
文章目录
Standalone集群部署
Standalone 模式是 Spark 自带的资源调度系统,无需依赖外部集群管理器。在此模式下,集群角色包含主节点(Master)、工作节点(Worker)、Client组成。各角色作用如下:
- Master节点:负责集群资源管理和任务调度。
- Worker节点:负责执行具体的计算任务。
- Client负责:向Standalone集群中提交任务。
一、节点划分
这里搭建Standalone集群选择一台Master和两台Worker以及一台Client,按照如下节点划分在各个节点上部署各个角色。
bash
#Spark安装包中各个目录和文件作用如下
[root@node1 software]# ll spark-3.5.5
drwxr-xr-x bin:包含管理Spark的可执行脚本。
drwxr-xr-x conf:包含Spark的配置模板文件。
drwxr-xr-x data:包含示例应用程序所需的数据集,通常用于GraphX、MLlib和Streaming的示例。
drwxr-xr-x examples:包含Spark的示例代码和JAR包,供用户参考和测试。
drwxr-xr-x jars:存放Spark运行时所需的所有JAR包,包括Spark自身的JAR以及其依赖项。
drwxr-xr-x kubernetes:包含与Kubernetes集成相关的资源和配置。
-rw-r--r-- LICENSE:Spark的许可证文件,说明了软件的许可条款。
drwxr-xr-x licenses:包含Spark所依赖的第三方库的许可证文件。
-rw-r--r-- NOTICE:关于Spark的一些法律声明和通知。
drwxr-xr-x python:包含PySpark(Spark的Python API)相关的文件和资源。
drwxr-xr-x R:包含SparkR(Spark的R API)相关的文件和资源。
-rw-r--r-- README.md:提供关于Spark的简要介绍和使用说明。
-rw-r--r-- RELEASE:包含当前Spark版本的发布说明。
drwxr-xr-x sbin:包含用于启动和停止Spark集群的脚本。
drwxr-xr-x yarn:包含与Hadoop YARN集成相关的jar包。二、搭建Standalone集群
1、将下载好的Spark安装包上传解压
将"spark-3.5.5-bin-hadoop3-scala2.13.tgz"上传至node1节点,进行解压并修改名称。
bash
[root@node1 ~]# cd /software/ [root@node1 software]# tar -zxvf ./spark-3.5.5-bin-hadoop3-scala2.13.tgz
[root@node1 software]# mv spark-3.5.5-bin-hadoop3-scala2.13 spark-3.5.5
bash
#Spark安装包中各个目录和文件作用如下
[root@node1 software]# ll spark-3.5.5 drwxr-xr-x bin:包含管理Spark的可执行脚本。
drwxr-xr-x conf:包含Spark的配置模板文件。
drwxr-xr-x data:包含示例应用程序所需的数据集,通常用于GraphX、MLlib和Streaming的示例。
drwxr-xr-x examples:包含Spark的示例代码和JAR包,供用户参考和测试。
drwxr-xr-x jars:存放Spark运行时所需的所有JAR包,包括Spark自身的JAR以及其依赖项。
drwxr-xr-x kubernetes:包含与Kubernetes集成相关的资源和配置。
-rw-r--r-- LICENSE:Spark的许可证文件,说明了软件的许可条款。
drwxr-xr-x licenses:包含Spark所依赖的第三方库的许可证文件。
-rw-r--r-- NOTICE:关于Spark的一些法律声明和通知。
drwxr-xr-x python:包含PySpark(Spark的Python API)相关的文件和资源。
drwxr-xr-x R:包含SparkR(Spark的R API)相关的文件和资源。
-rw-r--r-- README.md:提供关于Spark的简要介绍和使用说明。
-rw-r--r-- RELEASE:包含当前Spark版本的发布说明。
drwxr-xr-x sbin:包含用于启动和停止Spark集群的脚本。
drwxr-xr-x yarn:包含与Hadoop YARN集成相关的jar包。2、配饰spark-env.sh
进入$SPARK_HOME/conf,配置spark-env.sh,配置如下内容:
bash
[root@node1 ~]# cd /software/spark-3.5.5/conf/
[root@node1 conf]# mv spark-env.sh.template spark-env.sh
[root@node1 conf]# vim spark-env.sh
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=3g
export SPARK_WORKER_WEBUI_PORT=8081- SPARK_MASTER_HOST:必配项,master的ip。
- SPARK_MASTER_PORT:提交任务的端口,默认7077。
- SPARK_MASTER_WEBUI_PORT:Spark WebUI端口,默认8080。
- SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数,默认是对应节点上所有可用的core。
- SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存大小,默认1G。
- SPARK_WORKER_WEBUI_PORT:worker WebUI 端口。
3、配置workers
进入$SPARK_HOME/conf,配置workers,写入node2、node3节点:
bash
[root@node1 ~]# cd /software/spark-3.5.5/conf/
[root@node1 conf]# mv workers.template workers
[root@node1 conf]# vim workers
node2
node34、将配置好的安装包发送到node2、node3节点上
bash
[root@node1 software]# cd /software/
[root@node1 software]# scp -r ./spark-3.5.5 node2:`pwd`
[root@node1 software]# scp -r ./spark-3.5.5 node3:`pwd`5、启动Standalone集群
进入$SPARK_HOME/sbin,指定如下命令启动standalone集群。
bash
[root@node1 software]# cd /software/spark-3.5.5/sbin
[root@node1 sbin]#./start-all.sh注意:启动SparkStandalone集群的命令"start-all.sh"与启动HDFS集群的命令"start-all.sh"命令一样,这里不再单独配置Spark环境变量。
Standalone集群启动完成后,在浏览器输入"http://node1:8080"查看Spark Standalone集群信息。
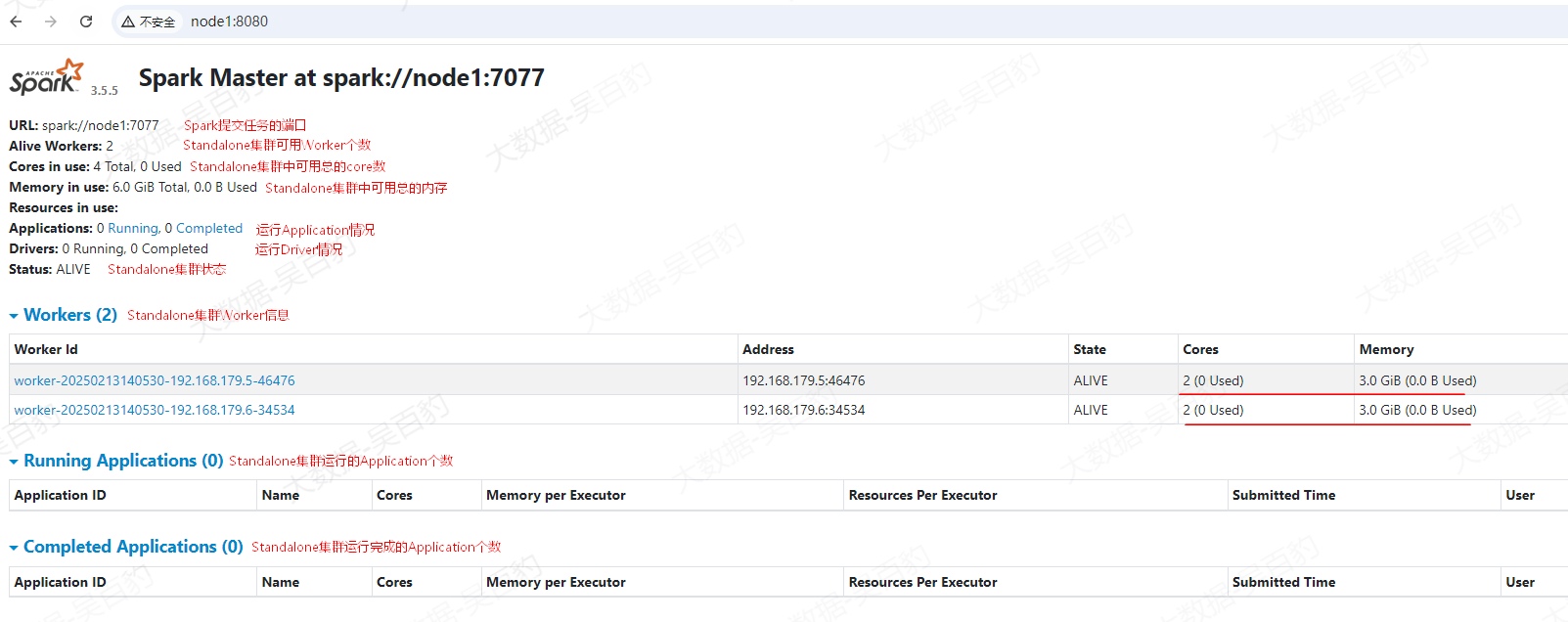
注意:如果Standalone集群没有正常运行,可以通过查看各个节点的$SPARK_HOME/logs目录中的日志错误来解决。
三、提交任务测试
这里向Standalone集群中提交Spark Pi任务为例,来测试集群是否可以正常提交任务。向Standalone集群中提交任务需要准备Spark客户端。
Spark客户端主要就是向Spark集群中提交任务,只要一台节点上有Spark安装包,就可以向Spark集群中提交任务,这里在node4节点上单独再搭建Spark提交任务的客户端,只需要将Spark安装包解压放在node4节点即可。
bash
[root@node4 ~]# cd /software/
[root@node4 software]# tar -zxvf ./spark-3.5.5-bin-hadoop3-scala2.13.tgz
[root@node4 software]# mv ./spark-3.5.5-bin-hadoop3-scala2.13 spark-3.5.5注意:任何一台Spark Standalone集群中的节点都可以作为客户端向Standalone集群中提交任务,这里只是将node4节点作为提交任务客户端后续向Standalone集群中提交任务。
在node4节点上向Standalone集群中提交任务命令如下:
bash
[root@node4 ~]# cd /software/spark-3.5.5/bin/
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.13-3.5.5.jar 100任务提交后,可以看到向Standalone集群中提交任务并执行100个task,最终输出pi大致结果。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨