HTTP
全称为"超文本传输协议",由名字可知,这是一个基于文本格式的协议,而TCP,UDP,以太网,IP...都是基于二进制格式的协议。
如何区别该协议是基于哪种格式的协议?
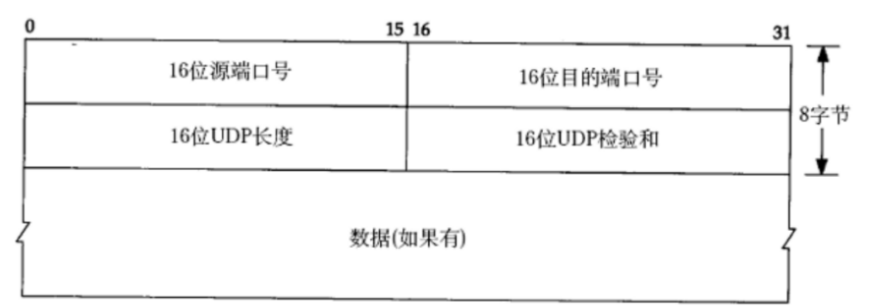
形如这种协议格式,按照xxx个字节,xxx个比特位,这样的方式来安排的妥妥的就是二进制(不涉及任何字符)
超文本:文本包含了一些更复杂的内容,例如图片、视频、音频、特殊字体、链接......
HTTP诞生于1991年,同时,Python,Linux,Vim,Qt(C++知名的库)同时诞生于这一年。
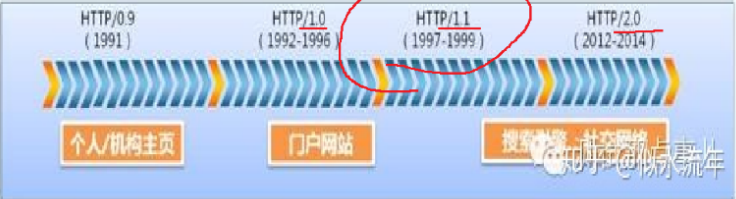
HTTP的各种版本
HTTP是应用层协议,传输层依赖于TCP来进行实现。(HTTP2.0及以前,是基于TCP;到了HTTP3.0,基于UDP)
因为TCP的传输效率更好,但是他的可靠性没有UDP好
HTTP协议,是一个非常经典的"一问一答"模型。
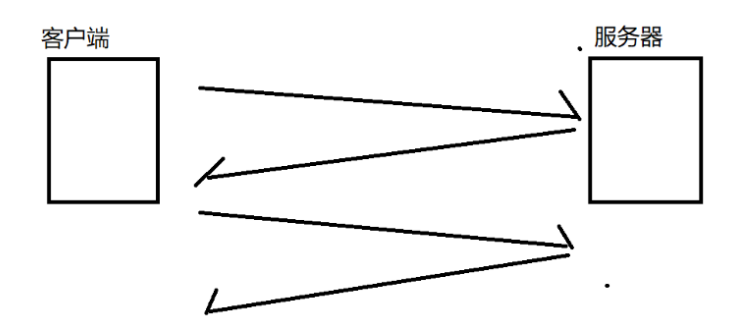
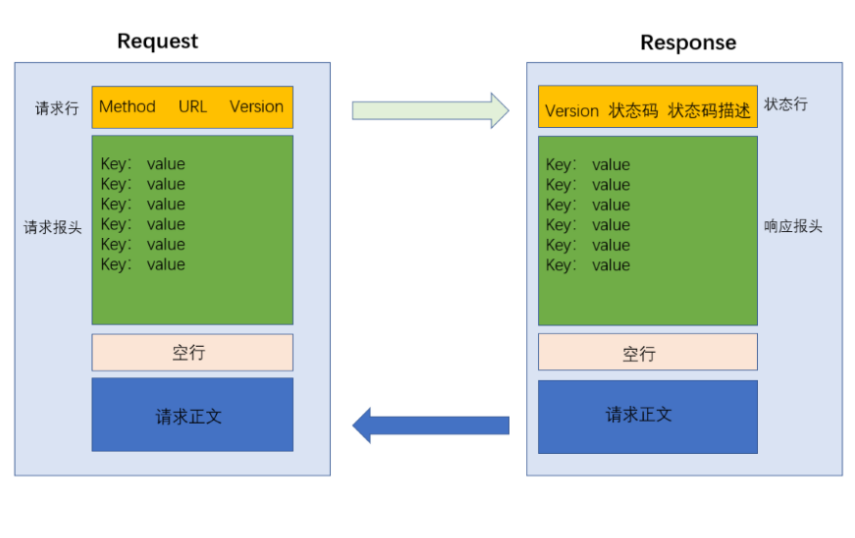
关心HTTP交互过程的时候,应该注重两方面:一方面需要关心HTTP请求是什么样子的,另一方面要关心HTTP响应是什么样子的。而上述二者就构成了HTTP的协议格式。
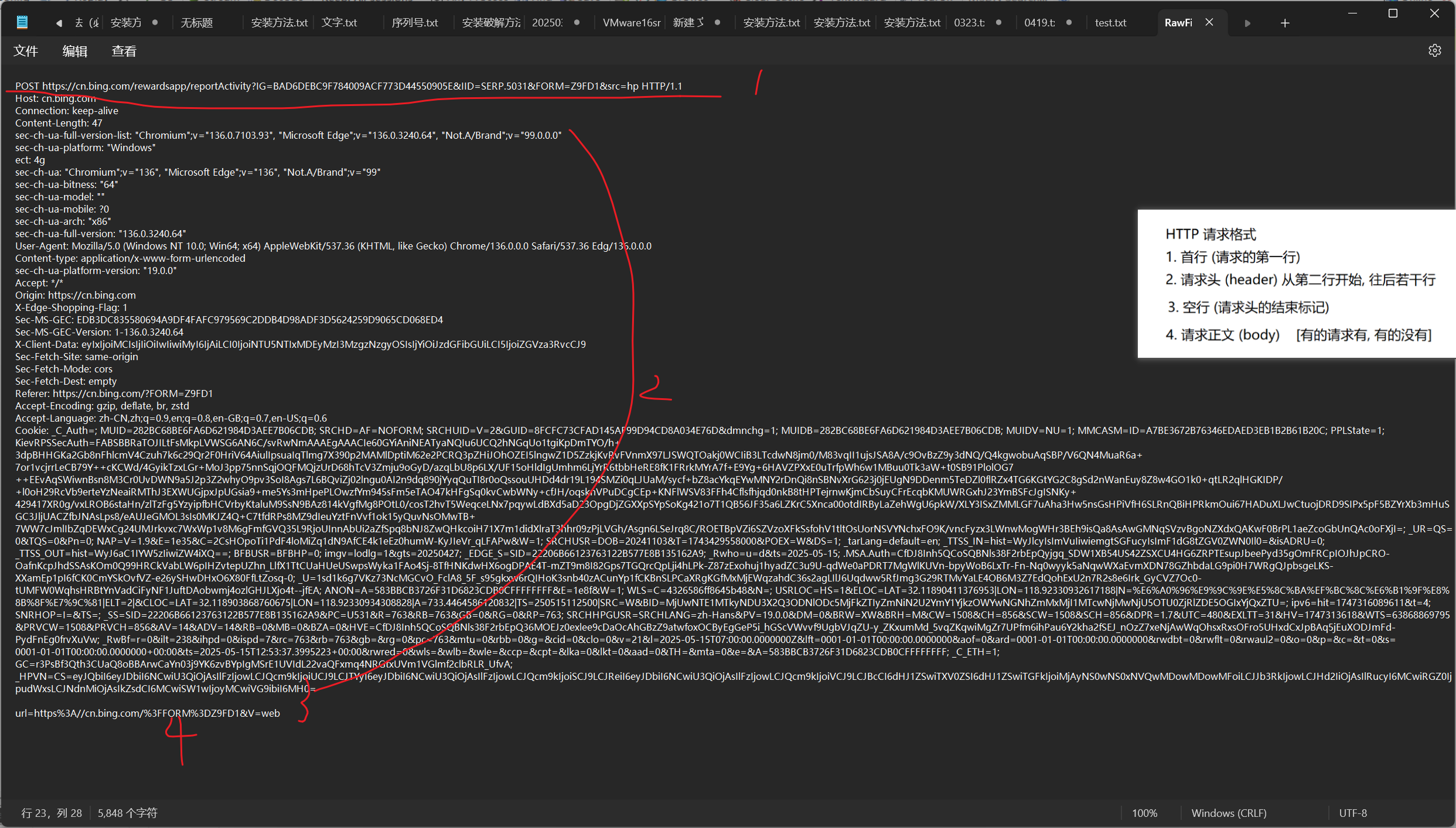
HTTP 请求格式
-
首行 (请求的第一行)
-
请求头 (header) 从第二行开始, 往后若干行
-
空行 (请求头的结束标记)
-
请求正文 (body) 有的请求有, 有的没有
HTTP 响应,可能被压缩的
Content-Encoding: gzip
本来是文本,压缩了就变成二进制了。
网络通信过程中,最贵的硬件资源,就是网络带宽
直接把原始数据进行传输,比较大,消耗的网络带宽就多了。
可以把数据进行压缩,压缩之后数据就变少了,通过网络传输的内容也少了。
数据到了对端再通过 CPU 来进行解压缩
压缩 / 解压缩
压缩包 (rar, zip....) (一系列的压缩算法)
一个不太恰当的例子
比如你的数据
aabbbccccccdddd
压缩后
2a3b4c5d

点击这个条条就能解压缩
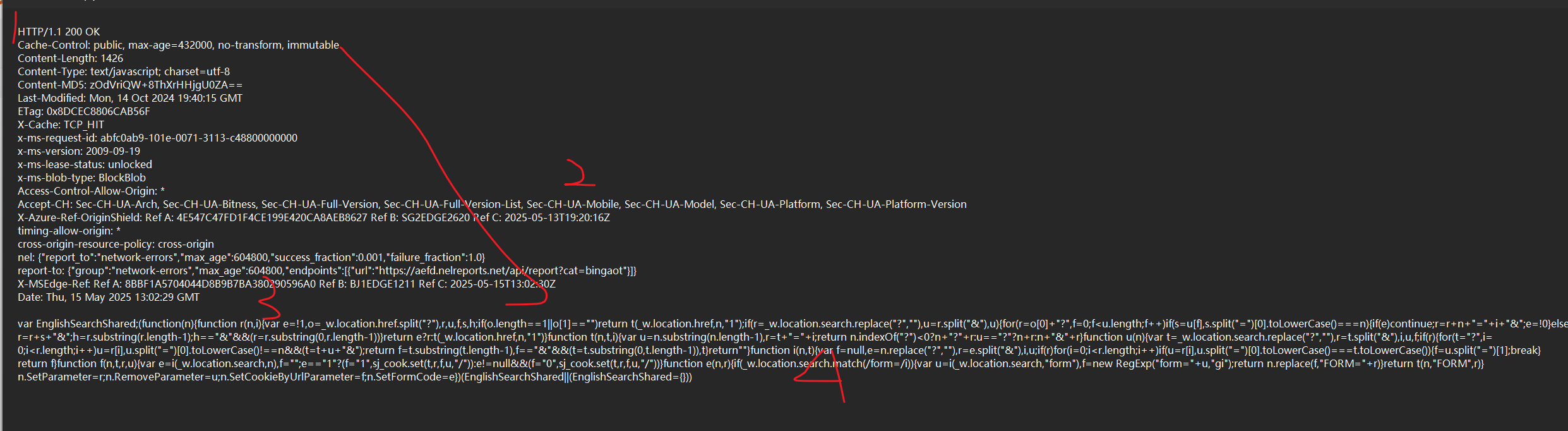
HTTP 响应格式
-
首行
-
响应头 (header)
-
空行 (响应报头的结束标记)
-
正文 (body)
(当前的正文部分就包含了网页的 HTML)
URL

方法(method) URL 版本号
URL:统一资源定位器,描述了网络上的某个资源的具体位置,需要明确访问网络上的哪个资源


登录信息(认证):淘汰了,现在已经没有网站采取这种认证方式了。30年前,采取这样的方式来进行身份认证。
服务器地址:服务器地址
服务器端口:服务器的端口号
带层次的文件路径:path,一个机器上的一个服务器程序,可能管理着很多资源,这些资源可能是真实的文件,还可能是一些"虚拟的""动态生成的"资源(根据请求,计算出来的响应)
查询字符串:query string。请求中的参数,通过参数进行进一步的解释说明。是键值对格式,=分割键和值,通过&分割多个键值对
片段标识符:标识网页的某个部分,实现"页面内跳转功能"。文档类网站会带有这个。
完整的 URL 包含了很多信息
重点关心的主要是 4 个部分
-
IP
-
端口
-
路径
-
查询字符串
https://www.sogou.com/ 只有 IP 地址, 其他的好像都没有。
https://cn.vuejs.org/guide/introduction.html#single-file-components 没有端口, 也没有查询字符串
一个 URL 中, 有些部分是可以省略的
如果没有端口号, 浏览器会给一个默认值
一次通信, 需要
源 IP (浏览器客户端, 端口号, 系统分配的空闲端口)
源端口
目的 IP
目的端口 (URL 中的端口, 描述了你访问的服务器的端口, 不是你浏览器客户端的端口)
URL 中目的端口如果不写, 浏览器会给默认值. 根据协议类型确定.
http:// => 端口给 80 (http 服务器的端口号 也是作为 "知名端口号")
https:// => 端口给 443 (https 服务器的端口号也是 "知名端口号")
带层次的路径也能省略, 省略之后, 其实是一个 /
表示 "根目录"
访问一个服务器管理资源/目录 中的最顶层的目录/资源
通常就对应到一个网站的主页
query string 本来就不是必须的. 都属于程序员自行约定的
片段标识符, 也可以省略(需要页面内跳转, 才设定, 不需要的话就可以省略了)
程序员代码中自定义的(前端内容)
URL encode

url 的 query string 中的 value 部分, 可能需要进行 "转义" 的.
query string 的内容, 程序员可以自定义 (尤其是 value)
如果 value 中包含特殊符号, 就可能使 url 的解析出现错误.
url 中的特殊符号有特定含义.
中文也需要转义 (中文通过 utf8/gbk 之类的编码格式表示的, 有可能某个汉字的
utf8/gbk 编码中的某个字节, 恰好和某个特殊符号的 ascii 码相同了 还是可能造成误会)
转义的规则非常简单
把特殊符号的 ascii 取出来, 按照字节维度, 插入一些 %
上述 utf8 的编码解码 过程不需要手动实现
都有专门的库来进行
如果需要放中文/符号, 需要主动进行 url encode
否则, 浏览器/服务器可能解析失败