智能交互能力正逐渐成为后台系统的重要组成部分,尤其在企业级应用中,大模型接入与管控已成为一项基础设施建设需求。
本文介绍一款专为 Dv3Admin 平台打造的插件 dv3admin_chatgpt,围绕模型接入、额度配置、调用分类与使用追踪构建完整方案,为 Django 系统提供即插即用的自然语言能力支持。
文章目录
功能展示
本插件围绕"大语言模型能力接入与精细化管理"构建了一套完整的后台控制方案,从 用户额度配置(积分用户) 、模型接入(GPT 配置) 、场景调用(分类管理) 到 使用追踪(积分记录) ,构成闭环。
管理员可以通过这套机制快速接入主流模型厂商的 API,灵活控制每位用户的调用权限与额度,提供标准化的业务场景模板支持,同时实现对调用行为的全面监控与可视化统计。
| 模块名称 | 功能说明 | 核心作用与场景 |
|---|---|---|
| 积分用户 | 管理系统用户的模型使用额度与充值记录 | 同步系统用户,支持手动分配 Token,监控使用量,避免滥用,便于成本控制 |
| GPT 配置 | 配置各大模型厂商的 API 接入参数与服务能力 | 快速接入 OpenAI、通义、文心等厂商模型,支持多模型能力分类与默认路由配置 |
| 分类管理 | 提供 1000+ 预设文本模板,支持自定义 Prompt 配置 | 一键调用高质量模板,按业务场景分类,支持自定义提示词与调用参数 |
| 积分记录 | 记录每次模型调用行为及 Token 消耗详情 | 精确追踪调用来源、消耗额度、模型类型,为分析优化与费用统计提供数据支撑 |
无论你是为内网部署提供接口封装,还是为 SaaS 应用构建可控的 AI 能力接入层,该插件都具备即插即用、易维护、可扩展的优势,适用于大多数企业级模型应用管理场景。
积分用户
该模块用于统计并管理系统用户在调用大语言模型(如 ChatGPT)服务过程中的 Token 消耗情况,帮助管理员精准掌握各用户的使用额度与历史记录。点击 "同步用户信息" 按钮,系统将自动从当前后台用户表中导入用户数据,生成对应的积分用户记录。同步操作无需手动添加,确保数据实时一致。
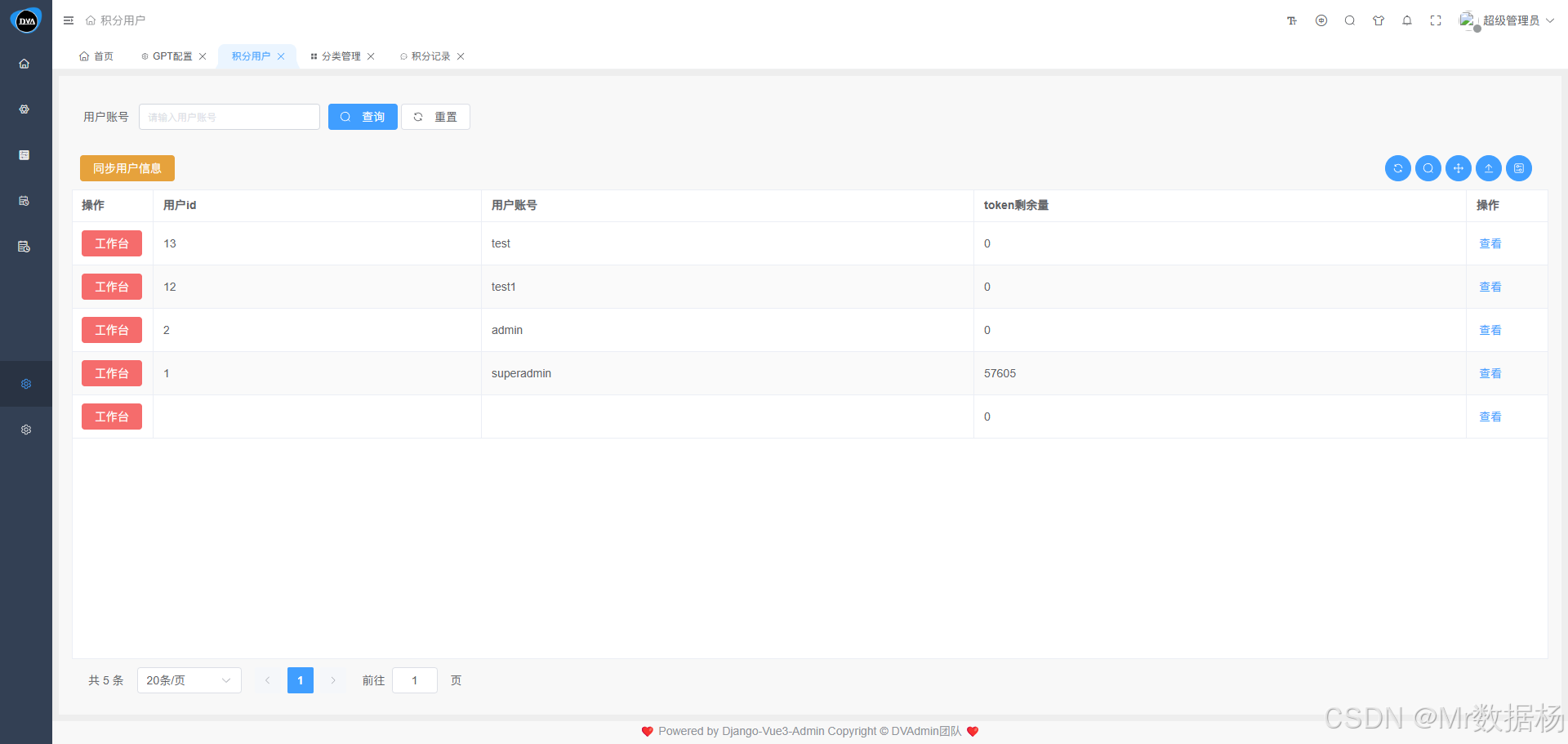
在工作台页面,管理员可以为每位用户分配 Token 使用额度,类似于"充值积分"。用户在使用 ChatGPT 等模型进行问答、生成内容等操作时,将按实际消耗从余额中扣除。该机制既能限制过度调用,又方便追踪成本开销。
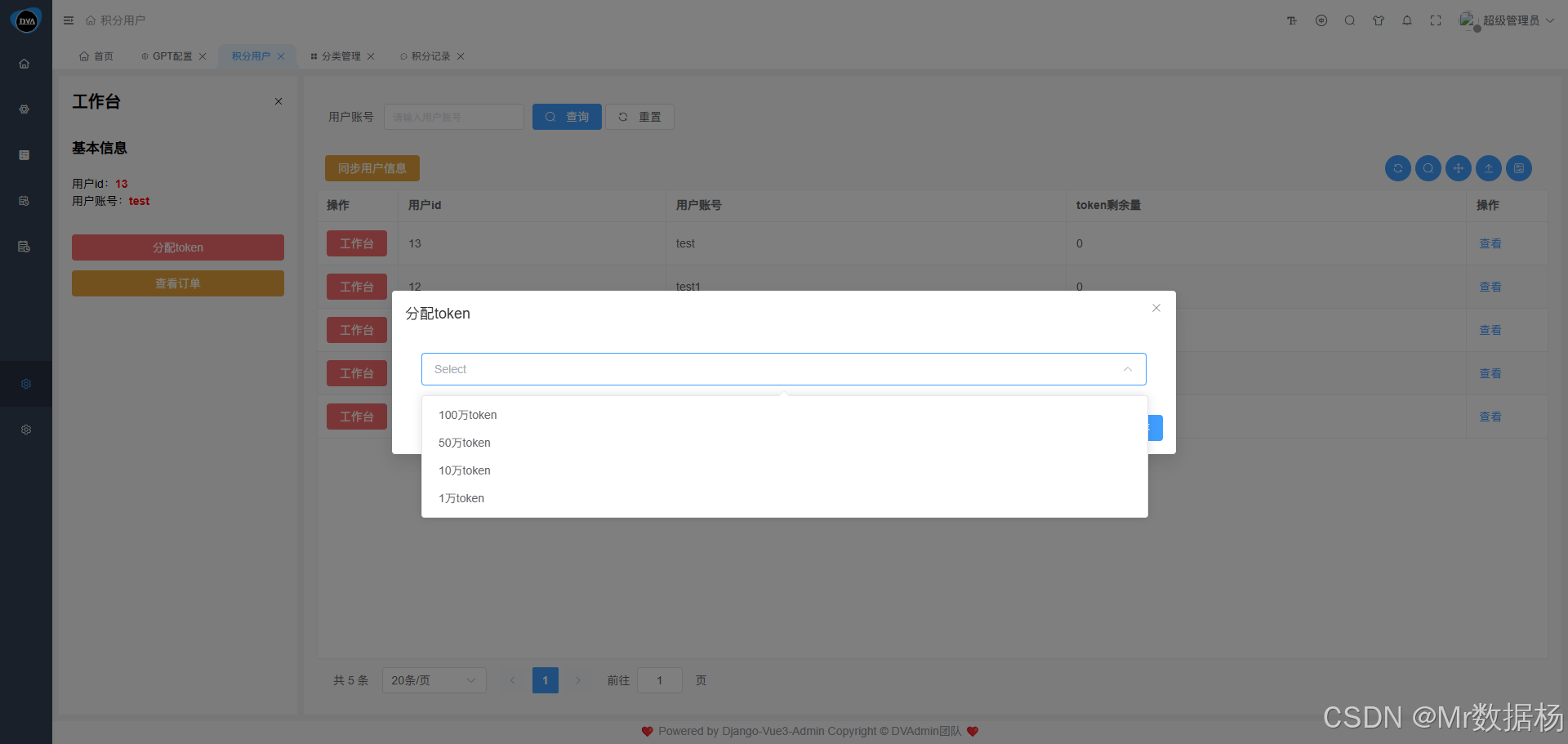
点击"查看订单"按钮可进入充值记录页面,支持查看所有用户的充值订单详情,包括时间、金额、备注信息等。该页面方便管理员审核充值行为、核对账单、导出报表等操作。
GPT配置
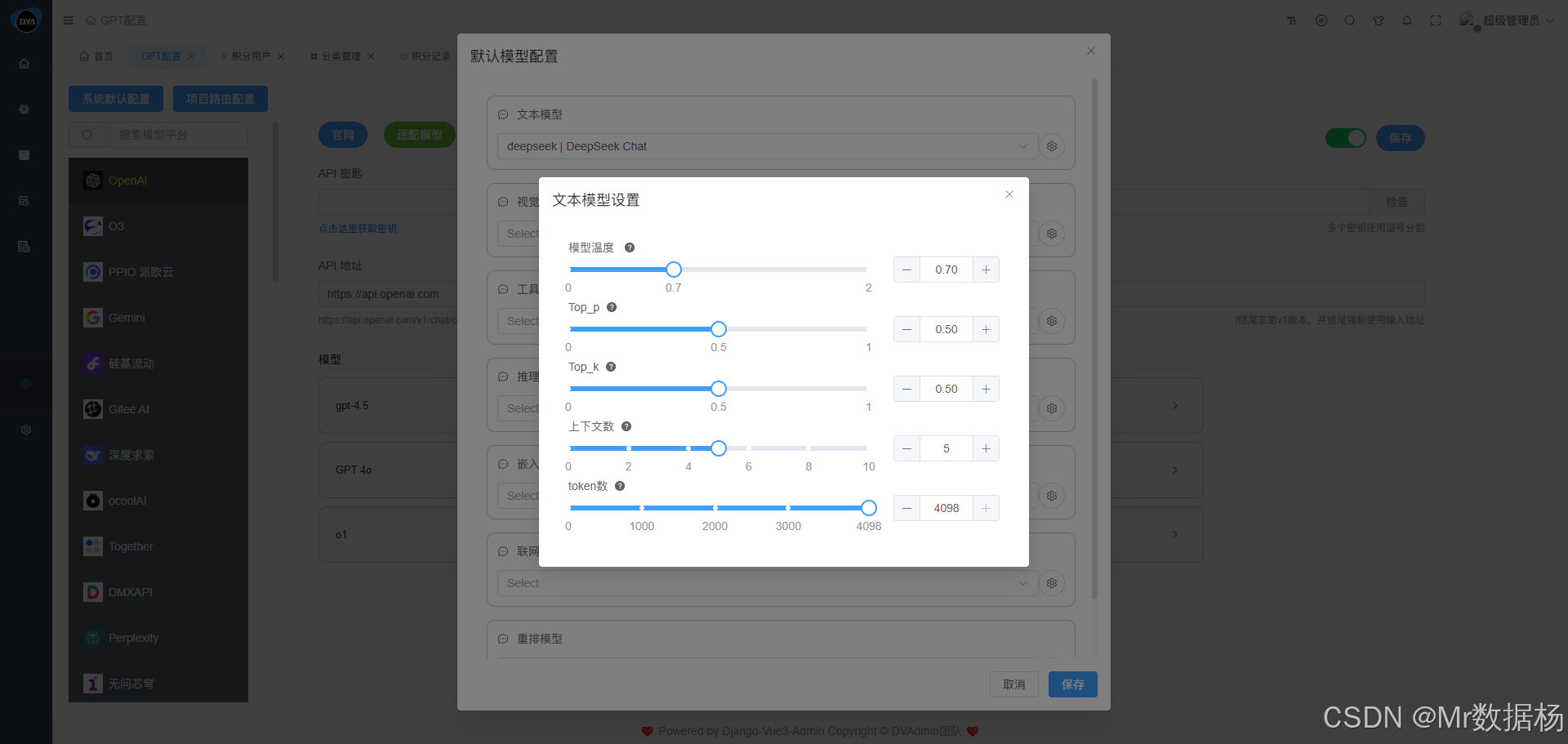
该模块用于统一管理系统支持的大模型厂商及其 API 接入配置,便于开发者与管理者对接第三方模型服务如 OpenAI、文心一言、通义千问等。系统会根据内置的初始化数据预配置主流模型厂商的服务信息。大多数情况下,API 地址已默认填写 ,用户只需手动输入或粘贴各厂商提供的 API 密钥(API Key) 即可完成认证接入。
⚠️ 修改或新增配置信息后,请务必点击右上角的 "保存" 按钮以生效。
保存成功后,系统将自动解析并展示当前接口支持的模型名称列表及其对应能力。
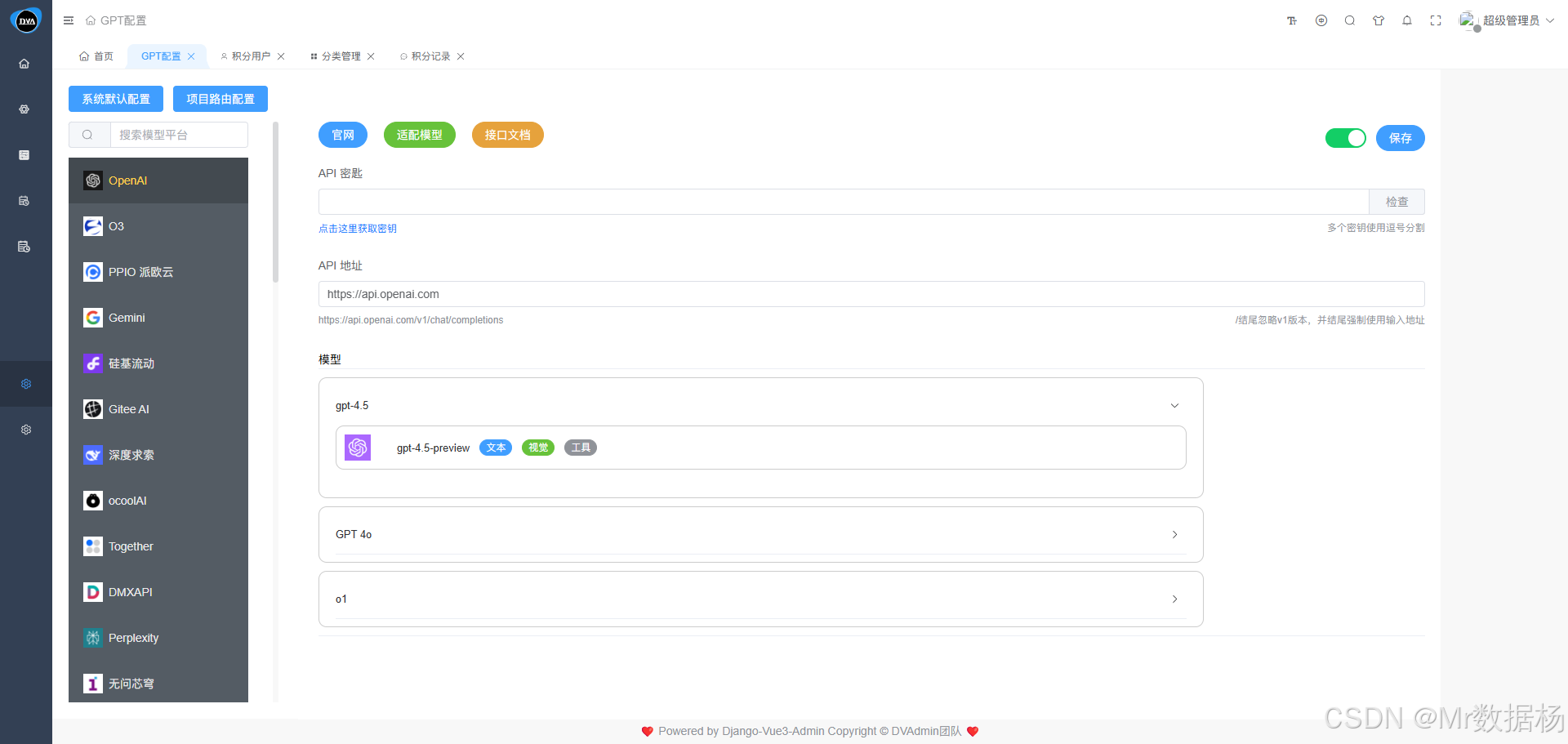
每个模型服务实例保存成功后,系统会根据其所支持的 能力标签 进行分类。下拉选择器中仅展示支持当前功能类型的模型,确保业务调用时不出错。
| 模型类型 | 功能说明 | 典型应用场景 |
|---|---|---|
| 文本模型 | 处理自然语言任务,如生成、对话、摘要等 | 聊天机器人、内容生成、文本改写 |
| 视觉模型 | 图像相关任务,如生成图片、图像识别等 | 生成插画、识图问答、图文生成 |
| 推理模型 | 执行结构化判断与逻辑推理任务 | 表格理解、自动分类、问卷判断 |
| 嵌入模型 | 将文本转化为向量,用于语义匹配与相似度计算 | 搜索引擎、知识库检索、相似问题推荐 |
| 联网模型 | 支持实时联网搜索,获取外部最新信息 | 实时问答、新闻摘要、数据补全 |
| 工具模型 | 调用外部函数或插件,执行具体操作 | 自动化脚本、插件联动、任务执行 |
| 重排模型 | 优化候选结果的排序,提升推荐或搜索准确性 | 智能推荐系统、搜索结果优化 |
只需选择匹配的模型能力,保存后即可供接口调用使用。
页面中提供快捷入口,可跳转至厂商官网或查看该模型的接口文档。
| 按钮 | 功能描述 |
|---|---|
| 官网 | 可跳转至模型厂商官网,了解产品背景与业务介绍。 |
| 适配模型 | 展示当前厂商所支持的模型接口(如 GPT-4、ERNIE-Bot、Qwen 等)。 |
| 接口文档 | 链接至官方 API 文档,方便开发者参考调用规范。 |
该模块还支持配置默认的模型路由信息,用于对接系统外部的 API 请求调用场景。例如,第三方工具类平台、低代码应用等若需调用当前后台统一管理的大模型服务,可通过此处配置访问入口与默认模型。
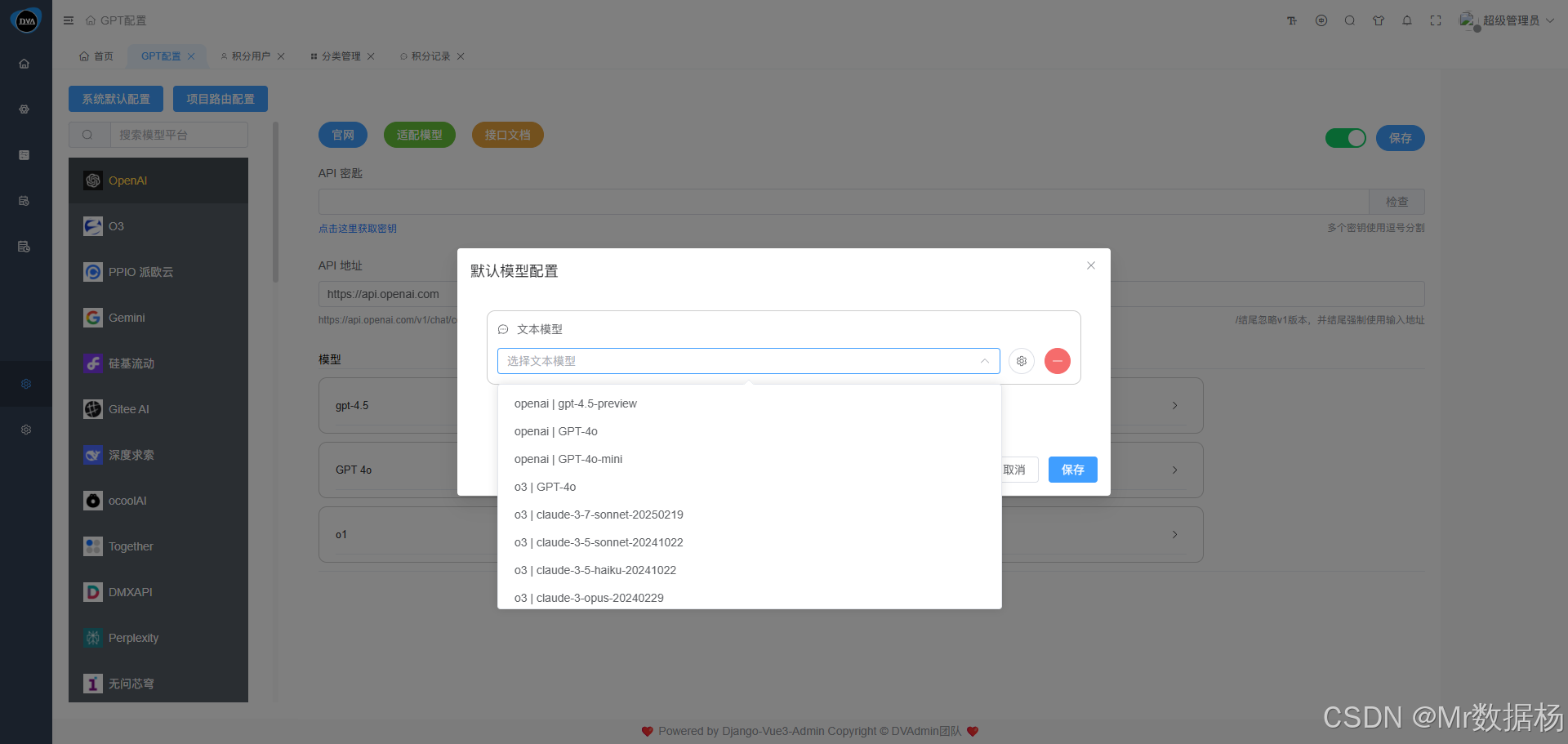
分类管理
系统内置了 1000+ 种 GPT 文本使用模板,根据初始化数据自动分类配置,覆盖常见业务场景,如内容生成、问答提示、数据摘要、代码生成、营销文案等,方便开发者或运营人员快速调用合适的模型能力。
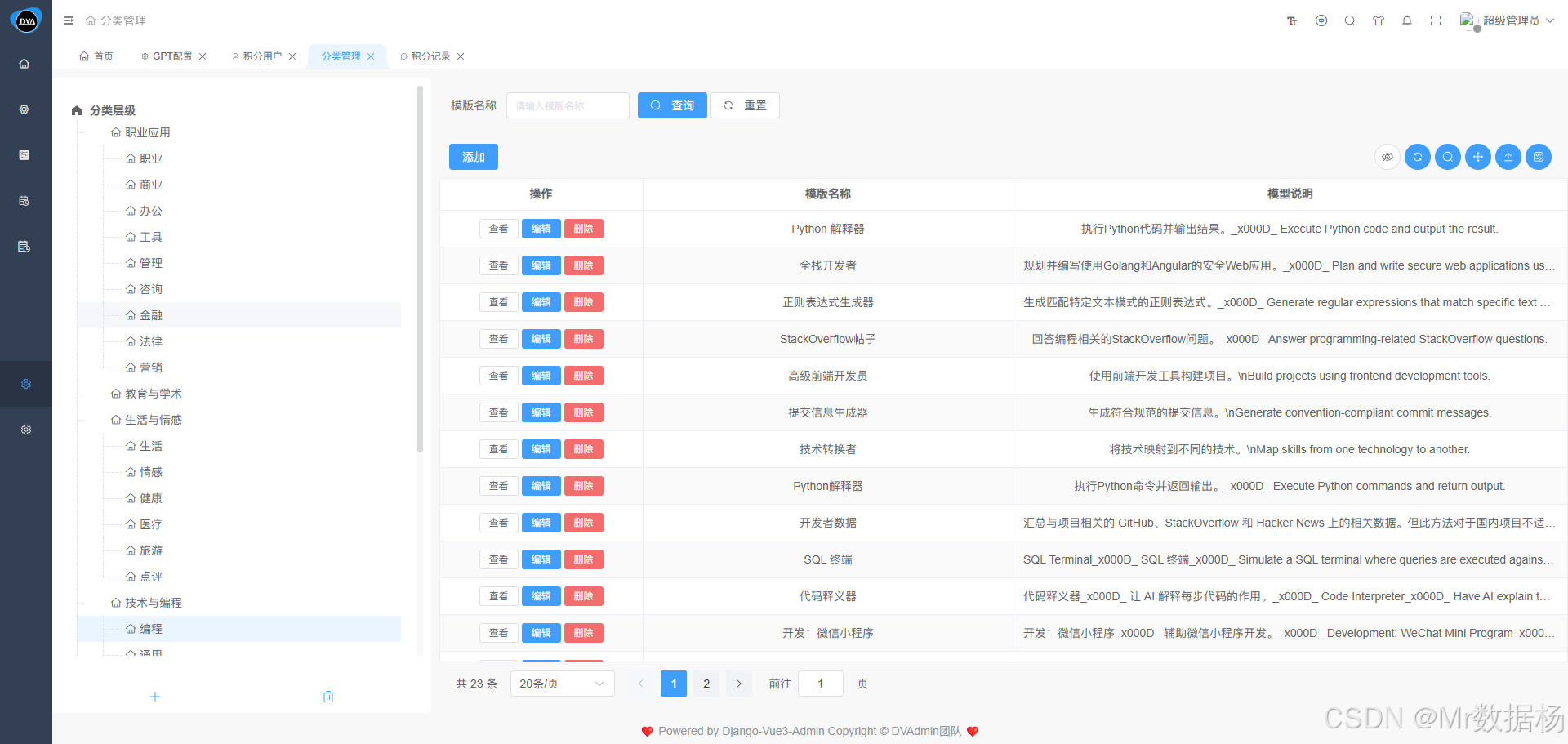
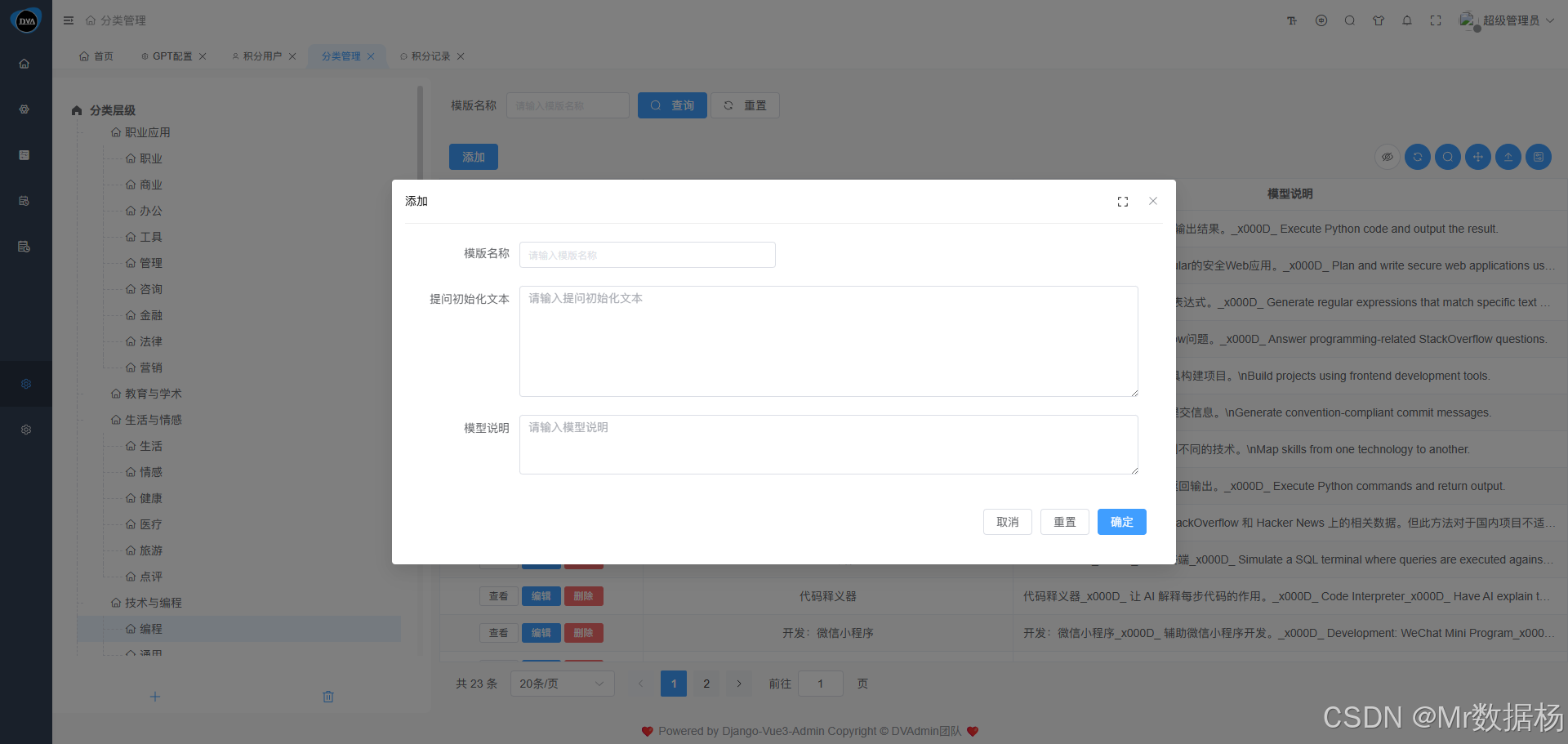
除了系统默认提供的模板外,用户也可以根据自身业务需求 自行创建模板,设置自定义提示词(Prompt),然后绑定绑定业务分类与用途标签即可。
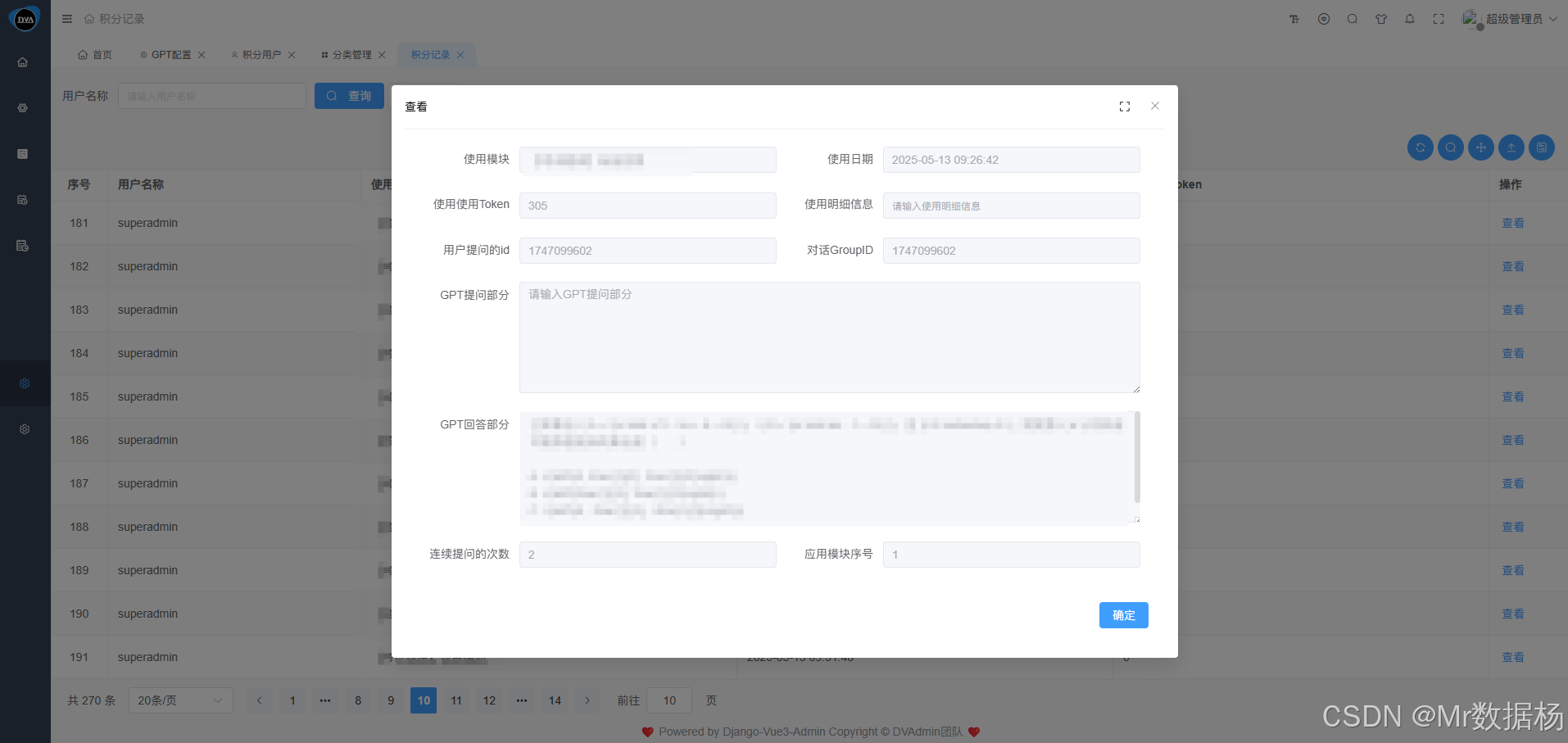
积分记录
该模块用于详细记录用户在系统中调用各类模型接口时的 Token 消耗情况,包括每一次请求的模型类型、调用时间、消耗额度、所属应用等关键信息。
快速上手
解压插件包放置 dv3admin 项目 plugins 目录下。
bash
dv3admin_chatgpt/
├── fixtures/ # 初始化数据(如模板导入、默认配置)
├── management/ # Django 自定义管理命令
├── migrations/ # 数据库迁移脚本
├── setting_data/ # 插件配置项、模型初始化配置
├── static/ # 前端静态资源(JS、CSS、图标等)
├── views_app/ # 后端视图逻辑模块
├── web/
│ └── dv3admin_chatgpt/ # Web 端交互组件或独立子应用(如前端集成页面)
├── .gitignore # Git 忽略配置
├── __init__.py # Python 包初始化
├── apps.py # Django 应用注册入口
├── models.py # 数据模型定义
├── README.md # 项目说明文档
├── settings.py # 插件级别的配置(如默认参数)
├── urls.py # URL 路由配置将 web 文件夹下的 dv3admin_chatgpt 复制到前端的 src/views/plugins 目录下即可。
在 application/settings.py 中添加下面的内容即可。
python
# ********** 一键导入插件配置开始 **********
from plugins.dv3admin_chatgpt.settings import * # ChatGPT配置在项目根目录下执行以下命令以完成模型配置、菜单注册和静态资源加载:
bash
python manage.py init_chatgpt初始化完成后将输出如下内容:
bash
✅ ChatGPT 菜单初始化完成
✅ ChatSetting 初始化完成
✅ ChatCategory 初始化完成
✅ ChatModel 初始化完成
✅ 静态文件 初始化完成完成以上步骤后,即可在后台系统中看到 ChatGPT 插件菜单并开始使用。
应用开发
管理后台项目内应用
如果想在管理后台中开发一个直接可以调用当前插件的应用模块,例如在某个模块嵌入使用当前功能进行内容生成。
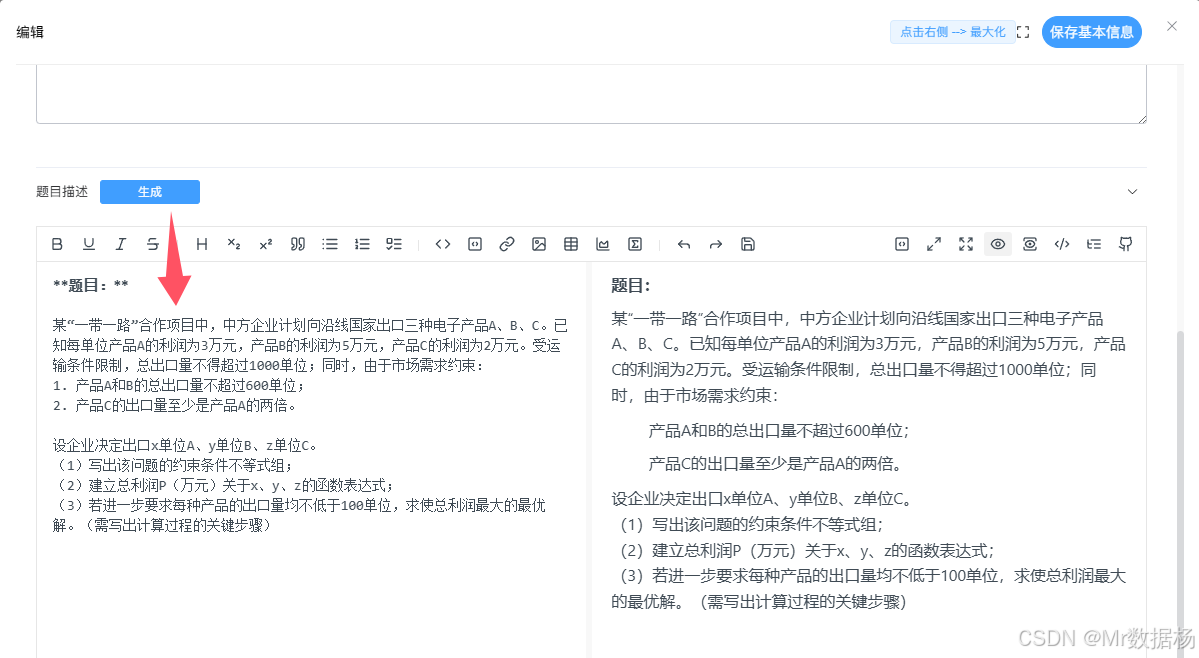
在后端创建 ChatStreamDemo.py
后端代码实现了一个统一的对话请求入口 。通过 URL 中的 chat_model_id 动态分发不同模型配置,调用 handle_chat_request 执行实际问答逻辑。question_info 是用于生成初始提示词和唯一对话分组 ID 的辅助函数,当前以时间戳为 ID,占位式 prompt 可后续拓展为模板驱动。
接口采用 @api_view 装饰,集成了 JWT 鉴权 和 CSRF 豁免,适合生产级别安全调用。
python
import time
from dvadmin.utils.json_response import SuccessResponse, ErrorResponse
from rest_framework.decorators import api_view, authentication_classes, permission_classes
from rest_framework.permissions import IsAuthenticated
from rest_framework_simplejwt.authentication import JWTAuthentication
from django.views.decorators.csrf import csrf_exempt
from plugins.dv3admin_chatgpt.views_app.ChatStream import handle_chat_request
def question_info(request, chat_model_id):
group_id = int(time.time())
q = getattr(request, 'query_params', request.GET)
question_info_prompt = "根据模板后续提问信息"
return question_info_prompt, group_id
@csrf_exempt
@api_view(['GET'])
@authentication_classes([JWTAuthentication])
@permission_classes([IsAuthenticated])
def chat_use_model(request, chat_model_id):
"""
通用接口,根据 URL 中的 chat_model_id 自动分发。
"""
try:
question_info_prompt, group_id = question_info(request, chat_model_id)
except ValueError as e:
return ErrorResponse(msg=str(e))
return handle_chat_request(request, chat_model_id, question_info_prompt, group_id)同级模块下修改 urls.py 注册一个接口路径 /ChatStream/chat_use_model/<chat_model_id>/,外部应用可直接调用此路径,通过指定模型 ID 实现统一入口接入不同语言模型。
python
from rest_framework.routers import DefaultRouter
from django.urls import path
from modules.Config.views_app.ChatStream import chat_use_model
router = DefaultRouter()
urlpatterns = [
path('ChatStream/chat_use_model/<str:chat_model_id>/', chat_use_model, name='chat_use_model'),
]
urlpatterns += router.urls使用 runserver 启动开发环境是可行的,可以实现SSE流显示,其他启动方式暂时都不行需要修改,可以
bash
daphne -b 0.0.0.0 -p 8000 application.asgi:application 这个不行
python manage.py runserver 0.0.0.0:8000可以在浏览器里输入下面的网址进行测试,返回的结果是一个SSE流式就可以了。
bash
htpp://127.0.0.1:8000/api/dv3admin_chatgpt/test-stream/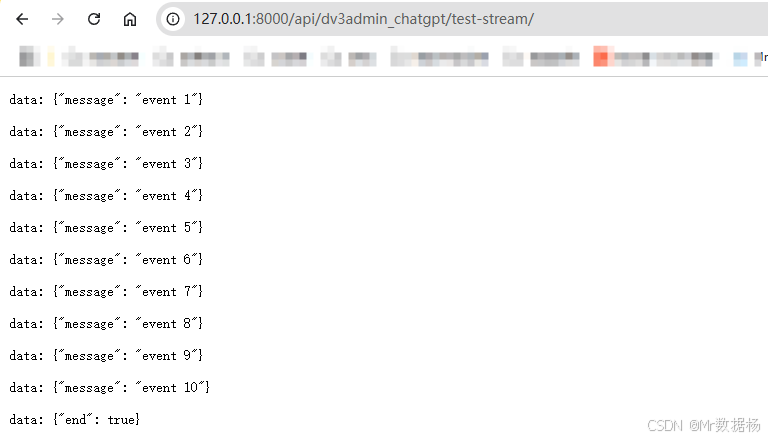
管理后台项目外应用
还是在 ChatStreamDemo.py 中台添加,构建一个同步 POST 接口 ,用户提交一个提问字段 txt,系统立刻将其转发给 handle_chat_question_request 进行处理。用途场景:适用于工具箱、表单式提问等一次性问答请求,不需要流式返回,也不保留上下文。
python
@csrf_exempt
@api_view(['POST'])
@authentication_classes([JWTAuthentication])
@permission_classes([IsAuthenticated])
def chat_post_question(request):
"""
通用接口,根据 URL 中的 chat_model_id 自动分发。
"""
question_info_prompt = request.data.get("txt")
group_id = int(time.time())
return handle_chat_question_request(request, question_info_prompt, group_id)异步 SSE(Server-Sent Events)接口用于生成 AI 对话的流式输出 。从系统配置中读取默认模型参数(如温度、Token 限制等),并允许通过 URL 参数动态覆盖,通过 Token 解析出用户身份,查找历史对话上下文,拼接成完整对话历史,使用 event_stream 实时返回响应数据片段(chunk),每段话以 delta 方式推送,最终发送 end 信号结束。
用途场景:适用于连续对话、多轮问答、工具箱内嵌 AI 对话模块,体验类似 ChatGPT 网页端的逐字生成。
python
async def sse_chat_use_model(request):
# 检查默认配置
config = ChatSettingData.objects.first()
if not config:
return ErrorResponse(msg="未获取到配置,请检查设置。")
# 根据用户配置重新配置参数
config_value = config.value
# 取出最深的 data 配置
text_data = config_value.get('text', {}).get('text', {}).get('data', {})
# 替换字段(保留原字段,如果 request 里没有传就用默认值)
text_data['temperature'] = float(request.GET.get('temperature', 0.8))
text_data['max_token'] = int(request.GET.get('max_tokens', 500))
text_data['top_k'] = float(request.GET.get('frequency_penalty', 1.0))
text_data['top_p'] = float(request.GET.get('presence_penalty', 1.0))
# 解析token获取用户id和用户信息
token = request.GET.get('token', '')
decoded_token = AccessToken(token)
user_id = decoded_token['user_id']
user = Users.objects.filter(id=user_id).first()
# 获取group_id
group_id = request.GET.get('group_id', None)
# 获取用户历史对话
history_num = int(request.GET.get('history_num')) + 2
history = ChatUse.objects.filter(userid_use=user.id, user_use=user.username, group_id=group_id).order_by('-id')[:history_num][::-1]
last = ChatUse.objects.filter(userid_use=user.id, user_use=user.username, group_id=group_id).last()
formatted = []
for item in history:
formatted.append({"role": "user", "content": item.question_info})
if item.answer_info != '待回答':
formatted.append({"role": "assistant", "content": item.answer_info})
def stream_generator():
for chunk in event_stream(
user, last.question_id, len(history), formatted, config
):
# 双换行表示一个完整事件
yield f"data: {json.dumps({'delta': {'content': chunk}})}\n\n"
time.sleep(0.1)
# 最后的 end 事件也要双换行
yield f"data: {json.dumps({'end': True})}\n\n"
response = StreamingHttpResponse(stream_generator(), content_type="text/event-stream")
response['Cache-Control'] = 'no-cache'
response['X-Accel-Buffering'] = 'no'
return response总结
通过 dv3admin_chatgpt 插件,Django 管理后台系统能够轻松接入主流大语言模型服务,在用户管理、模型接入、场景调用与使用追踪方面实现完整闭环。插件提供灵活的权限配置、丰富的预设模板和直观的可视化监控能力,兼顾可控性与扩展性,适配多类 AI 驱动场景。
大模型技术的发展正不断突破传统应用边界,管理后台的智能化将逐渐成为标配。未来版本可进一步引入上下文记忆优化、多模态支持、模型自动切换等机制,为复杂业务场景提供更高效、更智能的支持。