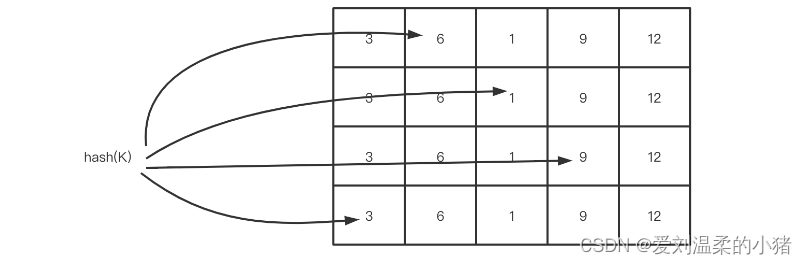
关于Count-Min Sketch算法,它可视为与布隆过滤器具有同源性的算法。传统上,使用hashmap来存储每个元素的访问次数可能会导致较大的存储开销,并且在hash冲突时需要进行额外处理以避免数据误差。而Count-Min Sketch算法通过多个hash操作降低了hash冲突的概率。当获取元素频率时,该算法会找到多个索引位置,并取其中的最低值作为元素的频率,即Count Min的含义所在。
下图展示了Count-Min Sketch算法简单的工作原理:
- 假设有四个hash函数。每当元素被访问时,其对应的计数会加1。
- 算法会根据这四个hash函数计算元素的位置,并在相应位置进行加1操作。
- 当需要获取元素的访问频率时,同样通过hash计算找到四个索引位置,并获取这些位置的频率信息。
- 最后,根据Count Min原则,选择这四个频率中的最低值作为元素的最终频率值返回。
三、实际应用
首先展示一下总体的思路流程图:

此篇文章不涉及到多容器下的本地Caffeine缓存同步的问题,后续会在本篇文章基础上写同步相关的处理手段。目前来看,大部分系统的本地缓存都不需要同步。
1、首先引入pom依赖
java
<!-- Caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>2、封装Caffeine相关的API
因为caffeine的api比较杂乱,为了统一管理和方便使用,我们需要对caffeine常用的api进行封装处理。
创建一个interface接口用作封装,代码如下:
java
/**
* @description: Caffeine封装接口
* @author: chenggh
* @date: 2024/3/22
*/
public interface CaffeineCache<K, V> {
/**
* put
*
* @param key
* @param value
*/
void put(K key, V value);
/**
* get
*
* @param key
* @return
*/
V get(K key);
/**
* 判断是否包含K
*
* @param key
* @return
*/
boolean containsKey(K key);
/**
* 判断是否包含V
*
* @param value
* @return
*/
boolean containsValue(V value);
/**
* 移除某个K
*
* @param key
*/
void remove(Object key);
/**
* 查询缓存命中,驱逐等数量
*
* @return
*/
CacheStats cacheStats();
/**
* 清除全部(性能较慢,考虑场景使用)
*/
void clear();
/**
* 转成MAP
*
* @return
*/
ConcurrentMap<K, V> asMap();
/**
* 获取values
*
* @return
*/
Collection<V> values();
/**
* 获取缓存大小
*
* @return
*/
long size();
/**
* 主动回收已失效的缓存
*
* @return
*/
void cleanUp();
/**
* 当缓存中有这个key就使用key对应的value值 如果没有就使用默认的value
*
* @return
*/
V getOrDefault(K k, V v);
/**
* entrySet
*
* @return
*/
Set<Map.Entry<K, V>> entrySet();
}3、编写Caffeine封装API实现类,并将初始化的过程抽象进去。
- maximumSize:最大容量,超过会自动清理。
- removalListener:监听器,当缓存对象发生变更时会被监听到,key,value ==> 键值对 cause ==> 清理原因。
- expireAfterWrite:全局时间淘汰策略,此处设置最后一次写入或访问后经过固定时间过期
其余参数说明:
initialCapacity 初始的缓存空间大小
maximumSize 缓存的最大条数
maximumWeight 缓存的最大权重
expireAfterAccess 最后一次写入或访问后,经过固定时间过期
expireAfterWrite 最后一次写入后,经过固定时间过期
refreshAfterWrite 写入后,经过固定时间过期,下次访问返回旧值并触发刷新
weakKeys 打开 key 的弱引用
weakValues 打开 value 的弱引用
softValues 打开 value 的软引用
recordStats 缓存使用统计
expireAfterWrite 和 expireAfterAccess 同时存在时,以expireAfterWrite 为准。
weakValues 和 softValues 不可以同时使用。
maximumSize 和 maximumWeight 不可以同时使用。
java
/**
* @description: Caffeine封装API实现类
* @author: chenggh
* @date: 2024/3/22
*/
public class CaffeineCacheLocal<K, V> implements CaffeineCache<K, V> {
private final Cache<K, V> localCache;
private RemovalListener<? super K, ? super V> removalListener;
private long maximumSize = -1L;
private long duration = -1L;
private TimeUnit unit;
public CaffeineCacheLocal() {
localCache = initCache();
}
public CaffeineCacheLocal(RemovalListener<? super K, ? super V> removalListener, long maximumSize, long duration, TimeUnit unit) {
if (removalListener != null) {
this.removalListener = removalListener;
}
if (unit != null) {
this.unit = unit;
}
this.duration = duration;
this.maximumSize = maximumSize;
this.localCache = initCache();
}
/**
* 初始化
*
* @return
*/
private Cache<K, V> initCache() {
Caffeine<Object, Object> caffeine = Caffeine.newBuilder();
//暂时未加入权重逻辑 所以maximumSize必须设定
//若加入权重逻辑后,可以根据是否有权重判断处理
if (this.maximumSize <= 0L) {
throw new RuntimeException("maximumSize is must be set");
}
//key的最大条数
caffeine.maximumSize(this.maximumSize);
//expireAfterWrite全局时间淘汰策略,此处设置最后一次写入或访问后经过固定时间过期
if (this.duration > 0L && this.unit != null) {
caffeine.expireAfterWrite(this.duration, this.unit);
}
//开启淘汰监听
if (this.removalListener != null) {
caffeine.removalListener(this.removalListener);
}
// 初始的缓存空间大小,可以不设置
//caffeine.initialCapacity(100);
return caffeine.build();
}
@Override
public void put(K key, final V value) {
localCache.put(key, value);
}
@Override
public V get(K key) {
if (Objects.nonNull(key)){
return localCache.getIfPresent(key);
}
return null;
}
@Override
public boolean containsKey(K key) {
return asMap().containsKey(key);
}
@Override
public boolean containsValue(V value) {
return asMap().containsValue(value);
}
@Override
public void remove(Object key) {
localCache.invalidate(key);
}
@Override
public CacheStats cacheStats() {
return localCache.stats();
}
@Override
public void clear() {
localCache.invalidateAll();
}
@Override
public ConcurrentMap<K, V> asMap() {
return localCache.asMap();
}
@Override
public Collection<V> values() {
return asMap().values();
}
@Override
public long size() {
return localCache.estimatedSize();
}
@Override
public void cleanUp() {
localCache.cleanUp();
}
@Override
public V getOrDefault(K k, V defaultValue) {
V v;
return ((v = get(k)) != null) ? v : defaultValue;
}
@Override
public Set<Map.Entry<K, V>> entrySet() {
return asMap().entrySet();
}
public static Builder<Object, Object> newBuilder() {
return new Builder<>();
}
public static class Builder<K1, V1> {
private RemovalListener<? super K1, ? super V1> removalListener;
private long maximumSize;
private long duration;
private TimeUnit unit;
public Builder<K1, V1> removalListener(RemovalListener removalListener) {
this.removalListener = removalListener;
return this;
}
public Builder<K1, V1> maximumSize(long maximumSize) {
this.maximumSize = maximumSize;
return this;
}
public Builder<K1, V1> expireAfterWrite(long duration, TimeUnit unit) {
this.duration = duration;
this.unit = unit;
return this;
}
public <K extends K1, V extends V1> CaffeineCache<K, V> build() {
return new CaffeineCacheLocal<>(removalListener, maximumSize, duration, unit);
}
}
}4、编写自定义配置类,方便IOC容器注入使用实现类对象
在这里我定义了两个一级缓存的bean对象,因为我们前边已经封装好了api方法和初始化配置,可以根据自己需求进行定义和注入。
java
@Configuration
public class CacheConfig {
private static Logger log = LoggerFactory.getLogger(CacheConfig.class);
@Bean
public CaffeineCache<String, String> localStringCache() {
return CaffeineCacheLocal.newBuilder()
.maximumSize(800)
.expireAfterWrite(2, TimeUnit.MINUTES)
.removalListener((key, value, cause) -> {
/*log.info("[移除缓存] key:{} reason:{}", key, cause.name());
if (cause == RemovalCause.SIZE) {
log.info("超出最大缓存");
}
if (cause == RemovalCause.EXPIRED) {
log.info("超出过期时间");
}
if (cause == RemovalCause.EXPLICIT) {
log.info("显式移除");
}
if (cause == RemovalCause.REPLACED) {
log.info("旧数据被更新");
}*/
})
.build();
}
@Bean
public CaffeineCache<Long, Map<String,String>> localMapCache() {
return CaffeineCacheLocal.newBuilder()
.maximumSize(50)
.expireAfterWrite(1, TimeUnit.MINUTES)
.removalListener((key, value, cause) -> {
// log.info("移除了Map-key:" + key + " value:" + value + " cause:" + cause);
})
.build();
}
}5、使用
- 查询
java
/**
* 接口调用频率限制查询
* @param key
* @return
*/
public RateLimitRule getRateLimitRule(String key) {
key = key + ":limitation";
String rl = localStringCache.get(key);
if(!StringUtils.isEmpty(rl)) {
log.info("走一级缓存");
return JSON.parseObject(rl, RateLimitRule.class);
}
rl = redisTemplate.opsForValue().get(key);
if(!StringUtils.isEmpty(rl)) {
localStringCache.put(key, rl);
log.info("走二级redis缓存");
return JSON.parseObject(rl, RateLimitRule.class);
}
return null;
}- 修改
java
/**
* 设置、修改接口调用频率限制
* @param rule
* rule.getApiKey() = application+":"+methodType+":"+uri 远程服务会拼接好此参数进行传递
* @return
*/
public ResultDto updateRateLimitRule(RateLimitRule rule) {
ResultDto resultDto = new ResultDto();
resultDto.setCode(ResultCodeEnum.SUCCESS.getCode());
String key = rule.getApiKey() + ":limitation";
String jsonString = JSON.toJSONString(rule);
redisTemplate.opsForValue().set(key, jsonString);
localStringCache.put(key, jsonString);
// 发布缓存更新消息 --同步到全部容器中,此步在后边做本地缓存同步时说明
caffeineCacheUpdateSubscriber.publishUpdateMessage(key, jsonString, "localStringCache", CommonConstant.REPLACED_TYPE);
return resultDto;
}- 删除
java
/**
* 删除接口调用频率限制
* @param key
* @return
*/
public Boolean delRateLimitRule(String key) {
String key_limit = key + ":limitation";
redisTemplate.delete(key_limit);
localStringCache.remove(key_limit);
// 发布缓存删除消息 --同步到全部容器中,此步在后边做本地缓存同步时说明
caffeineCacheUpdateSubscriber.publishUpdateMessage(key_limit, null, "localStringCache", CommonConstant.DELETE_TYPE);
return true;
}