#任务:基于已有文本数据,建立LSTM模型,预测序列文字
1 完成数据预处理,将文字序列数据转化为可用于LSTM输入的数据。
2 查看文字数据预处理后的数据结构,并进行数据分离操作
3 针对字符串输入("In the heart of the ancient, dense forest, where sunlight filtered through the thick canopy in a patchwork of gold and shadow, a creature of unparalleled grace and mystery roamed. This was no ordinary animal; it was a panther, a living embodiment of the wild's s untamed beauty and raw power. Its presence sent shivers down the spines of every creature that shared its domain, a silent yet potent reminder of nature's hierarchy.")预测其后续对应的字符
备注:模型结构:单层LSTM,输出20个神经元;每次使用前20个字符预测第21个字符。
#l载入数据
data = open('test.txt').read()
#移除换行符
data = data.replace('\n','').replace('\r','')
print(data)
#字符去重
letters = list(set(data))
print(letters)
num_letters = len(letters)
print(num_letters)
#建立字典,字母到数字的映射关系
int_to_char={a:b for a,b in enumerate(letters)}
print(int_to_char)
char_to_int={b:a for a,b in enumerate(letters)}
print(char_to_int)

----------生成训练数据---------
time_step = 20
import numpy as np
from keras.utils import to_categorical
滑动窗口提取数据
def extract_data(data, slide):
x = \[\]
y = \[\]
for i in range(len(data) - slide):
x.append(a for a in data\[i:i+slide])
y.append(datai+slide) # 修正变量名,将side改为slide
return x, y
字符到数字的批量转化
def char_to_int_Data(x, y, char_to_int):
x_to_int = \[\]
y_to_int = \[\]
for i in range(len(x)):
x_to_int.append(char_to_int\[char for char in xi])
y_to_int.append(char_to_int\[char for char in yi])
return x_to_int, y_to_int
实现输入字符文章的批量处理,输入整个字符,滑动窗大小,转化字典
def data_preprocessing(data, slide, num_letters, char_to_int):
char_Data = extract_data(data, slide)
int_Data = char_to_int_Data(char_Data0, char_Data1, char_to_int)
Input = int_Data0
Output = list(np.array(int_Data1).flatten())
Input_RESHAPED = np.array(Input).reshape(len(Input), slide)
创建全零数组,然后用独热编码填充
one_hot_input = np.zeros((Input_RESHAPED.shape0, Input_RESHAPED.shape1, num_letters))
修正嵌套循环的索引
for i in range(Input_RESHAPED.shape0): # 遍历样本
for j in range(Input_RESHAPED.shape1): # 遍历时间步
one_hot_inputi, j, : = to_categorical(Input_RESHAPEDi, j, num_classes=num_letters)
return one_hot_input, Output
#提取X和y的数据
X, y = data_preprocessing(data, time_step, num_letters, char_to_int)
#分离数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.1,random_state=10)
print(X_train.shape, len(y_train))
y_train_category = to_categorical(y_train, num_letters)
print(y_train_category)
#setup the model
from keras.models import Sequential
from keras.layers import Dense, LSTM
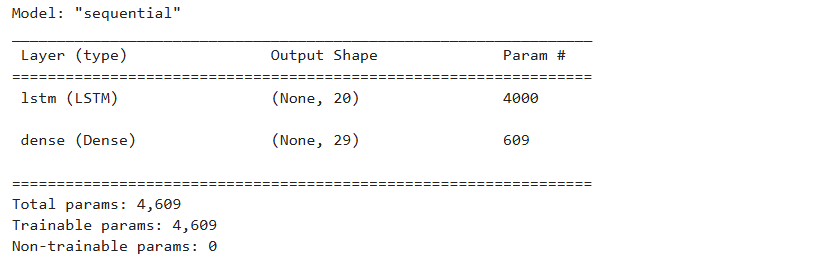
model =Sequential()
model.add(LSTM(units=20, input_shape=(X_train.shape1, X_train.shape2), activation='relu'))
model.add(Dense(units=num_letters, activation='softmax'))
model.compile(optimizer='adam', loss = 'categorical_crossentropy', metrics='accuracy')
model.summary()
#train the model
model.fit(X_train,y_train_category,batch_size=1000,epochs=50)
#make prediction based on the training data
假设这是一个分类模型(如多类或二分类)
使用 model.predict() 替代 predict_classes()
y_train_predict_probs = model.predict(X_train)
对于多分类问题(softmax输出),获取预测类别索引
if y_train_predict_probs.shape1 > 1:
y_train_predict = np.argmax(y_train_predict_probs, axis=1)
对于二分类问题(sigmoid输出),使用阈值0.5
else:
y_train_predict = (y_train_predict_probs > 0.5).astype(int)
print(y_train_predict)
#transform the int to letters
y_train_predict_char = int_to_char\[i for i in y_train_predict]
print(y_train_predict_char)
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train, y_train_predict)
print(accuracy_train)
#make prediction based on the training data
假设这是一个分类模型(如多类或二分类)
使用 model.predict() 替代 predict_classes()
y_test_predict_probs = model.predict(X_test)
对于多分类问题(softmax输出),获取预测类别索引
if y_test_predict_probs.shape1 > 1:
y_test_predict = np.argmax(y_test_predict_probs, axis=1)
对于二分类问题(sigmoid输出),使用阈值0.5
else:
y_test_predict = (y_test_predict_probs > 0.5).astype(int)
#transform the int to letters
y_test_predict_char = int_to_char\[i for i in y_test_predict]
print(y_test_predict_char)
from sklearn.metrics import accuracy_score
accuracy_test = accuracy_score(y_test, y_test_predict)
print(accuracy_test)
print(y_test_predict)
print(y_test)
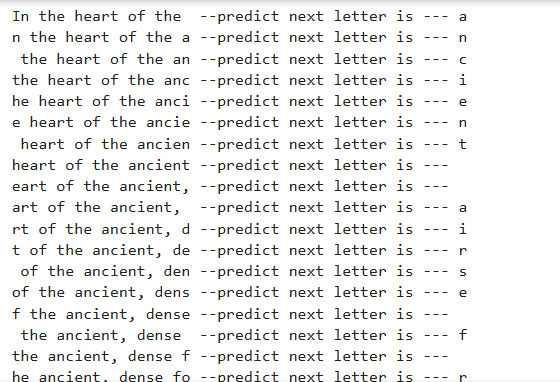
new_letters = 'In the heart of the ancient, dense forest, where sunlight filtered through the thick canopy in a patchwork of gold and shadow, a creature of unparalleled grace and mystery roamed. '
#new_letters = 'fifin is a student in sf industry. He studiess her her fo sssssssss'
X_new,y_new = data_preprocessing(new_letters, time_step, num_letters, char_to_int)
#make prediction based on the training data
假设这是一个分类模型(如多类或二分类)
使用 model.predict() 替代 predict_classes()
y_new_predict_probs = model.predict(X_new)
对于多分类问题(softmax输出),获取预测类别索引
if y_new_predict_probs.shape1 > 1:
y_new_predict = np.argmax(y_new_predict_probs, axis=1)
对于二分类问题(sigmoid输出),使用阈值0.5
else:
y_new_predict = (y_new_predict_probs > 0.5).astype(int)
print(y_new_predict)
#transform the int to letters
y_new_predict_char = int_to_char\[i for i in y_new_predict]
print(y_new_predict_char)
for i in range(0, X_new.shape0-20):
print(new_lettersi:i+20, '--predict next letter is ---', y_new_predict_chari)