目录
[1. 将与Linux上版本相同的hadoop压缩包解压到本地](#1. 将与Linux上版本相同的hadoop压缩包解压到本地)
[编辑2.设置HADOOP HOME环境变量指向:E:\\hadoop-3.3.4](#编辑2.设置HADOOP HOME环境变量指向:E:\hadoop-3.3.4)
[4.将hadoop.dll和winutils.exe放入HADOOP HOME/bin中](#4.将hadoop.dll和winutils.exe放入HADOOP HOME/bin中)
[1.下载Big Data Tools插件](#1.下载Big Data Tools插件)
Windows的准备
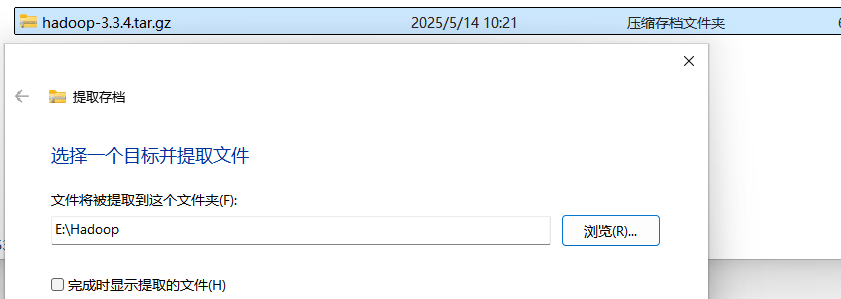
1. 将与Linux上版本相同的hadoop压缩包解压到本地
如解压到E:\Hadoop。
 2.设置$HADOOP HOME环境变量指向:E:\hadoop-3.3.4
2.设置$HADOOP HOME环境变量指向:E:\hadoop-3.3.4
打开此电脑的属性
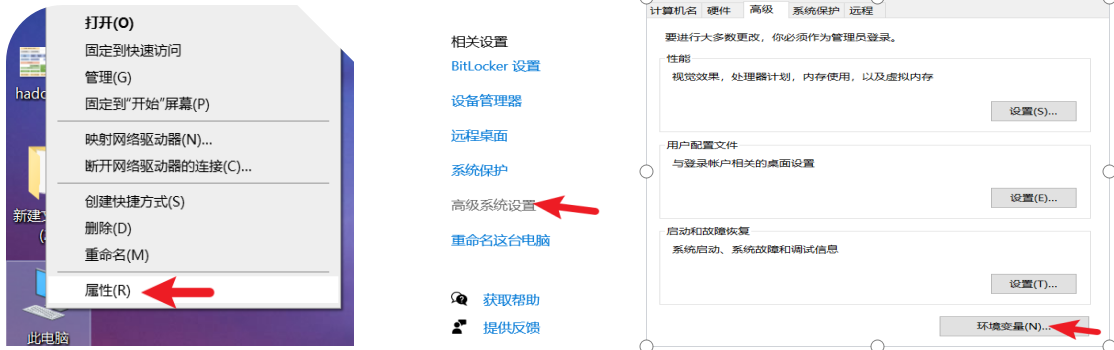
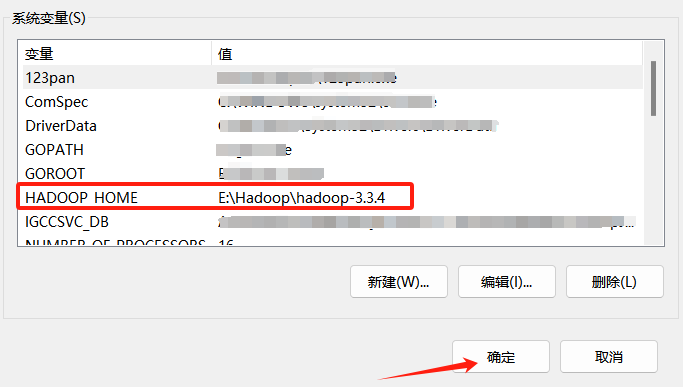
找到环境变量,进入环境变量,点击进入系统变量,编辑,添加
HADOOP_HOME
E:\Hadoop\hadoop-3.3.4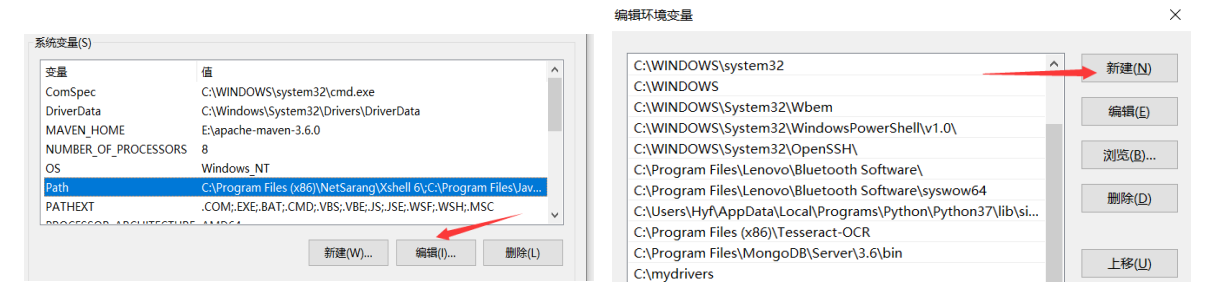
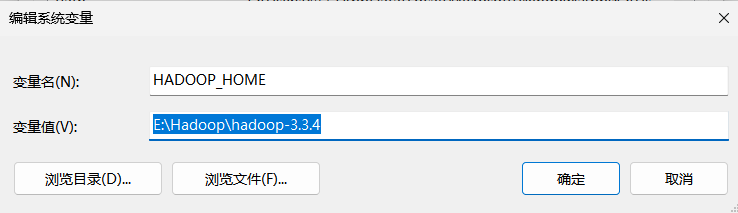
点击确定,确定,确定!!!
确保环境变量配置正确,如下图。
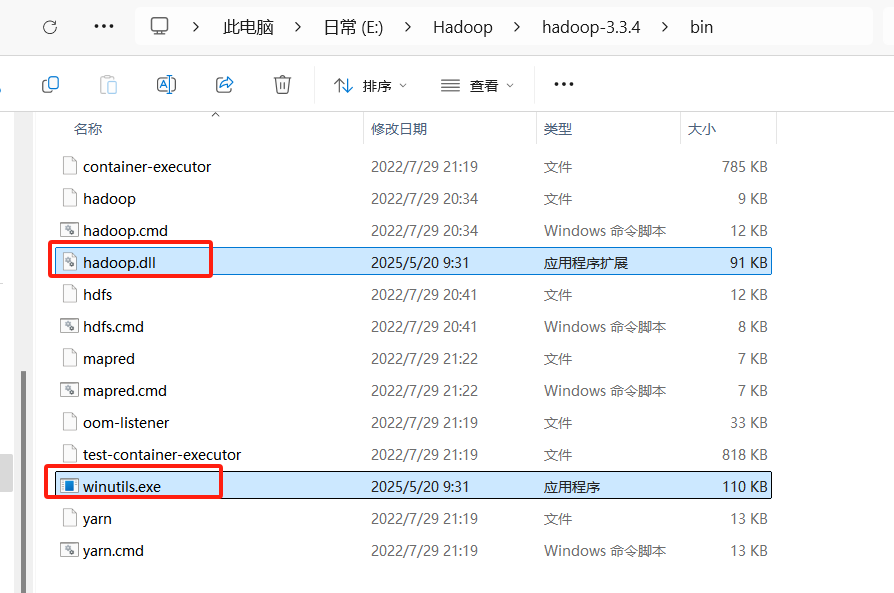
3.下载hadoop.dll和winutils.exe文件
下载路径如下:
- hadoop.dll(https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/hadoop.dll)
- winutils.exehttps://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe)
4.将hadoop.dll和winutils.exe放入$HADOOP HOME/bin中
IDEA中操作
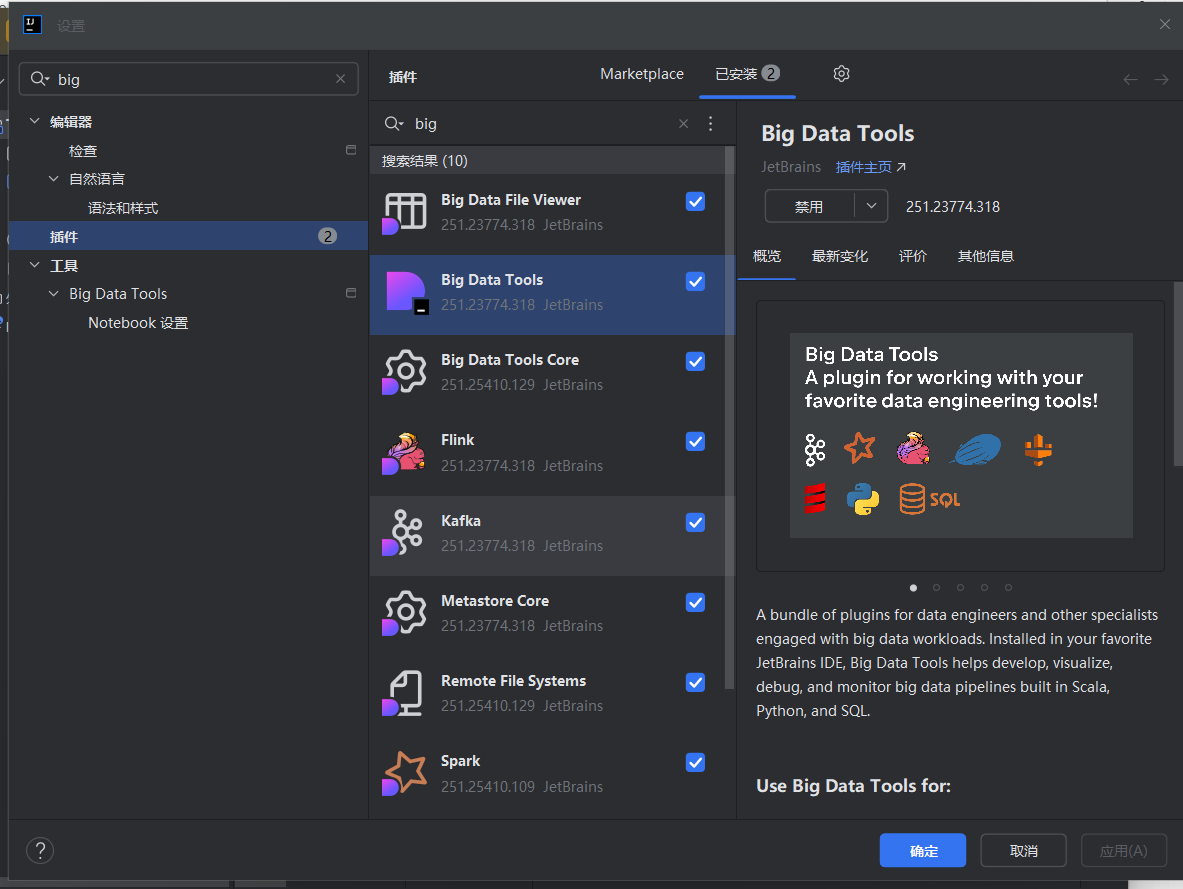
1.下载Big Data Tools插件
确保 IDEA 版本与 Big Data Tools 兼容, 本文以IntelliJ IDEA 2025.1.1.1为例
2.添加并连接HDFS
安装好之后, 右侧边栏会出现Big Data Tools的选项框。
点击选项框, 在左上角的 + 中选择添加HDFS
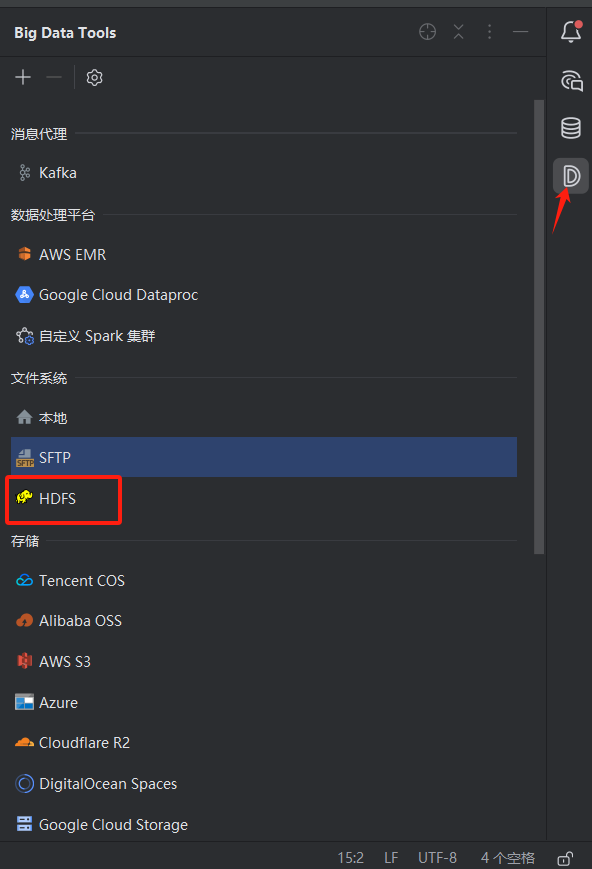
然后进行如下操作:
- 在红框内填入Linux服务器地址或者虚拟机的IP地址
- 在黄框内填入Linux中使用hadoop的用户
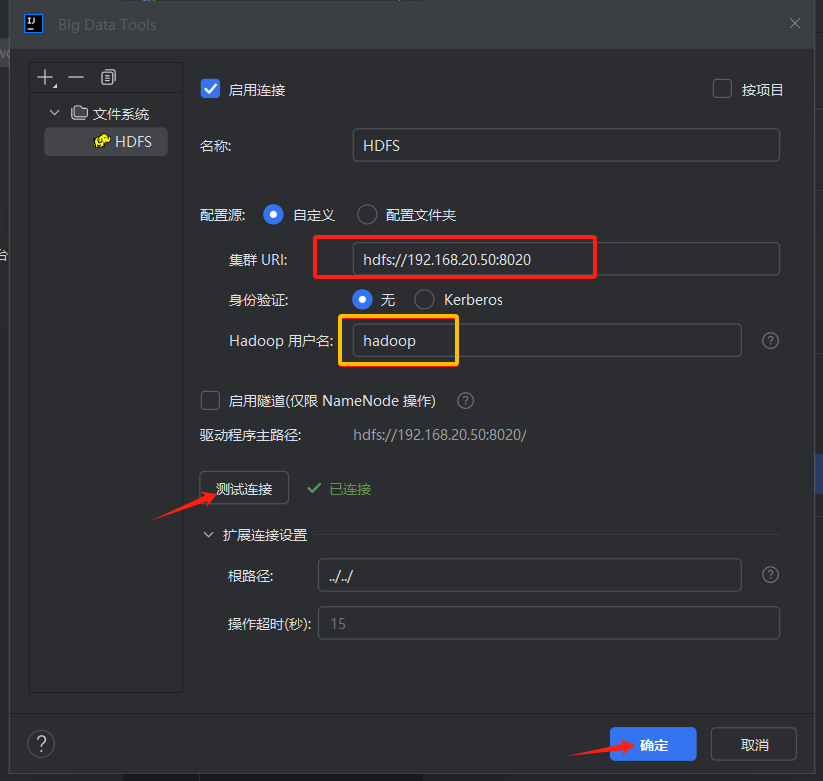
然后点击测试链接,成功会显示已连接,然后点击确定,如下图。
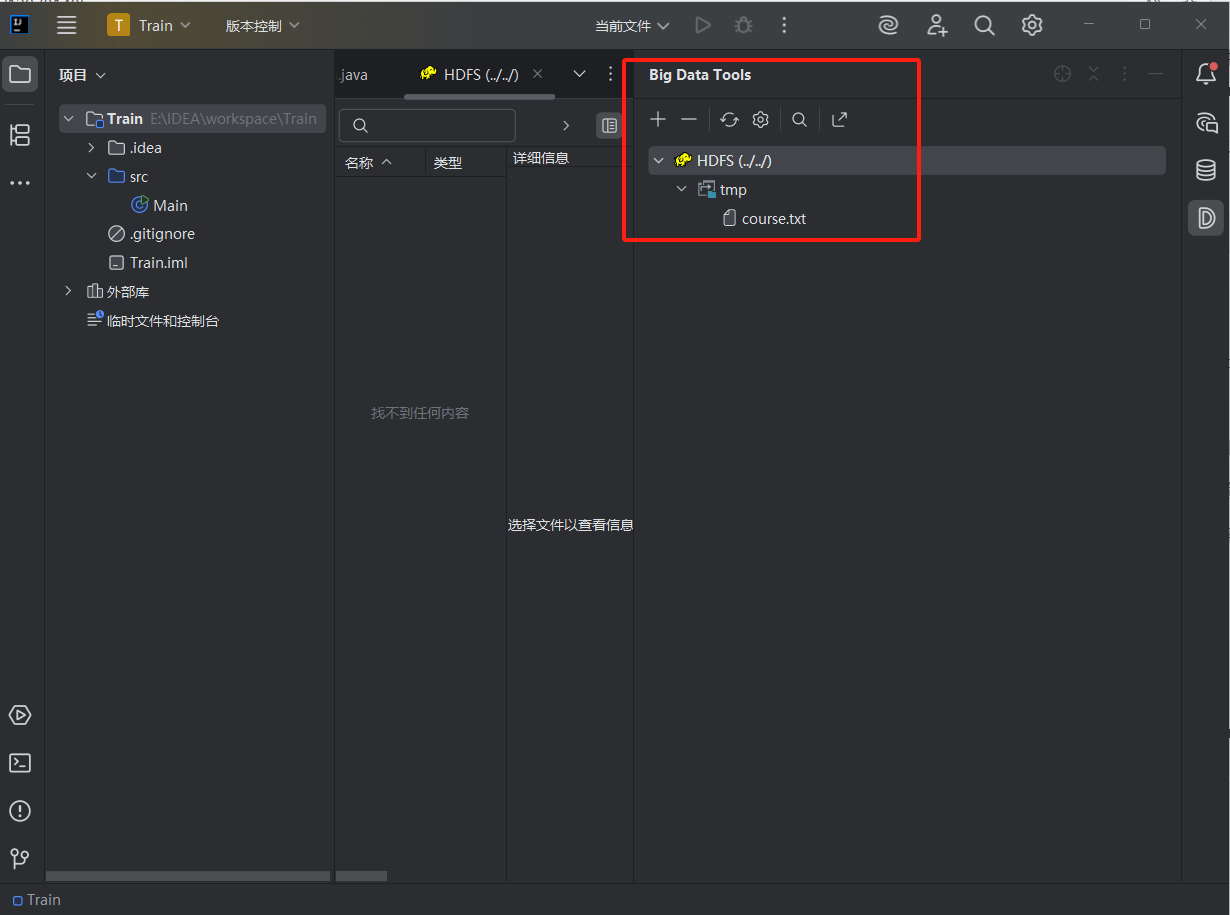
至此,IDEA成功连接Hadoop的HDFS。