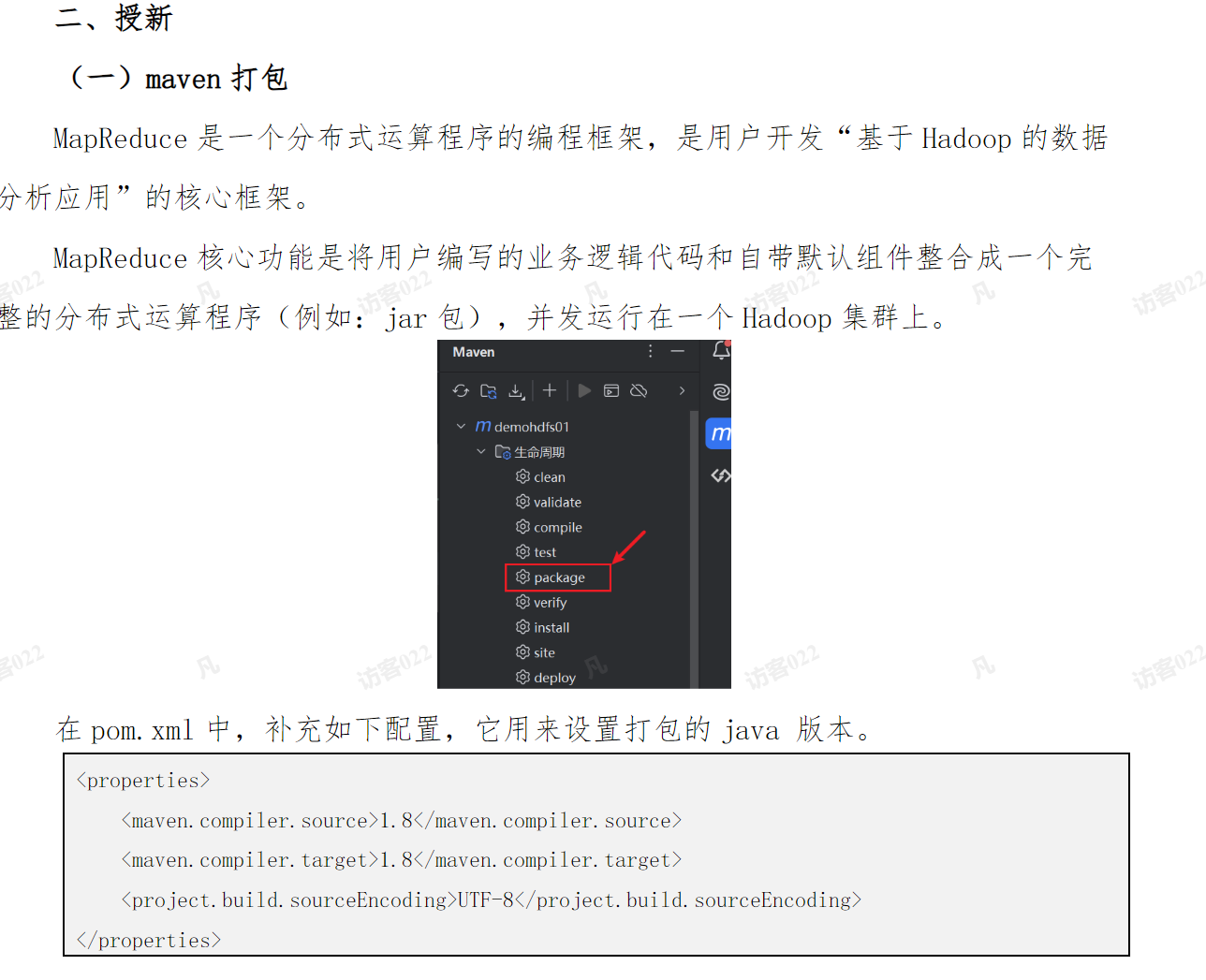
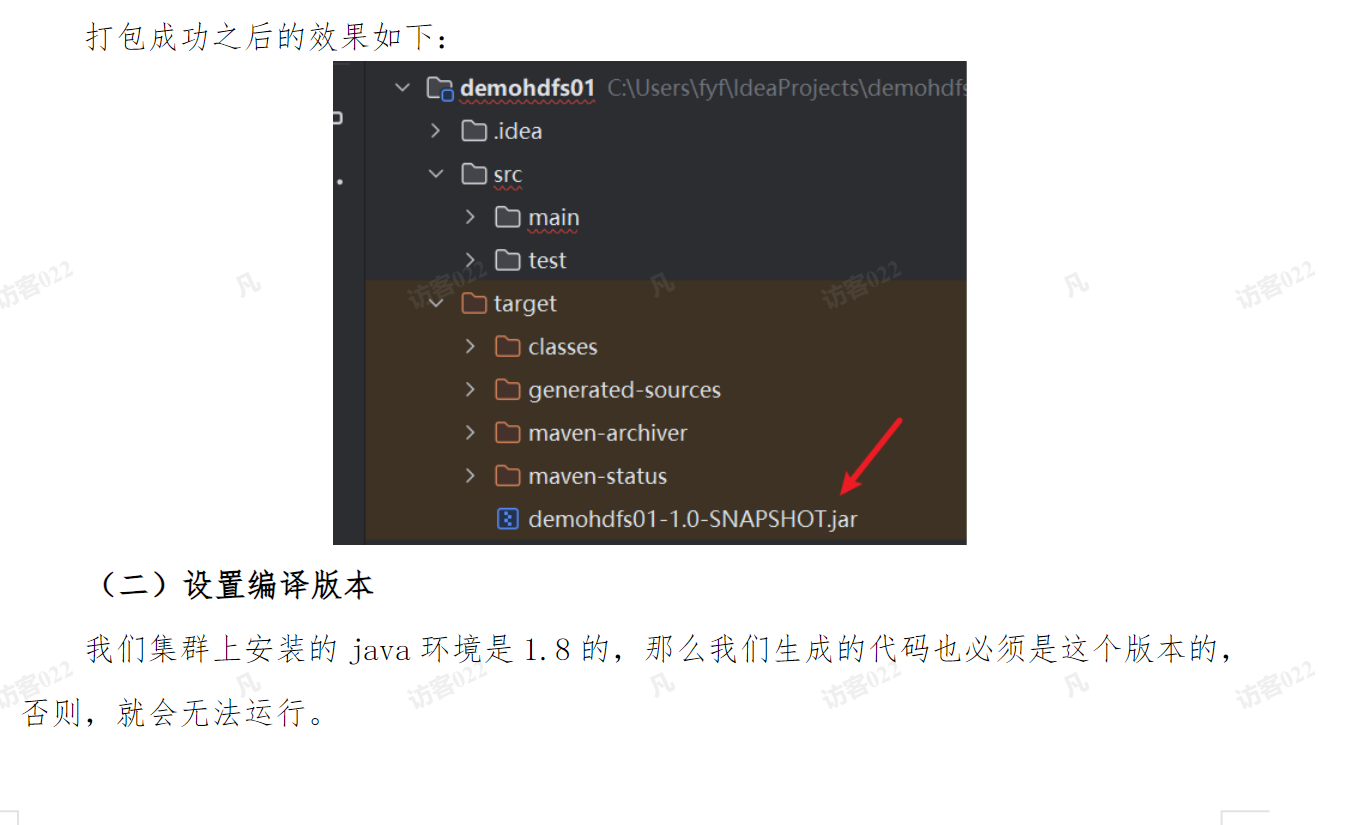
三)修改代码,设置执行环境和文件路径
我们集群上安装的java环境是1.8的,那么我们生成的代码也必须是这个版本的,否则,就会无法运行。
打开代码,找到driver类,并修改如下:
conf.set("fs.defaultFS", "hdfs://hadoop100:8020"); // 新增加一句
FileInputFormat.setInputPaths(job, new Path("/wcinput")); // 修改
FileOutputFormat.setOutputPath(job, new Path("/output1"));
确保集群中有/wcinput目录,并且下面有记事本文件中的单词。
确保集群中没有output1这个目录,因为它应该是要被动态创建出来的。
(四)上传到节点运行
使用finalshell上到任意节点,例如hadoop100上的/opt下,。
然后通过命令来执行执行WordCount程序,注意要写Driver类的全名
$ hadoop jar /opt/wc.jarcom.root.mapreduce.wordcount.WordCountDriver
(五)修改执行参数
在上面的代码中,我们的程序只能完成固定目录下的功能。现在希望它能处理不同的目录。
修改代码,让程序能指定要执行的输入目录和要保存结果的输出目录。
修改driver类的代码,更新输入和输入路径。
// 6. 设置输入和输出路径
路径为程序的第一个参数,第二个参数
FileInputFormat.setInputPaths(job, new Path(args0));
FileOutputFormat.setOutputPath(job, new Path(args1));
这里的args0和args1是程序运行时的两个参数。