继续流水账完这本书,这个案例是打造文字形式的个人知识库雏形。
create_context_db:
python
# Milvus Setup Arguments
COLLECTION_NAME = 'text_content_search'
DIMENSION = 2048
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
# Inference Arguments
BATCH_SIZE = 128
from pymilvus import MilvusClient,utility,connections
milvus_client = MilvusClient(uri="http://localhost:19530")
# Connect to the instance
connections.connect(host=MILVUS_HOST,port=MILVUS_PORT)
from markdown_processor import vectorize_segments,split_html_into_segments
test_embedding = vectorize_segments(split_html_into_segments("<h1>RAG还是挺有意思的!</h1>"))
embedding_dim = len(test_embedding[0]) #原始的test_embedding的len结构是[[],[]]的形式
print(embedding_dim)
print(test_embedding[:10])
# Remove any previous collection with the same name
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
milvus_client.create_collection(
collection_name=COLLECTION_NAME,
dimension=embedding_dim,
metric_type="IP", # Inner product distance
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
)
#下面这个手法可以直接读取md文件,然后向量化存系统。
#from tqdm import tqdm
#data = []
#from glob import glob
#text_lines = []
#for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
# with open(file_path, "r") as file:
# file_text = file.read()
# text_lines += file_text.split("# ")
#
#for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
# data.append({"id": i, "vector": vectorize_segments(split_html_into_segments(line)), "text": line})
#
#milvus_client.insert(collection_name=COLLECTION_NAME, data=data)markdown_processor.py 这个文件如今大可不必了。
python
import markdown
from bs4 import BeautifulSoup #用于解析和操作HTML文档
from transformers import AutoTokenizer,AutoModel #用于自动加载预训练的模型以及分词器
import torch #用于深度学习计算
def markdown_to_html(markdown_text):
return markdown.markdown(markdown_text)
def split_html_into_segments(html_text): #定义函数,将HTML文档分割成多个段落
soup = BeautifulSoup(html_text,"html.parser") #解析HTML文档
segments = [] #初始化一个列表用于存储分割后的段落
#找HTML文档中的段落,标题,无序列表和有序列表标签
for tag in soup.find_all(["h1","h2","h3","h4","h5","h6","p","ul","ol"]):
segments.append(tag.get_text())
return segments
#定义函数,用于将文本段落转换为向量表示
def vectorize_segments(segments):
# 使用预训练的分词器和模型,这里使用的是BAAI/bge-large-zh-v1.5 一个中文模型
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-large-zh-v1.5")
model = AutoModel.from_pretrained("BAAI/bge-large-zh-v1.5")
model.eval() #将模型定位评估模式,避免dropout等训练模式下的参数
#使用分词器对文本段落进行编码,添加必要的填充和截断,并返回PyTorch张量格式
encoded_input = tokenizer(segments,padding=True,truncation=True,return_tensors="pt")
with torch.no_grad():
model_output = model(**encoded_input) #将编码后的输入传递给模型,获取模型的输出
sentence_embeddings = model_output[0][:,0] #从模型输出中提取句子向量化的结果
#对句子的量化结果进行L2归一化,以便于后续的相似度比较或聚类分析
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings,p=2,dim=1)
return sentence_embeddings
python
from flask import Flask,request,jsonify
from flask import render_template
import requests
from markdown_processor import markdown_to_html, split_html_into_segments, vectorize_segments
from pymilvus import MilvusClient
import logging
import os
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
COLLECTION_NAME = 'text_content_search'
TOP_K = 3
app = Flask(__name__)
milvus_client = MilvusClient(uri="http://localhost:19530")
@app.route("/")
def index():
return render_template("index.html")
@app.route('/upload', methods=['POST'])
def upload():
if 'file' not in request.files:
return jsonify({'error': 'No file part in the request'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': 'No file selected for uploading'}), 400
markdown_text = file.read().decode('utf-8')
html_text = markdown_to_html(markdown_text)
segments = split_html_into_segments(html_text)
vectors = vectorize_segments(segments)
# 将向量上传到数据库
data = []
for i, (segment, vector) in enumerate(zip(segments, vectors)):
data.append({"id": i + 1,"vector": vector.tolist(), "text": segment})
milvus_client.insert(collection_name=COLLECTION_NAME, data=data)
return jsonify({'message': '文件已处理并上传向量到数据库'})
@app.route('/search', methods=['POST'])
def search():
data = request.get_json()
search_text = data.get('search')
# 添加前缀到查询字符串
instruction = "为这个句子生成表示以用于检索相关文章:"
search_text_with_instruction = instruction + search_text
# 向量化修改后的查询
search_vector = vectorize_segments([search_text_with_instruction])[0].tolist()
search_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[
search_vector
],
limit=3, # Return top 3 results
search_params={"metric_type": "IP", "params": {}}, # Inner product distance
output_fields=["text"], # Return the text field
)
# 构建与 LLM API 交互的消息列表
messages = [
{"role": "system",
"content": "You are a helpful assistant. Answer questions based solely on the provided content without making assumptions or adding extra information."}
]
# 解析搜索结果
for index,value in enumerate(search_results):
#print(value)
text = value[0]["entity"]["text"]
print(text)
messages.append({"role": "assistant", "content": text})
messages.append({"role": "user", "content": search_text})
# 向 deepseek 发送请求并获取答案 (用的silicon flow)
url = "https://api.ap.siliconflow.com/v1/chat/completions"
payload = {
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-14B",
"messages": messages,
"stream": False,
"max_tokens": 1000,
"stop": None,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 10,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {"type": "text"},
}
headers = {
"Authorization": "Bearer <#你自己的token>",
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
answer = response.text
return jsonify({'answer': answer})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5020, debug=True)吐槽一下,silicon flow这种deepseek API免费问不到几个,就开始算钱咯。
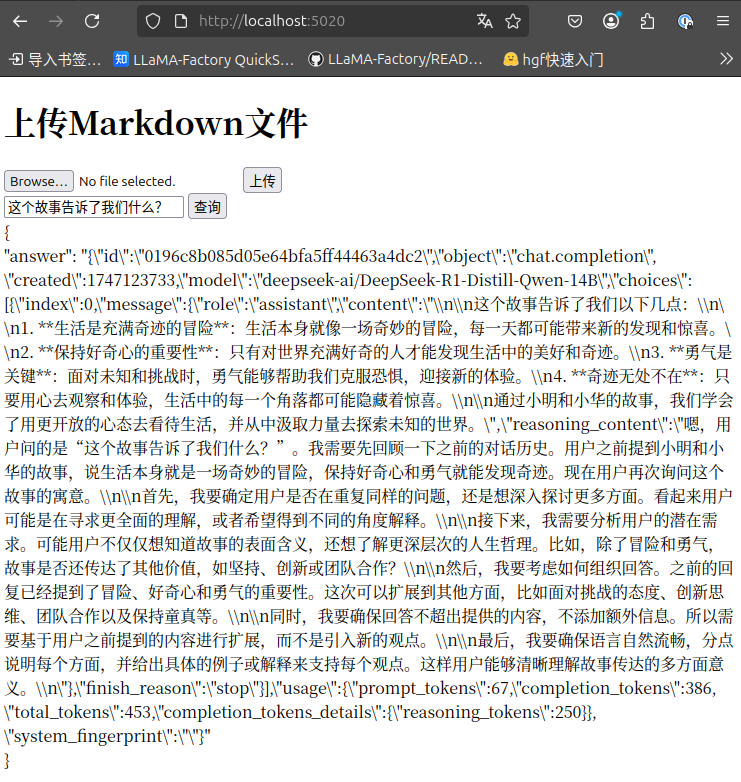
小网站结构,以及其他杂代码,可以查看以及直接下载:https://www.ituring.com.cn/book/3305