通过将说话人的声音与数据库中的记录声音进行比对,判断说话人是否为数据库白名单中的同一人,从而完成语音验证。目前,3D-Speaker 声纹验证的效果较为出色。
3D-Speaker 是一个开源工具包,可用于单模态和多模态的说话人验证、说话人识别以及说话人日志分割

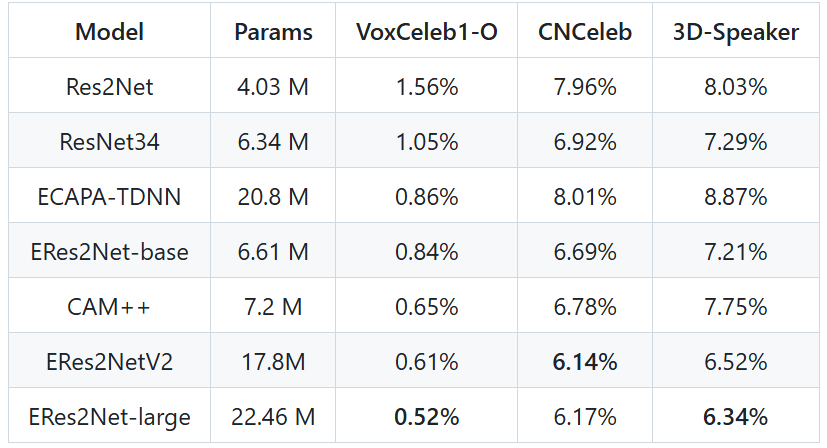
模型使用方法如下:
python
# 声纹识别测试
# 采样率要为16k
from modelscope.pipelines import pipeline
sv_pipeline = pipeline(
task='speaker-verification',
model=r'D:\Downloads\speech_campplus_sv_zh-cn_3dspeaker_16k'
)
speaker1_a_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_3dspeaker_16k/repo?Revision=master&FilePath=examples/speaker1_a_cn_16k.wav'
speaker1_b_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_3dspeaker_16k/repo?Revision=master&FilePath=examples/speaker1_b_cn_16k.wav'
speaker2_a_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_3dspeaker_16k/repo?Revision=master&FilePath=examples/speaker2_a_cn_16k.wav'
# speaker1_a_wav = r'D:\Downloads\ASR-LLM-TTS-master\ASR-LLM-TTS-master\my_recording.wav'
# speaker1_b_wav = r'D:\Downloads\ASR-LLM-TTS-master\ASR-LLM-TTS-master\my_recording_1.wav'
# speaker2_a_wav = r'D:\Downloads\ASR-LLM-TTS-master\ASR-LLM-TTS-master\my_recording_2.wav'
# 相同说话人语音
result = sv_pipeline([speaker1_a_wav, speaker1_b_wav])
print(result)
# 不同说话人语音
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav])
print(result)
# 可以自定义得分阈值来进行识别
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav], thr=0.6)
print(result)