- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:API Server详解(一)
- Kubernetes控制平面组件:API Server详解(二)
- Kubernetes控制平面组件:调度器Scheduler(一)
- Kubernetes控制平面组件:调度器Scheduler(二)
- Kubernetes控制平面组件:Controller Manager 之 内置Controller详解
- Kubernetes控制平面组件:Controller Manager 之 NamespaceController 全方位讲解
- Kubernetes控制平面组件:Kubelet详解(一):架构 及 API接口层介绍
- Kubernetes控制平面组件:Kubelet详解(二):核心功能层
- Kubernetes控制平面组件:Kubelet详解(三):CRI 容器运行时接口层
- Kubernetes控制平面组件:Kubelet详解(四):gRPC 与 CRI gRPC实现
- Kubernetes控制平面组件:Kubelet详解(五):切换docker运行时为containerd
- Kubernetes控制平面组件:Kubelet详解(六):pod sandbox(pause)容器
- Kubernetes控制平面组件:Kubelet 之 Static 静态 Pod
本文是 kubernetes 的控制面组件 kubelet 系列文章第七篇,主要对 容器网络接口CNI 进行讲解,包括:kubernetes网络模型的分类、通信原则、CNI发展历程、主要功能、工作原理、常见插件等,并对Calico插件的实现原理做了详细讲解
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.kubernetes网络模型
1.1.kubernetes网络模型分类
- kubernetes网络模型大体可以分为三类 :
- pod 之间的通信:包括 同节点pod通信、跨节点pod通信,这种一般通过CNI实现
- pod 通过service 与别的pod通信:这种并非pod之间的直连通信,而是通过service通信。此类不属于CNI范畴,由kube-proxy管理
- 外部流量访问pod:入站流量相关,由Ingress管理
1.2.pod 之间通信的基本原则
1.2.1.pod间通信基本原则

- Kubernetes 的网络模型定义了容器间通信的基本规则,核心目标是确保所有 Pod 无论位于哪个节点,均可直接通过 IP 地址相互通信,无需 NAT 转换。
1.2.2.如何理解 pod 间通信无需NAT转换
- NAT(网络地址转换)是一种 将私有网络内的设备IP地址转换为公共IP地址的技术,主要用于解决IPv4地址不足问题。它允许多个设备通过一个公网IP共享上网,常见于家庭路由器。
- 因此pod之间通信不使用NAT,就表示 每个 Pod 拥有集群内全局唯一的 IP 地址,跨节点通信时流量直接通过 Pod IP 寻址,无需经过地址或端口转换(类似局域网设备直连)。
- 对比传统 NAT 场景:若使用 NAT,Pod A 访问 Pod B 时,B 看到的源 IP 可能是 Pod A 所在的节点 IP,而非 Pod A 的真实 IP,破坏网络透明性并增加运维复杂度。
2.CNI(Container Network Interface)接口设计
2.1.CNI 的发展历程
-
Kubernetes 早期版本中,网络功能主要依赖 kubenet 等内置插件实现,存在显著局限性:
- 灵活性不足:网络方案与特定实现深度绑定,难以支持多样化的网络需求(如跨云网络、安全策略等)。
- 配置复杂:手动管理网络参数(如 IP 分配、路由规则)需要较高的运维成本,且易出错。
- 扩展性差:无法快速集成新兴网络技术,阻碍了 Kubernetes 在复杂场景下的应用。
-
为解决上述问题,CoreOS 等公司于 2015 年提出了 CNI 规范,CNI最初是由CoreOS为 rkt容器引擎创建的,目前已经成为事实标准。目前绝大部分的容器平台都采用CNI标准(rkt,Kubernetes,OpenShift等),核心设计原则包括:
- 插件化架构:CNI 仅定义接口标准,具体实现由第三方插件完成(如 Flannel、Calico 等)。
- 功能聚焦:仅关注容器的网络创建与销毁,接口设计简洁(如 ADD、DELETE 操作)。
- 兼容性:支持多种容器运行时(Docker、containerd)和编排系统(Kubernetes、Mesos)。
-
关键里程碑:2016年:Kubernetes 1.5 版本正式集成 CNI,取代原有网络模型,成为默认网络接口。
- 标准化流程:CNI 插件需以可执行文件形式实现,通过配置文件(
/etc/cni/net.d)定义网络参数。
- 标准化流程:CNI 插件需以可执行文件形式实现,通过配置文件(
2.2.CNI 的职能
- CNI(Container Network Interface) 是 Kubernetes 网络模型的实现标准,负责实现 pod 之间的直接通信 :包括
容器与主机的通信、同节点pod通信、跨节点pod通信 - 实现手段:
- 网络配置:在容器创建时分配 IP、配置路由和 DNS。
- 插件链:插件化设计,支持多个插件按顺序执行(如先分配 IP 再设置防火墙规则)。
- 资源管理:通过 IPAM(IP 地址管理)插件分配和回收 IP。
2.3.CNI 插件分类及常见插件

- CNI插件大体可以分为三类:
- IPAM:IP Address Manager,负责管理 ip 地址,比如给pod分配ip
- 主插件 网卡设置 :负责实现
容器与主机的通信、同节点pod通信、跨节点pod通信 - Meta 附加功能:负责cni的扩展功能。比如实现端口映射、容器网络限流、增加防火墙等
2.4.CNI工作原理
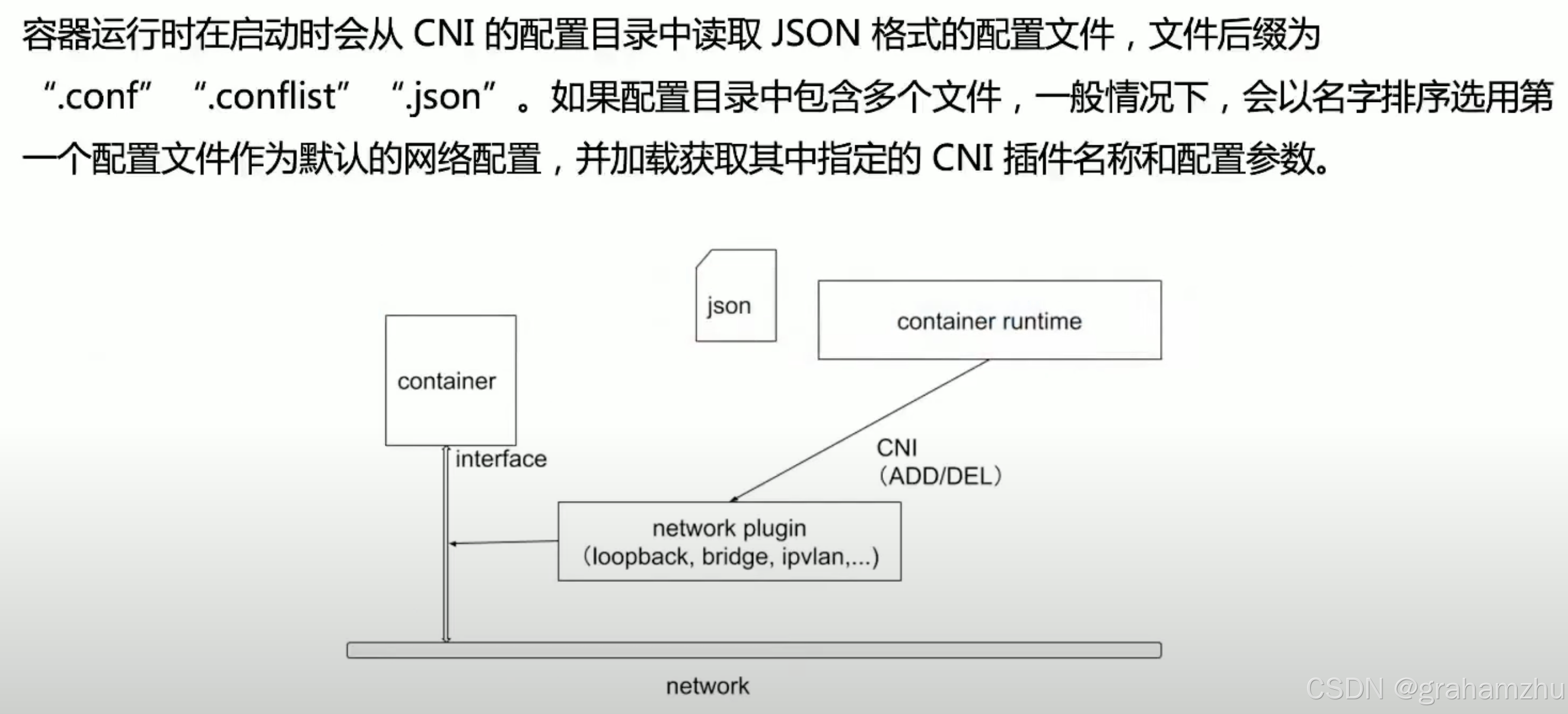
2.4.1.CNI 插件配置
- CNI 默认配置目录:
/etc/cni/net.d。配置文件中应该包含插件名称、CNI版本、插件列表 - 比如 使用calico作为cni插件时,
/etc/cni/net.d目录会存在10-calico.conflist
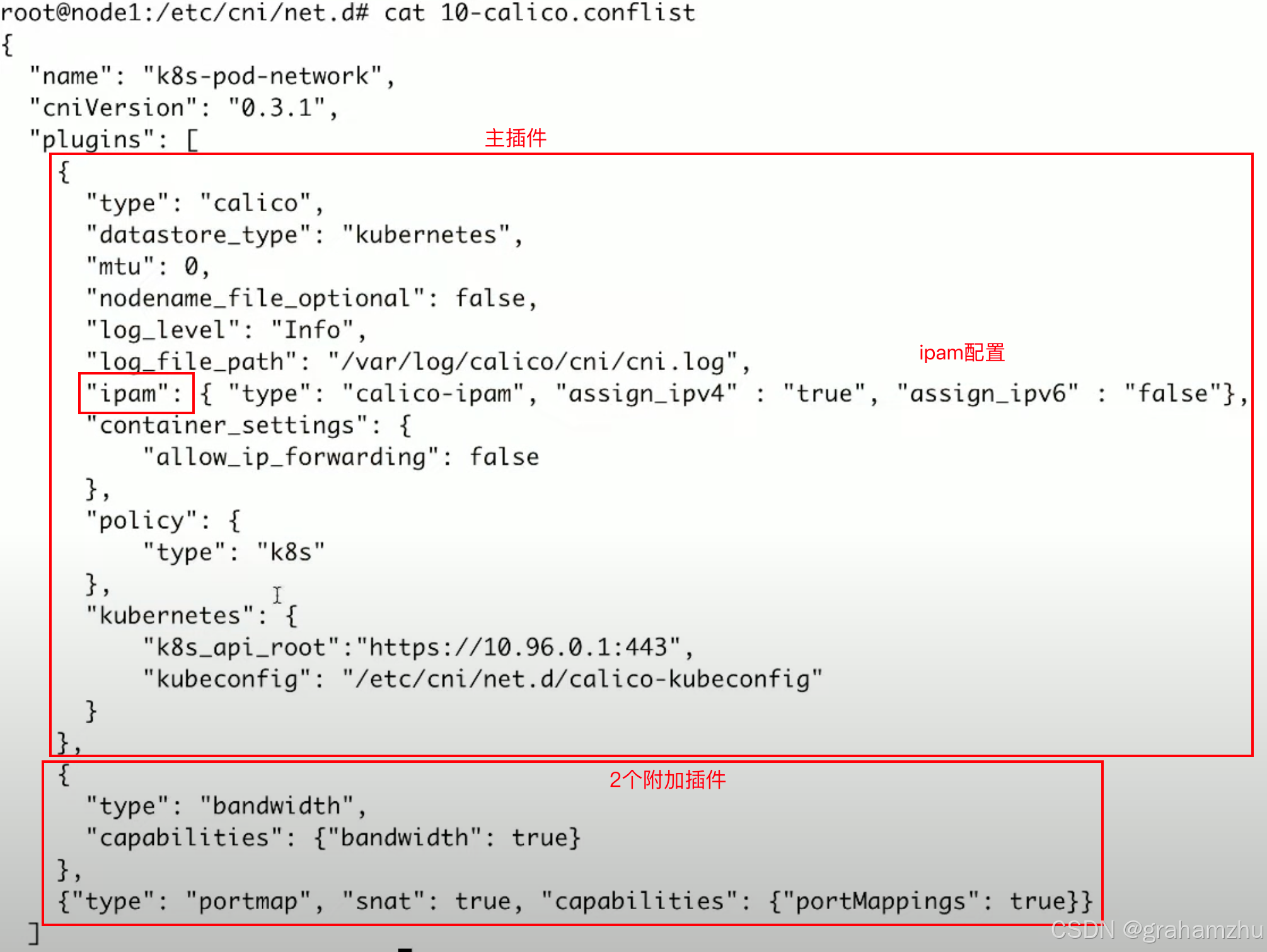
- 再比如使用flannel作为CNI插件,配置文件可能是这样
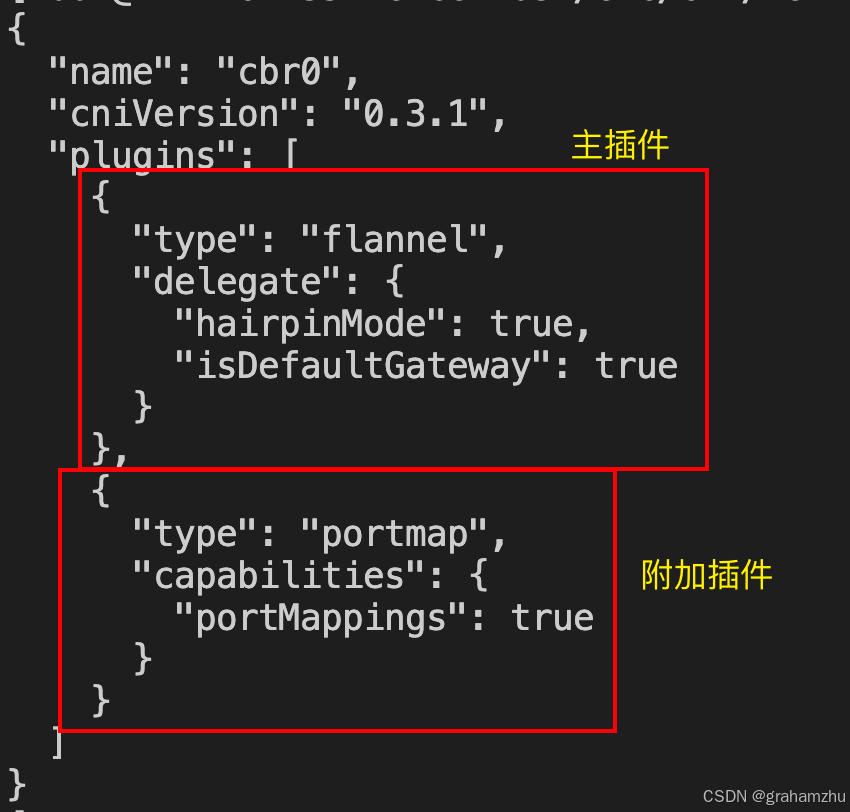
2.4.2.CNI 插件可执行文件
-
在 CNI 标准化流程中,规定 CNI 插件需以可执行文件形式实现,默认存放在目录:
/opt/cni/bin。- 因此,所谓的CNI插件,其实就是一个个编译好的二进制可执行文件,以供调用
-
比如使用calico时,
/opt/cni/bin下会包含可执行文件

-
再比如使用flannel时,
/opt/cni/bin下会包含可执行文件bash[/opt/cni/bin]# ls bandwidth bridge dhcp dummy firewall flannel host-device host-local ipvlan loopback macvlan portmap ptp sbr static tuning vlan vrf
2.4.3.CNI插件生效原理
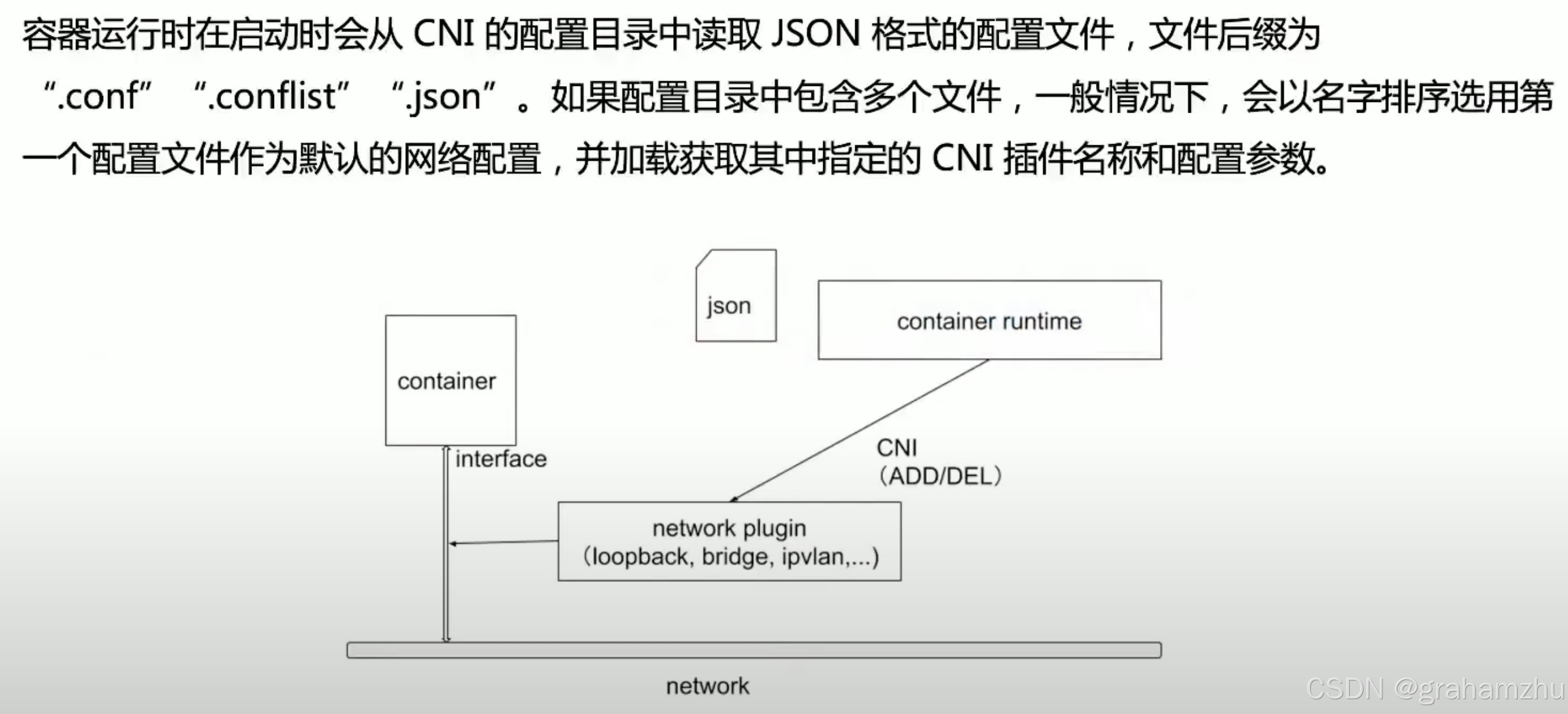
/opt/cni/bin存放所有的插件可执行文件/etc/cni/net.d存放cni配置,声明当前要开启哪些插件- CNI插件是如何生效的?
- 当调用cni时,kubelet 就相当于执行了一条本地命令,找到这个可执行文件,给出入参,即可使用cni功能
- 因此如果自己开发CNI插件,应该如何做?
- 自己开发CNI插件,首先要定义清楚 ADD network、Delete network 等操作的实现
- 然后以可执行文件方式放入
/opt/cni/bin,并在/etc/cni/net.d配置文件中开启
- 调用 CNI插件 时,是如何传参的?
- 通过设置环境变量,将 podId、sandbox net namespace、ADD/DEL 等信息设置为环境变量后,执行cni可执行文件,cni执行过程会读取这些预定义的env,进而执行特定的操作
2.4.4.CNI 与 kubelet 联动

- kubelet 包含两个参数,分别用来设置 cni可执行文件目录、cni配置文件目录
2.5.CNI 插件的设计考量


2.6.pod Ip的分配过程简述
- 学习了上述cni知识,知道有个IPAM插件用于为pod分配ip,那么pod ip分配后如何让apiserver知道呢?过程如下。
- 启动pod时,containerRuntime会调用CNI,CNI插件链中包含IPAM,会给pod分配一个ip。
- 然后 CNI主插件会将该ip 配置到 pod的网络namespace
- 附加功能插件里比如bandwidth就会为之限制带宽,处理完成后将结果返回给containerRuntime。
- containerRuntime会将ip以及结果返回给kubelet,kubelet上报到apiserver
- apiserver将ip写入etcd,这样这个pod就具有ip了
3.CNI 插件
3.1.常见CNI插件

- Calico、Cilium都是网络的一揽子解决方案,包括
容器与主机的通信、同节点pod通信、跨节点pod通信 - 目前生产上 Calico、Cilium 使用的更多,其中 Cilium 性能会更优异
3.2.Flannel
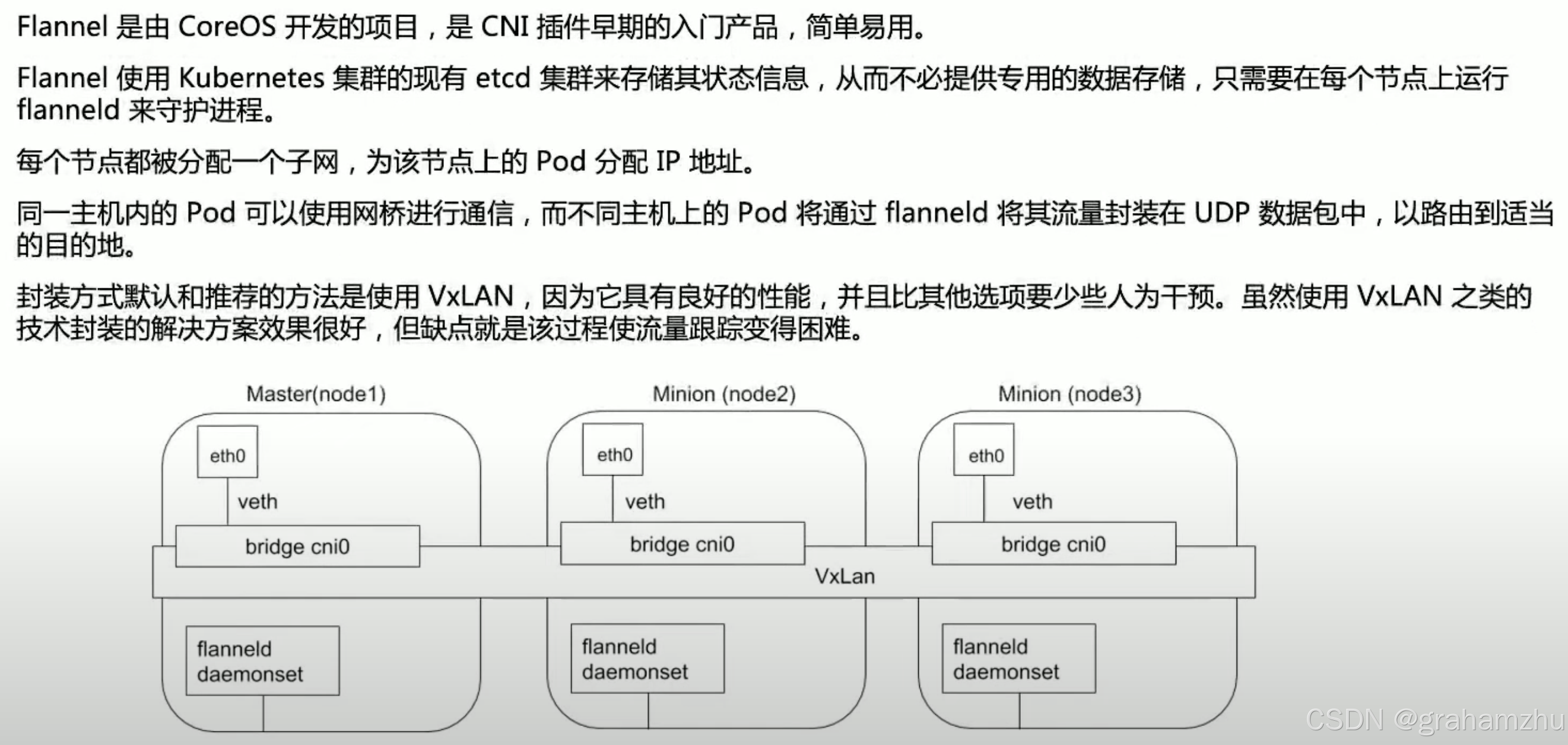
- Flannel 使用了VxLAN,会引入一些额外的开销,大约10%,所以注重效率的生产系统不太用Flannel
- Flannel 本身只做CNI插件,没有完备的生态,比如不能做网络隔离,不如Calico、Cilium都是网络的一揽子解决方案
3.3.Calico

3.3.1.pod ip 规划方案
在容器ip的分配上,有多种方案:分配真实ip、建立私有网络
3.3.1.1.直接给pod分配 基础架构中的真实ip
- 基础架构中的真实ip 在主机的网卡中都认识,所以pod之间的通信天然就是通的,不需要额外的配置,效率高。
- 但是 一个集群的真实ip很有限,而且非常宝贵,规划不当的情况下会限制集群的规模。
3.3.1.2.为pod分配虚拟ip
- 社区为了提供通用方案,假设pod都是私有ip,无法在底层基础架构中进行路由,只能实现主机内部通信,无法直接实现跨主机通信。
- 跨主机ping不通,由此带来 跨主机通信的 一些解决方案:
- 方案一:封包解包 。
- 为了实现跨主机通信,最直接的方法就是把 pod的 ip数据包 再包一层,封包解包。
- 如果数据包在主机内部流转,那么直接就可以路由到。
- 但如果包要出去,就需要在原始包基础上再加一层包,这就叫 tunnel模式(隧道模式)。
- 封装包也有多种方式:
- IPinIP:在ip包外边再加一层ip包
- VxLAN:在ip包外边增加一层udp包。比如Flannel就是用了这种
- 不过封包解包本身是有性能开销的
- 方案二:动态路由协议
- 既然网卡中的静态路由协议不认识这些私有的pod ip,那么可以自行维护动态路由协议,让主机能够知晓 这个ip在哪台主机
- 这种路由模式,无需引入额外的封装层,效率大大提升
- 方案一:封包解包 。
3.3.2.Calico的pod通信方案
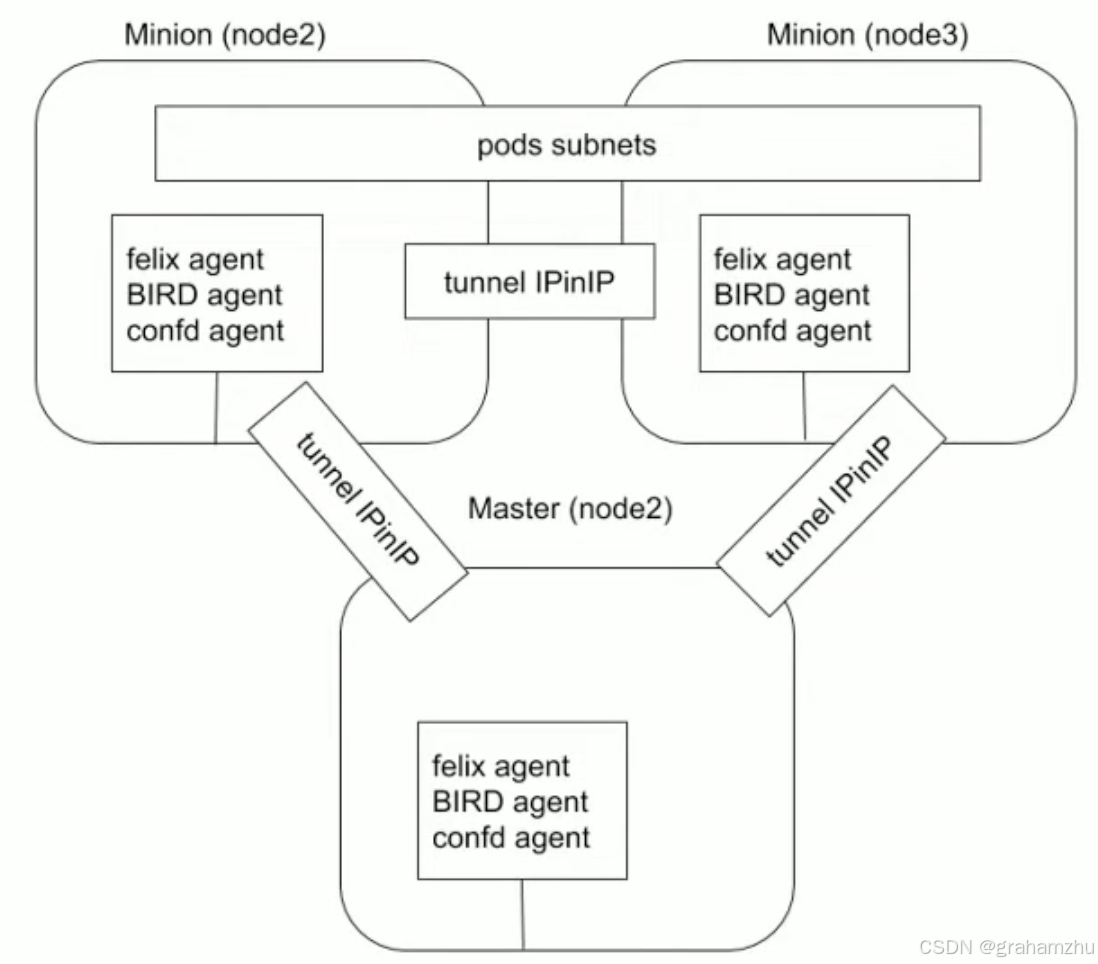
- Calico支持上述的三种 跨跨主机通信模式,上图将Calico支持的三种模式都画了出来:
- IPinIP:
- VxLAN
- BGP路由协议
| 组件名称 | 功能说明 |
|---|---|
| Felix Agent | 运行在每个节点(Master/Minion),负责: - 配置本地路由表 - 管理 ACL(安全策略) - 监控容器生命周期 |
| BIRD Agent | 基于 BGP 协议的路由守护进程,负责: - 节点间路由信息交换(图中未显式展示 BGP 对等连接) - 生成跨主机路由规则 |
| confd Agent | 动态生成 BIRD 的配置文件,监听 Etcd/Kubernetes API 的变更并更新路由策略 |
| IP-in-IP 隧道 | 封装 Pod 的原始 IP 包到宿主机 IP 包中,实现跨节点通信(如图中 tunnel IPinIP 连接) |
3.3.2.1.Calico 支持 IPinIP 模式
- 示例:Pod A(Node2)→ Pod B(Node3)
- 封装:Pod A 的 IP 包被 Felix 封装到 Node2 的 IP 包中(源 IP:Node2,目标 IP:Node3)。
- 传输:通过宿主机的物理网络传输到 Node3。
- 解封装:Node3 的 Felix 解封装,将原始 Pod IP 包传递给 Pod B。
- 适用场景
- 底层网络限制:当底层网络(如公有云 VPC)不支持直接路由 Pod IP 时,IP-in-IP 通过隧道绕开限制。
- 简单配置:无需依赖外部路由器或复杂网络策略。
3.3.2.2. Calico 支持 VxLAN 模式
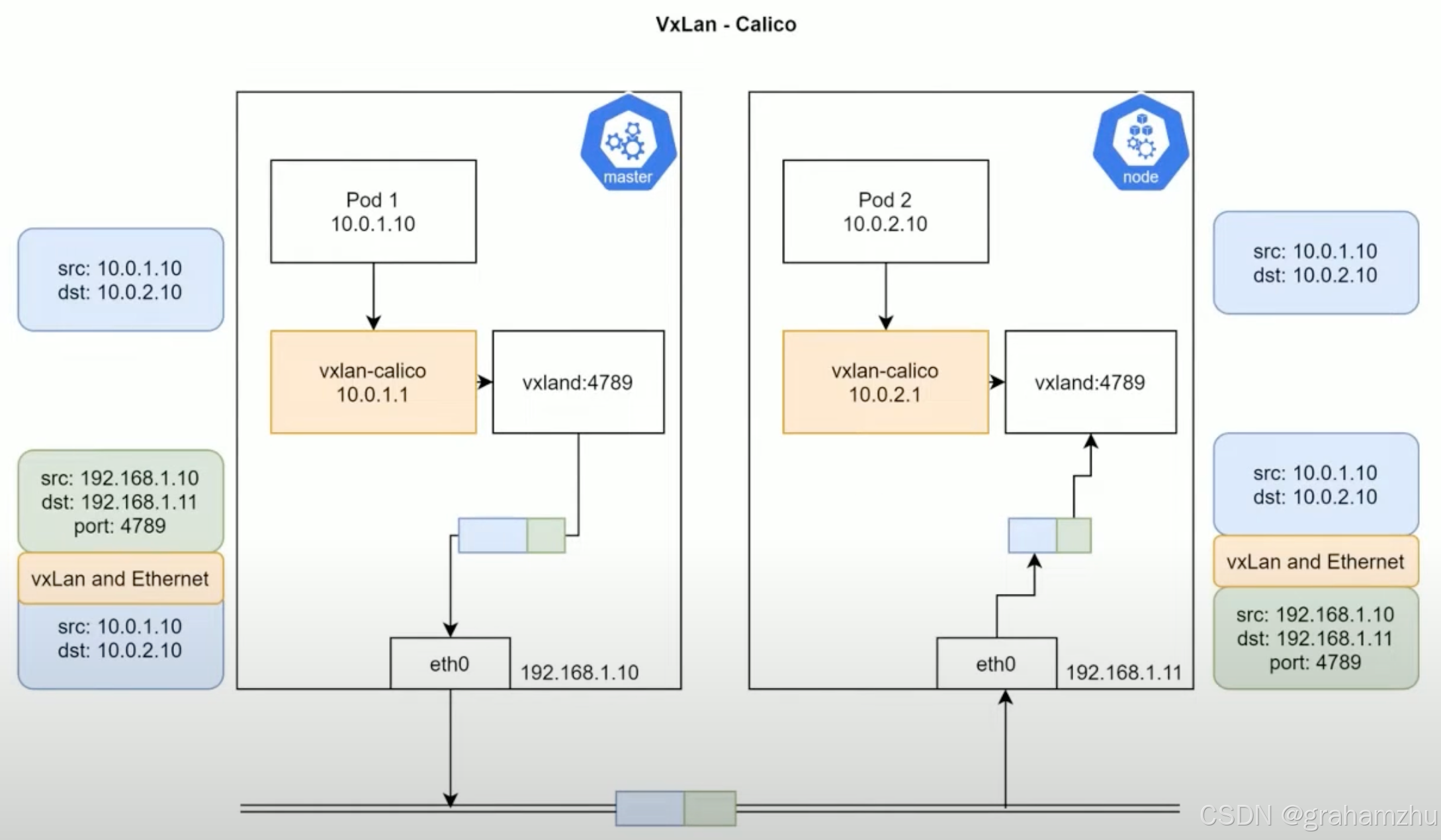
- 示例:Pod A(Node2)→ Pod B(Node3)
- 封装 :
- Pod A 的 IP 包被 主机上vxlan.calico 设备封装为 VxLAN 格式(外层 UDP 头部,目标端口 4789)。
- 外层 IP 头源地址为 Node2,目标地址为 Node3。
- VxLAN 头部包含 VNI(Virtual Network Identifier),默认值为
4096,用于多租户隔离。
- 传输:通过宿主机的物理网络传输到 Node3(基于 UDP 协议)。
- 解封装 :
- Node3 的 vxlan.calico 识别 VxLAN 封装,剥离外层 UDP 和 VxLAN 头部。
- 将原始 Pod IP 包传递给 Pod B。
- 封装 :
- 适用场景
- 多租户隔离:通过 VNI 实现不同租户或业务的网络隔离。
- 复杂网络环境:适用于需要灵活扩展虚拟网络且底层网络支持组播或单播转发的场景(如混合云)。
- 查看calico-vxlan设备:
ip a

3.3.2.3. Calico 支持 BGP 路由协议模式
- 示例:Pod A(Node2)→ Pod B(Node3)
- 路由同步:
- Node2 和 Node3 的 BIRD Agent 通过 BGP 协议向物理交换机或路由反射器宣告本地 Pod 子网(如
10.244.1.0/24)。 - 物理网络设备生成路由表,标记 Node3 的 Pod 子网下一跳为 Node3 的物理 IP。
- Node2 和 Node3 的 BIRD Agent 通过 BGP 协议向物理交换机或路由反射器宣告本地 Pod 子网(如
- 数据传输:
- Pod A 的 IP 包根据 Node2 的路由表直接通过物理网络发送到 Node3(无需封装)。
- Node3 根据本地路由规则将数据包转发给 Pod B。
- 路由同步:
- 适用场景
- 高性能需求:无封装开销,延迟最低,适合金融交易、实时计算等场景。
- 私有数据中心:要求底层网络设备(交换机/路由器)支持 BGP 协议(如企业级网络架构)。
模式对比总结
| 模式 | 封装方式 | 性能 | 网络要求 | 典型场景 |
|---|---|---|---|---|
| IP-in-IP | IP-in-IP 隧道(IP 协议) | 中等 | 仅需 IP 可达性 | 公有云、简单 Overlay 网络 |
| VxLAN | VxLAN 隧道(UDP 协议) | 中等 | 支持组播或单播转发 | 混合云、多租户隔离 |
| BGP 路由 | 无封装,依赖物理路由 | 高 | 需 BGP 兼容的物理网络设备 | 私有数据中心、高性能网络 |
通过灵活选择模式,Calico 可适配从公有云到私有数据中心的多样化网络需求。
3.3.3.Calico节点初始化
- 前面我们知道在使用了calico的时候,每个节点的
/etc/cni/net.d和/opt/cni/bin目录下都会分别包含 calico的配置文件、calico的可执行文件。 - 那么这些文件是如何被配置到主机上的?
- 答:通过daemonset代替人工,方便高效
3.3.3.1.Calico DaemonSet
- 在安装Calico时,一般会创建一个ds,用于启动Calico,现在看下这个ds都是做了什么
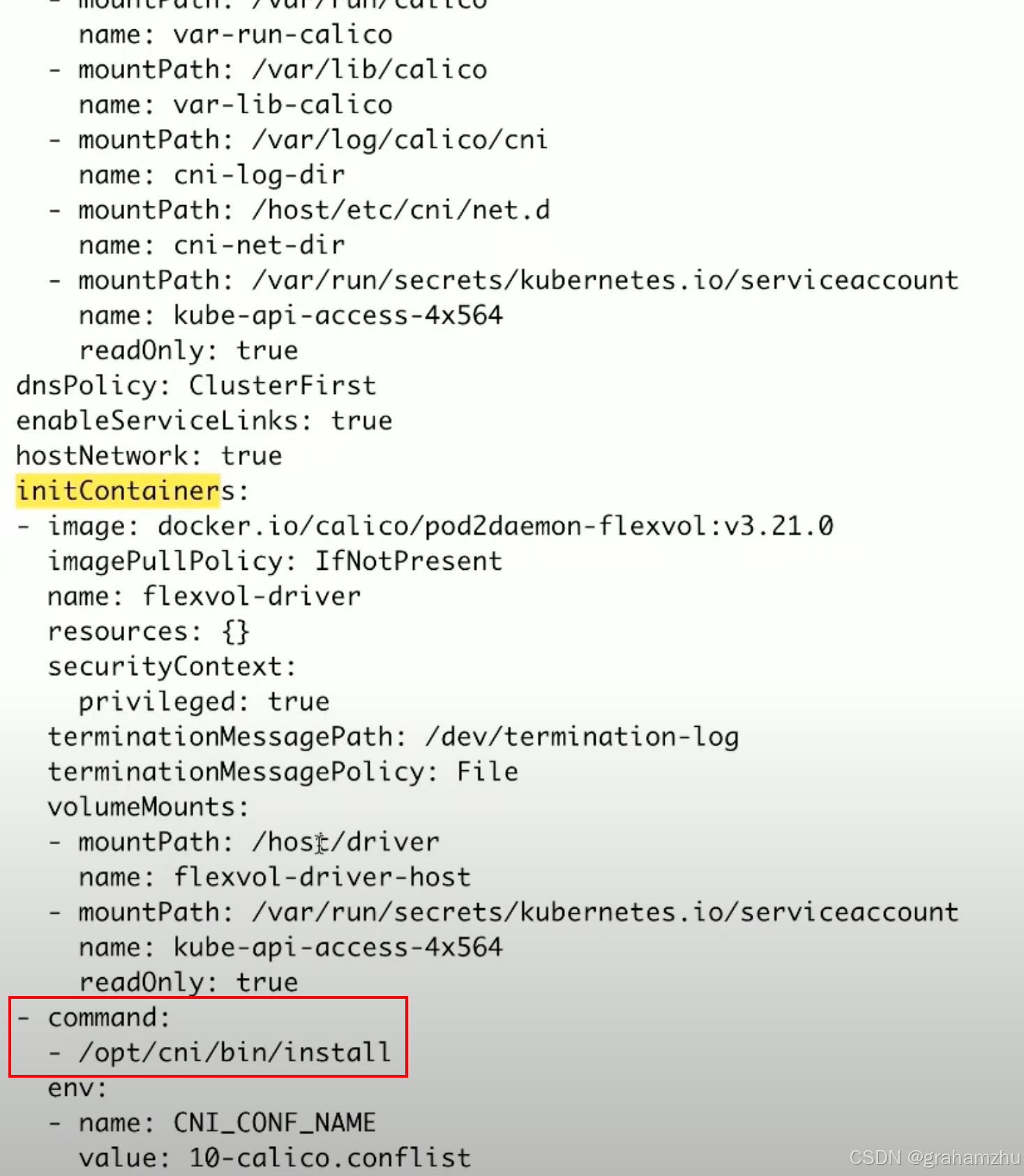
- 输出下ds的yaml,可以看到有一些initContainer,其中有个initContainer就负责 calico 的安装操作,这里实际上做的操作就是把 配置文件 拷贝到本机的
/etc/cni/net.d,把calico相关的插件可执行文件 拷贝到/opt/cni/bin - 如何拷贝?
- 通过挂载hostpath,将目录挂载到容器中,然后就可以直接把文件拷贝进去
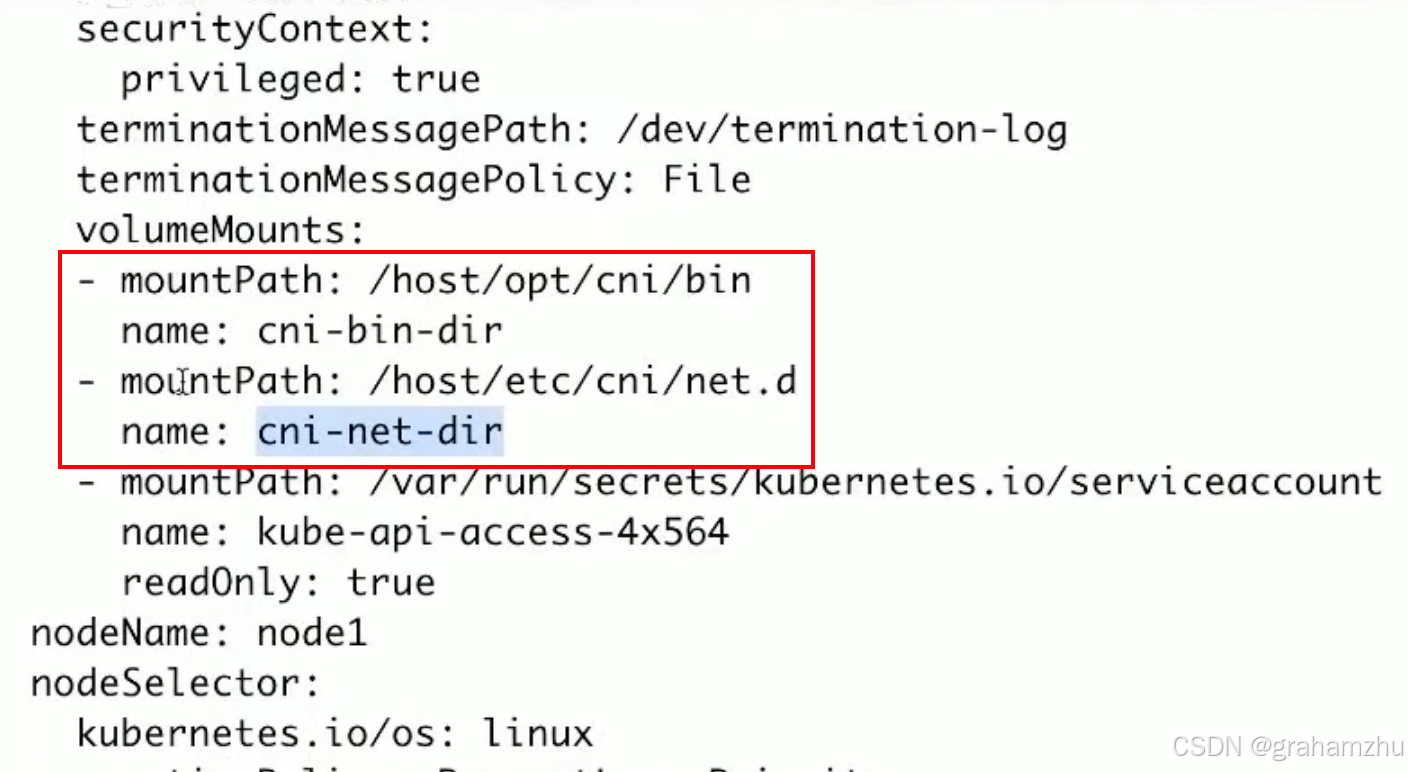
- 通过挂载hostpath,将目录挂载到容器中,然后就可以直接把文件拷贝进去
3.3.3.2.很多CNI插件采用DaemonSet初始化
- 除了calico,其他很多cni插件也是通过 daemonset initContainers 实现初始化的,比如Flannel
- Flannel 这里更直接,直接用在command中用cp命令做拷贝
bash
[root@VM /opt/cni/bin]# kubectl get ds -n kube-flannel kube-flannel-ds -oyaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
annotations:
deprecated.daemonset.template.generation: "1"
creationTimestamp: "2024-04-17T08:01:53Z"
generation: 1
labels:
app: flannel
k8s-app: flannel
tier: node
name: kube-flannel-ds
namespace: kube-flannel
resourceVersion: "97665682"
selfLink: /apis/apps/v1/namespaces/kube-flannel/daemonsets/kube-flannel-ds
uid: 8bb85be6-99a6-4896-ace9-11d2f7ecd2da
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: flannel
template:
metadata:
creationTimestamp: null
labels:
app: flannel
tier: node
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
containers:
- args:
- --ip-masq
- --kube-subnet-mgr
command:
- /opt/bin/flanneld
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
image: docker.io/flannel/flannel:v0.25.1
imagePullPolicy: IfNotPresent
name: kube-flannel
resources:
requests:
cpu: 100m
memory: 50Mi
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_RAW
privileged: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /run/flannel
name: run
- mountPath: /etc/kube-flannel/
name: flannel-cfg
- mountPath: /run/xtables.lock
name: xtables-lock
dnsPolicy: ClusterFirst
hostNetwork: true
initContainers:
- args:
- -f
- /flannel
- /opt/cni/bin/flannel
command:
- cp
image: docker.io/flannel/flannel-cni-plugin:v1.4.0-flannel1
imagePullPolicy: IfNotPresent
name: install-cni-plugin
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /opt/cni/bin
name: cni-plugin
- args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
command:
- cp
image: docker.io/flannel/flannel:v0.25.1
imagePullPolicy: IfNotPresent
name: install-cni
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/cni/net.d
name: cni
- mountPath: /etc/kube-flannel/
name: flannel-cfg
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: flannel
serviceAccountName: flannel
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- hostPath:
path: /run/flannel
type: ""
name: run
- hostPath:
path: /opt/cni/bin
type: ""
name: cni-plugin
- hostPath:
path: /etc/cni/net.d
type: ""
name: cni
- configMap:
defaultMode: 420
name: kube-flannel-cfg
name: flannel-cfg
- hostPath:
path: /run/xtables.lock
type: FileOrCreate
name: xtables-lock
updateStrategy:
rollingUpdate:
maxUnavailable: 1
type: RollingUpdate
status:
currentNumberScheduled: 1
desiredNumberScheduled: 1
numberAvailable: 1
numberMisscheduled: 0
numberReady: 1
observedGeneration: 1
updatedNumberScheduled: 13.3.4.Calico配置一览

3.3.5.Calico实现原理
本节解答问题:Calico是实现ip管理的?
3.3.5.1.Calico 自带众多CRD
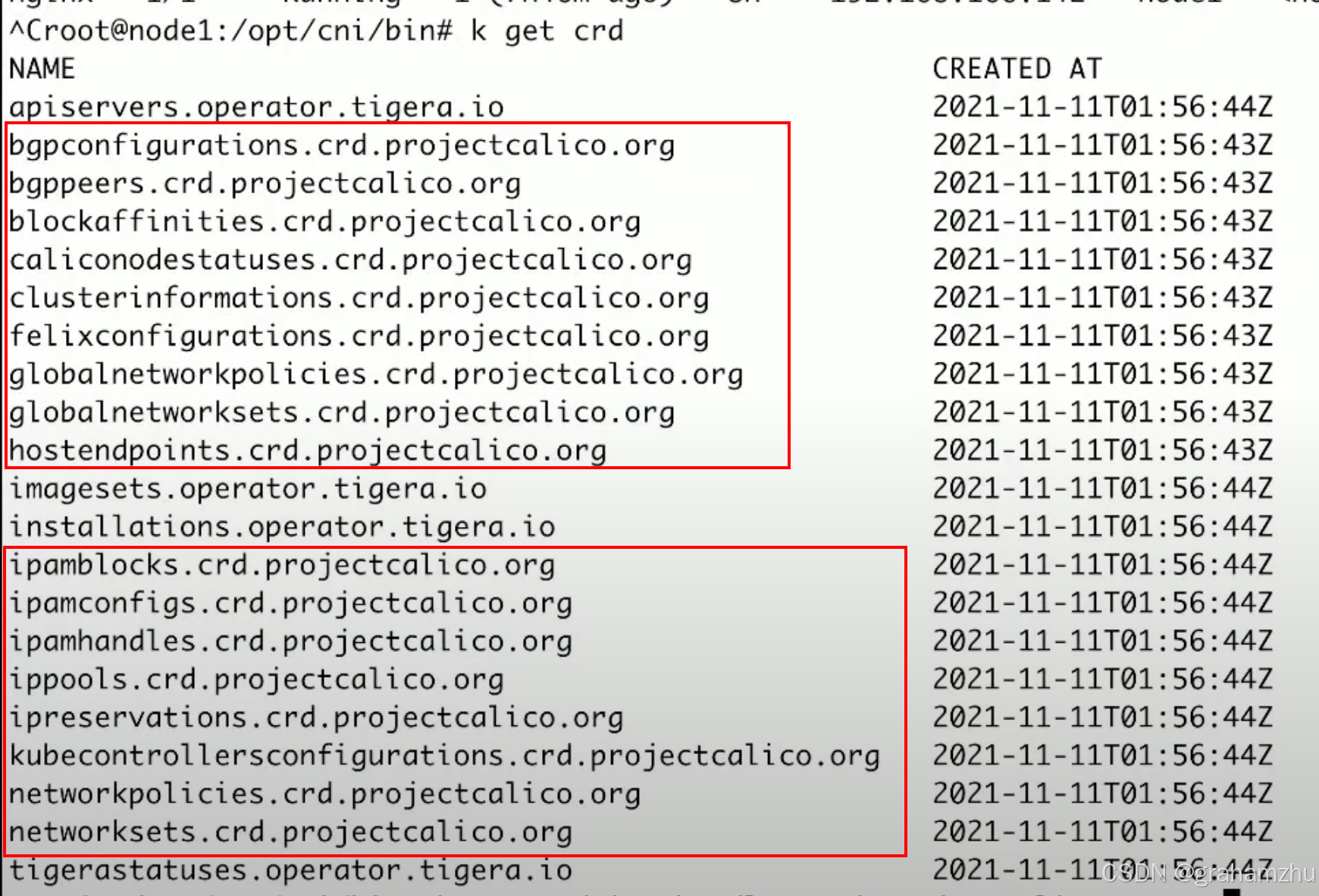
-
ippools:整个集群的ip池,定义了ip的总量、每个node ip的数量、是否开启ipip mode等
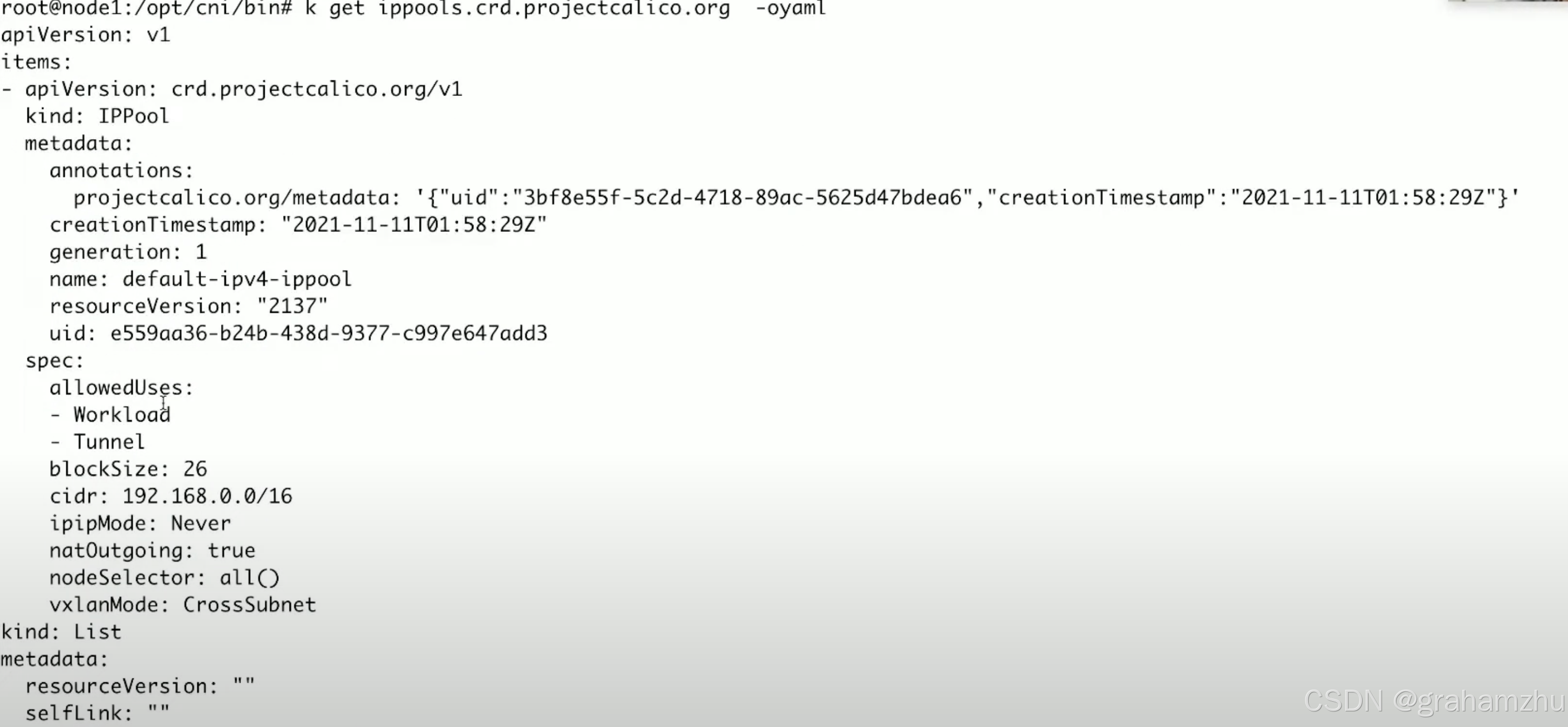
-
ipamblocks:在具体一个node上,按照ippools中对node ip 的规定,为当前node的ipamblocks分配ip段,并记录有哪些ip分配给了哪个pod,还有哪些ip没有分配等信息
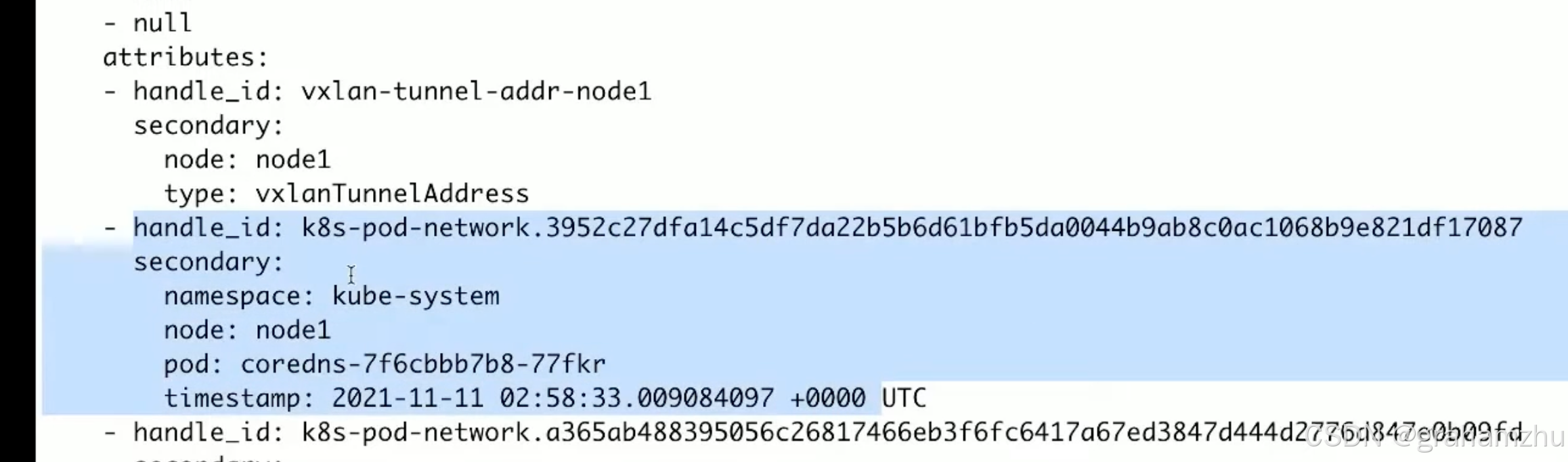
-
ipamhandles:每一个pod都会有一个具体的ipamhandle,记录自己分配到的ip
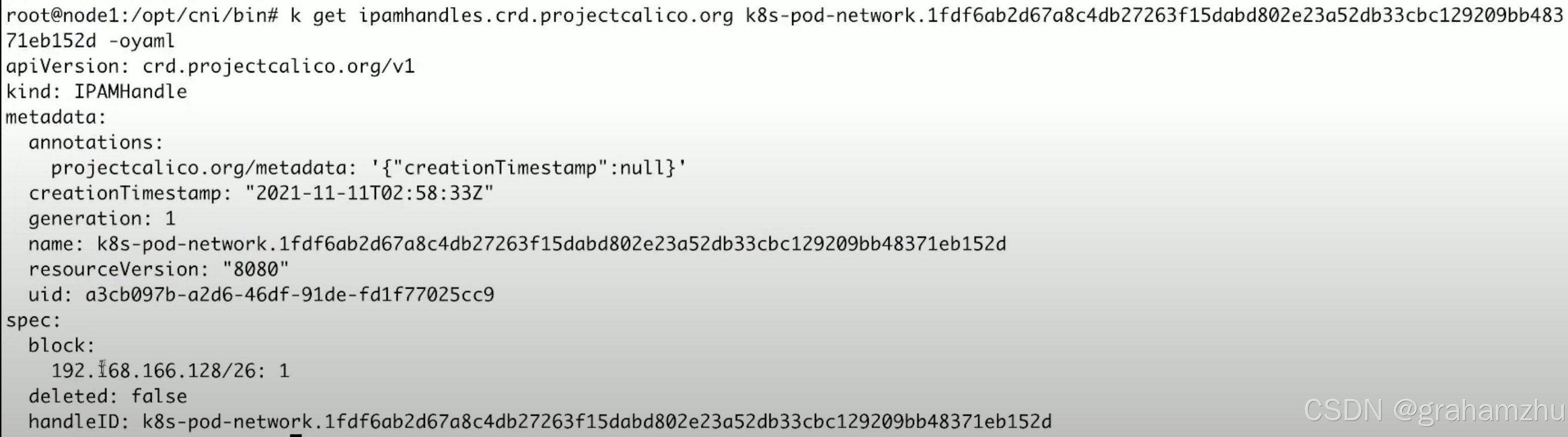
3.3.5.2.如何查看calico的通信模式
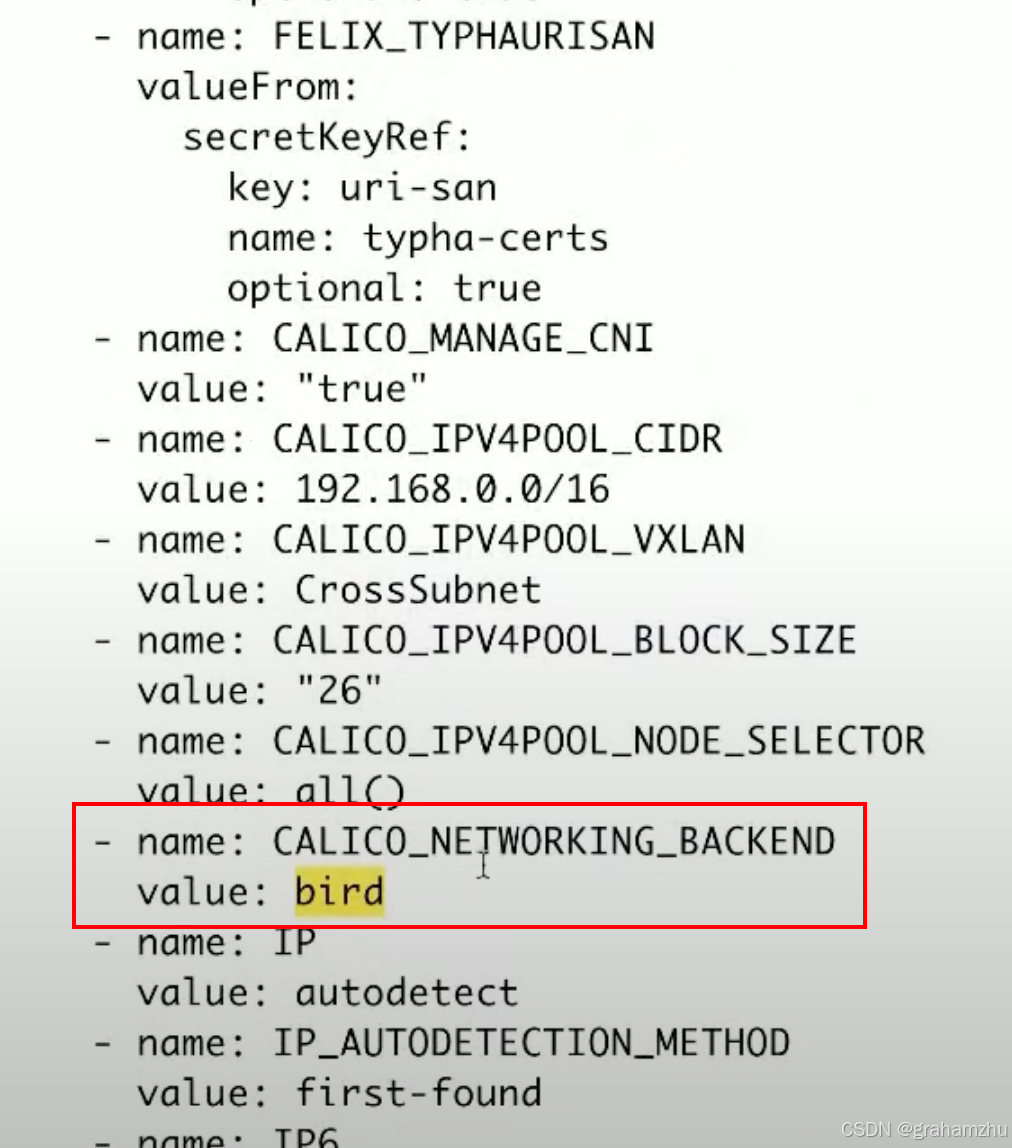
- 在 calico daemonset 中,规定了当前采用的通信模式
- 比如下图表示当前采用 bird模式
3.3.5.3.节点内pod通信实践
演示在 一个pod中,ping 同节点另一个pod 的包转发过程
- 当前运行了两个pod,pod分别为:centos 192.168.166.144、nginx 192.168.166.142

- 我们进入centos 192.168.166.144 的 pod中,ping 一下 nginx 192.168.166.142,是可以ping通的。那么为什么能通呢,中间过程如何?

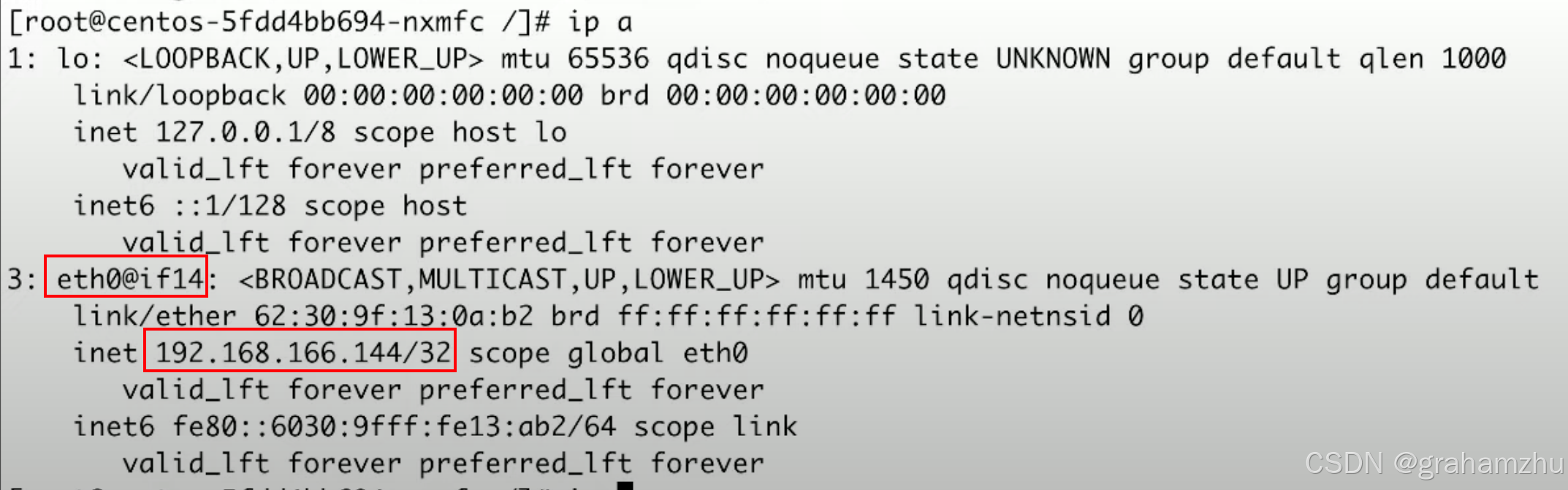
- 查看一下当前pod的网络设备
ip addr/ip a,可以看到自己的ip 192.168.166.144
- 查看一下当前pod的 路由表:
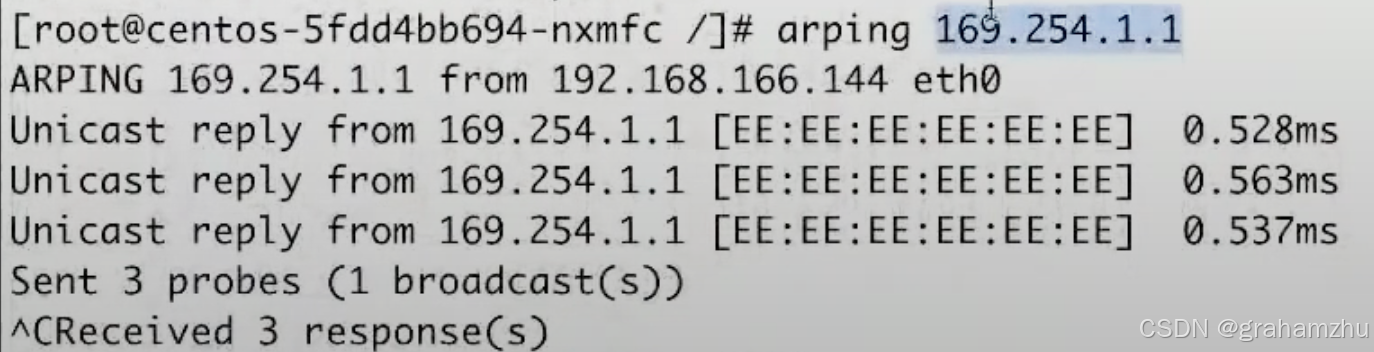
ip route/ip r。明显169.254.1.1和pod ip不属于同一网段

- 通过arping查看 ping 过程中的设备mac地址,可以看出是
ee:ee:ee:ee:ee:ee
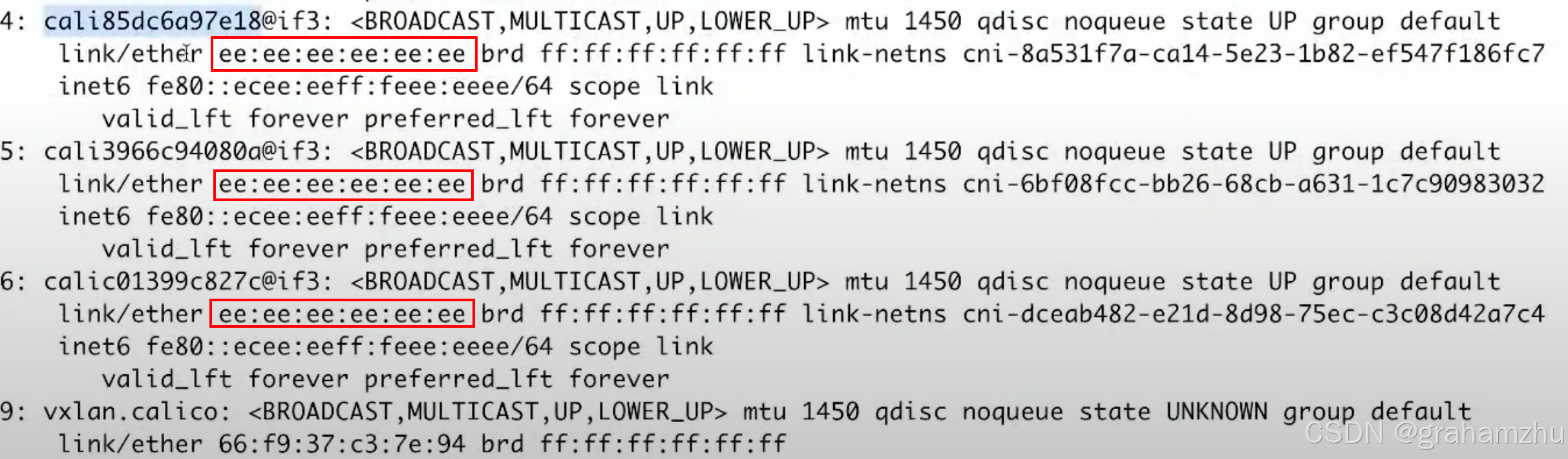
- 我们退出容器,回到主机上,查看主机的网络设备。
ip addr/ip a,可以看到,所有calico建出来的网络设备,mac地址都是ee:ee:ee:ee:ee:ee。说明只要是从centos网关出来的包都会被calico设备接收到
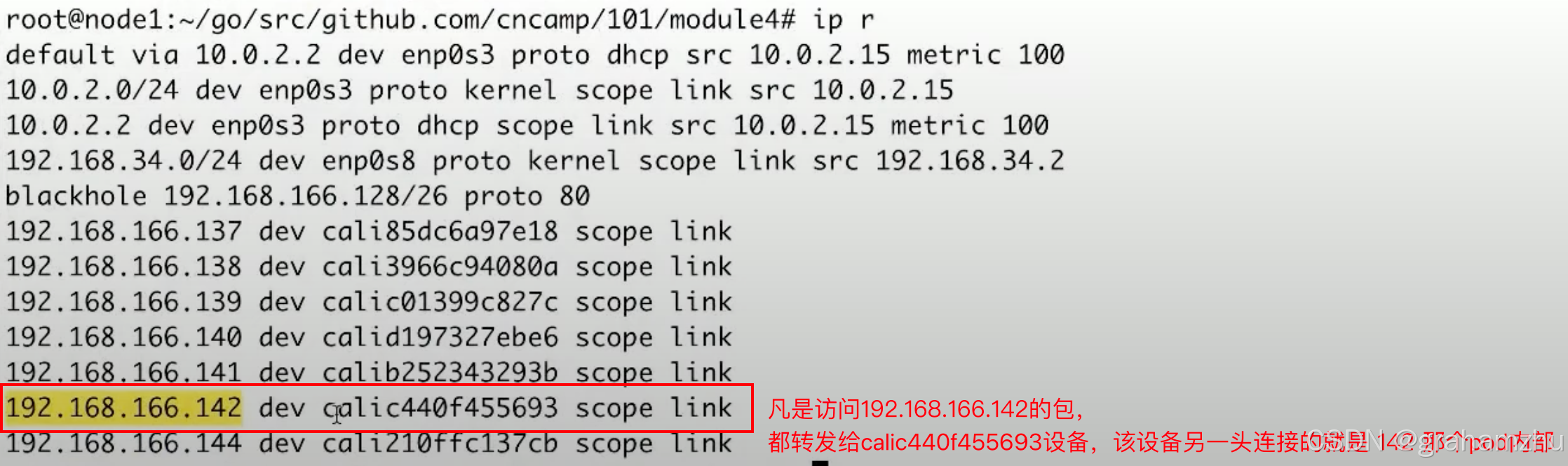
- 查看主机的路由表,可以看到有192.168.166.142,即只要在主机上访问 192.168.166.142,都会转发到 calico440f455693 的口,这个口的vethpair另一头正式连接的 nginx 192.168.166.142,包就被转发过去了
3.3.5.4.跨节点的pod通信实践:BIRD
-
如何通过BIRD实现跨节点的pod通信?
-
每个节点上都会运行一个 BIRD Daemon,所有节点上的BIRD会彼此建立长连接,互相同步路由表。
-
路由表示例
bashipamblock: 10-233-90-0-24 node1 # node1的网段 cidr: 10.233.90.0/24 # 路由表:凡是10.233.96.0/24网段的,都在192.168.34.11节点上 10.233.96.0/24 via 192.168.34.11 dev tunl0 proto bird onlink ipamblock: 10-233-96-0-24 node: node2 # node2的网段 cidr: 10.233.96.0/24 # 路由表:凡是10.233.90.0/24网段的,都在192.168.34.10节点上 10.233.90.0/24 via 192.168.34.10 dev tunl0 proto bird onlink
3.4.CNI plugin 对比
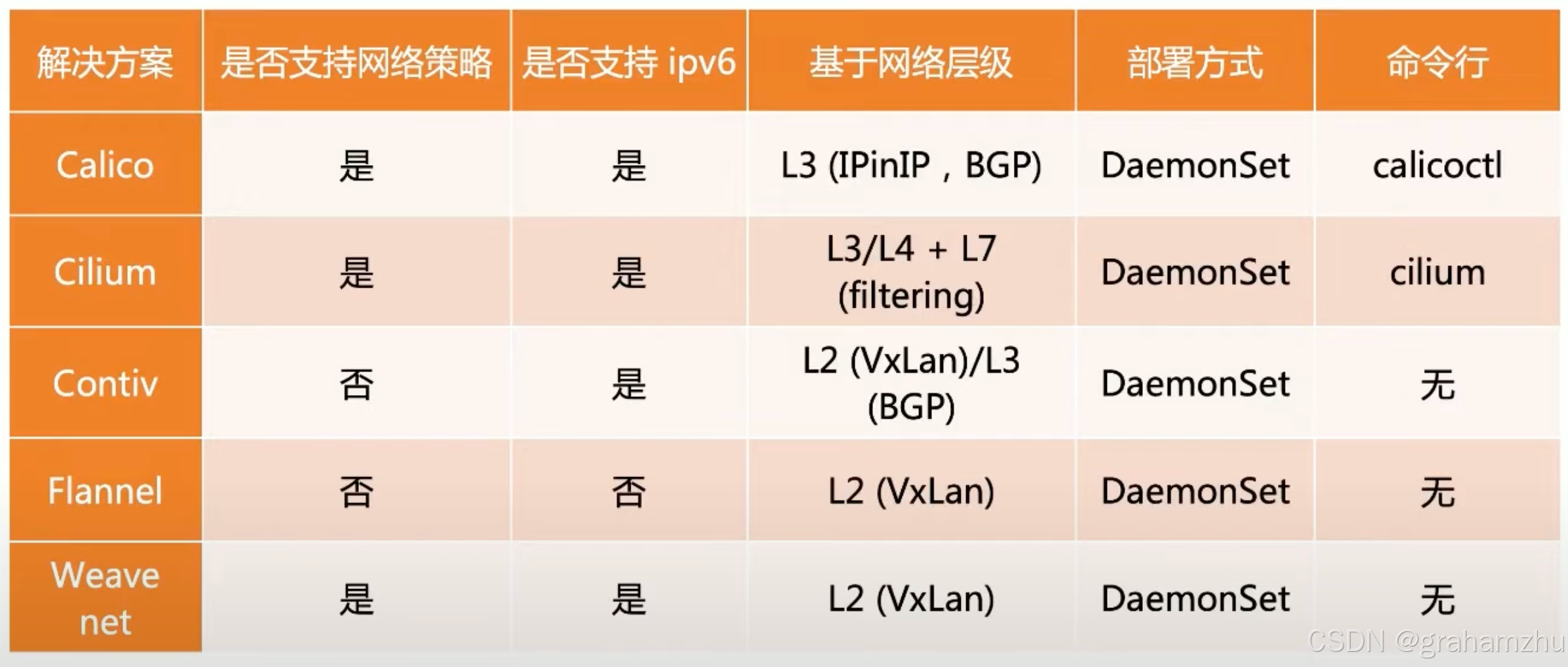
- 生产建议:Calico/Cilium
- Cilium性能好,但是需要比较新的 kernel
4.CNI 接口
- CNI提供了4个接口,由容器运行时调用,用于管理容器网络的生命周期
- ADD - 将容器添加到网络,或修改配置
- DEL - 从网络中删除容器,或取消修改
- CHECK - 检查容器网络是否正常,如果容器的网络出现问题,则返回错误
- VERSION - 显示插件的版本
| 接口 | 幂等性 | 必须实现 | 典型插件逻辑 |
|---|---|---|---|
ADD |
否 | 是 | 创建网卡、分配 IP、配置路由 |
DEL |
是 | 是 | 删除网卡、释放 IP、清理路由 |
CHECK |
是 | 否(可选) | 检查 IP 有效性、路由是否存在 |
VERSION |
是 | 是 | 返回支持的 CNI 版本列表 |
4.1.ADD接口
-
作用:为容器分配网络资源(如 IP、路由、网卡等),并配置网络连接。
-
调用时机:
- 容器创建时(如 Pod 启动时)
- 容器加入新网络时(多网络场景)
-
输入参数(JSON 格式):
json{ "cniVersion": "1.0.0", // CNI 版本 "name": "mynet", // 网络名称 "type": "bridge", // 插件类型 "containerID": "abcd1234", // 容器唯一 ID "netns": "/proc/1234/ns/net", // 容器的网络命名空间路径 "ifName": "eth0", // 容器内的网卡名称 "args": { ... }, // 额外参数(如 Kubernetes 传递的 Pod 元数据) "prevResult": { ... } // 前一个插件的执行结果(插件链场景) } -
输出结果:
interfaces:分配的网卡列表(如veth pair)。ips:分配的 IP 地址及网关。routes:路由规则。dns:DNS 配置。
-
示例输出:
json{ "cniVersion": "1.0.0", "interfaces": [ { "name": "eth0", "mac": "0a:58:0a:01:01:02", "sandbox": "/proc/1234/ns/net" } ], "ips": [ { "version": "4", "address": "10.1.1.2/24", "gateway": "10.1.1.1" } ] }
4.2.DEL 接口
- 作用:释放容器占用的网络资源(如删除 IP、清理路由、卸载网卡等)。
- 调用时机 :
- 容器删除时(如 Pod 终止时)。
- 容器离开网络时(多网络场景)。
- 输入参数 :
- 参数与
ADD接口一致
- 参数与
- 输出结果 :
- 无特定输出,但需返回成功(状态码
0)或失败(非零状态码)。
- 无特定输出,但需返回成功(状态码
4.3.CHECK 接口
- 作用:验证容器的网络配置是否正常(如 IP 是否有效、路由是否存在)。
- 调用时机 :
- 容器运行过程中定期检查。
- 容器网络异常时主动触发。
- 输入参数 :
- 与
ADD接口一致,但需要prevResult字段(即ADD接口的输出结果)。
- 与
- 输出结果 :
- 无特定输出,但需返回成功(状态码
0)或失败(非零状态码)。
- 无特定输出,但需返回成功(状态码
4.4.VERSION 接口
-
作用:报告插件支持的 CNI 版本列表。
-
调用方式 :
- 容器运行时通过命令行参数
--version调用插件。
- 容器运行时通过命令行参数
-
输出结果 :
json{ "cniVersion": "1.0.0", "supportedVersions": ["0.4.0", "1.0.0"] }