一、Flume安装与配置
步骤:
1、使用XFTP将Flume安装包apache-flume-1.9.0-bin.tar.gz发送到master机器的主目录。
2、解压安装包:
tar -zxvf ~/apache-flume-1.9.0-bin.tar.gz3、修改文件夹的名字,将其改为flume,或者创建软连接也可:
mv ~/apache-flume-1.9.0-bin ~/flume4、配置环境变量:
vim ~/.bashrc在文件末尾添加以下内容:
export FLUME_HOME=/home/hadoop/flume
export PATH=$FLUME_HOME/bin:$PATH保存文件,然后刷新环境变量或重新启动命令行终端:
source ~/.bashrc二、测试运行
可以直接使用以下Flume的默认配置启动Agent,该Agent的Source是一个序列生成器,Channel是内存,Sink是日志类型,直接打印到控制台。
Flume的配置可以在任意地方编写,只需在执行启动命令时,指定该配置即可。
步骤:
1、使用mv命令更改Flume自带的配置文件模版文件名:
cd ~/flume/conf
vim net-flume-logger.conf配置内容如下:
# 把这个agent命名为a1,且定义了source、sink、channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink
a1.sinks.k1.type = logger
# 使用内存作为Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定source和sink的channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12、启动Flume Agent:
flume-ng agent -n a1 -c ~/flume/conf -f ~/flume/conf/net-flume-logger.conf -Dflume.root.logger=INFO,console3、接着另外打开一个终端,使用以下命令,往44444端口发送消息:
nc localhost 44444在Flume Agent能看到对应的Event,则Flume能够正确运行。
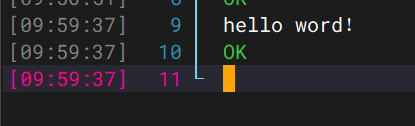

4、接着可以为其他机器都部署好Flume,使用scp -r命令把文件夹发送到另外两台机器,然后配置环境变量即可。
scp -r ~/flume hadoop@slave1:~/
scp -r ~/flume hadoop@slave2:~/