目录
[order by](#order by)
CRUD
表的增查改删:C(Create),R(Retrieve),U(Update),D(Delete)
Create
创建表

创建完表后插入数据,有两种方式:指定插入和全列插入

除了单行数据插入,mysql也支持多行数据插入
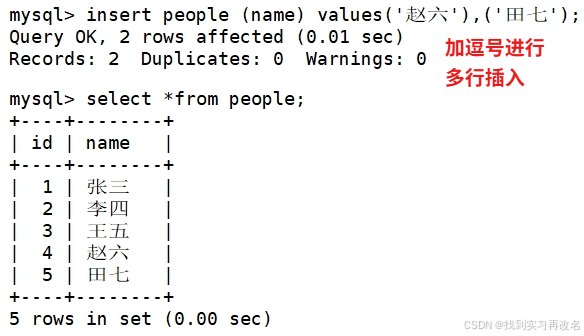
当插入数据在表中出现时,mysql会拦截你不让你插入;但是你想把原先存在的数据进行替换,有以下两种操作:
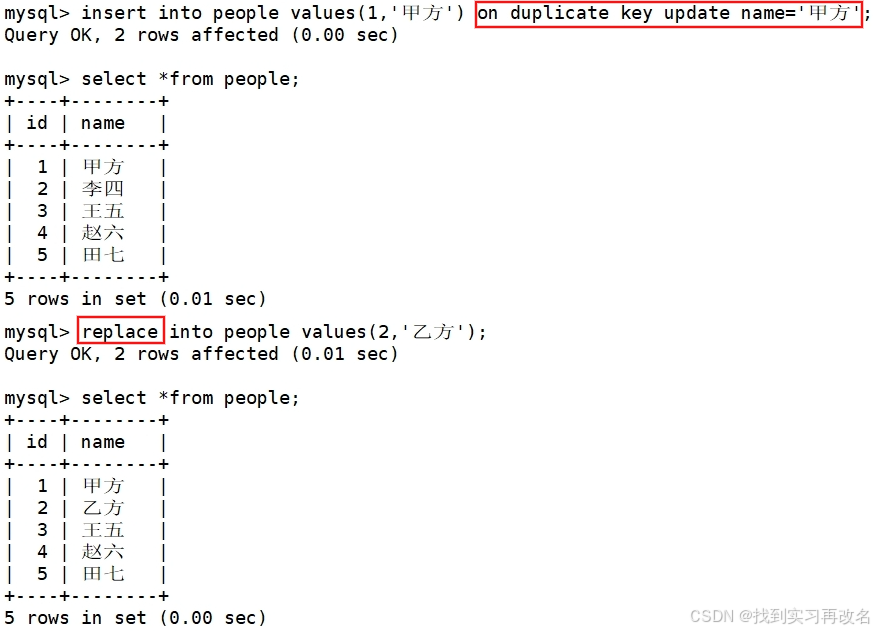
Retrieve
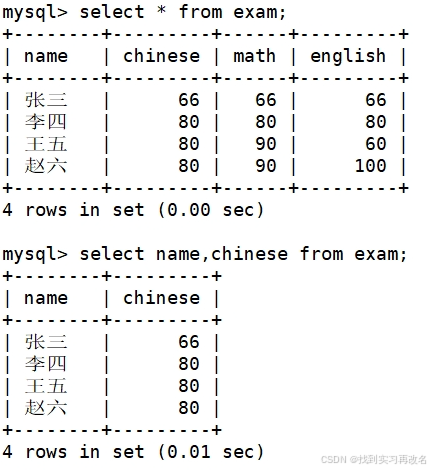
对数据作查询;查询数据之前先有表,表中还有有数据

查询语句select 对表中插入数据进行查看:有全列查询与指定查询
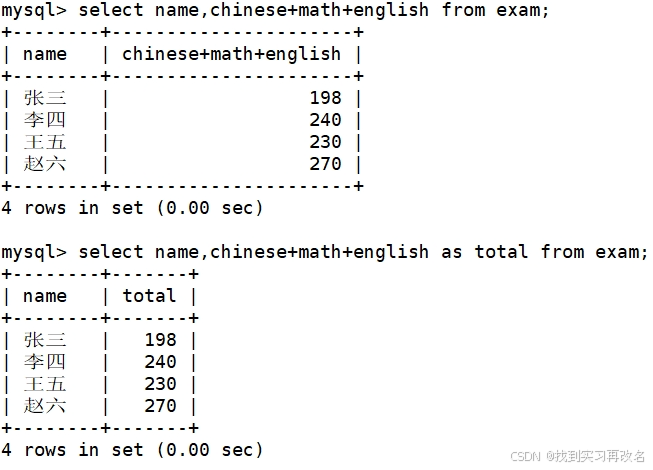
还能使用表达式统计它们的分数总和
如果分数出现重复,也可以使用 select 进行去重(这里 unique key 就不会出现数据)

where
select 搭配 where 进行使用时,where 后面接的是判断语句,与 if 用法是一样的,但在 mysql 中运算符的表示上就有区别
|-------------------|---------------------------------------------------|
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,a0, a1,如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
|-----|-------------------------------|
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为FALSE(0) |
英语小于70的同学及英语成绩

数学成绩在 80, 90 分的同学及其数学成绩:共有两种方法:比较法 和 between
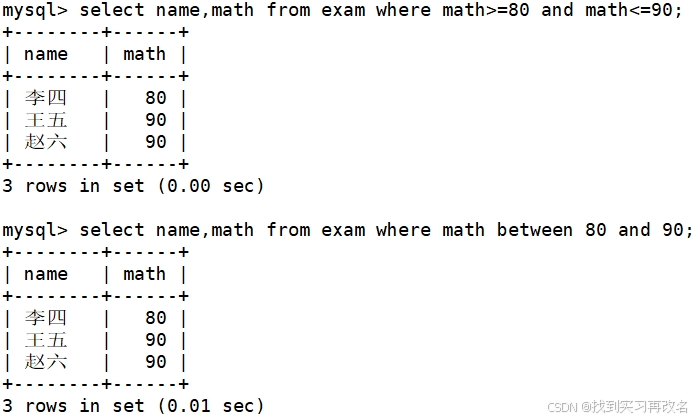
英语成绩是 60 或者 80 或者 100 分的同学及英语成绩,两种方法:比较法 和 in

找姓找同学和找赵某同学,使用%匹配多个字符,使用_匹配单个字符

总分在 200 分以下的同学:此时查询时如果是把总分的结果起别名,再把别名进行where 比较,会出现报错:因为 select 语句是从where开始执行,此时起别名操作还没生效!

语文成绩超过 80 分并且不姓孙的同学

找张某同学,或者要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80 的同学

order by
升序搭配 asc ;降序搭配 desc
全部学生的数学成绩按照升序排列,order by 不加desc 时默认排的是升序,但不推荐省略排升序
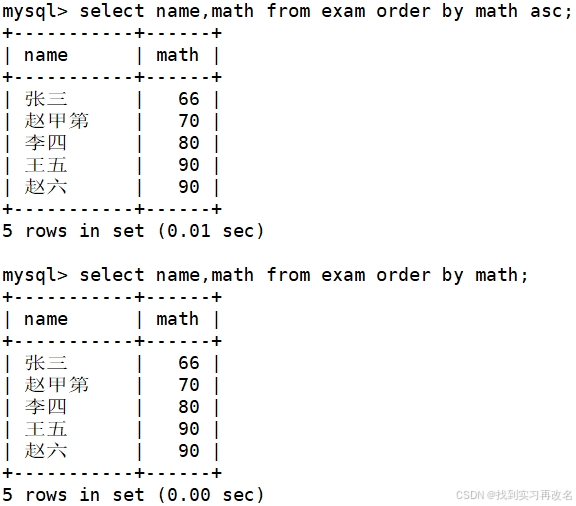
而NULL进行排序时,结果都比任何一个数要小
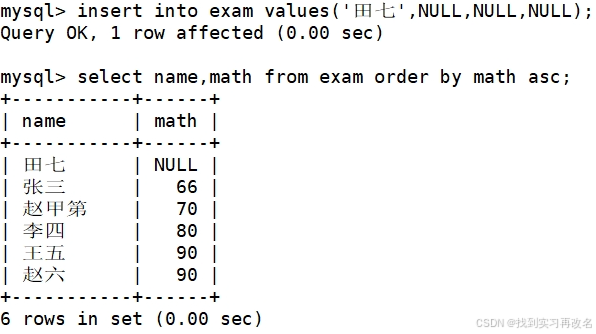
将同学各门成绩,依次按:数学降序,英语升序,语文升序的方式显示,多种情况排序是排序顺序按照书写顺序

查询同学及总分,由高到低

在 where中不能使用别名操作,这里怎么可以使用别名来进行排序? 因为进行排序时数据一定要准备好的,也就说前面的语句先执行(要有合适的数据再排序,而where不需要)
查询姓李的同学或者姓赵的同学数学成绩,结果按数学成绩由高到低显示

limit
查询表中数据时,不推荐直接使用 * 查询全部数据:数据有千万条,* 查询会一直刷屏查找不完,所以推荐查找时加上 limit 按找目标行下标查询想要的数据量(mysql也是从下标0开始)
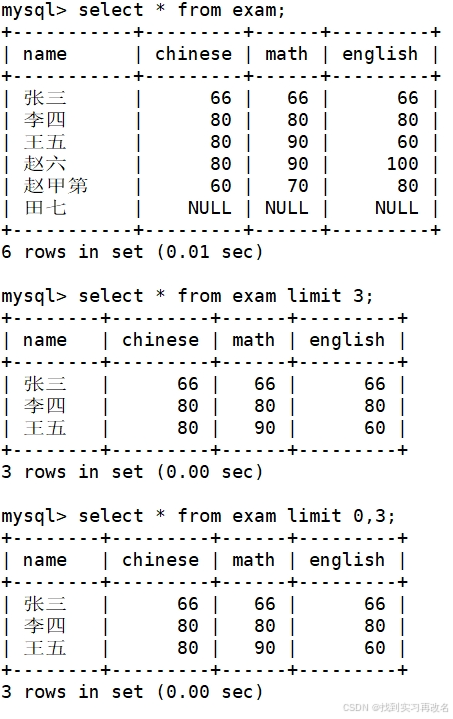
也可以使用 offset 的方式设置下标
在平常看电子书的分页功能就是设置了指定的offset 下标实现分页功能

用 limit 时也可以使用别名的方式进行"显示"数据:先要展示数据,数据是不是要先准备好!

Update
对查询结果进行更新
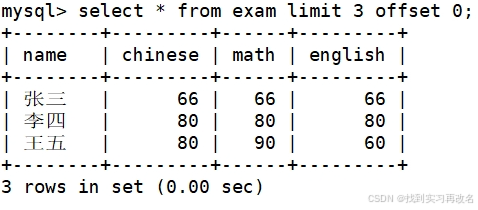
将张三的数学成绩变更为 80 分
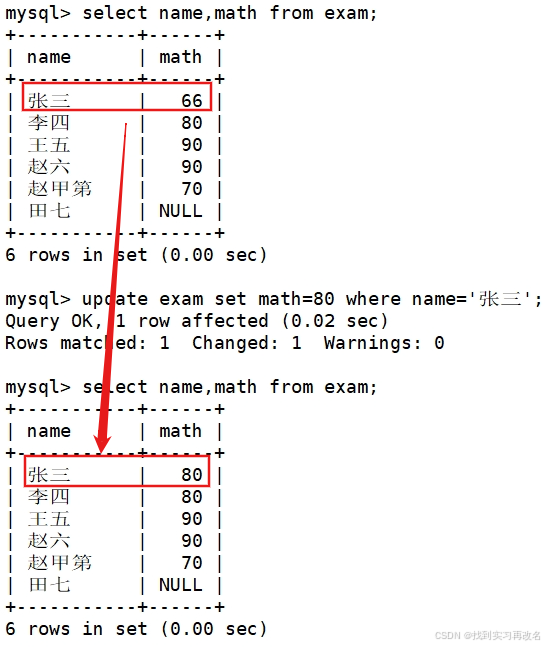
将田七的数学成绩变更为 60 分,语文成绩变更为 80 分
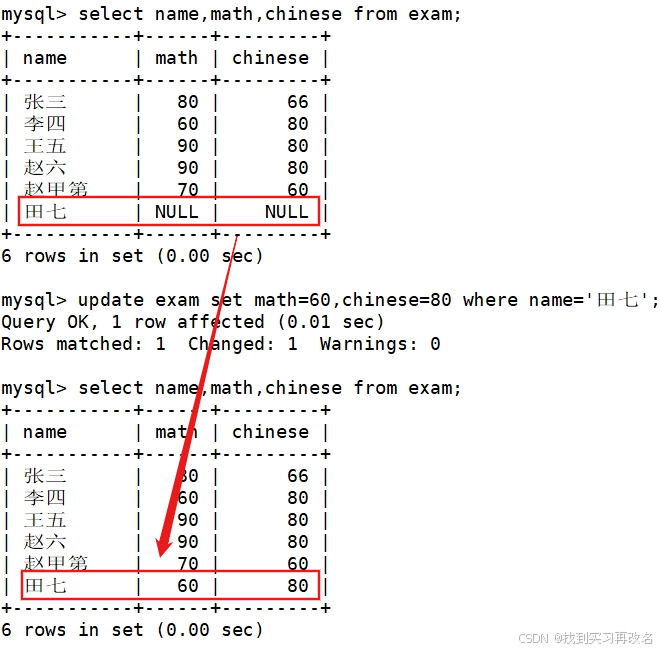
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分(mysql 不支持+=操作)
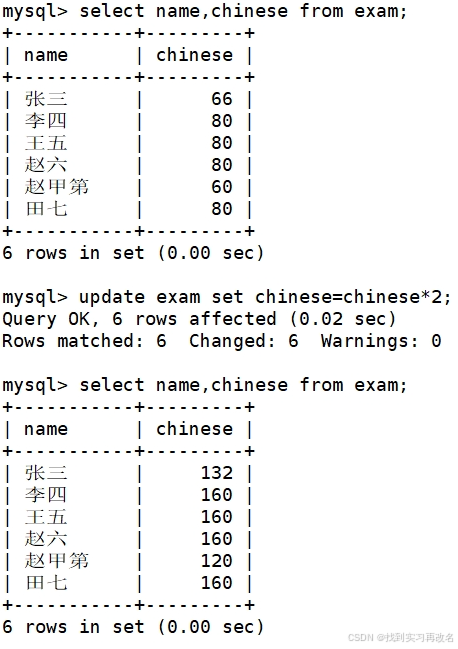
将所有同学的语文成绩更新为原来的 2 倍(在平时使用时慎用该操作)
Delete
只对表中的数据进行删除,不会把表也给删除掉
删除田七同学的考试成绩

删除整张表数据(注意:删除整表操作要慎用!)准备测试表,插入数据后进行测试
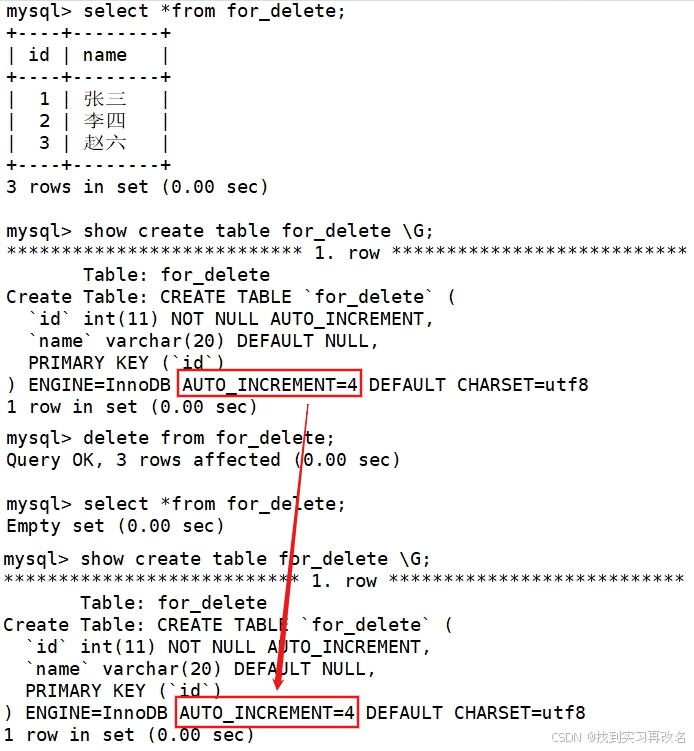
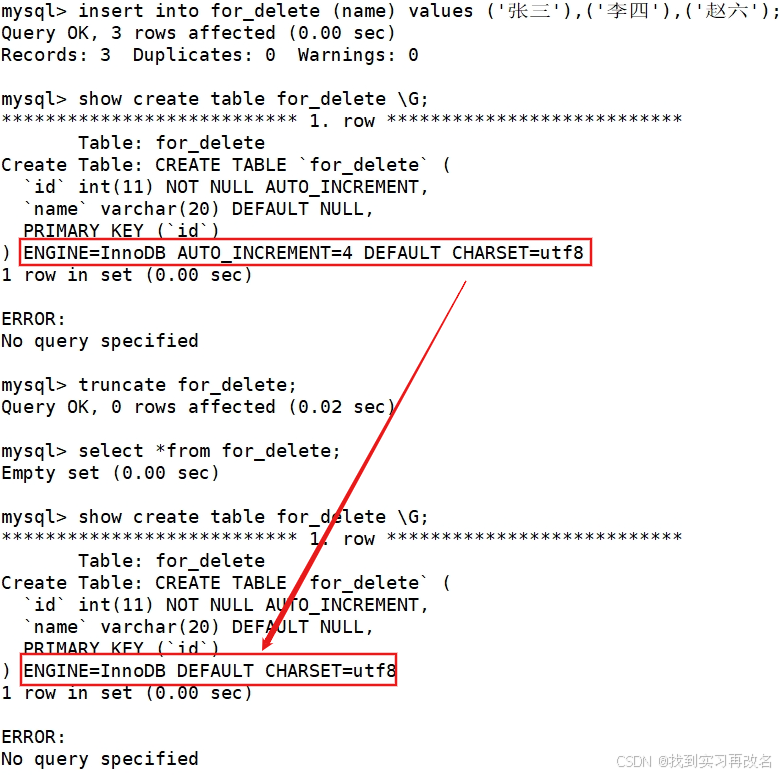
删除后,表中id的auto_increment没变,下次插入的数据开始为4;但如果想让下次开始为1的话,我们还有另一种方式:使用截断表:truncate 删除数据的同时改变表的auto_increment
| delete | truncate |
|---|---|
| 部分数据删除或者全部数据删除 | 只能全部数据删除 |
| 对数据操作,进行保留 | 不对数据操作,不经过事务无法进行回滚 |
| 不能重置 auto_increment | 重置 auto_increment |
去重操作
准备工作:先准备两张一样表
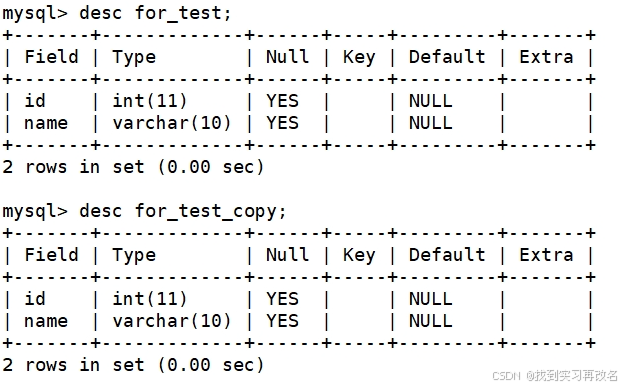
for_test 表中有重复数据;将它进行去重后的结果保留在 for_test_copy 表中
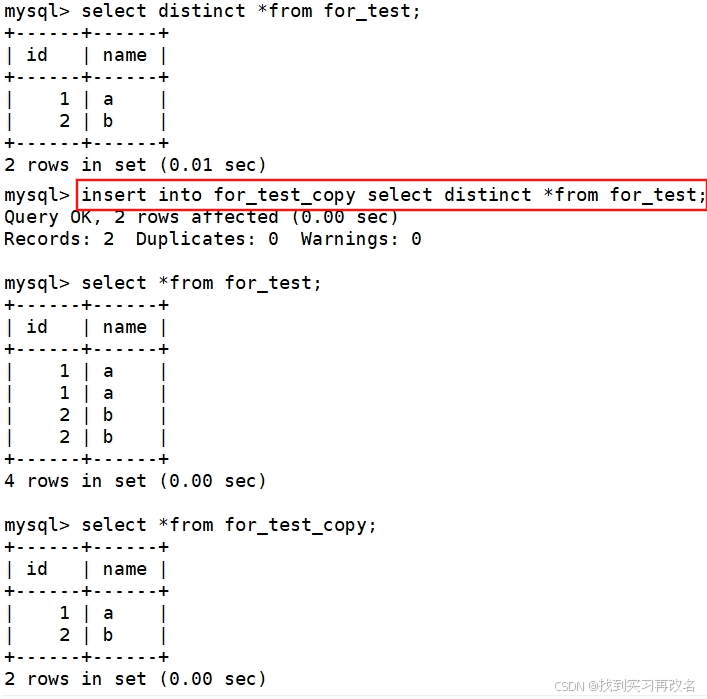
通过重命名表,实现表的原子操作
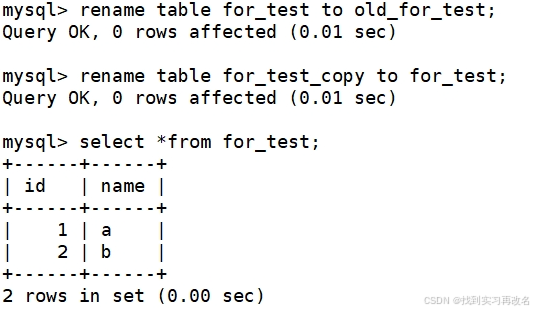
为什么最后是通过 rename 的方式进行的?
建表操作对应到Linux上就是在特定的目录下新建文件,进行 rename 操作其实是对文件进行重命名 mv 操作;当上传很大的数据文件到指定的目录上时,我们一般不直接进行这个操作,而是将数据文件统一上传到临时目录中,当数据文件统一上传完成后再对数据进行 mv 移动到特定的目录下使用:这个过程其实就是原子操作:只有成功与失败两种结果,保证安全性与可靠性;进行 rename 方式也类似:等一切数据就绪了,然后统一放入,更新,生效
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT(DISTINCT expr) | 返回查询到的数据的 数量 |
| SUM(DISTINCT expr) | 返回查询到的数据的 总和,不是数字没有意义,可以是任何数字 |
| AVG(DISTINCT expr) | 返回查询到的数据的 平均值,不是数字没有意义,可以是任何数字 |
| MAX(DISTINCT expr) | 返回查询到的数据的 最大值,不是数字没有意义,可以是任何数字 |
| MIN(DISTINCT expr) | 返回查询到的数据的 最小值,不是数字没有意义,可以是任何数字 |
统计班级共有多少同学参加了考试
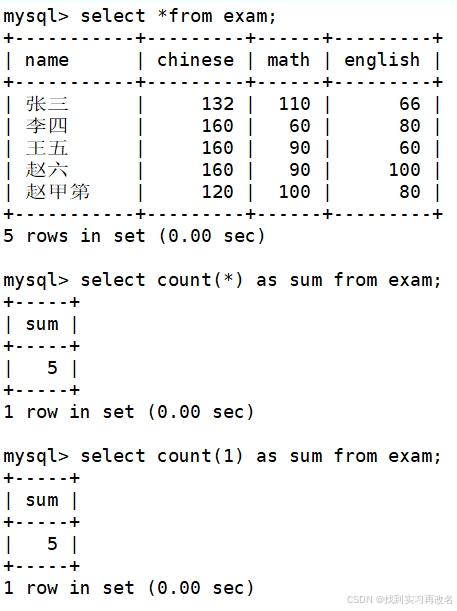
统计本次考试的英语成绩分数个数(去掉重复分数)
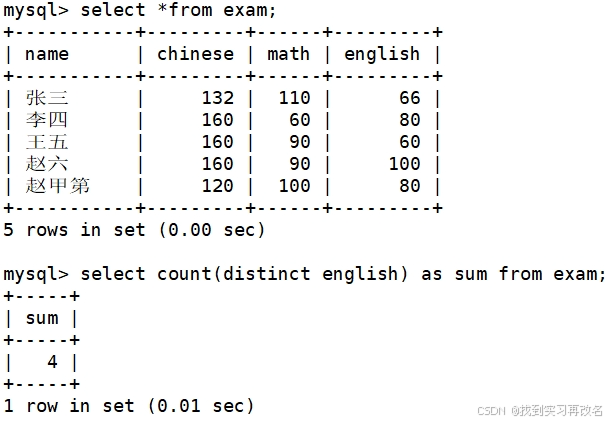
统计数学成绩总分并找出超过80分的人数
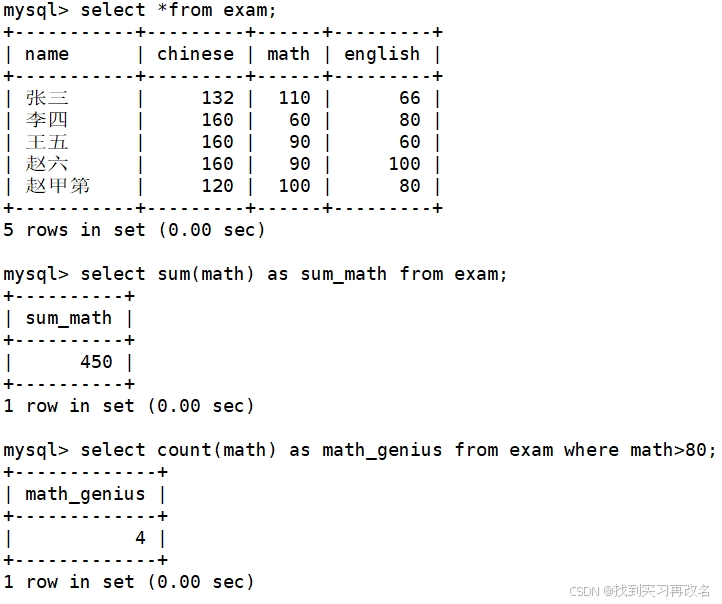
统计平均总分
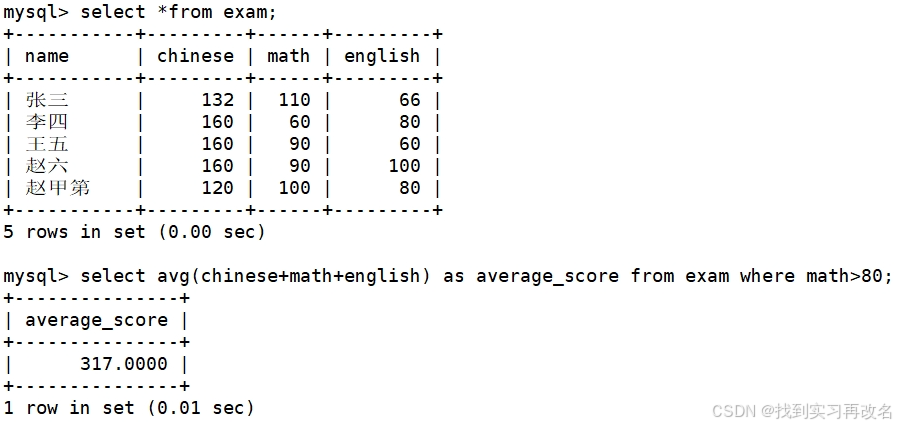
返回 > 70 分以上的数学最低分
聚合统计
在select中使用 group by子句可以对指定列进行分组,实现聚合统计
准备工作:创建一个雇员信息表(来自oracle 9i的经典测试表)
员工的部门表和薪资等级表
还有员工表
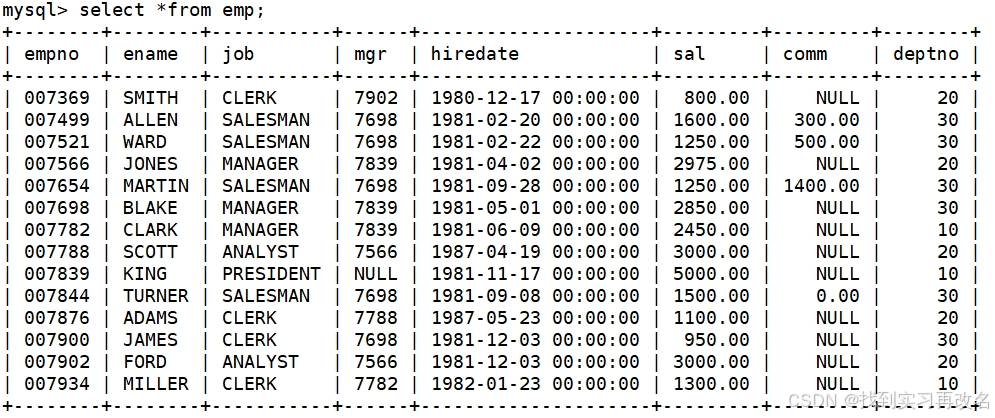
显示每个部门的平均工资和最高工资
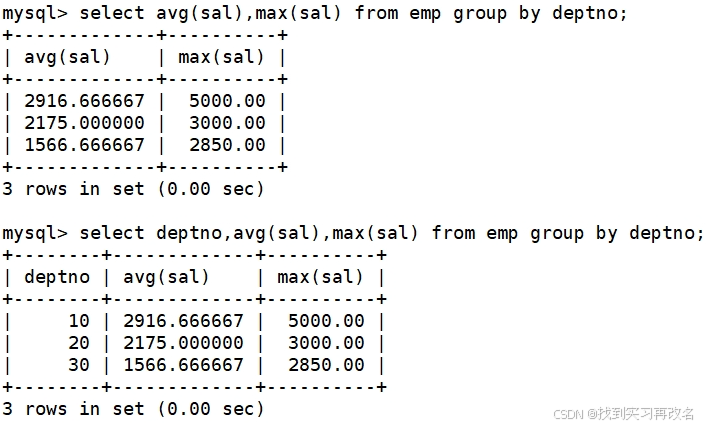
group by 指定列名:实际分组,是按不同的列名的行数据进行分组,组内的指定列名一定相同,从而进行聚合统计,聚合压缩
每个部门的每种岗位的平均工资和最低工资:先分为每个部门,再从每个部门中分成每种岗位后进行聚合统计
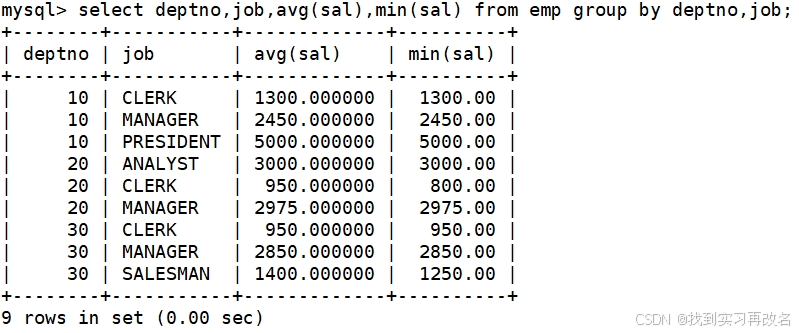
平均工资低于2000的部门和它的平均工资:先要聚合统计出各个部门的平均工资,再进行判断那个部门的工资低于2000,这里难道要使用where 语句? 使用where 语句会报错,要使用 having 语句,对聚合统计的数据进行条件筛选,一般与 group by 搭配使用
这里可能会有疑惑:where 和 having 都是进行条件筛选,区别在哪呢?
先来解决:除了SMITE的工资外,平均工资低于2000的部门和它的平均工资
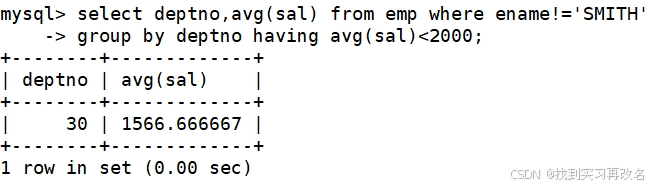
上面语句执行的顺序是:先提取表数据 from emp,再对表数据进行判断 where 判断,接着对'结果'进行分组 group by,再进行聚合统计 avg(sal),最后对聚合统计后的'结果'进行条件筛选平均工资低于2000的部门 avg(sal);所以:where 是对具体的列进行判断,而having 是对聚合后的结果进行判断,两者在条件筛选的阶段是不同的
对'结果'的理解:不要单纯地认为,保存在数据库中的表才是表,中间筛选出来的各种结果数据在我看来都是(逻辑)表,因为在mysql中一切皆表:只要掌握了单表的CRUD,未来所有的场景我们都能够应对解决!
内置函数
日期函数
| 函数名称 | 描述 |
|---|---|
| current_date() | 当前日期 |
| current_time() | 当前时间 |
| current_timestamp() | 当前时间戳 |
| date(datetime) | 返回datetime的日期部分 |
| date_add(date , interval d_value_type) | 添加date的时间,单位可以是year,day,minute,second |
| date_sub(date,interval d_value_type) | 将去date的时间,单位可以是year,day,minute,second |
| datediff(date1 , date2) | 两个日期的时间差,单位是天 |
| now() | 当前的时间 |
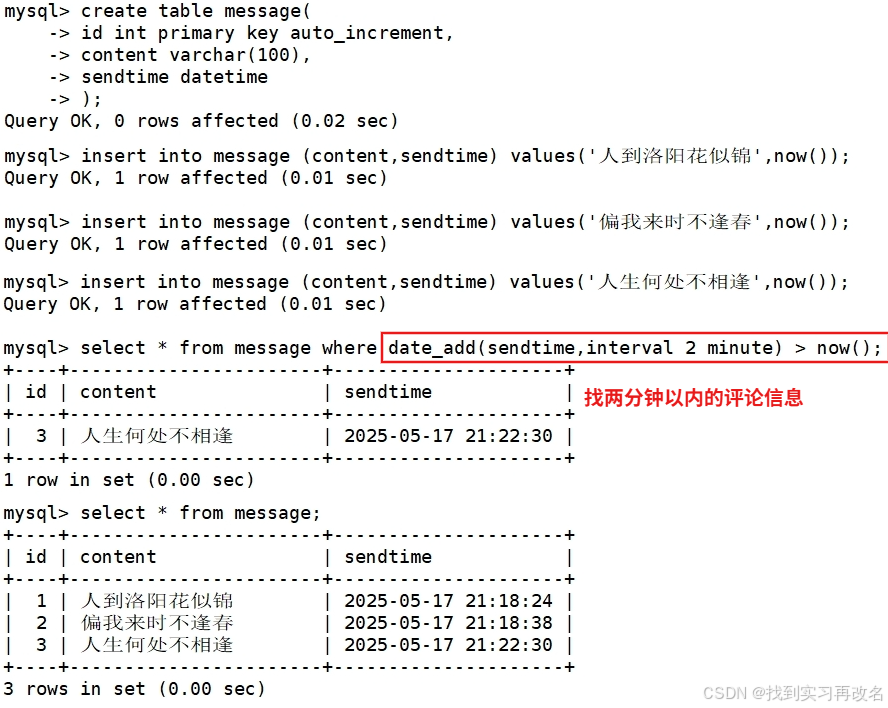
创建一个留言表并插入评论
字符函数
|-----------------------------------|------------------------------|
| charset(str) | 返回字符串字符集 |
| concat(string , ...) | 连接字符串 |
| instr(string1, string2) | 返回string2在string1出现的位置,没有返回0 |
| ucase(string) | string转大写 |
| lcase(string) | string转小写 |
| left(string , length) | 从string左边起取length个长度 |
| length(string) | 返回string的长度 |
| replace(str , string1 , string2) | 在str中的string1用string2替换 |
| substring(str , postion , length) | 从position位置开始取length个字符 |
| ltrim(string) | 去除左边所有空格 |
| trim(string) | 去除中间所有空格 |
| rtrim(string) | 去除右边所有空格 |
获取emp表的ename列的字符集

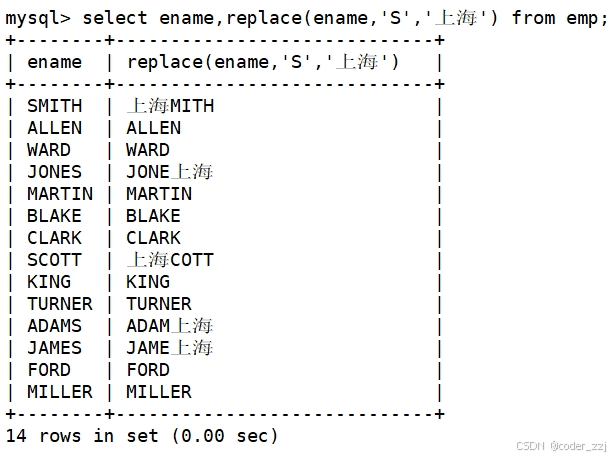
将emp表中所有名字中有S的替换成'上海'
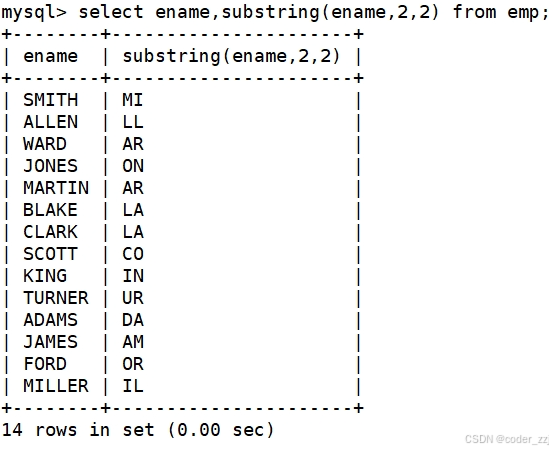
截取emp表中ename字段的第二个到第三个字符
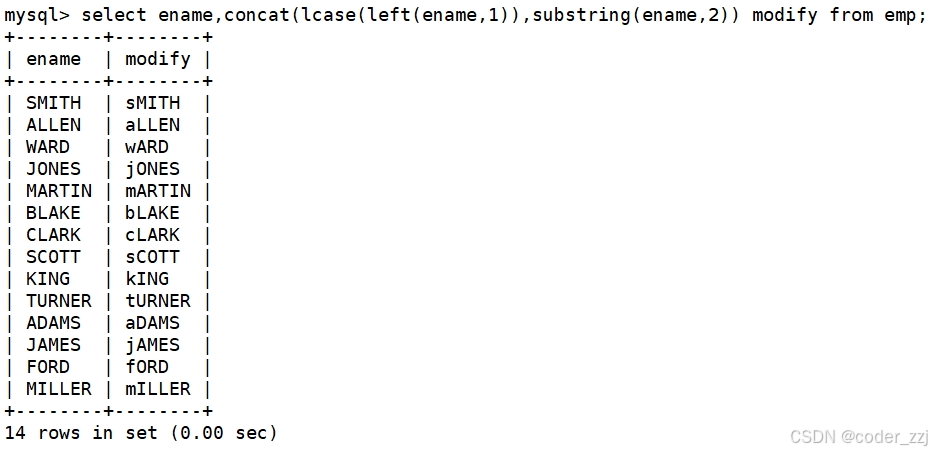
以首字母小写的方式显示所有员工的姓名(三个函数联合使用)
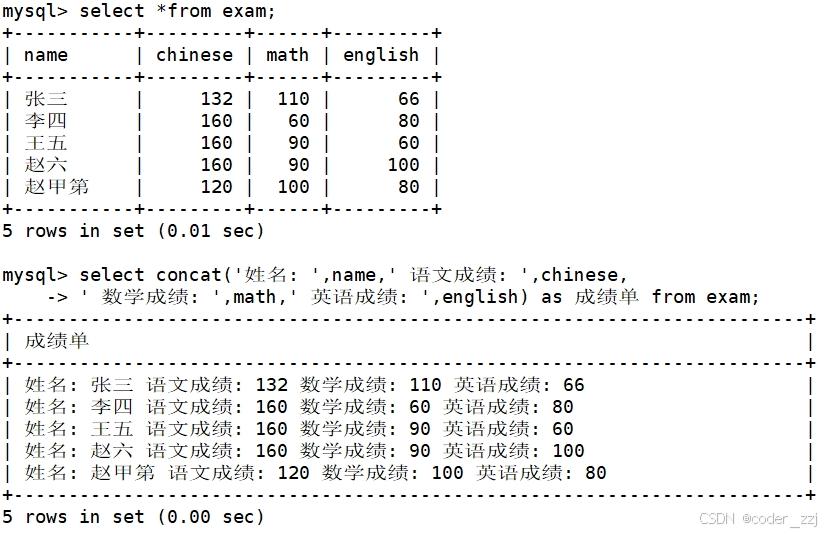
学生表中的信息的显示格式:"姓名:XXX 语文:XXX分,数学:XXX分,英语:XXX分"
求学生表中学生姓名占用的字节数

length返回大小以字节为单位。如果是多字节字符则计算多个字节数;如果是单字节字符则算作一个字节。比如:字母,数字算作一个字节,中文表示多个字节数(与字符集编码相关)
数学函数
|---------------------|-----------------------|
| abs(n) | n的绝对值 |
| bin(n) | n转成二进制 |
| hex(n) | n转成十六进制 |
| conv(n , from , to) | n是什么进制要转成什么进制 |
| ceiling(n) | n向上取整 |
| floor(n) | n向下取整 |
| format(n , cnt) | n格式化时保留cnt位小数 |
| rand() | 生成随机浮点数,范围【0.0 , 1.0】 |
| mod(n,m) | 返回n % m |
其它函数
|---------------------|----------------------------------------|
| user() | 查询当前用户 |
| database() | 查询当前正在使用的数据库 |
| md5(str) | 对字符串str进行md5摘要,生成32位字符串 |
| password(str) | 对用户的密码str进行加密 |
| ifnull(val1 , val2) | 对val1作判断:不为空返回val1,为空返回val2(C语言的三目操作符) |
实战OJ
批量插入数据
bash
insert into actor values (1,'PENELOPE','GUINESS','2006-02-15 12:34:33');
insert into actor values (2,'NICK','WAHLBERG','2006-02-15 12:34:33');找出所有员工当前薪水salary情况
cpp
select distinct salary from salaries order by salary desc;查找最晚入职员工的所有信息
cpp
select *from employees order by hire_date desc limit 1;查找入职员工时间升序排名的情况下的倒数第三的员工所有信息
可能有多个相同入职日期在倒数第三,所以要先分组后再排序
cpp
select *from employees
where hire_date= (select hire_date from employees group by hire_date order by hire_date desc limit 2,1);查找薪水记录超过15条的员工号emp_no
cpp
select emp_no,count(emp_no) as t from salaries group by emp_no having t >15;获取所有部门当前manager的当前薪水情况
两张表的emp_no相同才能找到经理对应的薪水
cpp
//方法1
select d.dept_no,d.emp_no,s.salary
from dept_manager as d,salaries as s
where d.emp_no = s.emp_no
and d.to_date = '9999-01-01'
and s.to_date = '9999-01-01'
order by d.dept_no;
//方法2
select d.dept_no,d.emp_no,s.salary
from dept_manager as d inner join salaries as s on
d.emp_no = s.emp_no
and d.to_date = '9999-01-01'
and s.to_date='9999-01-01'
order by d.dept_no;从titles表获取按照title进行分组
通过 emp_no 去重的个数来统计title个数:不同的emp_no下不同组的人(标题)的个数
cpp
select title,count(distinct emp_no) as t from titles group by title having t>=2;查找重复的电子邮箱
cpp
select email as Email from Person group by email having count(email) > 1;大的国家
cpp
select name,population,area from World where area >=3000000 or population >=25000000;第N高的薪水
cpp
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare M int;
set M = N-1;
RETURN (
select distinct salary from Employee order by salary desc limit M,1
);
END查找字符串中逗号出现的次数
cpp
select id,length(string)-length(replace(string,',','')) as cnt from strings;SQL查询中各个关键字的执行先后顺序:
from > on> join > where > group by > with > having > select > distinct > order by > limit
以上便是全部内容,有问题欢迎在评论区指正,感谢观看!